Discrete Causal Representations from Heterogeneous Domains: A Bayesian Approach with Social Survey Applications
Pith reviewed 2026-06-27 23:19 UTC · model grok-4.3
The pith
A Bayesian hierarchical model infers discrete causal concepts and relations from heterogeneous multi-domain data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
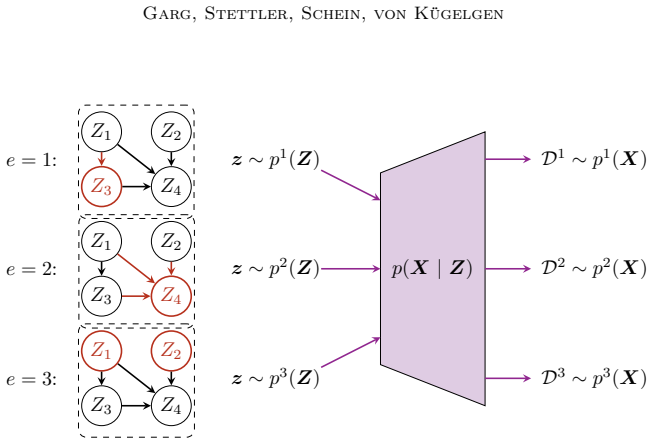
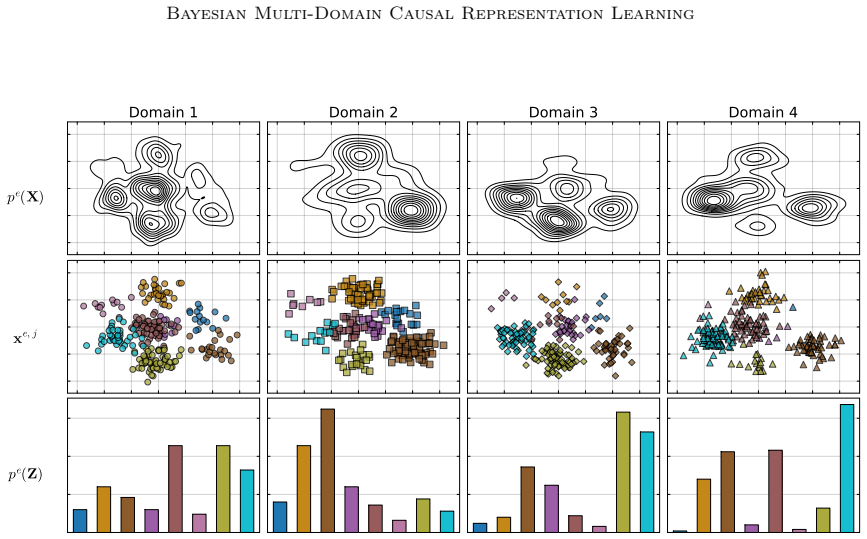
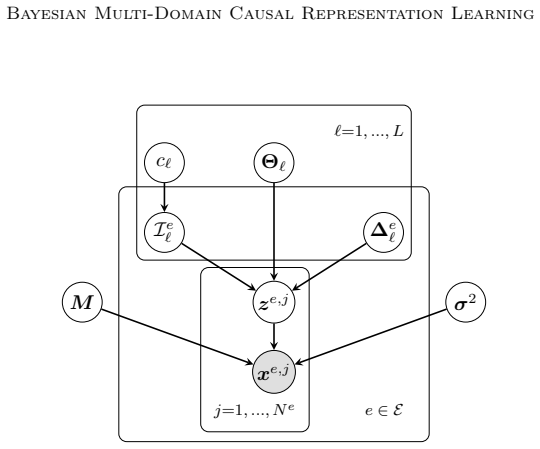
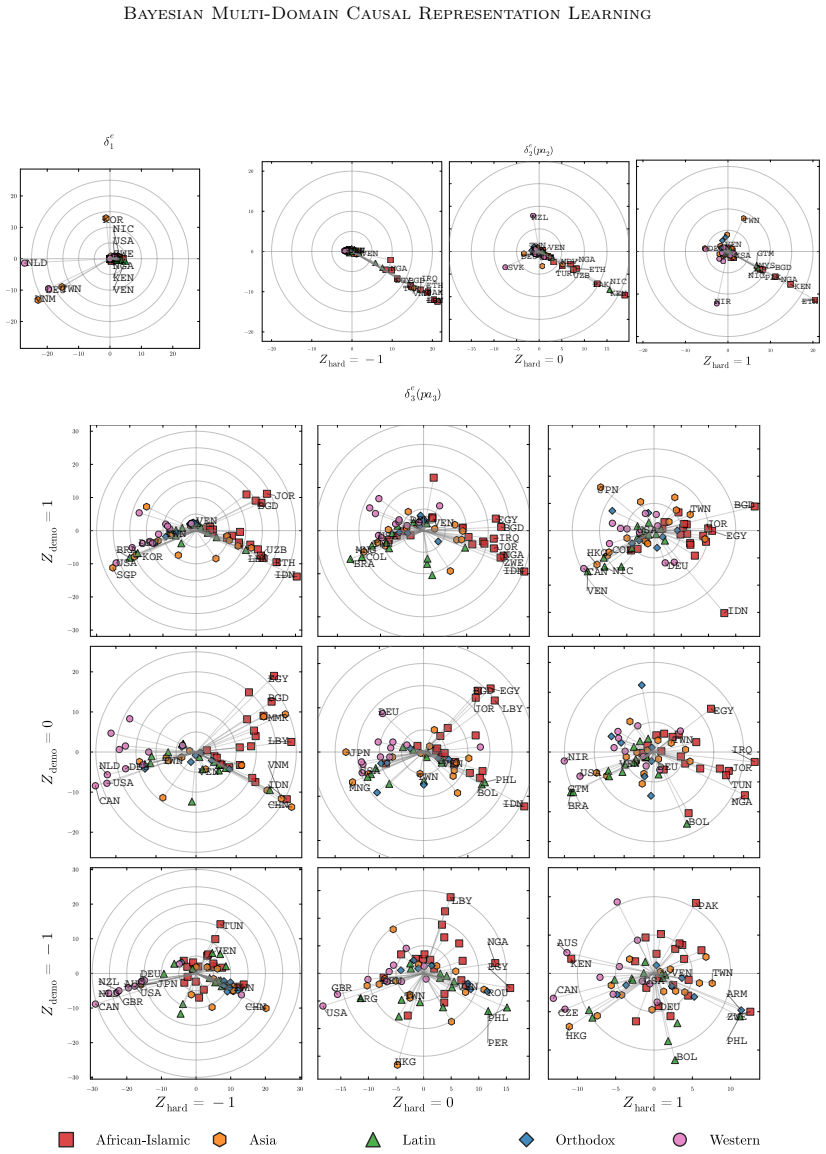
The paper shows that causal assumptions and interpretability desiderata can be encoded as priors and parametric choices inside a hierarchical model whose multimodal posterior over discrete concepts and unknown multi-node soft interventions is amenable to sequential Monte Carlo approximation, and that the resulting procedure recovers meaningful high-level concepts together with plausible causal relations when applied to multi-country social survey data.
