Evolution-Aware Regression Test Prioritization of ML-Enabled Systems Using Gradient-Based Behavior Vectors
Pith reviewed 2026-06-29 03:42 UTC · model grok-4.3
The pith
Projected loss gradients from the original model estimate which test cases will improve or regress after an ML parameter update.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
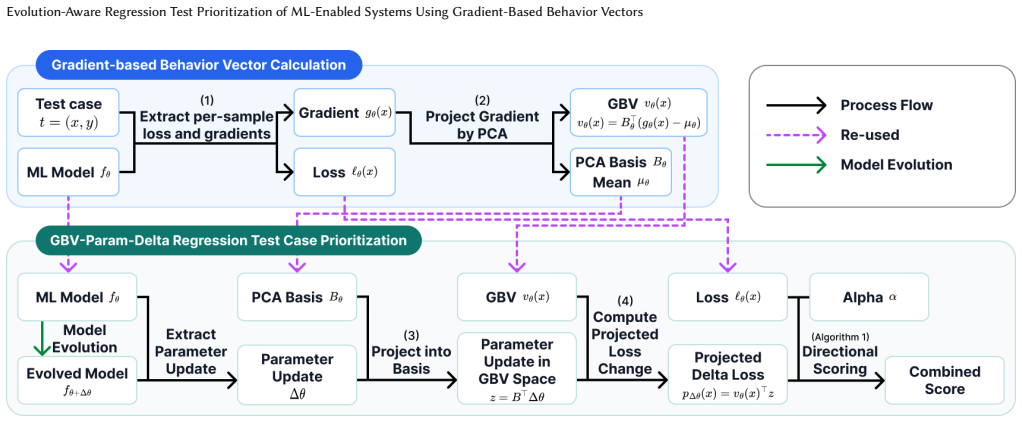
GBV-PD represents each test case as a gradient-based vector (GBV), a low-dimensional projection of its loss gradient under the original model. It then projects the observed parameter update of the evolved model onto the same PCA basis and uses the resulting alignment to estimate whether each test case's loss is likely to increase or decrease, without running the evolved model on test cases during prioritization.
What carries the argument
Gradient-based Behavior Vector-Parameter Delta (GBV-PD), which projects loss gradients and parameter deltas via PCA to estimate directional loss changes on test cases.
If this is right
- Test prioritization decisions can be made without any execution of the evolved model on the test suite.
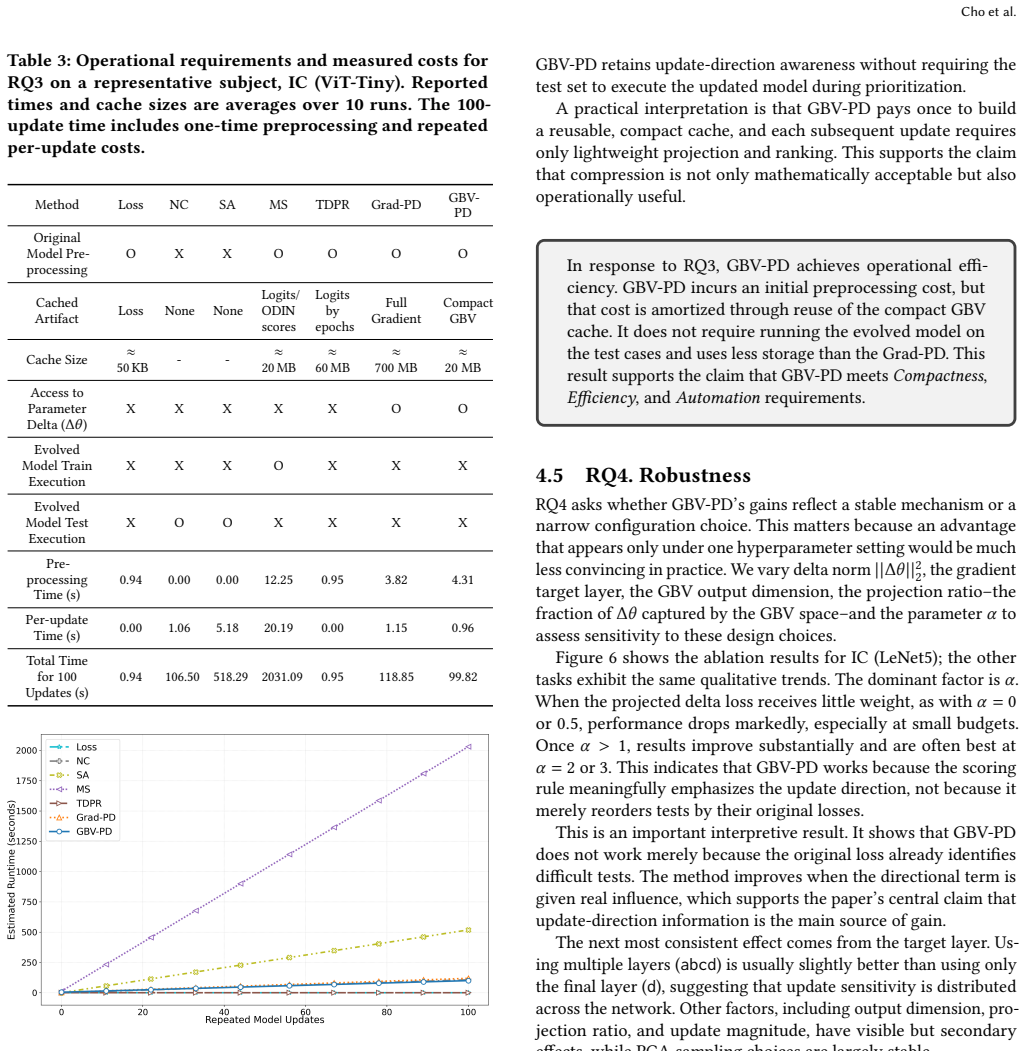
