Data and Evaluation Closed-Loop for Model Capability Enhancement
Pith reviewed 2026-06-30 01:29 UTC · model grok-4.3
The pith
Capability slices turn benchmark failures into targeted, testable data interventions via a closed loop of taxonomies and mapping rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
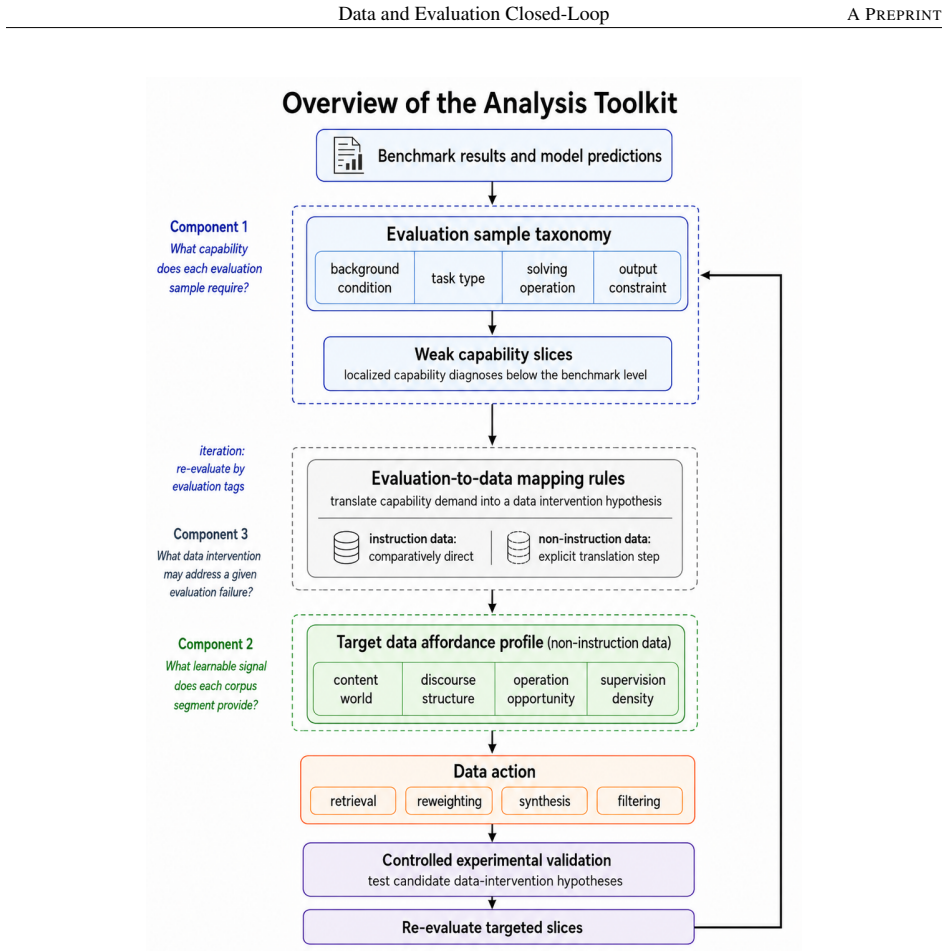
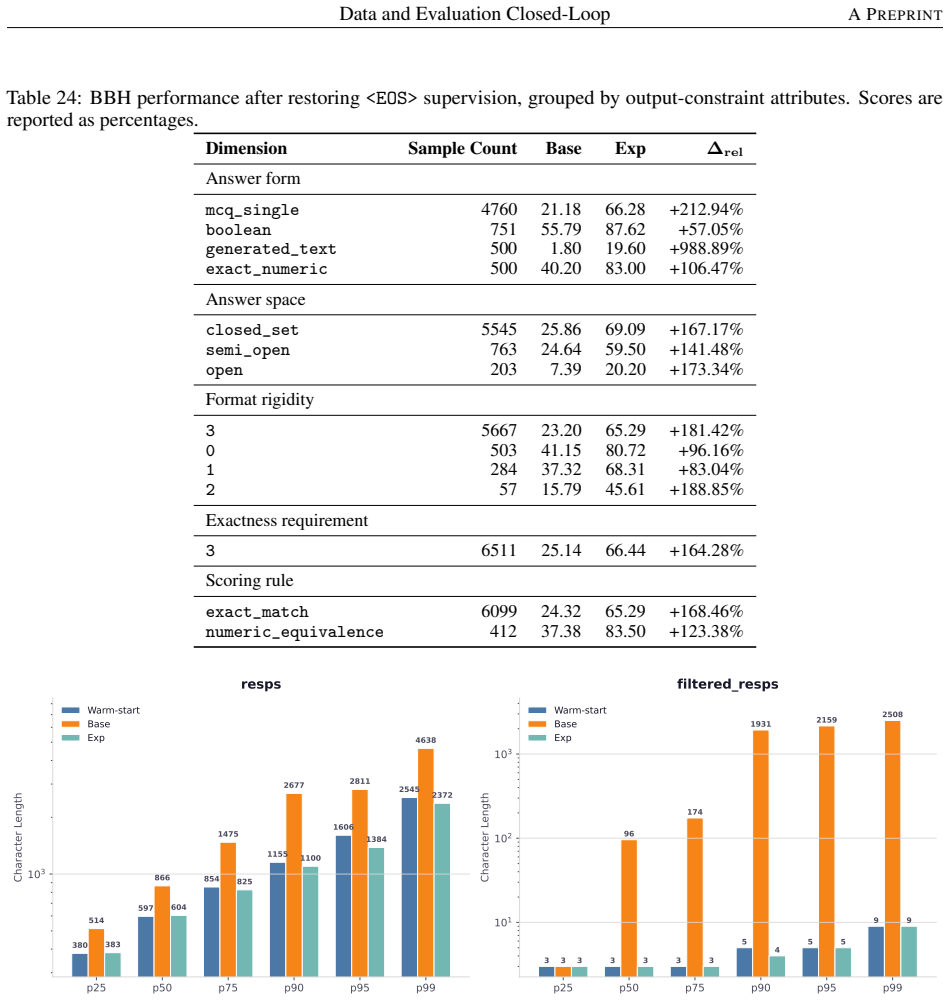
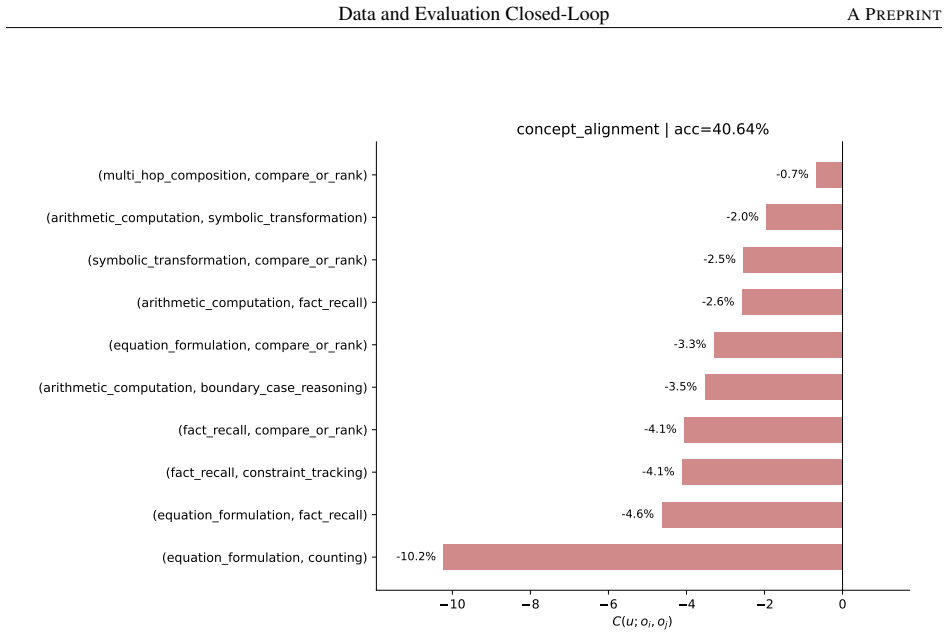
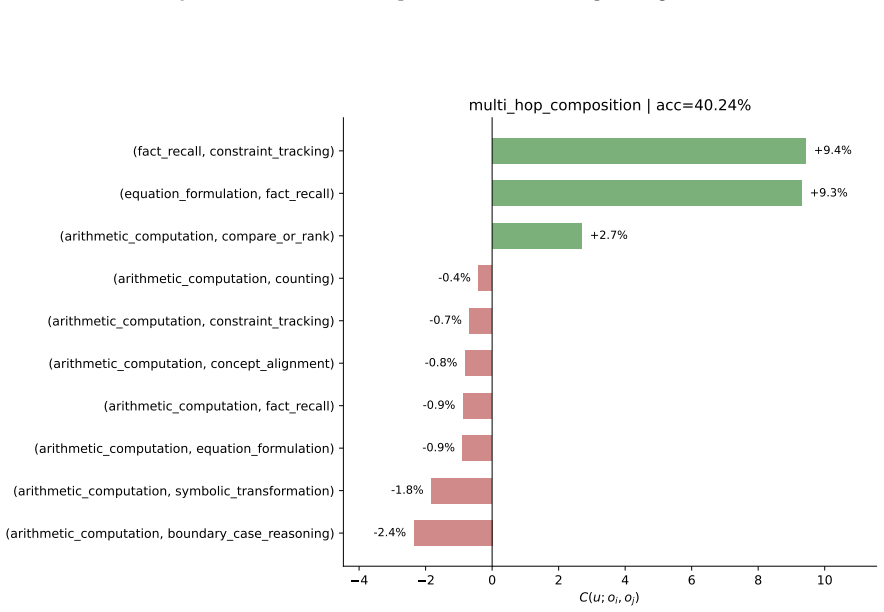
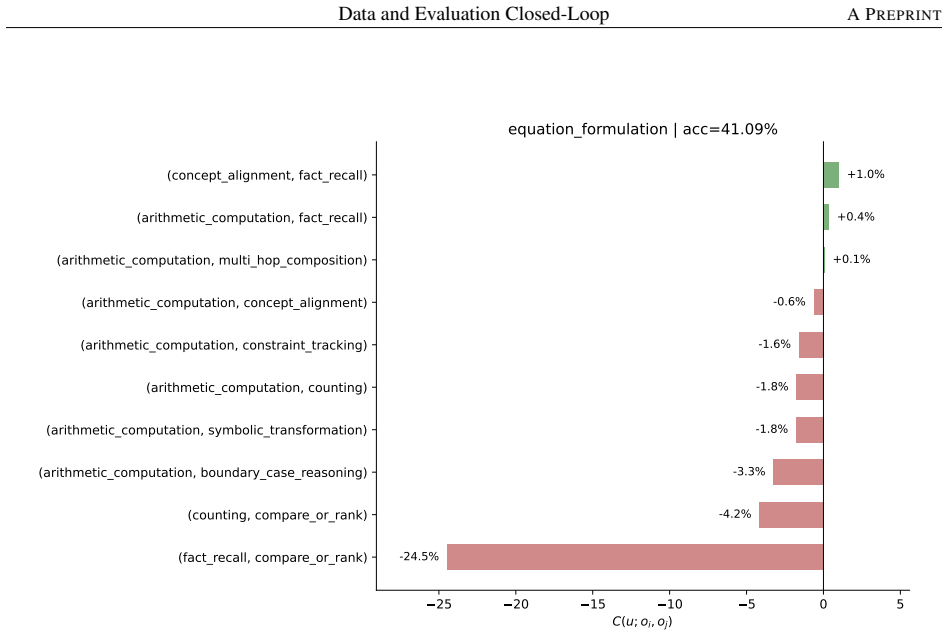
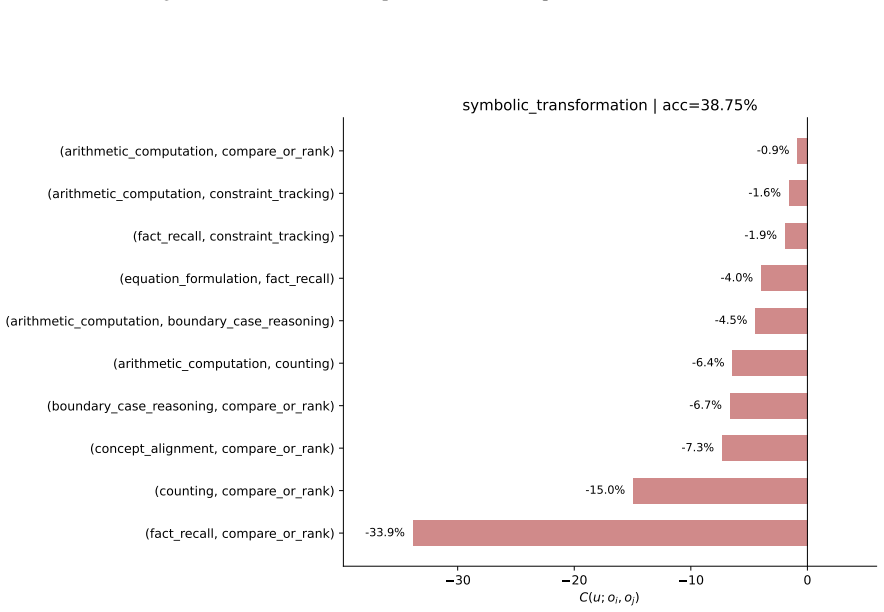
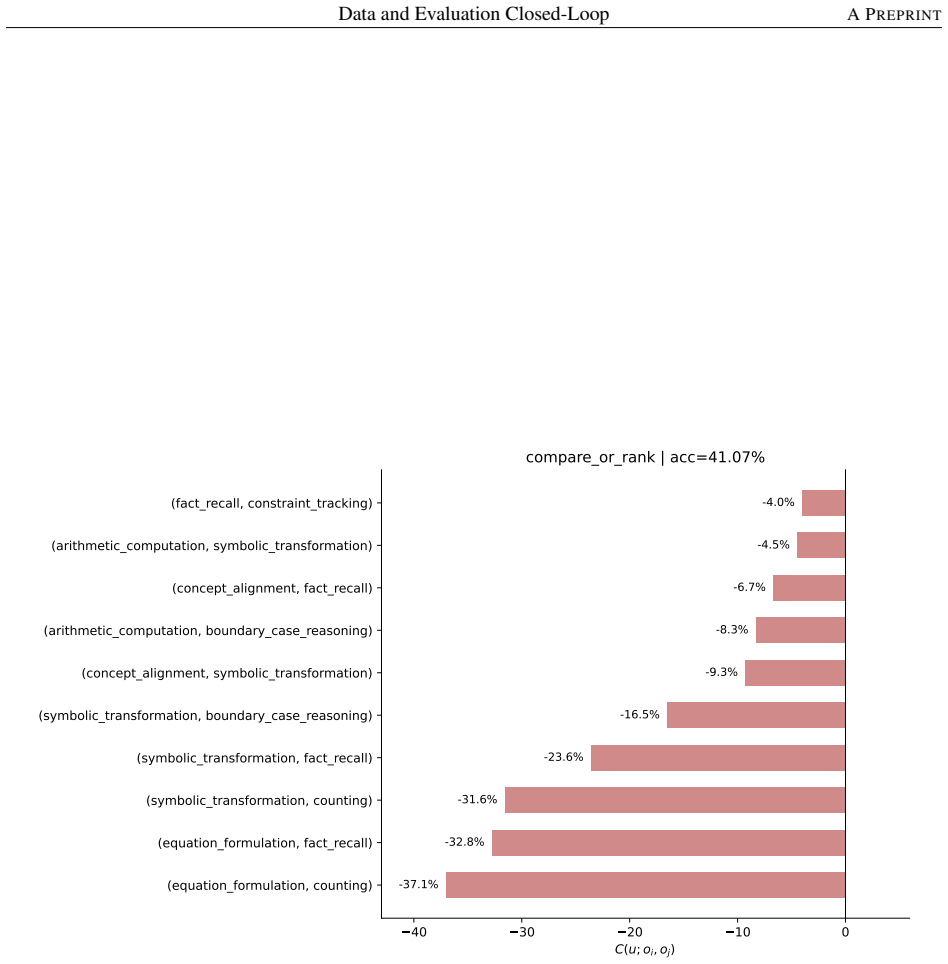
The capability slice is a group of evaluation samples sharing background condition, task type, solving operation, and output constraint. Built around this unit, an evaluation taxonomy, a non-instruction data taxonomy, and mapping rules form a closed loop turning a benchmark-level failure into a targeted, testable data intervention. The loop was tested on two case studies pulling in opposite directions. First, it rules the data out: continued pre-training drives BBH down by -46.82 percent, but diagnosis traces this to a single masked EOS loss rather than weakened reasoning; restoring it recovers BBH to 66.44 without changing the data. Second, it rules the data in: a persistent math-reasoning
What carries the argument
The capability slice, a group of evaluation samples that share background condition, task type, solving operation, and output constraint, which localizes a single weakness precisely enough for mapping to data while remaining stable under aggregation.