What carries the argument
Hierarchical Bayesian model whose priors encode causal assumptions and interpretability, sampled via sequential Monte Carlo to approximate the posterior over discrete concepts and unknown soft interventions.
If this is right
- The model identifies discrete high-level causal concepts from low-level measurements even when the data come from different environments.
- Unknown soft interventions that affect multiple nodes can be handled without prior specification of which nodes are affected.
- Posterior samples quantify uncertainty over both the concepts and the causal relations among them.
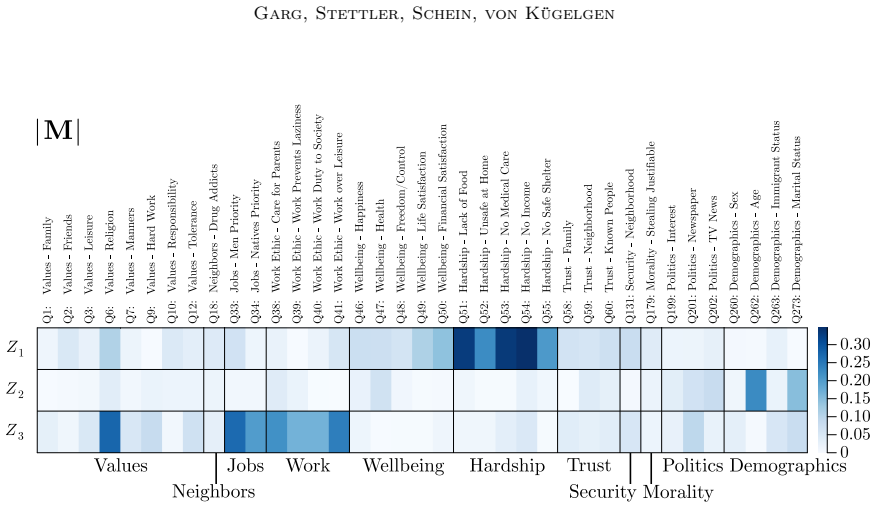
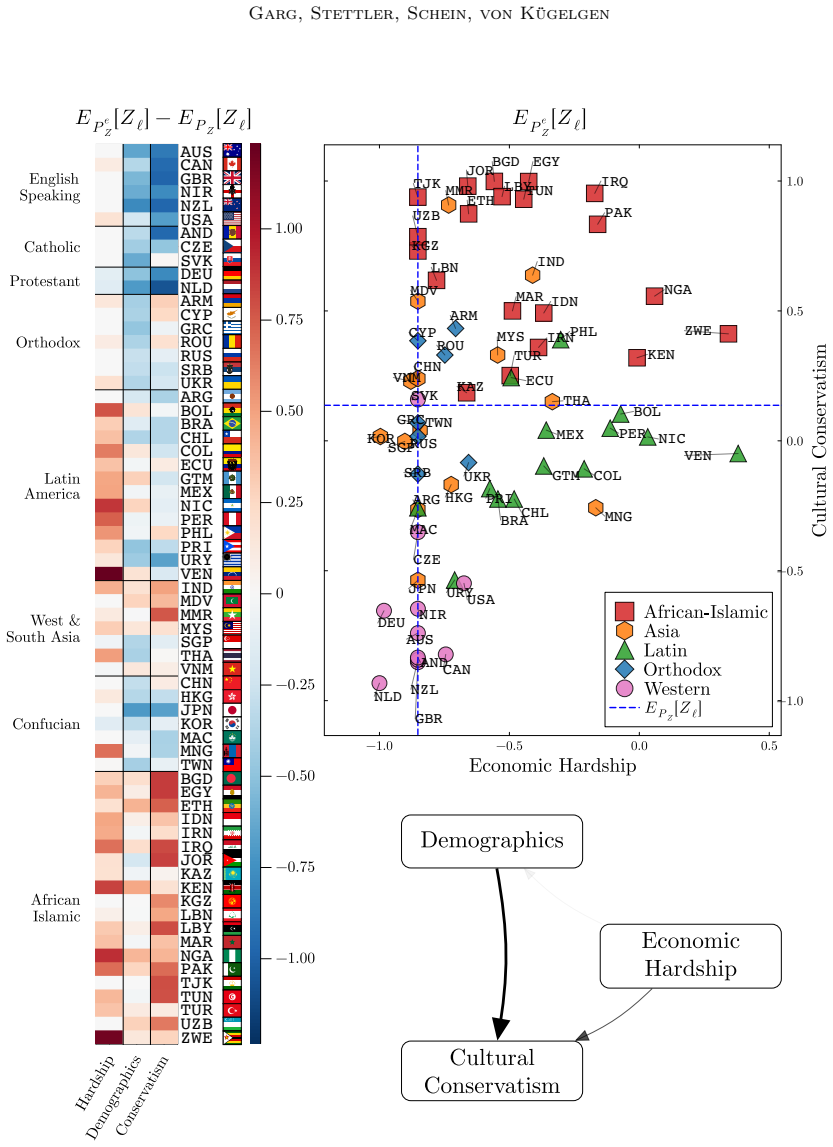
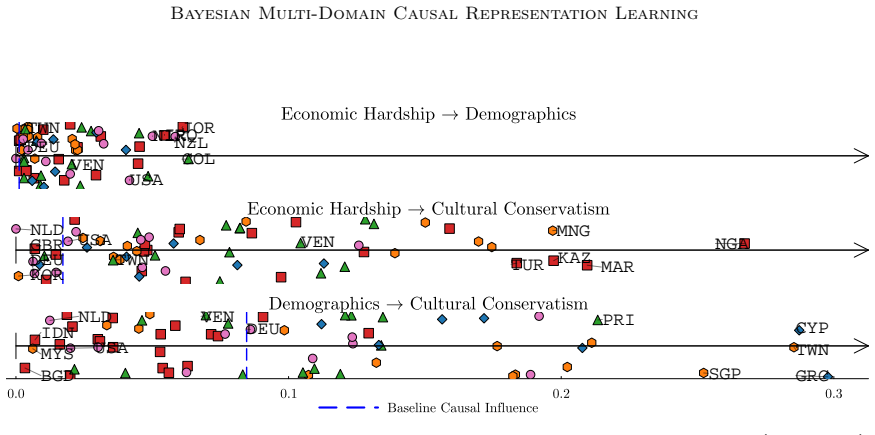
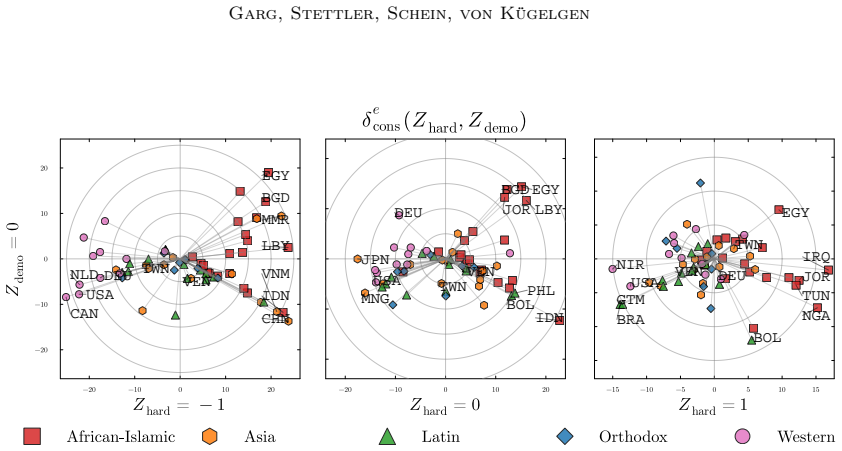
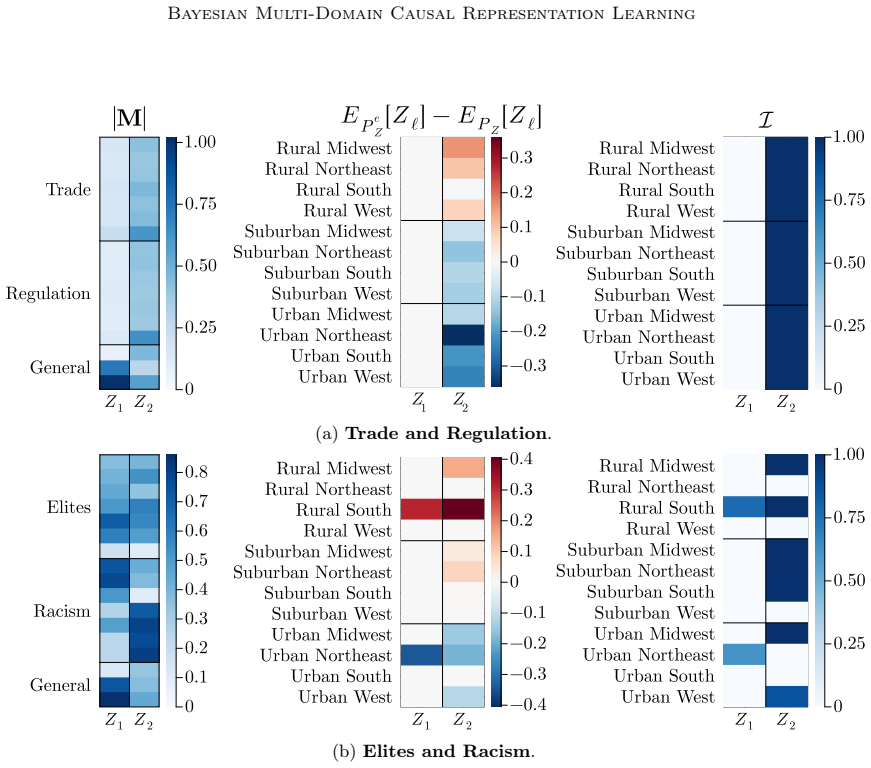
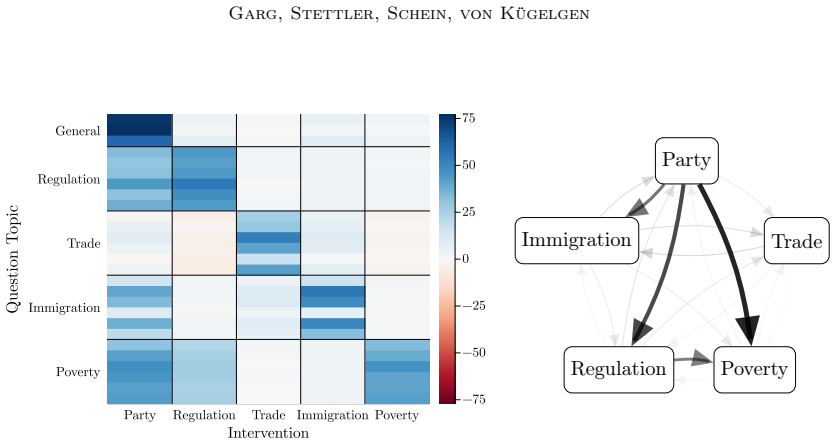
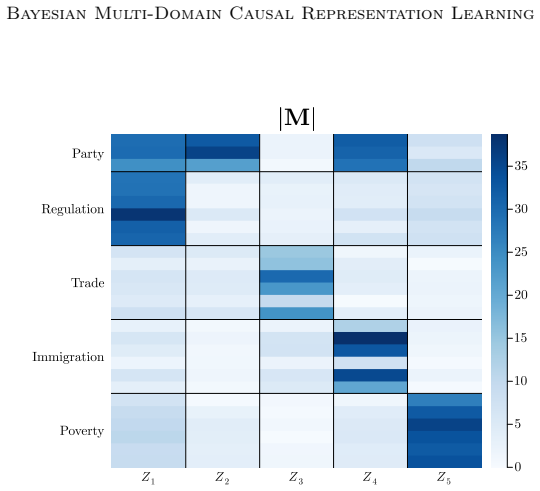
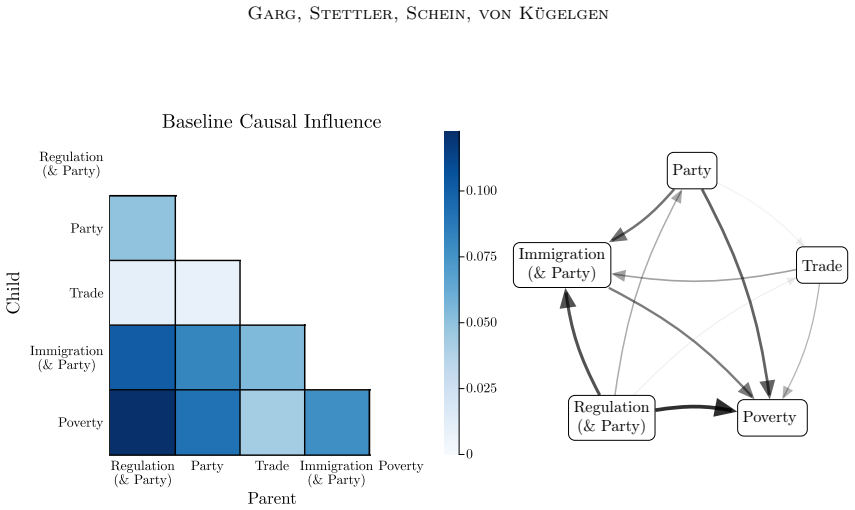
- Application to social surveys yields concepts that correspond to cultural values or opinions and relations that are consistent with domain knowledge.
Where Pith is reading between the lines
- The same encoding of assumptions into priors could be tested on other heterogeneous data sources such as economic indicators collected across regions.