- Reusable GBV caching reduces time and storage costs when the same test suite is re-prioritized after multiple successive updates.
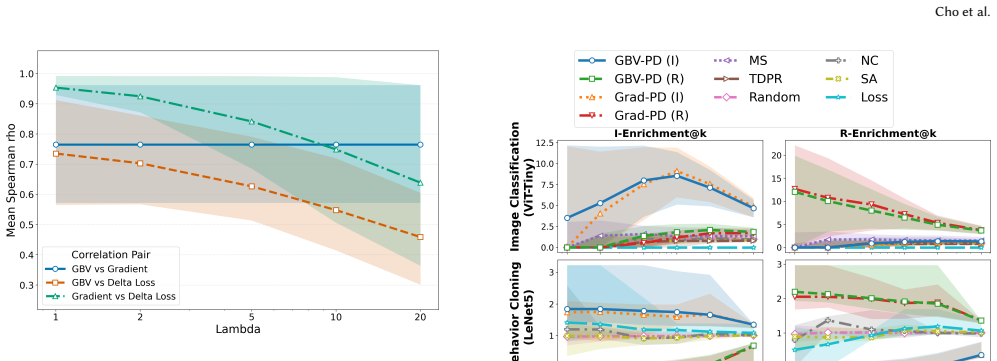
- The approach remains competitive with a full-gradient reference method while using only a low-dimensional projection.
- Non-directional baselines that ignore the sign of expected change are outperformed across both classification and regression tasks.
Where Pith is reading between the lines
- The same projected-gradient idea could be applied to black-box models if surrogate gradients or influence functions are substituted for direct loss gradients.
- Combining GBV-PD with existing coverage or diversity metrics might yield hybrid prioritizers that capture both directional loss change and structural coverage.
- The caching benefit suggests the technique is especially suited to continuous-integration pipelines that retrain models on a fixed test corpus at regular intervals.
Load-bearing premise
The loss-gradient directions computed on the original model, once projected via PCA, remain sufficiently aligned with the actual loss changes induced by a later parameter update so that the sign of the projected delta reliably indicates whether loss will increase or decrease on each test case.