If this is right
- A drop in BBH after continued pre-training can be diagnosed as caused by masked EOS loss rather than by the training data itself.
- Restoring the masked loss recovers BBH performance above the original checkpoint without any data change.
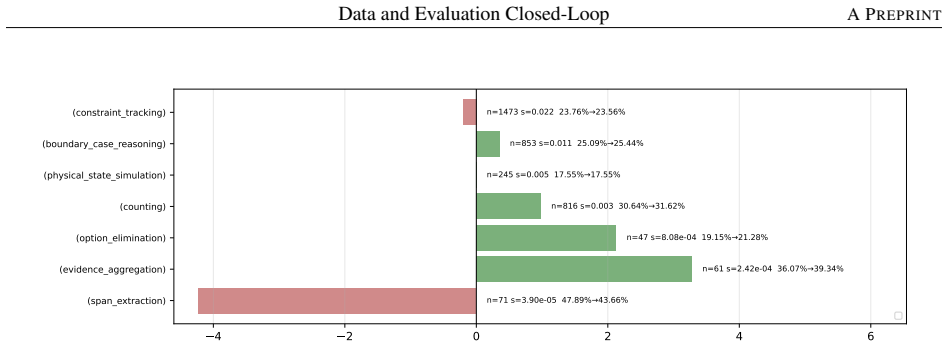
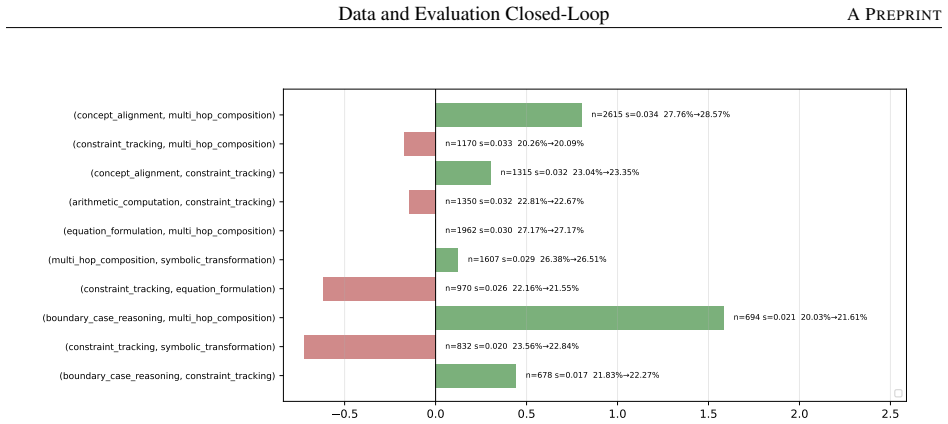
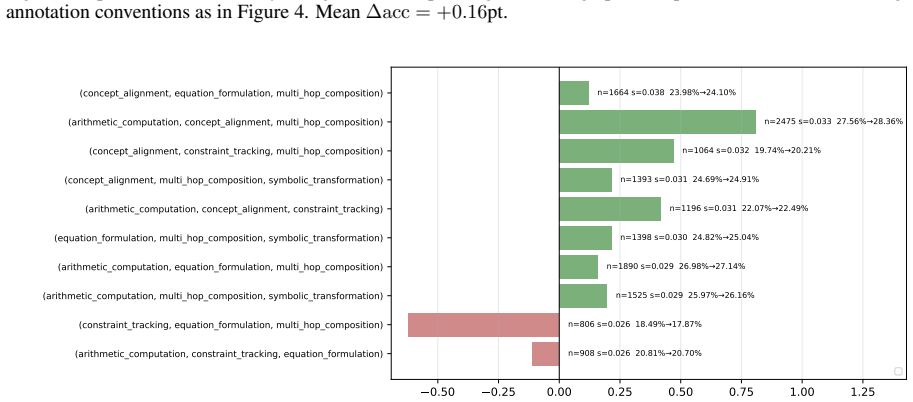
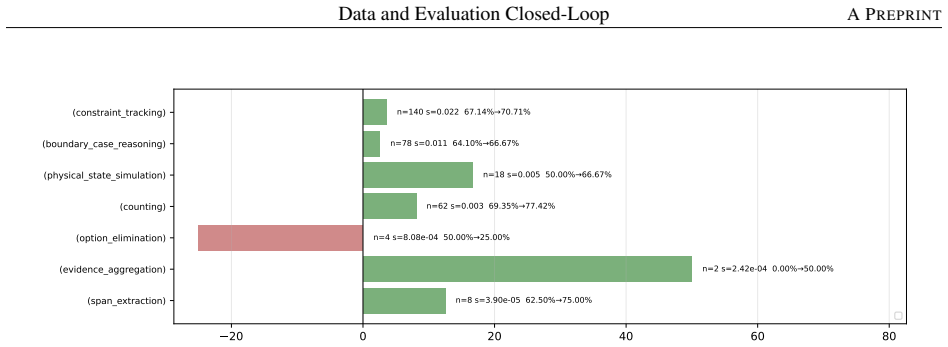
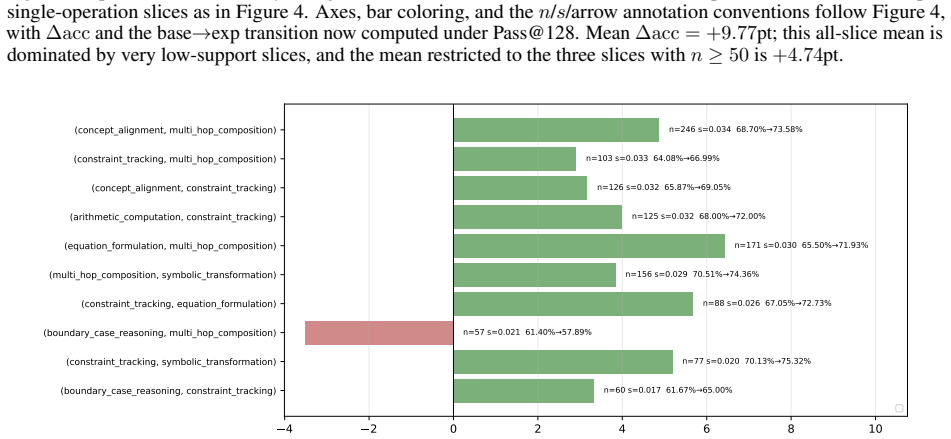
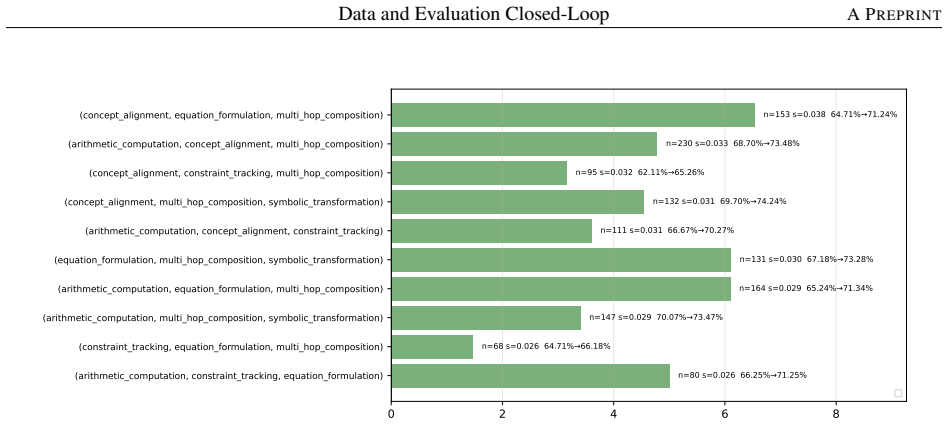
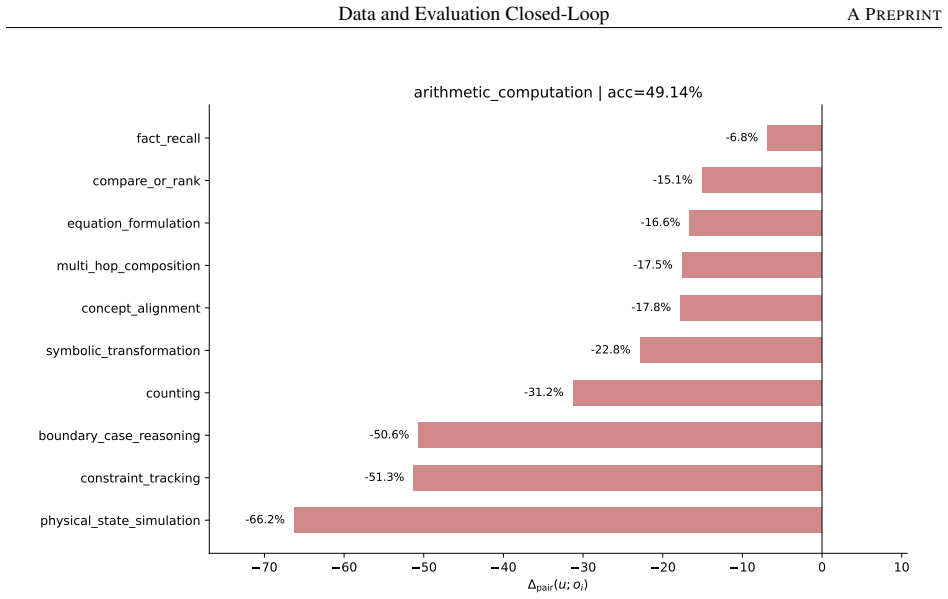
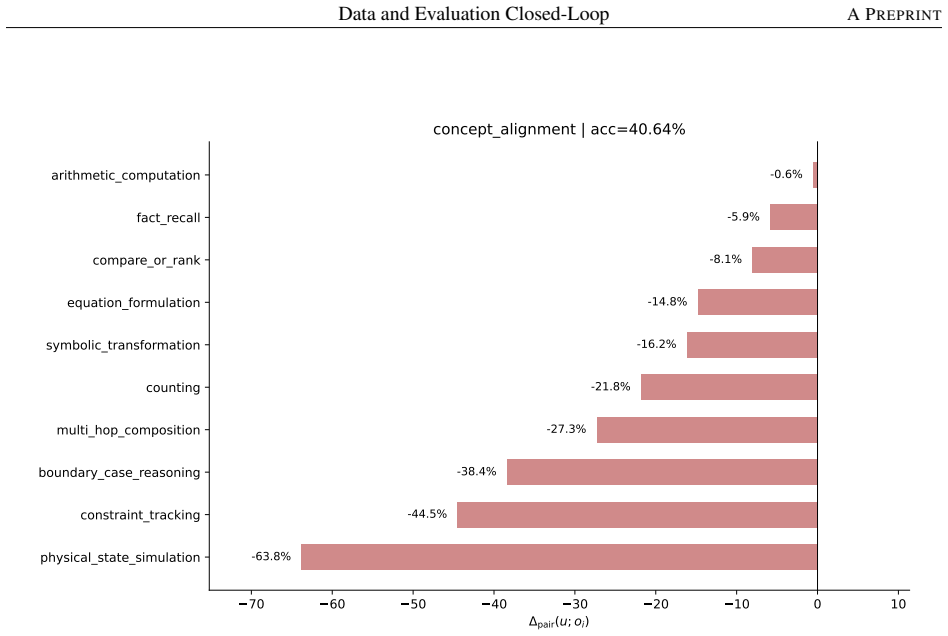
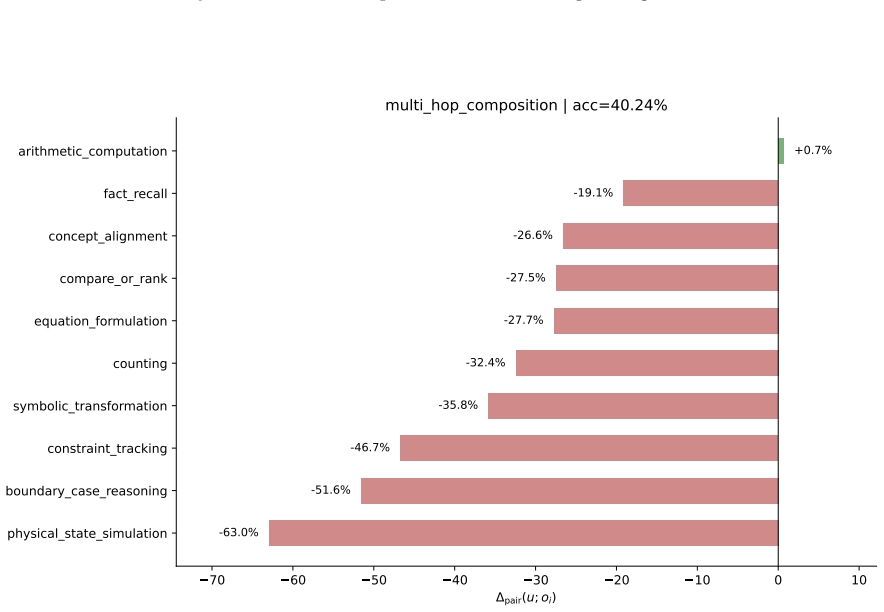
- Decomposing a math-reasoning weakness by solving operation identifies specific failing combinations that can be targeted by sampling.
- The same loop can correctly rule data in or out depending on the actual cause of the observed failure.
Where Pith is reading between the lines
- The closed loop could be run repeatedly during training so that each evaluation round directly informs the next data selection round.
- The approach might allow smaller, more focused data additions to replace large-scale random corpus growth when addressing specific weaknesses.
- If the taxonomies are extended to other modalities or model families, the same evaluation-to-data mapping could apply beyond text-only LLMs.
Load-bearing premise
The capability slice must be precise enough to localize one weakness yet stable enough to survive aggregation, rather than too coarse like a benchmark name or too noisy like a single sample.
What would settle it
Apply the closed loop to a new benchmark failure, execute the recommended data intervention or non-intervention, and check whether the targeted capability changes exactly as the diagnosis predicted.
