Can we trust our models? Epistemic calibration in second-order classification
Pith reviewed 2026-06-27 13:55 UTC · model grok-4.3
The pith
Epistemic calibration requires that a model's reported uncertainty about its uncertainty matches the actual spread of its predictions around the truth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Epistemic calibration measures whether reported epistemic uncertainty faithfully reflects the dispersion of model predictions around the ground truth. It is a strictly stronger notion than classical calibration and captures failure modes invisible to standard metrics. An impossibility theorem relates the concept to existing literature under the epistemic calibration hypothesis. The Expected Epistemic Calibration Error (EECE) is a consistent estimator of the True Epistemic Calibration Error (TECE). Experiments across uncertainty quantification methods confirm that the criterion is coherent and reveals substantial differences among methods despite similar predictive performance.
What carries the argument
Epistemic calibration, the alignment between a model's reported epistemic uncertainty and the observed dispersion of its predictions around ground truth.
If this is right
- Epistemic calibration captures failure modes invisible to classical calibration metrics.
- An impossibility theorem holds for methods satisfying the epistemic calibration hypothesis.
- EECE serves as a consistent estimator of TECE.
- Uncertainty quantification methods can differ substantially in epistemic calibration even when predictive performance is comparable.
Where Pith is reading between the lines
- Models selected for high-stakes use might change if epistemic calibration replaces or supplements classical calibration as the audit criterion.
- The same comparison between reported uncertainty and prediction dispersion could be examined in regression or other output types beyond classification.
- Training procedures for second-order models might be adjusted to optimize directly for low epistemic calibration error.
Load-bearing premise
Reported epistemic uncertainty can be meaningfully compared to the dispersion of model predictions around the ground truth as the target quantity for trustworthiness.
What would settle it