- If the SMC approximation proves reliable, the method supplies a practical way to add causal structure to representation learning pipelines that must handle distribution shift.
- Synthetic benchmarks with known interventions would allow direct measurement of how often the posterior places mass on the true concept graph.
Load-bearing premise
Causal assumptions and interpretability needs can be translated into priors and parametric choices that support valid posterior inference via SMC.
What would settle it
A simulation in which the recovered concepts and relations systematically fail to match the known ground-truth structure used to generate the multi-environment data.
Figures

read the original abstract
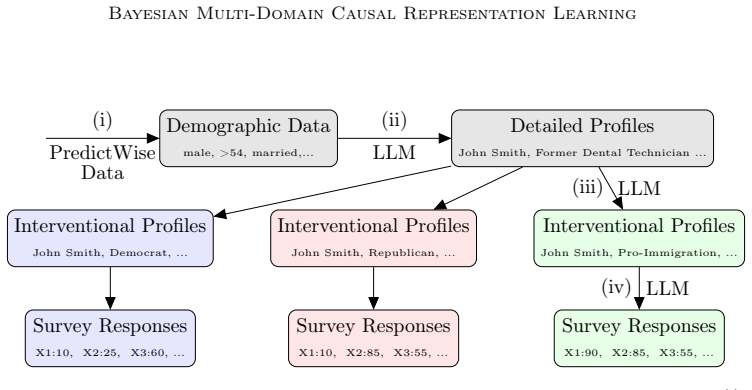
Causal representation learning aims to infer the high-level latent causal concepts that give rise to observed low-level measurements. This is particularly relevant for heterogeneous data from different environments or domains since distribution shifts often arise through sparse, localized changes in some of the underlying causal mechanisms, while other parts of the generative process remain unchanged. Whereas identifiability of causal representations has been studied extensively, practical uncertainty-aware methods and real-world use cases remain less explored. In this work, we propose a Bayesian approach to learning causal representations from multi-environment data, focusing on the case of discrete causal concepts and unknown multi-node soft interventions. To this end, we translate causal assumptions and interpretability desiderata into suitable priors and parametric choices within a hierarchical model. We then devise an inference scheme based on sequential Monte Carlo sampling to approximate the resulting multimodal posterior. We showcase our approach through case studies on social survey data, where latent causal concepts correspond to cultural values or political opinions, measurements to survey responses, and environments to different countries or states. Our model infers meaningful high-level concepts and plausible causal relations among them, demonstrating its utility for learning causal representations of complex real-world data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bayesian hierarchical model for causal representation learning from heterogeneous multi-environment data, with a focus on discrete latent causal concepts and unknown multi-node soft interventions. Causal assumptions and interpretability goals are encoded via priors and parametric choices; posterior inference is performed with sequential Monte Carlo (SMC); the approach is demonstrated on social survey data where environments correspond to countries or states, measurements to responses, and latents to cultural or political concepts.