Figures
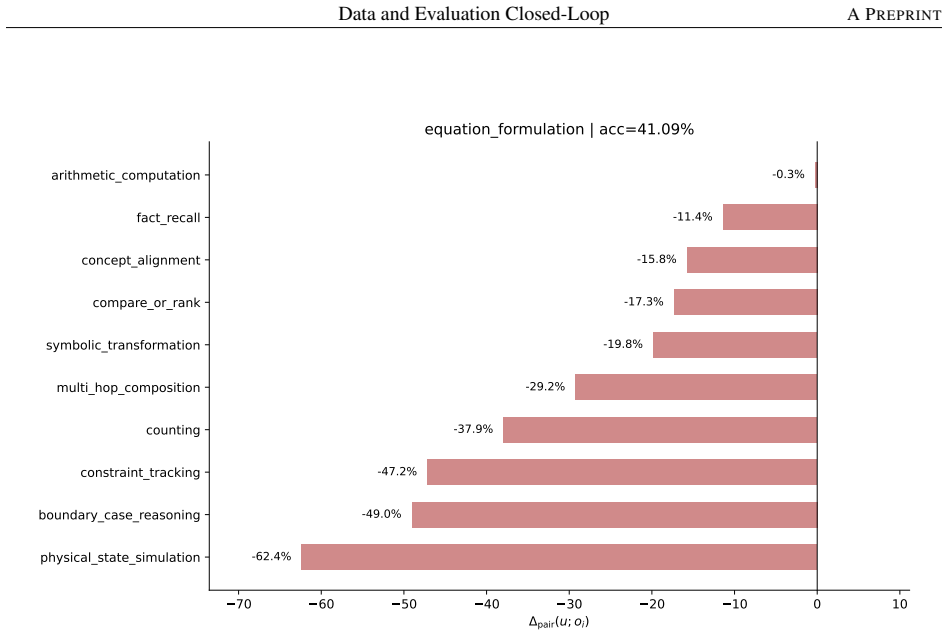
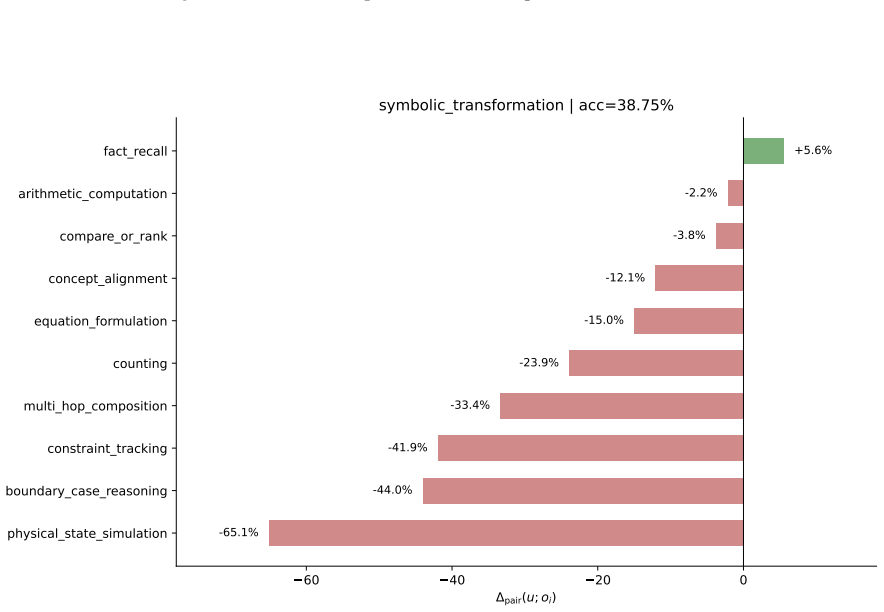
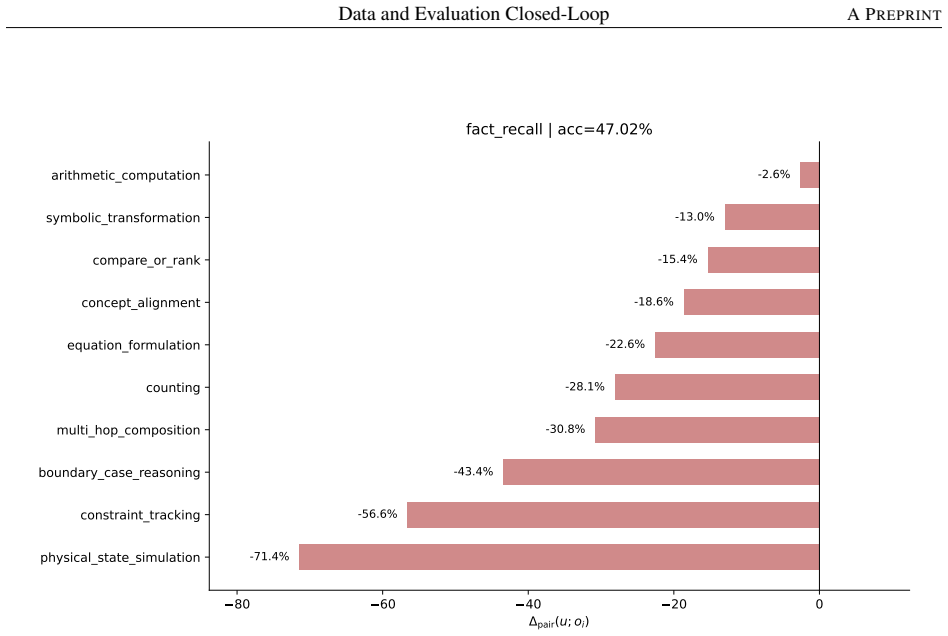
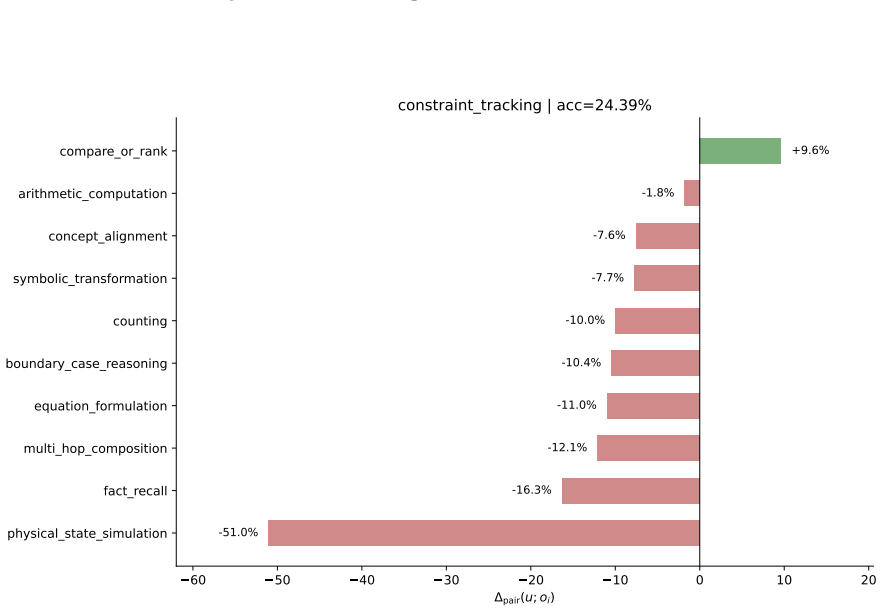
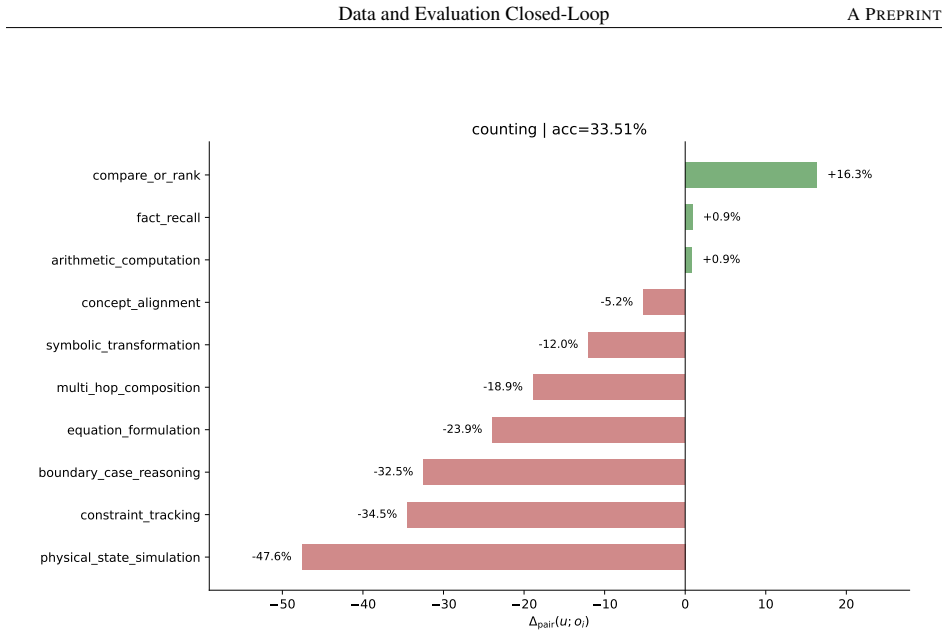
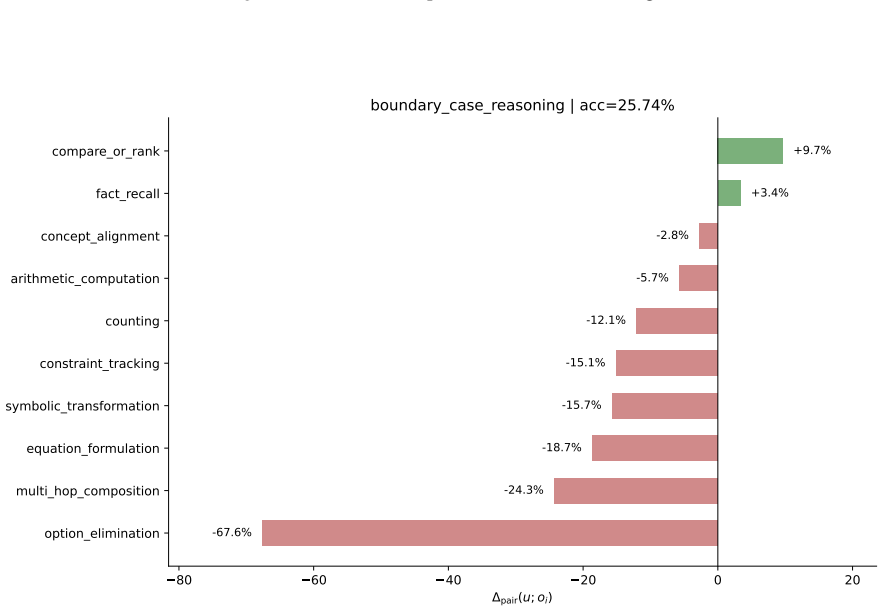
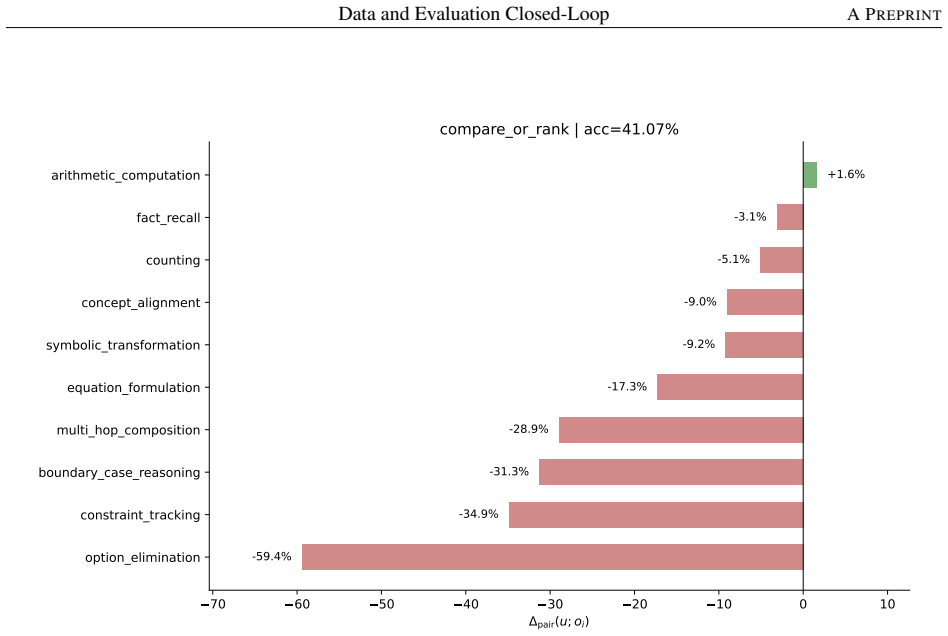
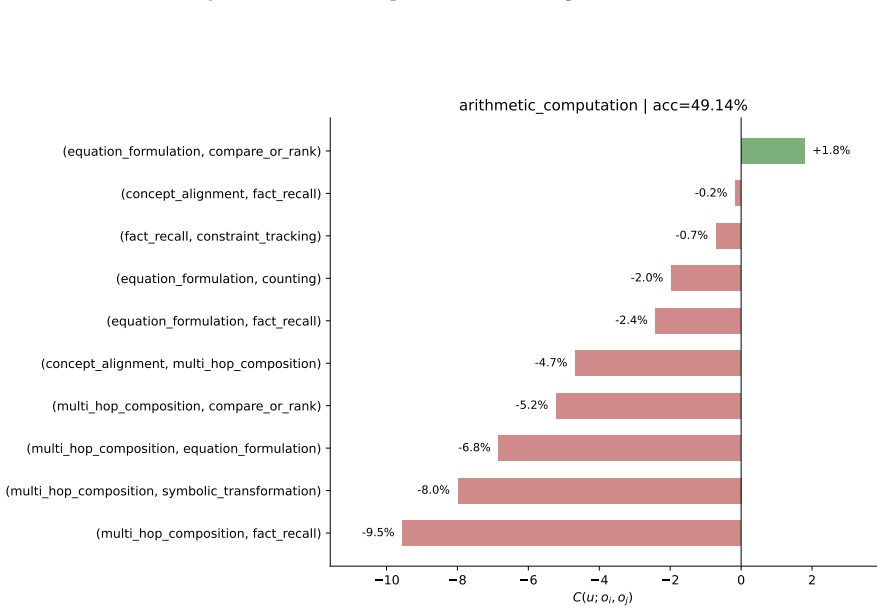
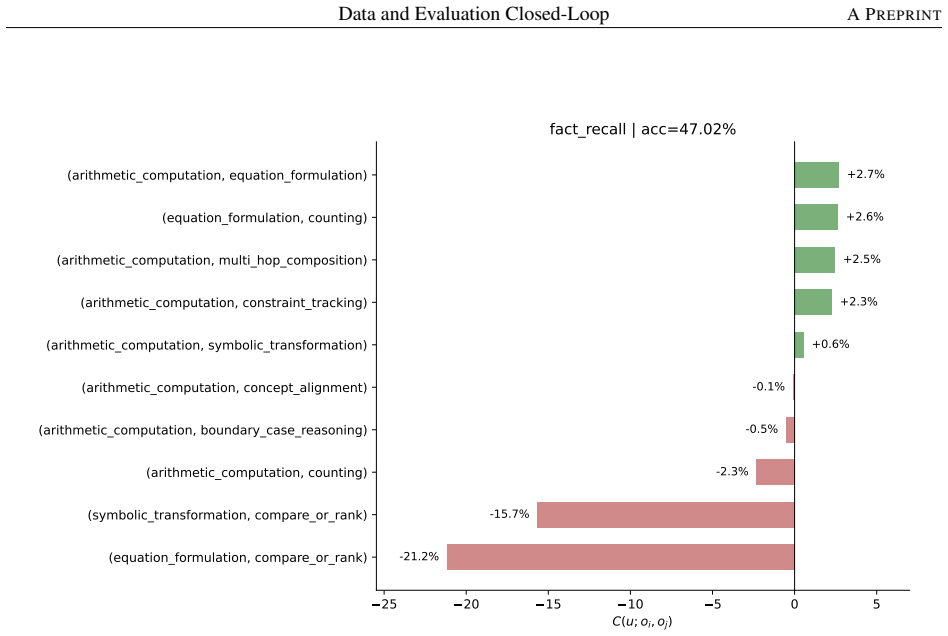
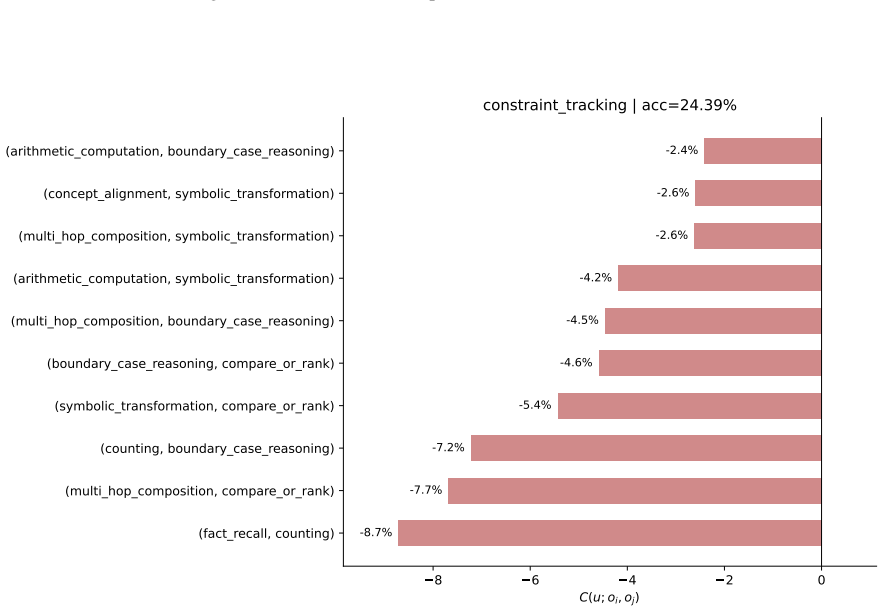
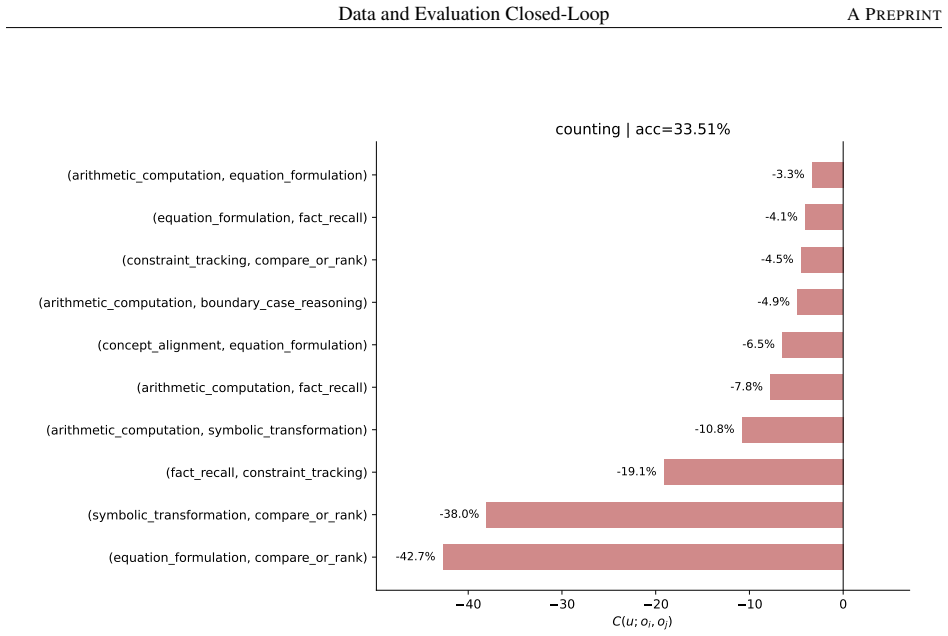
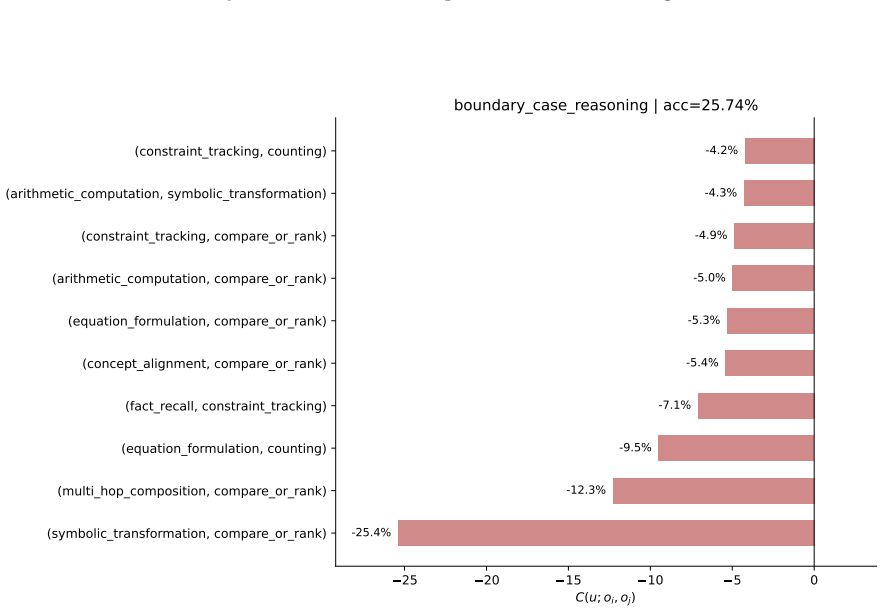
read the original abstract
Model capability is the central variable in LLM pre-training, yet is never observed directly: data shapes it prospectively, while evaluation reveals it only retrospectively, compressing samples, prompts, decoding, and scoring rules into one noisy score. Practical optimization runs this backward: a failure is observed first, and the engineer must infer the corpus fix. The two sides speak incompatible vocabularies -- benchmark names and per-sample correctness versus data sources, domains, and quality labels -- so this inference is