What would settle it
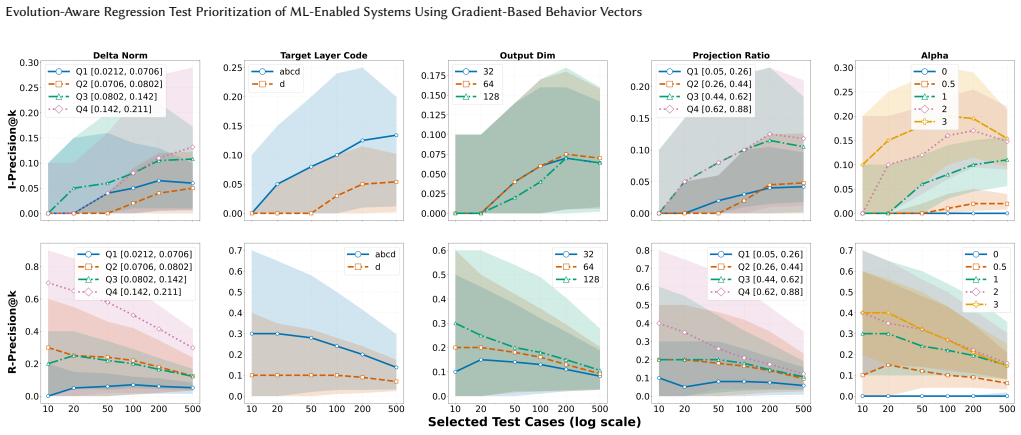
An experiment on a held-out set of model updates where the sign of the projected delta disagrees with the measured sign of actual loss change on more than half the test cases would show the alignment estimate is unreliable.
Figures

read the original abstract
The machine learning(ML) component of an ML-enabled system evolves through retraining, fine-tuning, and optimization, so previously valid test results may no longer hold. A single evolution step can worsen performance on some test cases while improving others, making regression test prioritization inherently directional. We present Gradient-based Behavior Vector-Parameter Delta(GBV-PD), the first approach to operationalize the behavior vector space for evolution-aware regression test prioritization. GBV-PD represents each test case as a gradient-based vector(GBV), a low-dimensional projection of its loss gradient under the original model. It then projects the observed parameter update of the evolved model onto the same PCA basis and uses the resulting alignment to estimate whether each test case's loss is likely to increase or decrease, without running the evolved model on test cases during prioritization. In an empirical study across classification and regression tasks, GBV-PD consistently outperformed non-directional baselines and remained competitive with a full-gradient reference, while offering better time and storage profiles for repeated updates via reusable GBV caching. These results show that behavior-space ideas can be operationalized into a practical and efficient mechanism for repeated-update regression testing of evolving ML-enabled systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GBV-PD for evolution-aware regression test prioritization of ML-enabled systems. Test cases are represented as low-dimensional GBVs obtained by PCA projection of loss gradients under the original model; the observed parameter delta of an evolved model is projected onto the same basis, and the sign of the resulting scalar is used to estimate whether each test case's loss will increase or decrease. An empirical study across classification and regression tasks reports that GBV-PD outperforms non-directional baselines, remains competitive with a full-gradient reference, and offers improved time/storage profiles via reusable GBV caching for repeated updates.
Significance. If the directional approximation holds, the work provides a practical, cacheable mechanism for handling directional regression testing under model evolution without re-executing the evolved model on the test suite. The reusable GBV caching for multiple updates is a concrete engineering contribution that addresses a common operational need in ML-enabled systems.
major comments (2)
- [Abstract] Abstract: the reported outperformance is presented without accompanying details on dataset sizes, number of evolution steps, statistical significance tests, or effect sizes. These omissions make it impossible to assess whether the gains are robust or sensitive to post-hoc choices.
- [Abstract] Abstract (method description): GBV-PD's central claim rests on the sign of the projected parameter delta reliably indicating loss increase/decrease. No auxiliary metric (sign-prediction accuracy, Spearman correlation between projected scalars and observed loss deltas, or similar) is supplied to validate that the first-order PCA alignment remains informative after the update. Without this, performance gains cannot be confidently attributed to the directional mechanism.
minor comments (1)
- [Abstract] Abstract: the phrase 'remained competitive with a full-gradient reference' would benefit from a brief parenthetical on what the reference computes and its computational cost relative to GBV-PD.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported outperformance is presented without accompanying details on dataset sizes, number of evolution steps, statistical significance tests, or effect sizes. These omissions make it impossible to assess whether the gains are robust or sensitive to post-hoc choices.