Significance. If the SMC procedure reliably recovers posterior modes that correspond to stable, interpretable causal concepts, the work would supply a practical uncertainty-aware method for causal representation learning on real heterogeneous data, addressing a noted gap between identifiability theory and applied use cases in the social sciences.
major comments (1)
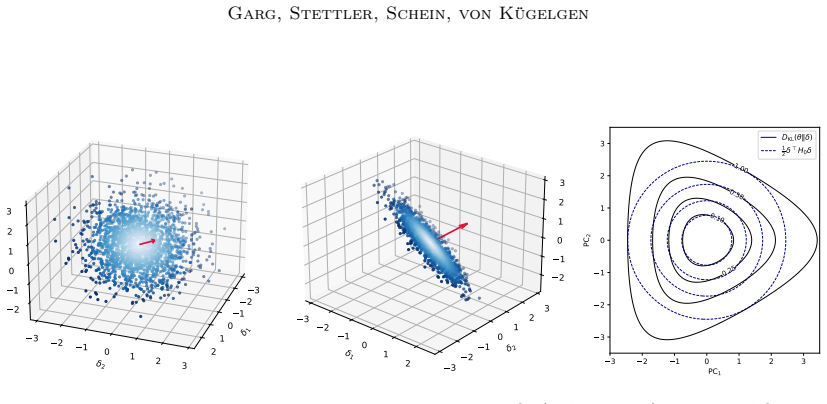
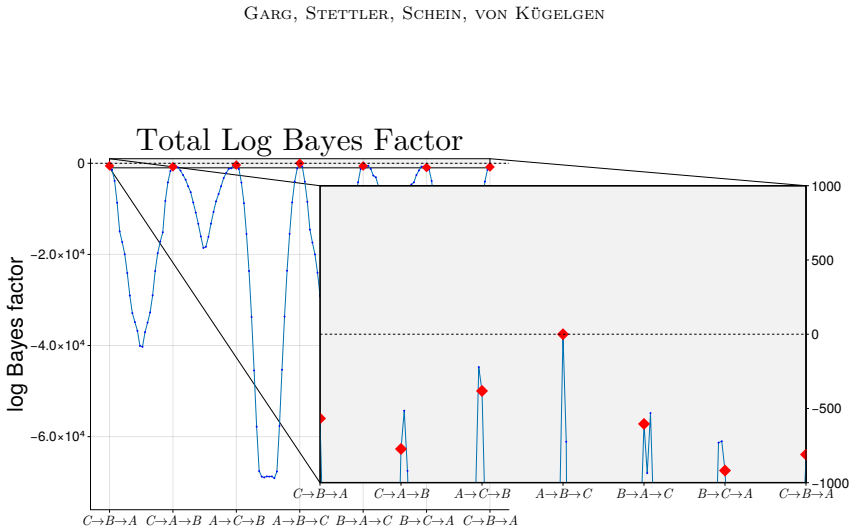
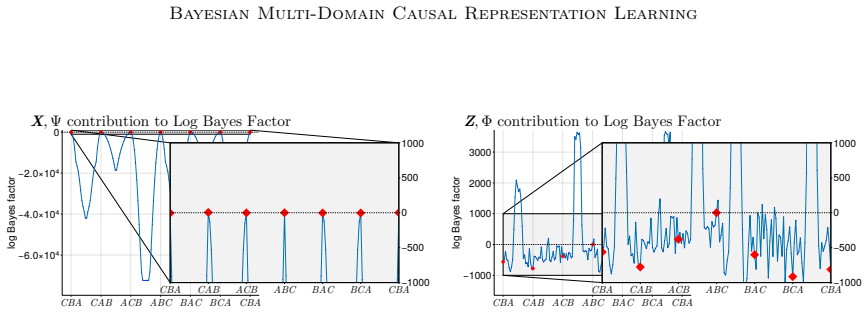
- [Inference scheme] Inference section: the central claim that the model infers meaningful high-level concepts and plausible causal relations rests on SMC recovering the modes of a combinatorial, highly multimodal posterior over discrete concepts and unknown multi-node soft interventions. No effective-sample-size diagnostics, tempering schedules, or small-scale exact-enumeration comparisons are reported, leaving open the possibility that reported concepts are sampler artifacts rather than posterior features.
minor comments (1)
- [Abstract] Abstract: the description of the modeling choices and inference scheme contains no equations, making it impossible to verify whether the hierarchical construction actually supports the claimed identifiability or posterior properties without the full text.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Inference scheme] Inference section: the central claim that the model infers meaningful high-level concepts and plausible causal relations rests on SMC recovering the modes of a combinatorial, highly multimodal posterior over discrete concepts and unknown multi-node soft interventions. No effective-sample-size diagnostics, tempering schedules, or small-scale exact-enumeration comparisons are reported, leaving open the possibility that reported concepts are sampler artifacts rather than posterior features.
Authors: We agree that the absence of these diagnostics leaves the reliability of the reported modes open to question. In the revised manuscript we will add effective-sample-size diagnostics for the SMC runs on the social-survey data, a description of the tempering schedule, and small-scale synthetic experiments in which the posterior can be enumerated exactly, thereby confirming that the sampler recovers the relevant modes rather than artifacts. revision: yes
Circularity Check
No significant circularity; derivation is a standard Bayesian modeling and inference pipeline
full rationale
The paper translates causal assumptions into priors within a hierarchical model and approximates the posterior via SMC. No equations or steps in the abstract reduce a claimed prediction or result to fitted inputs by construction, nor do they rely on self-citations for uniqueness or load-bearing premises. The central claim of inferring concepts is an application of the model to data rather than a tautological renaming or self-definition. The derivation chain is self-contained against external benchmarks of Bayesian causal representation learning.