A second-order model with low EECE yet systematic mismatch between reported epistemic uncertainty and the actual variance of predictions around ground truth would show that EECE does not consistently estimate TECE.
Figures
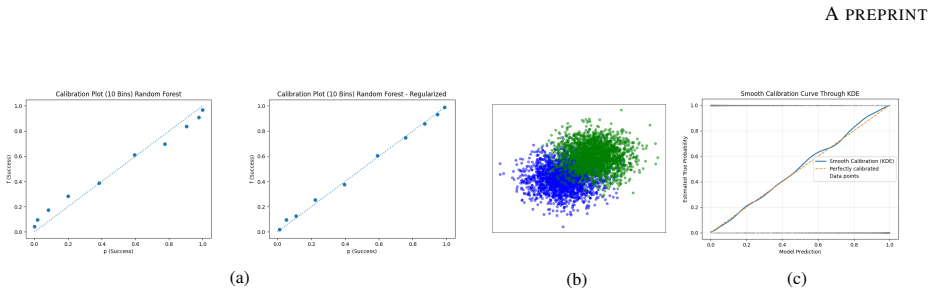
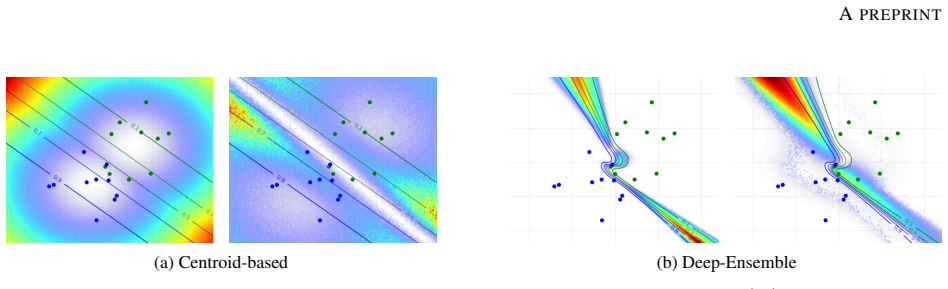
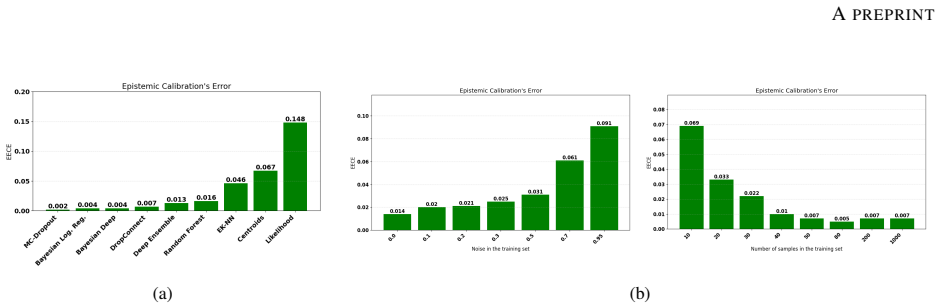
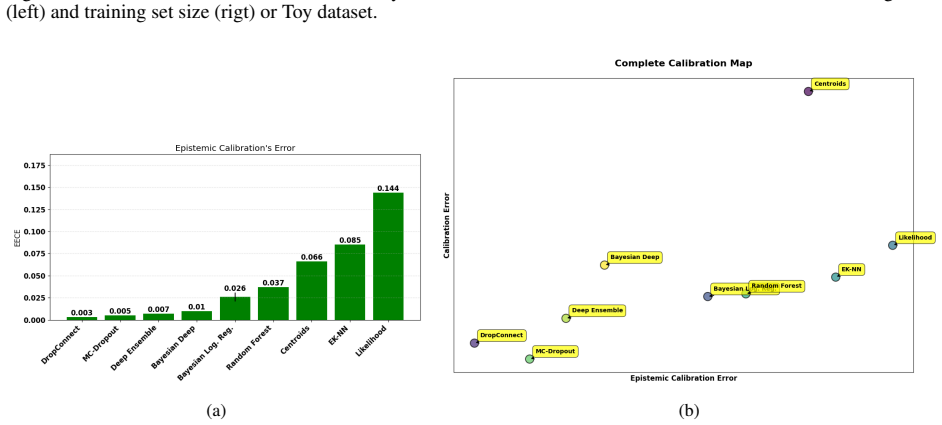
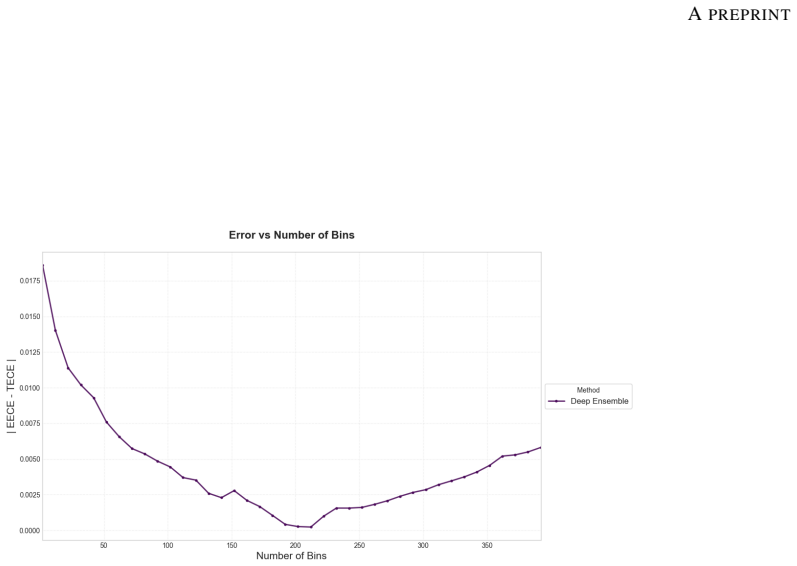
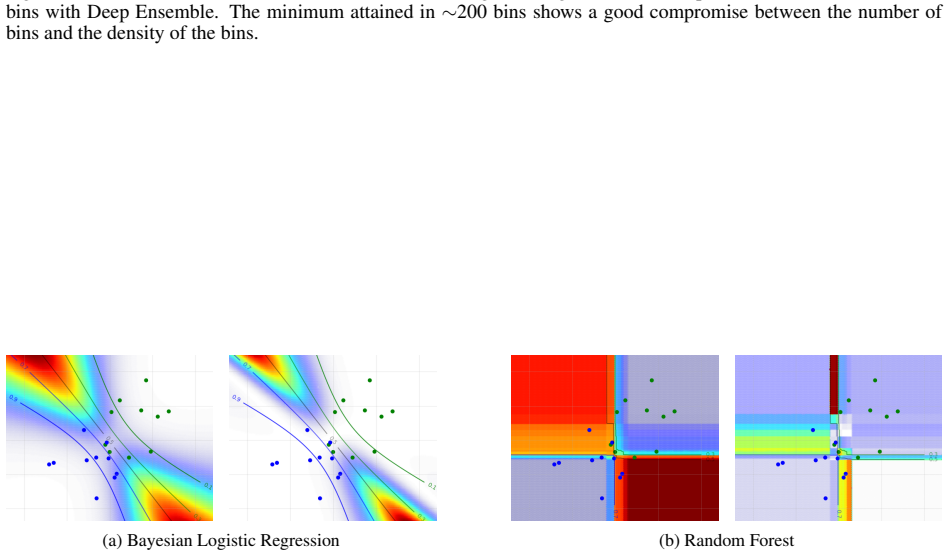
read the original abstract
Uncertainty estimation is critical for deploying machine learning models in high-stakes settings. However, classical calibration only assesses the reliability of predicted probabilities and does not evaluate whether epistemic uncertainty estimates are themselves trustworthy. This limitation is particularly relevant for second-order classification models. We introduce epistemic calibration, a principled criterion that measures whether reported epistemic uncertainty faithfully reflects the dispersion of model predictions around the ground truth. We show that epistemic calibration is a strictly stronger notion than classical calibration and captures failure modes invisible to standard metrics. We relate this work to the existing literature through an impossibility theorem that holds under the epistemic calibration hypothesis. To operationalize this concept, we propose the Expected Epistemic Calibration Error (EECE), which we prove to be a consistent estimator of a True Epistemic Calibration Error (TECE). Experiments across a broad range of uncertainty quantification methods show that epistemic calibration is a coherent and meaningful criterion and reveal substantial differences across methods, despite similar predictive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces epistemic calibration as a new criterion for second-order classification models, measuring whether reported epistemic uncertainty faithfully reflects the dispersion of model predictions around the ground truth. It claims this notion is strictly stronger than classical calibration and captures additional failure modes, presents an impossibility theorem that holds under the epistemic calibration hypothesis, proposes the Expected Epistemic Calibration Error (EECE) as a consistent estimator of the True Epistemic Calibration Error (TECE), and reports experiments across uncertainty quantification methods showing that the criterion is coherent and reveals differences despite similar predictive performance.