usually intuition, not method. We close this gap with the \emph{capability slice}: a group of evaluation samples sharing background condition, task type, solving operation, and output constraint -- precise enough to localize a single weakness yet stable enough to survive aggregation, unlike a benchmark name, too coarse, or a single sample, too noisy. Built around this unit, an evaluation taxonomy, a non-instruction data taxonomy, and mapping rules form a closed loop turning a benchmark-level failure into a targeted, testable data intervention. We test this loop on two case studies pulling in opposite directions. First, the loop rules the data out: continued pre-training drives BBH down by $-46.82\%$, but diagnosis traces this to a single masked \texttt{\textless EOS\textgreater} loss rather than weakened reasoning; restoring it recovers BBH to $66.44$, above the original checkpoint, without changing the data. Second, the loop rules the data in: a persistent math-reasoning weakness is decomposed by solving operation into specific failing combinations, and a weakness-targeted sampling procedure built from it lifts AIME2025/AIME2026 Pass@128 from $6.67$/$0.00$ to $26.67$ each. The same unmodified loop reaches opposite, correct verdicts in both cases, showing the evaluation-to-data inference can be routine, auditable, and experimentally validated rather than intuitive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a 'capability slice' (grouping evaluation samples by shared background condition, task type, solving operation, and output constraint) combined with an evaluation taxonomy, non-instruction data taxonomy, and mapping rules forms a closed loop that converts benchmark-level LLM failures into targeted, testable data interventions. This is demonstrated in two case studies reaching opposite but correct verdicts: one rules data out as the cause of a BBH drop (attributing it to masked EOS loss instead) and recovers performance without data changes; the other rules data in to improve AIME math reasoning via weakness-targeted sampling, lifting Pass@128 scores from 6.67/0.00 to 26.67.