Axiom & Free-Parameter Ledger
free parameters (1)
- prior hyperparameters
axioms (1)
- domain assumption Causal assumptions and interpretability desiderata can be translated into suitable priors and parametric choices
invented entities (1)
-
discrete causal concepts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adams, N
J. Adams, N. Hansen, and K. Zhang. Identification of partially observed linear causal models: Graphical conditions for the non-gaussian and heterogeneous cases. In Advances in Neural Information Processing Systems, volume 34, pages 22822--22833, 2021
2021
-
[2]
Agrawal, C
R. Agrawal, C. Squires, K. Yang, K. Shanmugam, and C. Uhler. Abcd-strategy: Budgeted experimental design for targeted causal structure discovery. In International Conference on Artificial Intelligence and Statistics, volume 89, pages 3400--3409. PMLR, 2019
2019
-
[3]
Ahuja, J
K. Ahuja, J. Hartford, and Y. Bengio. Properties from mechanisms: an equivariance perspective on identifiable representation learning. In International Conference on Learning Representations, 2021
2021
-
[4]
Ahuja, D
K. Ahuja, D. Mahajan, Y. Wang, and Y. Bengio. Interventional causal representation learning. In International conference on machine learning, pages 372--407. PMLR, 2023
2023
-
[5]
Ahuja, A
K. Ahuja, A. Mansouri, and Y. Wang. Multi-domain causal representation learning via weak distributional invariances. In International Conference on Artificial Intelligence and Statistics, pages 865--873. PMLR, 2024
2024
-
[6]
E. M. Airoldi, D. Blei, E. A. Erosheva, and S. E. Fienberg. Handbook of mixed membership models and their applications. Chapman & Hall/CRC, 1st edition, 2014
2014
-
[7]
J. H. Albert and S. Chib. B ayesian analysis of binary and polychotomous response data. Journal of the American Statistical Association, 88 0 (422): 0 669--679, 1993
1993
-
[8]
J. D. Angrist and J.-S. Pischke. Mostly harmless econometrics: An empiricist's companion . Princeton University Press, 2009
2009
-
[9]
L. P. Argyle, E. C. Busby, N. Fulda, J. R. Gubler, C. Rytting, and D. Wingate. Out of one, many: Using language models to simulate human samples. Political Analysis, 31 0 (3): 0 337--351, 2023
2023
-
[10]
Bareinboim and J
E. Bareinboim and J. Pearl. Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences, 113 0 (27): 0 7345--7352, 2016
2016
-
[11]
Y. Bengio, N. L \'e onard, and A. Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432, 2013
Pith/arXiv arXiv 2013
-
[12]
S. Bing, U. Ninad, J. Wahl, and J. Runge. Identifying linearly-mixed causal representations from multi-node interventions. In Conference on Causal Learning and Reasoning, pages 843--867. PMLR, 2024
2024
-
[13]
D. M. Blei. Build, compute, critique, repeat: Data analysis with latent variable models. Annual Review of Statistics and Its Application, 1 0 (1): 0 203--232, 2014
2014
-
[14]
D. M. Blei, A. Kucukelbir, and J. D. McAuliffe. Variational inference: A review for statisticians. Journal of the American Statistical Association, 112 0 (518): 0 859--877, 2017
2017
-
[15]
Brehmer, P
J. Brehmer, P. De Haan, P. Lippe, and T. Cohen. Weakly supervised causal representation learning. In Advances in Neural Information Processing Systems, 2022
2022
-
[16]
Brouillard, S
P. Brouillard, S. Lachapelle, A. Lacoste, S. Lacoste-Julien, and A. Drouin. Differentiable Causal Discovery from Interventional Data . In Advances in Neural Information Processing Systems, volume 33, pages 21865--21877, 2020
2020
-
[17]
Buchholz, G
S. Buchholz, G. Rajendran, E. Rosenfeld, B. Aragam, B. Sch \"o lkopf, and P. Ravikumar. Learning linear causal representations from interventions under general nonlinear mixing. In Advances in Neural Information Processing Systems, 2023
2023
-
[18]
R. Cai, F. Xie, C. Glymour, Z. Hao, and K. Zhang. Triad constraints for learning causal structure of latent variables. In Advances in Neural Information Processing Systems, volume 32, 2019
2019
-
[19]
C. L. Canonne, I. Diakonikolas, D. M. Kane, and A. Stewart. Testing conditional independence of discrete distributions. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, pages 735--748, 2018
2018
-
[20]
J. Chen, J. Zhu, Z. Wang, X. Zheng, and B. Zhang. Scalable inference for logistic-normal topic models. In C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, editors, Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013
2013
-
[21]
Chevalley, P
M. Chevalley, P. Schwab, and A. Mehrjou. Deriving causal order from single-variable interventions: Guarantees & algorithm. In International Conference on Learning Representations, volume 2025, pages 48992--49017, 2025
2025
-
[22]
S. Chib. Marginal likelihood from the gibbs output. Journal of the American Statistical Association, 90 0 (432): 0 1313--1321, 1995
1995
-
[23]
T. M. Cover and J. A. Thomas. Elements of information theory. Wiley-Interscience, Hoboken, N.J, 2nd ed edition, 2006. ISBN 978-0-471-24195-9
2006
-
[24]
C. Dai, J. Heng, P. E. Jacob, and N. Whiteley. An invitation to sequential monte carlo samplers. Journal of the American Statistical Association, 117 0 (539): 0 1587--1600, 2022
2022
-
[25]
H. Dai, Y. Qiu, I. Ng, X. Dong, P. Spirtes, and K. Zhang. Latent variable causal discovery under selection bias. In International Conference on Machine Learning, pages 12161--12178. PMLR, 2025
2025
-
[26]
Daunhawer, A
I. Daunhawer, A. Bizeul, E. Palumbo, A. Marx, and J. E. Vogt. Identifiability results for multimodal contrastive learning. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[27]
Del Moral, A