Significance. If the proofs of strict dominance, the impossibility theorem, and consistency of EECE hold, the work provides a principled extension of calibration concepts that addresses trustworthiness of epistemic uncertainty estimates in high-stakes settings. The consistency result for EECE and the experimental demonstration of method differences are concrete strengths that could influence evaluation practices in uncertainty quantification.
major comments (2)
- [Theory section on impossibility theorem] The impossibility theorem (abstract and theory section) is conditioned on the epistemic calibration hypothesis; the manuscript must explicitly demonstrate that the definitions of TECE and EECE are independent of this hypothesis and of any fitted parameters to confirm the argument is non-circular.
- [Section proving consistency of EECE] The claim that EECE is a consistent estimator of TECE (abstract) is central; the full derivation and assumptions (e.g., in the section proving consistency) must be provided in detail, as the abstract alone does not allow verification of the estimator's properties under the stated conditions.
minor comments (2)
- [Abstract] The abstract refers to experiments across 'a broad range of uncertainty quantification methods' but does not list them; adding the specific methods and a summary table of results would improve clarity.
- [Definition of epistemic calibration] The weakest assumption (comparability of reported epistemic uncertainty to dispersion around ground truth) is definitional for the new concept and does not introduce inconsistency, but the manuscript should state this choice explicitly in the definition section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical contributions. We address each major comment below.
read point-by-point responses
-
Referee: [Theory section on impossibility theorem] The impossibility theorem (abstract and theory section) is conditioned on the epistemic calibration hypothesis; the manuscript must explicitly demonstrate that the definitions of TECE and EECE are independent of this hypothesis and of any fitted parameters to confirm the argument is non-circular.
