Place recognition in gardens by learning visual representations: data set and benchmark analysis
Pith reviewed 2026-05-25 13:47 UTC · model grok-4.3
The pith
Learning garden-tailored representations improves place recognition performance within garden environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
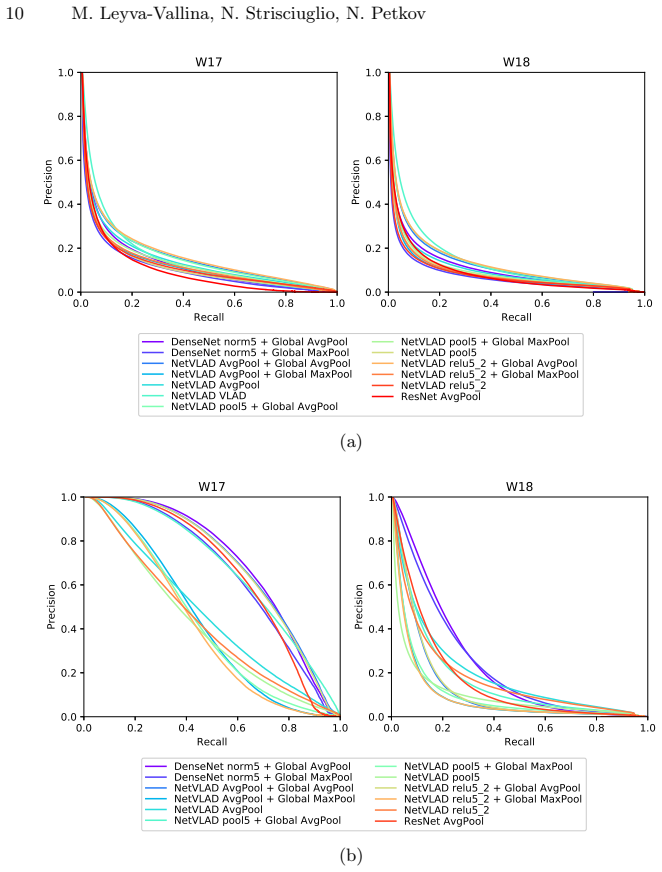
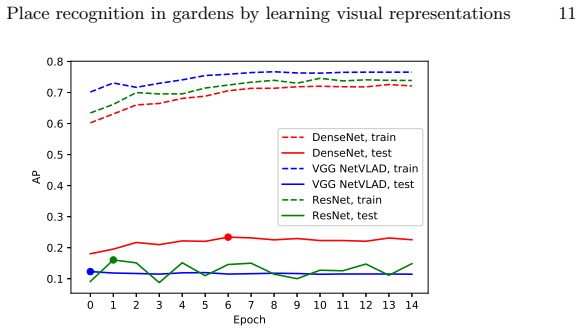
Training existing convolutional networks on the extended TB-Places garden dataset with pairwise place labels produces holistic image descriptors that raise place recognition accuracy in garden scenes relative to off-the-shelf networks, although the resulting representations exhibit limited generalization beyond the training conditions.
What carries the argument
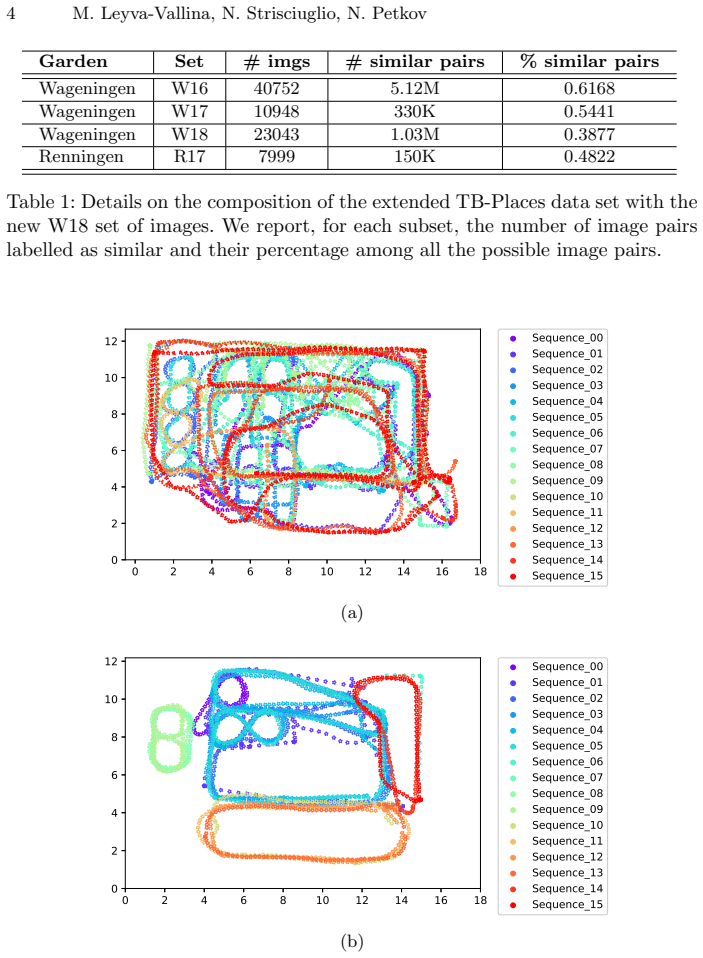
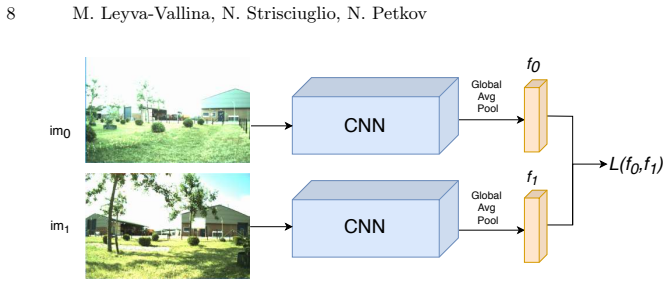
The extended TB-Places dataset supplying ground truth for all image pairs, used to train a two-way CNN architecture with contrastive loss for garden-specific holistic descriptors.
If this is right
- Garden-specific training raises matching accuracy for places within garden scenes compared with standard pre-trained networks.
- Including seasonal and lighting variations in the training data supports the observed performance gains.
- The same two-way contrastive architecture works with multiple backbones such as ResNet, DenseNet and VGG NetVLAD.
- Generalization across different garden collections remains limited.
Where Pith is reading between the lines
- The same dataset-extension and fine-tuning strategy could be applied to other repetitive natural scenes such as orchards or fields.
- Hybrid systems that combine garden-specific visual features with additional sensors might reduce the observed generalization limits.
- Controlled experiments that isolate layout versus lighting variations could clarify the source of limited cross-garden transfer.
Load-bearing premise
The collected garden images and their pairwise labels capture the visual challenges of real gardens without overfitting to the particular sites and collection times.
What would settle it
Evaluation of the trained models on an independent collection of garden images from new locations and seasons shows no accuracy gain over general-purpose networks.
Figures


read the original abstract
