Rigel: Self-Distilled Score Adaptation for Image and Video Captioning Evaluation
Pith reviewed 2026-06-30 06:52 UTC · model grok-4.3
The pith
Rigel distills an evaluation-specific scoring head from a frozen LLM to align caption metrics more closely with human judgments without large-vocabulary mismatches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
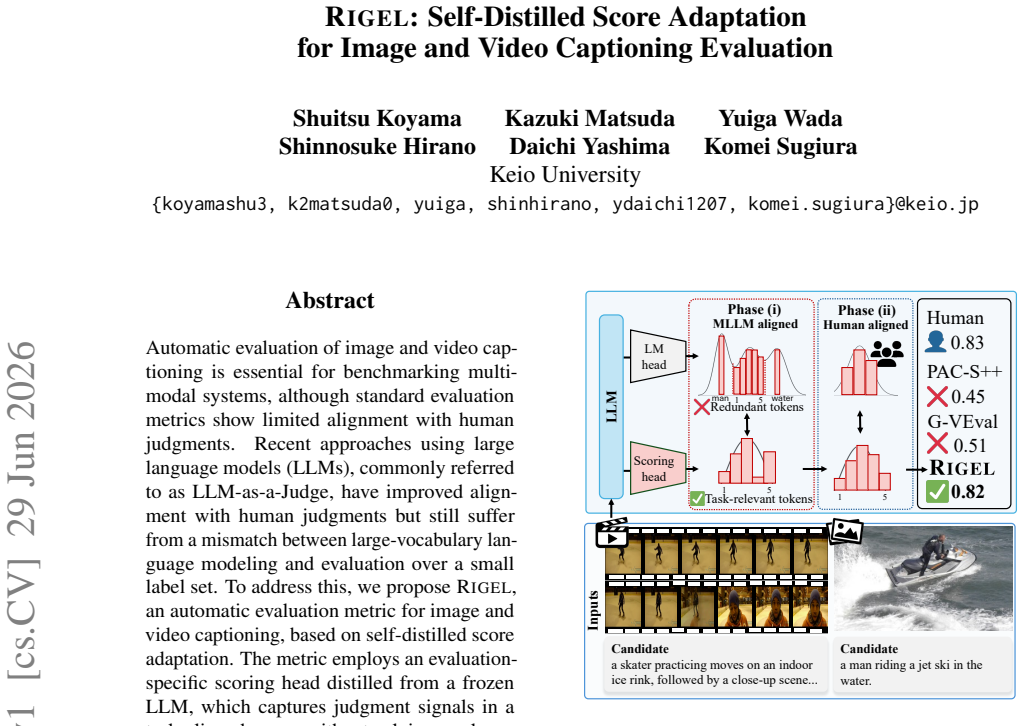
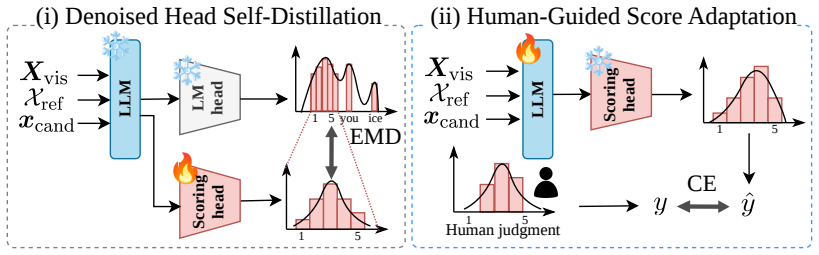
Rigel introduces self-distilled score adaptation: an evaluation-specific scoring head is distilled from a frozen LLM to capture judgment signals directly in a task-aligned space, bypassing reliance on large-vocabulary token sets; the LLM backbone is then refined using human judgment data. The method is trained on the Vid-Lepus dataset of 3,338 video clips, 33,380 reference captions, and 5,637 candidate captions. On multiple benchmarks Rigel outperforms existing metrics and delivers over 10-point gains on ActivityNet-Fact under reference-free conditions.
What carries the argument
The evaluation-specific scoring head distilled from the frozen LLM, which extracts judgment signals into a dedicated task-aligned space separate from full language modeling.
If this is right
- Rigel achieves higher correlation with human judgments than prior metrics across image and video captioning benchmarks.
- The approach yields particularly large gains in reference-free evaluation where no reference captions are supplied.
- A new Vid-Lepus dataset is provided that pairs video clips with multiple reference and candidate captions for metric training.
- Refining the LLM backbone on human judgment data further improves alignment after the initial distillation step.
Where Pith is reading between the lines
- The same distillation pattern could be tested on other generation tasks such as visual question answering or story generation to check whether task-specific heads generalize.
- If the scoring head proves stable, captioning models might be trained end-to-end by back-propagating through Rigel scores rather than cross-entropy on references.