Authors: We agree that an explicit statement is needed to preclude any perception of circularity. The definitions of TECE (Definition 3) and EECE (Definition 4) are introduced in Section 3 solely in terms of the joint distribution of model predictions and ground-truth labels; they make no reference to the epistemic calibration hypothesis or to any fitted parameters. The hypothesis is stated only at the beginning of Section 4, where the impossibility theorem is proved under that assumption. In the revision we will insert a short clarifying paragraph immediately before the theorem stating that the preceding definitions are independent of the hypothesis. revision: yes
-
Referee: [Section proving consistency of EECE] The claim that EECE is a consistent estimator of TECE (abstract) is central; the full derivation and assumptions (e.g., in the section proving consistency) must be provided in detail, as the abstract alone does not allow verification of the estimator's properties under the stated conditions.
Authors: The consistency proof, including the full set of assumptions (i.i.d. sampling, finite second moments of the epistemic uncertainty, and the use of the law of large numbers), appears in Section 5 together with the supporting lemmas in the appendix. Nevertheless, to facilitate direct verification from the main text we will expand Section 5 by (i) listing all assumptions in a dedicated box and (ii) inserting the key intermediate steps of the proof that were previously only sketched. This change will be made in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines epistemic calibration as a new criterion measuring whether reported epistemic uncertainty reflects dispersion of predictions around ground truth, then derives that it is strictly stronger than classical calibration, presents an impossibility theorem conditional on the epistemic calibration hypothesis, and proves EECE is a consistent estimator of TECE. These steps follow from the introduced definitions and standard consistency arguments without reducing to fitted inputs renamed as predictions, self-citations as load-bearing premises, or any self-definitional equivalence where outputs equal inputs by construction. The conditional nature of the impossibility theorem is a standard logical structure and does not create circularity. Core claims remain independent of the paper's own fitted values or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Epistemic uncertainty estimates can be isolated and compared to prediction dispersion around ground truth in second-order models.
Reference graph
Works this paper leans on
-
[1]
On second-order scoring rules for epistemic uncertainty quantification
Viktor Bengs, Eyke Hüllermeier, and Willem Waegeman. On second-order scoring rules for epistemic uncertainty quantification. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[2]
Random forests.Machine Learning, 45:5–32, 10 2001
L Breiman. Random forests.Machine Learning, 45:5–32, 10 2001
2001
-
[3]
Quarterly Journal of the Royal Meteorological Society , volume =
Jochen Bröcker. Reliability, sufficiency, and the decomposition of proper scores.Quar- terly Journal of the Royal Meteorological Society, 135(643):1512–1519, 2009. _eprint: https://rmets.onlinelibrary.wiley.com/doi/pdf/10.1002/qj.456
-
[4]
Posterior network: Uncertainty estimation with- out ood samples via density-based pseudo-counts
Bertrand Charpentier, Daniel Zügner, and Stephan Günnemann. Posterior network: Uncertainty estimation with- out ood samples via density-based pseudo-counts. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 1356–1367. Curran As- sociates, Inc., 2020
2020
-
[5]
Laplace redux – effortless bayesian deep learning, 2022
Erik Daxberger, Agustinus Kristiadi, Alexander Immer, Runa Eschenhagen, Matthias Bauer, and Philipp Hennig. Laplace redux – effortless bayesian deep learning, 2022
2022
-
[6]
A. P. Dempster. Upper and Lower Probabilities Induced by a Multivalued Mapping.The Annals of Mathematical Statistics, 38(2):325 – 339, 1967
1967
-
[7]
A k-nearest neighbor classification rule based on dempster-shafer theory.Systems, Man and Cybernetics, IEEE Transactions on, 219, 1995
Thierry Denœux. A k-nearest neighbor classification rule based on dempster-shafer theory.Systems, Man and Cybernetics, IEEE Transactions on, 219, 1995
1995
-
[8]
Decomposition of un- certainty in Bayesian deep learning for efficient and risk-sensitive learning
Stefan Depeweg, Jose-Miguel Hernandez-Lobato, Finale Doshi-Velez, and Steffen Udluft. Decomposition of un- certainty in Bayesian deep learning for efficient and risk-sensitive learning. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, page...