Visual place recognition is an important component of systems for camera localization and loop closure detection. It concerns the recognition of a previously visited place based on visual cues only. Although it is a widely studied problem for indoor and urban environments, the recent use of robots for automation of agricultural and gardening tasks has created new problems, due to the challenging appearance of garden-like environments. Garden scenes predominantly contain green colors, as well as repetitive patterns and textures. The lack of available data recorded in gardens and natural environments makes the improvement of visual localization algorithms difficult. In this paper we propose an extended version of the TB-Places data set, which is designed for testing algorithms for visual place recognition. It contains images with ground truth camera pose recorded in real gardens in different seasons, with varying light conditions. We constructed and released a ground truth for all possible pairs of images, indicating whether they depict the same place or not. We present the results of a benchmark analysis of methods based on convolutional neural networks for holistic image description and place recognition. We train existing networks (i.e. ResNet, DenseNet and VGG NetVLAD) as backbone of a two-way architecture with a contrastive loss function. The results that we obtained demonstrate that learning garden-tailored representations contribute to an improvement of performance, although the generalization capabilities are limited.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the TB-Places dataset with images recorded in real gardens across seasons and lighting conditions, releases exhaustive ground-truth labels for all image pairs indicating whether they depict the same place, and benchmarks CNN backbones (ResNet, DenseNet, VGG NetVLAD) inside a two-way contrastive architecture. It claims that training garden-tailored representations yields performance gains for visual place recognition, while noting that generalization capabilities remain limited.
Significance. Release of a garden-specific dataset with complete pair-wise ground truth fills a documented gap for agricultural robotics applications. If the reported gains can be shown to arise from transferable domain features rather than site-specific memorization, the benchmark would supply useful empirical guidance on the value of tailored holistic descriptors in repetitive green textures.
major comments (2)
- Abstract: the central claim that garden-tailored training improves performance is stated without any quantitative metrics, baseline comparisons, or error analysis, leaving the magnitude and reliability of the improvement unverifiable from the provided text.