P. Del Moral, A. Doucet, and A. Jasra. Sequential monte carlo samplers. Journal of the Royal Statistical Society Series B: Statistical Methodology, 68 0 (3): 0 411--436, 2006
2006
-
[28]
D. Durante. Conjugate bayes for probit regression via unified skew-normal distributions. Biometrika, 106 0 (4): 0 765--779, 2019
2019
-
[29]
u gelgen, H. Hassani, G. J. Pappas, and B. Sch \
C. Eastwood, A. Robey, S. Singh, J. Von K \"u gelgen, H. Hassani, G. J. Pappas, and B. Sch \"o lkopf. Probable domain generalization via quantile risk minimization. In Advances in Neural Information Processing Systems, 2022
2022
-
[30]
Eberhardt, C
F. Eberhardt, C. Glymour, and R. Scheines. On the number of experiments sufficient and in the worst case necessary to identify all causal relations among n variables. In Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence, pages 178--184, 2005
2005
-
[31]
Friedman and D
N. Friedman and D. Koller. Being B ayesian about network structure. a B ayesian approach to structure discovery in B ayesian networks. Machine learning, 50 0 (1): 0 95--125, 2003
2003
-
[32]
Gelman, J
A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, and D. B. Rubin. B ayesian Data Analysis . Chapman & Hall/CRC Texts in Statistical Science Series. CRC, third edition, 2013. ISBN 9781439840955 1439840954
2013
-
[33]
Gelman, J
A. Gelman, J. Hwang, and A. Vehtari. Understanding predictive information criteria for bayesian models. Statistics and computing, 24 0 (6): 0 997--1016, 2014
2014
-
[34]
C. J. Geyer. Markov chain monte carlo maximum likelihood. In Computing Science and Statistics: Proceedings of the 23rd Symposium on the Interface, pages 156--163. Interface Foundation of North America, 1991
1991
-
[35]
D. P. Green, B. Palmquist, and E. Schickler. Partisan hearts and minds: Political parties and the social identities of voters. Yale University Press, 2002
2002
-
[36]
Haerpfer, R
C. Haerpfer, R. Inglehart, A. Moreno, C. Welzel, K. Kizilova, J. Diez-Medrano, M. Lagos, P. Norris, E. Ponarin, B. Puranen, et al. World values survey: Round seven-country-pooled datafile version 5.0, 2022
2022
-
[37]
a gele, J. Rothfuss, L. Lorch, V. R. Somnath, B. Sch \
A. H \"a gele, J. Rothfuss, L. Lorch, V. R. Somnath, B. Sch \"o lkopf, and A. Krause. Bacadi: B ayesian causal discovery with unknown interventions. In International Conference on Artificial Intelligence and Statistics, pages 1411--1436. PMLR, 2023
2023
-
[38]
Hauser and P
A. Hauser and P. B \"u hlmann. Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs. The Journal of Machine Learning Research, 13 0 (1): 0 2409--2464, 2012
2012
-
[39]
Hauser and P
A. Hauser and P. B \"u hlmann. Jointly interventional and observational data: estimation of interventional M arkov equivalence classes of directed acyclic graphs. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 77 0 (1): 0 291--318, 2015
2015
-
[40]
Heckerman, D
D. Heckerman, D. Geiger, and D. M. Chickering. Learning B ayesian networks: The combination of knowledge and statistical data. Machine learning, 20 0 (3): 0 197--243, 1995
1995
-
[41]
Heckerman, C
D. Heckerman, C. Meek, and G. Cooper. A B ayesian approach to causal discovery. In Innovations in Machine Learning: Theory and Applications, pages 1--28. Springer, 2006
2006
-
[42]
Heinze-Deml, J
C. Heinze-Deml, J. Peters, and N. Meinshausen. Invariant causal prediction for nonlinear models. Journal of Causal Inference, 6 0 (2), 2018
2018
-
[43]
M. A. Hern\'an and J. M. Robins. Causal inference: What if . Boca Raton: Chapman & Hall/CRC., 2020
2020
-
[44]
Huang, C
B. Huang, C. J. H. Low, F. Xie, C. Glymour, and K. Zhang. Latent hierarchical causal structure discovery with rank constraints. In Advances in Neural Information Processing Systems, volume 35, pages 5549--5561, 2022
2022
-
[45]
Hyv \"a rinen and H
A. Hyv \"a rinen and H. Morioka. Unsupervised feature extraction by time-contrastive learning and nonlinear ica. In Advances in Neural Information Processing Systems, pages 3765--3773, 2016
2016
-
[46]
Hyv \"a rinen and H
A. Hyv \"a rinen and H. Morioka. Nonlinear ICA of temporally dependent stationary sources. In International Conference on Artificial Intelligence and Statistics, pages 460--469. PMLR, 2017
2017
-
[47]
Hyv \"a rinen and P
A. Hyv \"a rinen and P. Pajunen. Nonlinear independent component analysis: Existence and uniqueness results. Neural networks, 12 0 (3): 0 429--439, 1999
1999
-
[48]
Hyv \"a rinen, H
A. Hyv \"a rinen, H. Sasaki, and R. Turner. Nonlinear ICA using auxiliary variables and generalized contrastive learning. In International Conference on Artificial Intelligence and Statistics, pages 859--868, 2019
2019
-
[49]
G. W. Imbens and D. B. Rubin. Causal inference in statistics, social, and biomedical sciences . Cambridge University Press, 2015
2015
-
[50]
Inglehart, C
R. Inglehart, C. Haerpfer, A. Moreno, C. Welzel, K. Kizilova, J. Diez-Medrano, M. Lagos, P. Norris, E. Ponarin, B. Puranen, et al. World values survey, 2005
2005
-
[51]
Jaber, M
A. Jaber, M. Kocaoglu, K. Shanmugam, and E. Bareinboim. Causal discovery from soft interventions with unknown targets: Characterization and learning. In Advances in Neural Information Processing Systems, volume 33, pages 9551--9561, 2020
2020
-
[52]
Janzing, D
D. Janzing, D. Balduzzi, M. Grosse-Wentrup, and B. Sch \"o lkopf. Quantifying causal influences. The Annals of Statistics, 41 0 (5): 0 2324--2358, 2013
2013
-
[53]
Jasra, C
A. Jasra, C. Holmes, and D. Stephens. Markov chain monte carlo methods and the label switching problem in B ayesian mixture modeling. Statistical Science, 20 0 (1): 0 50--67, 2005