2018
-
[9]
The Epistemic Uncertainty Hole: an issue of Bayesian Neural Networks, July 2024
Mohammed Fellaji and Frédéric Pennerath. The Epistemic Uncertainty Hole: an issue of Bayesian Neural Networks, July 2024. arXiv:2407.01985 [stat.ML]
arXiv 2024
-
[10]
Dropout as a Bayesian approximation: representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, pages 1050–1059, New York, NY , USA, June 2016. JMLR.org
2016
-
[11]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On Calibration of Modern Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, pages 1321–1330. PMLR, July 2017
2017
-
[12]
Kaplan, Audun Jøsang, Dong H
Zhen Guo, Zelin Wan, Qisheng Zhang, Xujiang Zhao, Qi Zhang, Lance M. Kaplan, Audun Jøsang, Dong H. Jeong, Feng Chen, and Jin-Hee Cho. A survey on uncertainty reasoning and quantification in belief theory and its application to deep learning.Information Fusion, 101, 2024
2024
-
[13]
Evidential uncer- tainty sampling strategies for active learning.Machine Learning, 113:1–22, 06 2024
Arthur Hoarau, Vincent Lemaire, Yolande Gall, Jean-Christophe Dubois, and Arnaud Martin. Evidential uncer- tainty sampling strategies for active learning.Machine Learning, 113:1–22, 06 2024
2024
-
[14]
Stephen C. Hora. Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management.Reliability Engineering & System Safety, 54(2), 1996. Treatment of Aleatory and Epistemic Uncertainty
1996
-
[15]
Aleatoric and epistemic uncertainty in machine learning: An intro- duction to concepts and methods.Machine Learning, 110:457–506, 2021
Eyke Hüllermeier and Willem Waegeman. Aleatoric and epistemic uncertainty in machine learning: An intro- duction to concepts and methods.Machine Learning, 110:457–506, 2021
2021
-
[16]
Position: Epistemic uncertainty estimation methods are fundamentally incomplete, February 2026
Sebastián Jiménez, Mira Jürgens, and Willem Waegeman. Position: Epistemic uncertainty estimation methods are fundamentally incomplete, February 2026. arXiv:2505.23506 [cs.LG]. 10 APREPRINT
arXiv 2026
-
[17]
Is epistemic uncertainty faithfully represented by evidential deep learning methods? InProceedings of the 41st International Conference on Machine Learning, ICML’24
Mira Jürgens, Nis Meinert, Viktor Bengs, Eyke Hüllermeier, and Willem Waegeman. Is epistemic uncertainty faithfully represented by evidential deep learning methods? InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[18]
A calibration test for evaluating set-based epistemic uncertainty representations.Machine Learning, 114(9):202, August 2025
Mira Jürgens, Thomas Mortier, Eyke Hüllermeier, Viktor Bengs, and Willem Waegeman. A calibration test for evaluating set-based epistemic uncertainty representations.Machine Learning, 114(9):202, August 2025
2025
-
[19]
What uncertainties do we need in bayesian deep learning for computer vision? In NIPS, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? In NIPS, 2017
2017
-
[20]
Position: Uncertainty Quantification Needs Re- assessment for Large-language Model Agents, May 2025
Michael Kirchhof, Gjergji Kasneci, and Enkelejda Kasneci. Position: Uncertainty Quantification Needs Re- assessment for Large-language Model Agents, May 2025. arXiv:2505.22655 [cs.LG]
arXiv 2025
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. InUniversity of Toronto, 2009
2009
-
[22]
Trainable Calibration Measures for Neural Networks from Kernel Mean Embeddings
Aviral Kumar, Sunita Sarawagi, and Ujjwal Jain. Trainable Calibration Measures for Neural Networks from Kernel Mean Embeddings. InProceedings of the 35th International Conference on Machine Learning, pages 2805–2814. PMLR, July 2018
2018
-
[23]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, pages 6402–6413, 2017
2017
-
[24]
Lecun, L
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[25]
Dropconnect is effective in modeling uncertainty of bayesian deep networks.Scientific Reports, 11, 03 2021
Aryan Mobiny, Pengyu Yuan, Supratik Moulik, Naveen Garg, Carol wu, and Hien Nguyen. Dropconnect is effective in modeling uncertainty of bayesian deep networks.Scientific Reports, 11, 03 2021
2021
-
[26]
Benchmarking uncertainty disentanglement: special- ized uncertainties for specialized tasks