- Benchmark analysis / Experiments: the evaluation protocol does not describe a cross-garden or leave-one-garden-out train/test split; without such isolation, observed gains cannot be distinguished from overfitting to the finite set of recorded sites, cameras, paths, or collection conditions, which directly undermines the claim that the improvement reflects domain tailoring rather than memorization.
minor comments (2)
- Abstract and methods: contrastive-loss hyperparameters, learning-rate schedules, data-augmentation choices, and exact training protocol are not reported, hindering reproducibility.
- Dataset description: while pair-wise ground truth is released, the manuscript does not state how seasonal or viewpoint variation is balanced across any proposed splits.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of quantitative results and to better isolate domain-specific effects in the evaluation. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: Abstract: the central claim that garden-tailored training improves performance is stated without any quantitative metrics, baseline comparisons, or error analysis, leaving the magnitude and reliability of the improvement unverifiable from the provided text.
Authors: We agree that the abstract would be strengthened by including concrete metrics. In the revised manuscript we will update the abstract to report specific quantitative improvements (e.g., recall@1 or mAP gains of the garden-trained models relative to the pre-trained baselines) together with a brief reference to the observed error patterns. revision: yes
-
Referee: Benchmark analysis / Experiments: the evaluation protocol does not describe a cross-garden or leave-one-garden-out train/test split; without such isolation, observed gains cannot be distinguished from overfitting to the finite set of recorded sites, cameras, paths, or collection conditions, which directly undermines the claim that the improvement reflects domain tailoring rather than memorization.
Authors: The current experiments employ a standard random train/test split across the collected garden imagery. We acknowledge that this does not explicitly isolate performance across distinct gardens and therefore cannot fully rule out site-specific effects. To address the concern we will add a leave-one-garden-out evaluation protocol and report the corresponding results in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark on new dataset with no self-referential derivations
full rationale
The paper extends the TB-Places dataset with garden images across seasons, constructs ground-truth image pairs, and benchmarks CNN backbones (ResNet, DenseNet, VGG NetVLAD) trained via contrastive loss for place recognition. The central claim is an empirical observation that garden-tailored training improves performance with limited generalization. No equations, predictions, or uniqueness theorems are present. No self-citation chains, fitted parameters renamed as predictions, or ansatzes smuggled via prior work. All results are direct performance metrics on the released pairs; the derivation chain is self-contained data collection plus standard supervised training. This is the expected non-finding for a benchmark paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive loss hyperparameters
axioms (1)
- domain assumption Convolutional neural networks can extract useful visual representations from image data when trained with contrastive loss
Reference graph
Works this paper leans on
-
[1]
Netvlad: Cnn architecture for weakly supervised place recognition
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InIEEE CVPR, pages 5297–5307, 2016
work page 2016
-
[2]
Harvesting robots for high-value crops: State-of-the-art review and challenges ahead
C Wouter Bac, Eldert J van Henten, Jochen Hemming, and Yael Edan. Harvesting robots for high-value crops: State-of-the-art review and challenges ahead. Journal of Field Robotics , 31(6):888–911, 2014
work page 2014
-
[3]
Visual topometric localization
Hern´ an Badino, D Huber, and Takeo Kanade. Visual topometric localization. In Intelligent Vehicles Symposium (IV), 2011 IEEE , pages 794–799, 2011
work page 2011
-
[4]
Fab-map: Probabilistic localization and map- ping in the space of appearance
Mark Cummins and Paul Newman. Fab-map: Probabilistic localization and map- ping in the space of appearance. Int. J. Rob. Res. , 27(6):647–665, 2008
work page 2008
-
[5]
Highly scalable appearance-only slam-fab-map 2.0
Mark Cummins and Paul Newman. Highly scalable appearance-only slam-fab-map 2.0. In Robotics: Science and Systems , volume 5, page 17, 2009
work page 2009
-
[6]
Vision meets robotics: The kitti dataset
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. Int. J. Rob. Res. , 32(11):1231–1237, 2013
work page 2013
-