Authors: We agree that the abstract should provide more context for evaluating robustness. In the revised version, we will expand the abstract to report dataset sizes, the number of evolution steps, the statistical significance tests used, and observed effect sizes. revision: yes
-
Referee: [Abstract] Abstract (method description): GBV-PD's central claim rests on the sign of the projected parameter delta reliably indicating loss increase/decrease. No auxiliary metric (sign-prediction accuracy, Spearman correlation between projected scalars and observed loss deltas, or similar) is supplied to validate that the first-order PCA alignment remains informative after the update. Without this, performance gains cannot be confidently attributed to the directional mechanism.
Authors: We acknowledge that a direct auxiliary metric would help attribute gains specifically to the directional approximation. In the revision, we will add sign-prediction accuracy and Spearman correlation metrics (computed from the existing empirical data on observed loss changes) to both the abstract and main text. revision: yes
Circularity Check
No circularity: method defined via external gradients/PCA; empirical results independent of fitted inputs
full rationale
The paper defines GBV-PD directly from loss gradients on the original model, PCA projection, and parameter-delta alignment; none of these quantities are fitted to the prioritization outcomes or test labels used in evaluation. The reported performance gains are measured against external baselines on held-out evolution scenarios, with no self-citation chain or self-definitional reduction in the derivation. The central claim therefore remains non-circular by the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amin Abbasishahkoo, Mahboubeh Dadkhah, Lionel Briand, and Dayi Lin. 2025. Metasel: A test selection approach for fine-tuned dnn models.IEEE Transactions on Software Engineering(2025)
2025
-
[2]
Zohreh Aghababaeyan, Manel Abdellatif, Lionel Briand, Mojtaba Bagherzadeh, et al. 2023. Black-box testing of deep neural networks through test case diversity. IEEE Transactions on Software Engineering49, 5 (2023), 3182–3204
2023
-
[3]
Saleema Amershi, Andrew Begel, Christian Bird, Robert DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, and Thomas Zimmermann. 2019. Software engineering for machine learning: A case study. In2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 291–300
2019
-
[4]
Anonymous Authors. 2026. Replication kit. 10.6084/m9.figshare.31830196. Ac- cessed: 2026-06-23
-
[5]
2004.Convex optimization
Stephen Boyd and Lieven Vandenberghe. 2004.Convex optimization. Cambridge university press
2004
-
[6]
Jialuo Chen, Jingyi Wang, Xingjun Ma, Youcheng Sun, Jun Sun, Peixin Zhang, and Peng Cheng. 2023. QuoTe: Quality-oriented testing for deep learning systems. ACM Transactions on Software Engineering and Methodology32, 5 (2023), 1–33
2023
-
[7]
Jialuo Chen, Jingyi Wang, Xiyue Zhang, Youcheng Sun, Marta Kwiatkowska, Jiming Chen, and Peng Cheng. 2024. Fast: Boosting uncertainty-based test prioritization methods for neural networks via feature selection. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 895–906
2024
-
[8]
Eunho Cho. 2026. Towards Behavior Space Testing of Critical ML-Enabled Systems. InProceedings of the 2026 IEEE/ACM 48th International Conference on Software Engineering: Companion Proceedings
2026
-
[9]
Swaroopa Dola, Matthew B Dwyer, and Mary Lou Soffa. 2023. Input distribution coverage: Measuring feature interaction adequacy in neural network testing. ACM Transactions on Software Engineering and Methodology32, 3 (2023), 1–48
2023
-
[10]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations (ICLR)
2021
-
[11]
Yang Feng, Qingkai Shi, Xinyu Gao, Jun Wan, Chunrong Fang, and Zhenyu Chen. 2020. Deepgini: prioritizing massive tests to enhance the robustness of deep neural networks. InProceedings of the 29th ACM SIGSOFT international symposium on software testing and analysis. 177–188
2020
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Resid- ual Learning for Image Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778
2016
-
[13]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[14]
Krishnateja Killamsetty, Sivasubramanian Durga, Ganesh Ramakrishnan, Abir De, and Rishabh Iyer. 2021. Grad-match: Gradient matching based data subset selection for efficient deep model training. InInternational Conference on Machine Learning. PMLR, 5464–5474