Bálint Mucsányi, Michael Kirchhof, and Seong Joon Oh. Benchmarking uncertainty disentanglement: special- ized uncertainties for specialized tasks. InProceedings of the 38th International Conference on Neural Informa- tion Processing Systems, volume 37 ofNIPS ’24, pages 50972–51038, Red Hook, NY , USA, December 2024. Curran Associates Inc
2024
-
[27]
Cooper, and Milos Hauskrecht
Mahdi Pakdaman Naeini, Gregory F. Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities us- ing bayesian binning. InProceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, pages 2901–2907, Austin, Texas, January 2015. AAAI Press
2015
-
[28]
How to measure uncertainty in uncertainty sampling for active learning.Machine Learning, 111:89–122, jan 2022
Vu-Linh Nguyen, Mohammad Hossein Shaker, and Eyke Hüllermeier. How to measure uncertainty in uncertainty sampling for active learning.Machine Learning, 111:89–122, jan 2022
2022
-
[29]
Predicting good probabilities with supervised learning
Alexandru Niculescu-Mizil and Rich Caruana. Predicting good probabilities with supervised learning. InPro- ceedings of the 22nd international conference on Machine learning, ICML ’05, pages 625–632, New York, NY , USA, August 2005. Association for Computing Machinery
2005
-
[30]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[31]
Exclusive: The $2 Per Hour Workers Who Made ChatGPT Safer, January 2023
Billy Perrigo. Exclusive: The $2 Per Hour Workers Who Made ChatGPT Safer, January 2023
2023
-
[32]
Polson, James G
Nicholas G. Polson, James G. Scott, and Jesse Windle. Bayesian Inference for Logistic Models Using Pólya–Gamma Latent Variables.Journal of the American Statistical Association, 108(504):1339–1349, De- cember 2013
2013
-
[33]
Blaschko
Teodora Popordanoska, Raphael Sayer, and Matthew B. Blaschko. A consistent and differentiable Lp canonical calibration error estimator. InProceedings of the 36th International Conference on Neural Information Process- ing Systems, NIPS ’22, pages 7933–7946, Red Hook, NY , USA, November 2022. Curran Associates Inc
2022
-
[34]
Evidential deep learning to quantify classification uncer- tainty
Murat Sensoy, Lance Kaplan, and Melih Kandemir. Evidential deep learning to quantify classification uncer- tainty. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[35]
C. E. Shannon. A mathematical theory of communication.Bell System Technical Journal, 27(3):379–423, 1948
1948
-
[36]
Rethinking Aleatoric and Epistemic Uncertainty
Freddie Bickford Smith, Jannik Kossen, Eleanor Trollope, Mark Van Der Wilk, Adam Foster, and Tom Rain- forth. Rethinking Aleatoric and Epistemic Uncertainty. InProceedings of the 42nd International Conference on Machine Learning, pages 4345–4359. PMLR, October 2025
2025
-
[37]
Prior and posterior networks: A survey on evidential deep learning methods for uncertainty estimation.Transactions of Machine Learning Research, 2023
Dennis Ulmer, Christian Hardmeier, and Jes Frellsen. Prior and posterior networks: A survey on evidential deep learning methods for uncertainty estimation.Transactions of Machine Learning Research, 2023. 11 APREPRINT
2023
-
[38]
Andersson, Fredrik Lindsten, Jacob Roll, and Thomas Bo Schön
Juozas Vaicenavicius, David Widmann, Carl R. Andersson, Fredrik Lindsten, Jacob Roll, and Thomas Bo Schön. Evaluating model calibration in classification. InInternational Conference on Artificial Intelligence and Statis- tics, 2019
2019
-
[39]
de With, and Fons van der Sommen
Amaan Valiuddin, Ruud Van Sloun, Christiaan Viviers, Peter H.N. de With, and Fons van der Sommen. A review of bayesian uncertainty quantification in deep probabilistic image segmentation.Transactions on Machine Learning Research, 2025
2025
-
[40]
Uncertainty estimation using a single deep deterministic neural network
Joost Van Amersfoort, Lewis Smith, Yee Whye Teh, and Yarin Gal. Uncertainty estimation using a single deep deterministic neural network. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9690–9700. PMLR, 13–18 Jul 2020
2020
-
[41]
Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers
Bianca Zadrozny and Charles Elkan. Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers. InProceedings of the Eighteenth International Conference on Machine Learning, ICML ’01, pages 609–616, San Francisco, CA, USA, June 2001. Morgan Kaufmann Publishers Inc. 12 APREPRINT A Proofs Theorem 2.For an epistemically cali...
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.