- Reference-free evaluation becoming stronger would reduce dependence on expensive reference caption collections during model development.
Load-bearing premise
The distilled scoring head from the frozen LLM successfully isolates human judgment signals in its own space without needing the original large vocabulary.
What would settle it
On a held-out benchmark such as ActivityNet-Fact, Rigel fails to exceed prior metrics by a statistically significant margin in correlation with human ratings under reference-free conditions.
Figures



read the original abstract
Automatic evaluation of image and video captioning is essential for benchmarking multimodal systems, although standard evaluation metrics show limited alignment with human judgments. Recent approaches using large language models (LLMs), commonly referred to as LLM-as-a-Judge, have improved alignment with human judgments but still suffer from a mismatch between large-vocabulary language modeling and evaluation over a small label set. To address this, we propose Rigel, an automatic evaluation metric for image and video captioning, based on self-distilled score adaptation. The metric employs an evaluation-specific scoring head distilled from a frozen LLM, which captures judgment signals in a task-aligned space without relying on large-vocabulary token sets. We then refine the LLM backbone with human judgment data. To train Rigel, we constructed the Vid-Lepus dataset, which contains 3,338 video clips, 33,380 reference captions, and 5,637 candidate captions. Experiments on multiple benchmarks show that Rigel outperforms state-of-the-art metrics, achieving over 10-point improvements on ActivityNet-Fact in the reference-free setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Rigel, a new automatic evaluation metric for image and video captioning based on self-distilled score adaptation. It distills an evaluation-specific scoring head from a frozen LLM to operate in a task-aligned space without relying on large-vocabulary token sets, constructs the Vid-Lepus dataset (3,338 video clips, 33,380 reference captions, 5,637 candidate captions) for training with human judgments, refines the LLM backbone, and reports outperforming state-of-the-art metrics with over 10-point improvements on ActivityNet-Fact in the reference-free setting.
Significance. If the results hold with proper validation, this work could advance automatic evaluation in multimodal systems by addressing the known mismatch in LLM-as-a-Judge approaches. The Vid-Lepus dataset is a concrete contribution that supports training and benchmarking of judgment-aligned metrics. The self-distillation strategy for creating a task-aligned scoring head is a clear technical strength.
major comments (1)
- Abstract: the central performance claim of >10-point gains on ActivityNet-Fact (reference-free) is load-bearing, yet the provided description contains no experimental section, ablation studies, or statistical significance tests to support it; this prevents verification that the distilled scoring head, rather than dataset-specific fitting, drives the result.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify the experimental support for our claims. The abstract is a concise summary; the full manuscript provides the requested details.
read point-by-point responses
-
Referee: [—] Abstract: the central performance claim of >10-point gains on ActivityNet-Fact (reference-free) is load-bearing, yet the provided description contains no experimental section, ablation studies, or statistical significance tests to support it; this prevents verification that the distilled scoring head, rather than dataset-specific fitting, drives the result.
Authors: We agree that abstracts omit full experimental details by design. The complete manuscript includes Section 4 (Experiments) with benchmark results on ActivityNet-Fact (reference-free) showing the reported gains, Section 4.3 with ablations isolating the self-distilled scoring head, and statistical significance via paired tests in the result tables. Generalization is demonstrated by evaluating on held-out datasets distinct from Vid-Lepus training data, with ablations confirming the scoring head's contribution beyond dataset fitting. revision: no
Circularity Check
No significant circularity detected
full rationale
The described pipeline distills an evaluation-specific scoring head from a frozen LLM to operate in a task-aligned space, constructs a new Vid-Lepus dataset of video clips and captions, and refines the backbone on human judgments before reporting empirical gains on separate benchmarks such as ActivityNet-Fact. No equations, fitted-input predictions, self-citation chains, or uniqueness theorems are present in the text that would reduce any claimed result to its own inputs by construction. The central performance claims therefore remain independent of the training procedure in the supplied description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AuroraCap: Efficient, Performant Video De- tailed Captioning and a New Benchmark. InICLR. David Chan, Suzanne Petryk, Joseph Gonzalez, Trevor Darrell, and John Canny. 2023. CLAIR: Evaluating Image Captions with Large Language Models. In EMNLP, pages 13638–13646. Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Framing Image Description as a Ranking Task: Data, Models and Evaluation Metrics.JAIR, 47:853– 899. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InICLR. Nakamasa Inoue, Kanoko Goto, Masanari Oi, Martyna Gruszka, Mahiro Ukai, Takumi Hir...
2022
-
[3]
DENEB: A Hallucination-Robust Automatic Evaluation Metric for Image Captioning. InACCV, pages 3570–3586. Masanari Ohi, Masahiro Kaneko, Naoaki Okazaki, and Nakamasa Inoue. 2024. HarmonicEval: Multi- modal, Multi-task, Multi-criteria Automatic Evalua- tion Using a Vision Language Model.arXiv preprint arXiv:2412.14613. Gabriel Oliveira, Esther Colombini, an...