[7]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE CVPR , pages 770–778, 2016. 12 M. Leyva-Vallina, N. Strisciuglio, N. Petkov
work page 2016
-
[8]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In IEEE CVPR , pages 4700–4708, 2017
work page 2017
-
[9]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, pages 1097–1105, 2012
work page 2012
-
[10]
Tb-places: a data set for visual place recognition in garden environments
Mar´ ıa Leyva-Vallina, Nicola Strisciuglio, Manuel L´ opez-Antequera, Radim Tyle- cek, Michael Blaich, and Nicolai Petkov. Tb-places: a data set for visual place recognition in garden environments. IEEE Access, 2019
work page 2019
-
[11]
Appearance-invariant place recognition by discriminatively training a convolutional neural network
Manuel Lopez-Antequera, Ruben Gomez-Ojeda, Nicolai Petkov, and Javier Gonzalez-Jimenez. Appearance-invariant place recognition by discriminatively training a convolutional neural network. Pattern Recognit. Lett., 92:89–95, 2017
work page 2017
-
[12]
Visual place recognition: A survey
Stephanie Lowry, Niko S¨ underhauf, Paul Newman, John J Leonard, David Cox, Peter Corke, and Michael J Milford. Visual place recognition: A survey. IEEE Transactions on Robotics, 32(1):1–19, 2016
work page 2016
-
[13]
Colin McManus, Winston Churchill, Will Maddern, Alexander D. Stewart, and Paul Newman. Shady dealings: Robust, long-term visual localisation using illumi- nation invariance. In IEEE ICRA , pages 901–906, 2014
work page 2014
-
[14]
Seqslam: Visual route-based navigation for sunny summer days and stormy winter nights
Michael J Milford and Gordon F Wyeth. Seqslam: Visual route-based navigation for sunny summer days and stormy winter nights. InIEEE ICRA, pages 1643–1649, 2012
work page 2012
-
[15]
Design of an autonomous precision pollination robot
Nicholas Ohi, Kyle Lassak, Ryan Watson, Jared Strader, Yixin Du, Chizhao Yang, Gabrielle Hedrick, Jennifer Nguyen, Scott Harper, Dylan Reynolds, et al. Design of an autonomous precision pollination robot. In IEEE IROS , 2018
work page 2018
-
[16]
Benchmarking 6dof outdoor visual localization in changing conditions
Torsten Sattler, Will Maddern, Carl Toft, Akihiko Torii, Lars Hammarstrand, Erik Stenborg, Daniel Safari, Masatoshi Okutomi, Marc Pollefeys, Josef Sivic, et al. Benchmarking 6dof outdoor visual localization in changing conditions. In IEEE CVPR, volume 1, 2018
work page 2018
-
[17]
Image retrieval for image-based localization revisited
Torsten Sattler, Tobias Weyand, Bastian Leibe, and Leif Kobbelt. Image retrieval for image-based localization revisited. In BMVC, volume 1, page 4, 2012
work page 2012
-
[18]
Scene coordinate regression forests for camera relocaliza- tion in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocaliza- tion in rgb-d images. In IEEE CVPR , pages 2930–2937, 2013
work page 2013
-
[19]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[20]
A Push-Pull Layer Improves Robustness of Convolutional Neural Networks
Nicola Strisciuglio, Manuel Lopez-Antequera, and Nicolai Petkov. A push-pull layer improves robustness of convolutional neural networks. arXiv preprint arXiv:1901.10208, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[21]
Nicola Strisciuglio, Radim Tylecek, Michael Blaich, Nicolai Petkov, Peter Bieber, Jochen Hemming, Eldert van Henten, Torsten Sattler, Marc Pollefeys, Theo Gev- ers, Thomas Brox, and Robert B. Fisher. Trimbot2020: an outdoor robot for automatic gardening. ISR, 2018
work page 2018
-
[22]
Are we there yet? challenging seqslam on a 3000 km journey across all four seasons
Niko S¨ underhauf, Peer Neubert, and Peter Protzel. Are we there yet? challenging seqslam on a 3000 km journey across all four seasons. In IEEE ICRA , page 2013, 2013
work page 2013
-
[23]
Brief-gist-closing the loop by simple means
Niko S¨ underhauf and Peter Protzel. Brief-gist-closing the loop by simple means. In IEEE IROS , pages 1234–1241. IEEE, 2011
work page 2011
-
[24]
Visual place recognition with repetitive structures
Akihiko Torii, Josef Sivic, Masatoshi Okutomi, and Tomas Pajdla. Visual place recognition with repetitive structures. IEEE Trans. Pattern Anal. Mach. Intell. , pages 2346–2359, 2015. Place recognition in gardens by learning visual representations 13
work page 2015
-
[25]
Flourish-a robotic approach for automation in crop management
Achim Walter, Raghav Khanna, Philipp Lottes, Cyrill Stachniss, Roland Siegwart, Juan Nieto, and Frank Liebisch. Flourish-a robotic approach for automation in crop management. In ICPA, 2018
work page 2018
-
[26]
Improving the robustness of deep neural networks via stability training
Stephan Zheng, Yang Song, Thomas Leung, and Ian Goodfellow. Improving the robustness of deep neural networks via stability training. In IEEE CVPR , pages 4480–4488, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.