2005
-
[54]
Jiang and J
Z. Jiang and J. Templin. Gibbs samplers for logistic item response models via the p \'o lya--gamma distribution: A computationally efficient data-augmentation strategy. Psychometrika, 84 0 (2): 0 358--374, 2019
2019
-
[55]
Khemakhem, D
I. Khemakhem, D. Kingma, R. Monti, and A. Hyvarinen. Variational autoencoders and nonlinear ica: A unifying framework. In International Conference on Artificial Intelligence and Statistics, pages 2207--2217, 2020
2020
-
[56]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015. URL https://arxiv.org/abs/1412.6980
Pith/arXiv arXiv 2015
-
[57]
Kitagawa
G. Kitagawa. Monte carlo filter and smoother for non-gaussian nonlinear state space models. Journal of Computational and Graphical Statistics, 5 0 (1): 0 1--25, 1996
1996
-
[58]
Kivva, G
B. Kivva, G. Rajendran, P. Ravikumar, and B. Aragam. Learning latent causal graphs via mixture oracles. In Advances in Neural Information Processing Systems, volume 34, pages 18087--18101, 2021
2021
-
[59]
Krueger, E
D. Krueger, E. Caballero, J.-H. Jacobsen, A. Zhang, J. Binas, D. Zhang, R. Le Priol, and A. Courville. Out-of-distribution generalization via risk extrapolation (rex). In International Conference on Machine Learning, pages 5815--5826. PMLR, 2021
2021
-
[60]
S. Lachapelle, P. R. L \'o pez, Y. Sharma, K. Everett, R. L. Priol, A. Lacoste, and S. Lacoste-Julien. Nonparametric partial disentanglement via mechanism sparsity: Sparse actions, interventions and sparse temporal dependencies. arXiv preprint arXiv:2401.04890, 2024
arXiv 2024
-
[61]
E. Lehmann and J. P. Romano. Testing Statistical Hypotheses. Springer Texts in Statistics. Springer International Publishing, Cham, 2022. ISBN 978-3-030-70577-0. doi:10.1007/978-3-030-70578-7. URL https://link.springer.com/10.1007/978-3-030-70578-7
-
[62]
J. Li, R. Gibbons, and V. Ro c kov \'a . Sparse B ayesian multidimensional item response theory. Journal of the American Statistical Association, 120 0 (552): 0 2592--2605, 2025
2025
-
[63]
Lippe, S
P. Lippe, S. Magliacane, S. L \"o we, Y. M. Asano, T. Cohen, and E. Gavves. Causal representation learning for instantaneous and temporal effects in interactive systems. In International Conference on Learning Representations, 2022 a
2022
-
[64]
Lippe, S
P. Lippe, S. Magliacane, S. L \"o we, Y. M. Asano, T. Cohen, and S. Gavves. Citris: Causal identifiability from temporal intervened sequences. In International Conference on Machine Learning, pages 13557--13603. PMLR, 2022 b
2022
-
[65]
Locatello, S
F. Locatello, S. Bauer, M. Lucic, G. Raetsch, S. Gelly, B. Sch \"o lkopf, and O. Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. In International Conference on Machine Learning, pages 4114--4124. PMLR, 2019
2019
-
[66]
Lorch, J
L. Lorch, J. Rothfuss, B. Sch \"o lkopf, and A. Krause. DiBS : Differentiable B ayesian structure learning. In Advances in Neural Information Processing Systems, volume 34, pages 24111--24123, 2021
2021
-
[67]
F. M. Lord. Applications of item response theory to practical testing problems. Routledge, 1980
1980
-
[68]
C. J. Maddison, A. Mnih, and Y. W. Teh. The concrete distribution: A continuous relaxation of discrete random variables. arXiv preprint arXiv:1611.00712, 2016
Pith/arXiv arXiv 2016
-
[69]
Marinari and G
E. Marinari and G. Parisi. Simulated tempering: a new monte carlo scheme. EPL (Europhysics Letters), 19 0 (6): 0 451--458, 1992
1992
-
[70]
Mason and J
L. Mason and J. Wronski. One tribe to bind them all: How our social group attachments strengthen partisanship. Political Psychology, 39: 0 257--277, 2018
2018
-
[71]
Moran and B
G. Moran and B. Aragam. Towards interpretable deep generative models via causal representation learning. Journal of the American Statistical Association, pages 1--32, 2026
2026
-
[72]
S. L. Morgan and C. Winship. Counterfactuals and Causal Inference: Methods and Principles for Social Research . Cambridge University Press, 2014
2014
-
[73]
K. P. Murphy. Active learning of causal B ayes net structure. Technical report, Department of Computer Science, U.C. Berkeley, 2001
2001
-
[74]
R. M. Neal. Sampling from multimodal distributions using tempered transitions. Statistics and computing, 6 0 (4): 0 353--366, 1996
1996
-
[75]
R. O. Ness, K. Sachs, P. Mallick, and O. Vitek. A bayesian active learning experimental design for inferring signaling networks. Journal of Computational Biology, 25 0 (7): 0 709--725, 2018
2018
-
[76]
Neykov, S
M. Neykov, S. Balakrishnan, and L. Wasserman. Minimax optimal conditional independence testing. The Annals of Statistics, 49 0 (4): 0 2151--2177, 2021
2021
-
[77]
J. Neyman. Sur les applications de la th \'e orie des probabilit \'e s aux experiences agricoles: Essai des principes. Roczniki Nauk Rolniczych, 10 0 (1): 0 1--51, 1923
1923
-
[78]
J. Pearl. Causality: Models, Reasoning, and Inference. Cambridge University Press, New York, NY, 2nd edition, 2009
2009
-
[79]
u gelgen, and B. Sch \
R. Perry, J. Von K \"u gelgen, and B. Sch \"o lkopf. Causal discovery in heterogeneous environments under the sparse mechanism shift hypothesis. In Advances in Neural Information Processing Systems, volume 35, pages 10904--10917, 2022
2022
-
[80]
Peters, P
J. Peters, P. B \"u hlmann, and N. Meinshausen. Causal inference by using invariant prediction: identification and confidence intervals. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 78 0 (5): 0 947--1012, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.