2021
-
[15]
Jinhan Kim, Robert Feldt, and Shin Yoo. 2019. Guiding deep learning system testing using surprise adequacy. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 1039–1049
2019
-
[16]
Dominik Kreuzberger, Niklas Kühl, and Sebastian Hirschl. 2023. Machine learning operations (mlops): Overview, definition, and architecture.IEEE access11 (2023), 31866–31879
2023
-
[17]
2009.Learning Multiple Layers of Features from Tiny Images
Alex Krizhevsky. 2009.Learning Multiple Layers of Features from Tiny Images. Technical Report. University of Toronto
2009
-
[18]
Yongchan Kwon, Eric Wu, Kevin Wu, and James Zou. 2024. DataInf: Efficiently Estimating Data Influence in LoRA-tuned LLMs and Diffusion Models. InThe Twelfth International Conference on Learning Representations
2024
-
[19]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. Gradient- Based Learning Applied to Document Recognition.Proc. IEEE86, 11 (1998), 2278–2324
1998
-
[20]
Shuyue Li, Ming Fan, and Ting Liu. 2025. Towards regression testing and regression-free update for deep learning systems.Knowledge-Based Systems 315 (2025), 113292
2025
-
[21]
Shuyue Li, Jiaqi Guo, Jian-Guang Lou, Ming Fan, Ting Liu, and Dongmei Zhang
-
[22]
In Proceedings of the 44th international conference on software engineering: software engineering in practice
Testing machine learning systems in industry: an empirical study. In Proceedings of the 44th international conference on software engineering: software engineering in practice. 263–272
-
[23]
Zenan Li, Maorun Zhang, Jingwei Xu, Yuan Yao, Chun Cao, Taolue Chen, Xi- aoxing Ma, and Jian Lü. 2023. Lightweight approaches to DNN regression error reduction: An uncertainty alignment perspective. In2023 IEEE/ACM 45th Inter- national Conference on Software Engineering (ICSE). IEEE, 1187–1199
2023
-
[24]
2006.Numerical optimization
Jorge Nocedal and Stephen J Wright. 2006.Numerical optimization. Springer
2006
-
[25]
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Alek- sander Mądry. 2023. TRAK: attributing model behavior at scale. InProceedings of the 40th International Conference on Machine Learning. 27074–27113
2023
-
[26]
Kexin Pei, Yinzhi Cao, Junfeng Yang, and Suman Jana. 2017. Deepxplore: Au- tomated whitebox testing of deep learning systems. Inproceedings of the 26th Symposium on Operating Systems Principles. 1–18
2017
-
[27]
Cedric Renggli, Bojan Karlaš, Bolin Ding, Feng Liu, Kevin Schawinski, Wentao Wu, and Ce Zhang. 2019. Continuous integration of machine learning models with ease. ml/ci: Towards a rigorous yet practical treatment.Proceedings of Machine Learning and Systems1 (2019), 322–333
2019
-
[28]
Jian Shen, Zhong Li, Minxue Pan, and Xuandong Li. 2024. Prioritizing test inputs for DNNs using training dynamics. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1219–1231
2024
-
[29]
Andy Su. 2023. Udacity Self Driving Car - Behavioural Cloning. Kaggle dataset. https://www.kaggle.com/datasets/andy8744/udacity-self-driving-car- behavioural-cloning Accessed: 2026-03-21
2023
-
[30]
Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. 2020. Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Asso- ciation for Computational Linguistics, 9275–9293. doi...
-
[31]
Udacity. 2016. CarND-Behavioral-Cloning-P3. GitHub repository. https:// github.com/udacity/CarND-Behavioral-Cloning-P3 Starting files for the Udacity CarND Behavioral Cloning Project. Accessed: 2026-03-21
2016
-
[32]
Hanmo You, Zan Wang, Junjie Chen, Shuang Liu, and Shuochuan Li. 2023. Re- gression fuzzing for deep learning systems. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 82–94
2023
-
[33]
Hanmo You, Zan Wang, Bin Lin, and Junjie Chen. 2025. Navigating the testing of evolving deep learning systems: An exploratory interview study. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2726–2738
2025
-
[34]
Jie M Zhang, Mark Harman, Lei Ma, and Yang Liu. 2020. Machine learning testing: Survey, landscapes and horizons.IEEE Transactions on Software Engineering48, 1 (2020), 1–36
2020
-
[35]
Tahereh Zohdinasab, Vincenzo Riccio, Alessio Gambi, and Paolo Tonella. 2023. Efficient and effective feature space exploration for testing deep learning systems. ACM Transactions on Software Engineering and Methodology32, 2 (2023), 1–38
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.