-
[4]
InW-NUT, pages 351–360
CIDEr-R: Robust Consensus-based Image De- scription Evaluation. InW-NUT, pages 351–360. Kishore Papineni, Salim Roukos, Todd Ward, and Wei Zhu. 2002. BLEU: a Method for Automatic Evalua- tion of Machine Translation. InACL, pages 311–318. Yossi Rubner, Carlo Tomasi, and Leonidas J. Guibas
2002
-
[5]
Sara Sarto, Manuele Barraco, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara
The Earth Mover’s Distance as a Metric for Image Retrieval.International Journal of Computer Vision, 40(2):99–121. Sara Sarto, Manuele Barraco, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2023. Positive- Augmented Contrastive Learning for Image and Video Captioning Evaluation. InCVPR, pages 6914– 6924. Sara Sarto, Marcella Cornia, Lorenzo Barald...
2023
-
[6]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A Family of Highly Capable Multi- modal Models.arXiv preprint arXiv:2312.11805. Tony Cheng Tong, Sirui He, Zhiwen Shao, and Dit- Yan Yeung. 2025. G-VEval: A Versatile Metric for Evaluating Image and Video Captions Using GPT-4o. InAAAI, pages 7419–7427. Ramakrishna Vedantam, Lawrence Zitnick, and Devi Parikh. 2015. CIDEr: Consensus-based Image De- ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
JaSPICE: Automatic Evaluation Metric Using Predicate-Argument Structures for Image Captioning Models. InCoNLL, pages 424–435. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, and 65 others. 2025. In- ternvl3.5: Advancing open-source multimodal mod- els in versatility, reasoning, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
and JaSPICE (Wada et al., 2023), have also been proposed to improve robustness or adapt eval- uation to specific settings. Although these metrics remain standard in the literature, prior studies have shown that they often correlate only weakly with human judgments, especially when captions are semantically correct but lexically diverse (Hessel et al., 202...
2023
-
[9]
improve this paradigm by adapting CLIP- based scoring to image caption evaluation. Other approaches, such as ViLBERTScore (Lee et al., 2020), UMIC (Lee et al., 2021), Polos (Wada et al., 2024), and DENEB (Matsuda et al., 2024), further Qwen2.5-VL-3BLLaVA-OneVision-1.5-8BQwen3-VL-2B InternVL-3.5-2B [%] Figure 6: The logit distribution over score tokens (“1...
2020
-
[12]
Compare the generated caption to video frames
-
[14]
Your score is Full prompt for video captioning in the reference-based setting Evaluate the quality of a video caption based on video frames and reference captions
Assign ONE score from 1 to 5 Generated Caption: cand Please output only a single integer from 1 to 5, without any explanation or formatting. Your score is Full prompt for video captioning in the reference-based setting Evaluate the quality of a video caption based on video frames and reference captions. Evaluation Criteria: - Score ranges from 1 to 5 - 1:...
-
[15]
Examine the video frames to understand the main content
-
[16]
Assess how accurately the caption describes the video
-
[17]
Compare the generated caption to both video frames and references
-
[19]
Your score is Full prompt for image captioning in the reference-free setting Evaluate the quality of a image caption based on image
Assign ONE score from 1 to 5 Reference Captions: refs_text Generated Caption: cand Please output only a single integer from 1 to 5, without any explanation or formatting. Your score is Full prompt for image captioning in the reference-free setting Evaluate the quality of a image caption based on image. Evaluation Criteria: - Score ranges from 1 to 5 - 1: ...
-
[22]
Compare the generated caption to image
-
[24]
Your score is Full prompt for image captioning in the reference-based setting Evaluate the quality of a image caption based on image and reference captions
Assign ONE score from 1 to 5 Generated Caption: cand Please output only a single integer from 1 to 5, without any explanation or formatting. Your score is Full prompt for image captioning in the reference-based setting Evaluate the quality of a image caption based on image and reference captions. Evaluation Criteria: - Score ranges from 1 to 5 - 1: Comple...
-
[25]
Examine the image to understand the main content
-
[26]
Assess how accurately the caption describes the image
-
[27]
Compare the generated caption to both im- age and references
-
[28]
Assess coverage of main points and rele- vance
-
[29]
Your score is H Additional Details for ARR Checklist Discuss the License for Artifacts.RIGELand Vid-Lepus are released under the BSD 3-Clause Clear License
Assign ONE score from 1 to 5 Reference Captions: refs_text Generated Caption: cand Please output only a single integer from 1 to 5, without any explanation or formatting. Your score is H Additional Details for ARR Checklist Discuss the License for Artifacts.RIGELand Vid-Lepus are released under the BSD 3-Clause Clear License. The licenses of the models an...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.