Significance. If the central claim holds, the framework provides a systematic alternative to intuitive diagnosis of pre-training issues, with the experimental validation across opposing outcomes serving as a notable strength. The approach could support more auditable capability enhancement if the slice definitions prove stable and reproducible.
major comments (2)
- [Abstract] Abstract: The claim that capability slices are 'precise enough to localize a single weakness yet stable enough to survive aggregation' (unlike benchmark names or single samples) is load-bearing for the assertion that the loop is 'routine, auditable, and experimentally validated rather than intuitive,' yet no quantitative checks are reported, such as inter-annotator agreement on slice boundaries or sensitivity of diagnoses to small re-groupings of samples.
- [Case studies] Case studies (as summarized in Abstract): Neither case study reports data exclusion criteria, statistical controls, or full methods for defining and applying the capability slices and mapping rules, which limits assessment of whether the diagnoses are reproducible or dependent on the particular choices made in these examples.
minor comments (1)
- [Abstract] Abstract: The numerical results (e.g., BBH drop of -46.82% and recovery to 66.44) should be explicitly cross-referenced to the corresponding tables or figures in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments and the recommendation for major revision. We address each major comment point by point below, and agree to incorporate revisions to enhance the reproducibility and quantitative validation of the proposed framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that capability slices are 'precise enough to localize a single weakness yet stable enough to survive aggregation' (unlike benchmark names or single samples) is load-bearing for the assertion that the loop is 'routine, auditable, and experimentally validated rather than intuitive,' yet no quantitative checks are reported, such as inter-annotator agreement on slice boundaries or sensitivity of diagnoses to small re-groupings of samples.
Authors: We agree that quantitative checks on slice stability would strengthen the central claim. The manuscript defines the slices via explicit taxonomies and rules, and the case studies apply them consistently to reach correct but opposing conclusions. However, no inter-annotator agreement or sensitivity analysis is currently reported. In the revised manuscript, we will add a dedicated subsection under the methodology that reports inter-annotator agreement on a sample of slices and sensitivity tests to small re-groupings. revision: yes
-
Referee: [Case studies] Case studies (as summarized in Abstract): Neither case study reports data exclusion criteria, statistical controls, or full methods for defining and applying the capability slices and mapping rules, which limits assessment of whether the diagnoses are reproducible or dependent on the particular choices made in these examples.
Authors: The full definitions of the evaluation taxonomy, non-instruction data taxonomy, and mapping rules are provided in Sections 3-5 of the manuscript, along with the specific application to each case study. Data exclusion criteria are noted in the experimental details for BBH (e.g., filtering for certain task types) and AIME. That said, we acknowledge that the presentation could be more explicit regarding statistical controls and step-by-step application procedures. We will revise the case study sections to include expanded methods descriptions, explicit data exclusion criteria, and any statistical controls used. revision: yes
Circularity Check
No significant circularity; derivation self-contained via explicit definitions and empirical tests
full rationale
The paper defines the capability slice explicitly as a group sharing background condition, task type, solving operation, and output constraint, then builds an evaluation taxonomy, non-instruction data taxonomy, and mapping rules around this unit to form the closed loop. The central claim—that the unmodified loop produces routine, auditable, opposite-correct verdicts—is supported by two independent case studies with concrete experimental outcomes (BBH recovery to 66.44 without data change; AIME Pass@128 lift to 26.67). No equations, fitted parameters, or predictions reduce by construction to inputs; no self-citations are invoked as load-bearing uniqueness theorems; the validation rests on external empirical results rather than tautology or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Capability slices can be defined to be both precise enough to localize a single weakness and stable enough to survive aggregation
invented entities (3)
-
capability slice
no independent evidence
-
evaluation taxonomy
no independent evidence
-
non-instruction data taxonomy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=
Real-time segmentation of on-line handwritten arabic script , author=. Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=. 2014 , organization=
2014
-
[2]
Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=
Fast classification of handwritten on-line Arabic characters , author=. Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=. 2014 , organization=
2014
-
[3]
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
PIQA: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[6]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proceedings of NAACL-HLT , year=
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs , author=. Proceedings of NAACL-HLT , year=
-
[9]
Information Processing Letters , volume=
Weighted random sampling with a reservoir , author=. Information Processing Letters , volume=
-
[10]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
FrontierMath: A benchmark for evaluating advanced mathematical reasoning in AI , author=. arXiv preprint arXiv:2411.04872 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
International Conference on Learning Representations , year=
Measuring massive multitask language understanding , author=. International Conference on Learning Representations , year=
-
[12]
Advances in Neural Information Processing Systems Datasets and Benchmarks Track , year=
Measuring mathematical problem solving with the MATH dataset , author=. Advances in Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[13]
Advances in Neural Information Processing Systems , year=
C-Eval: A multi-level multi-discipline Chinese evaluation suite for foundation models , author=. Advances in Neural Information Processing Systems , year=
-
[14]
Proceedings of ACL , year=
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of ACL , year=
-
[15]
Proceedings of EMNLP , year=
RACE: Large-scale reading comprehension dataset from examinations , author=. Proceedings of EMNLP , year=
-
[16]
Findings of ACL , year=
CMMLU: Measuring massive multitask language understanding in Chinese , author=. Findings of ACL , year=
-
[17]
DataComp-LM: In search of the next generation of training sets for language models
DataComp-LM: In search of the next generation of training sets for language models , author=. arXiv preprint arXiv:2406.11794 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2407.01492 , year=
RegMix: Data mixture as regression for language model pre-training , author=. arXiv preprint arXiv:2407.01492 , year=
-
[19]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
The FineWeb datasets: Decanting the web for the finest text data at scale , author=. arXiv preprint arXiv:2406.17557 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
First Conference on Language Modeling , year=
GPQA: A graduate-level Google-proof Q&A benchmark , author=. First Conference on Language Modeling , year=
-
[21]
Findings of ACL , year=
Challenging BIG-Bench tasks and whether chain-of-thought can solve them , author=. Findings of ACL , year=
-
[22]
2023 , howpublished=
Stanford Alpaca: An instruction-following LLaMA model , author=. 2023 , howpublished=
2023
-
[23]
Proceedings of ACL , year=
Self-Instruct: Aligning language models with self-generated instructions , author=. Proceedings of ACL , year=
-
[24]
Advances in Neural Information Processing Systems , year=
How far can camels go? Exploring the state of instruction tuning on open resources , author=. Advances in Neural Information Processing Systems , year=
-
[25]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark , author=. arXiv preprint arXiv:2406.01574 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in Neural Information Processing Systems , year=
DoReMi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , year=
-
[27]
International Conference on Learning Representations , year=
WizardLM: Empowering large language models to follow complex instructions , author=. International Conference on Learning Representations , year=
-
[28]
arXiv preprint arXiv:2403.16952 , year=
Data mixing laws: Optimizing data mixtures by predicting language modeling performance , author=. arXiv preprint arXiv:2403.16952 , year=
-
[29]
Proceedings of ACL , year=
HellaSwag: Can a machine really finish your sentence? , author=. Proceedings of ACL , year=
-
[30]
Findings of NAACL , year=
AGIEval: A human-centric benchmark for evaluating foundation models , author=. Findings of NAACL , year=
-
[31]
Pavlos S. Efraimidis and Paul G. Spirakis , keywords =. Weighted random sampling with a reservoir , journal =. 2006 , issn =. doi:https://doi.org/10.1016/j.ipl.2005.11.003 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.