Controlled Personalization in Legacy Media Online Services: A Case Study in News Recommendation
Pith reviewed 2026-05-25 08:06 UTC · model grok-4.3
The pith
A modest level of controlled personalization on a legacy news site raised click-through rates, cut navigation effort, increased content diversity, and reduced popularity bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the A/B test, the version that added a modest algorithmic layer on top of editorial curation produced higher click-through rates, lower navigation effort, greater content diversity, broader catalog coverage, and reduced popularity bias relative to the purely editorial control condition.
What carries the argument
Controlled personalization, defined as the deliberate combination of editorially curated content with a limited set of algorithmically selected articles.
If this is right
- Legacy news platforms can adopt limited algorithmic selection and still meet editorial standards.
- User engagement metrics improve without requiring full automation of story selection.
- Diversity and catalog coverage increase while popularity bias decreases under the mixed approach.
- The same controlled strategy offers a practical route for other traditional media outlets to test personalization.
Where Pith is reading between the lines
- Similar modest personalization layers could be tested on other content domains such as video or audio archives.
- The observed reduction in popularity bias might help surface stories that editorial teams already value but that algorithms alone would suppress.
- If navigation effort drops, the approach may indirectly increase time spent on the site, though that metric was not reported.
Load-bearing premise
The A/B test isolated the effect of the added personalization component with comparable user groups and no other site changes during the test window.
What would settle it
A follow-up A/B test on the same or a comparable legacy news site that finds no difference in click-through rate or diversity metrics between the two conditions would falsify the reported benefit.
Figures










read the original abstract
Personalized news recommendations have become a standard feature of large news aggregation services, optimizing user engagement through automated content selection. In contrast, legacy news media often approach personalization cautiously, striving to balance technological innovation with core editorial values. As a result, online platforms of traditional news outlets typically combine editorially curated content with algorithmically selected articles - a strategy we term controlled personalization. In this industry article, we evaluate the effectiveness of controlled personalization through an A/B test conducted on the website of a major Norwegian legacy news organization. Our findings indicate that even a modest level of personalization yields substantial benefits. Specifically, we observe that users exposed to personalized content demonstrate higher click-through-rates and reduced navigation effort, suggesting improved discovery of relevant content. Moreover, our analysis reveals that controlled personalization contributes to greater content diversity and catalog coverage and in addition reduces popularity bias. Overall, our results suggest that controlled personalization can successfully align user needs with editorial goals, offering a viable path for legacy media to adopt personalization technologies while upholding journalistic values.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This industry case study evaluates 'controlled personalization' (editorially curated content combined with algorithmic recommendations) via an A/B test on the website of a major Norwegian legacy news organization. The central claim is that even modest personalization produces higher click-through rates, reduced navigation effort, greater content diversity and catalog coverage, and reduced popularity bias while aligning user needs with editorial goals.
Significance. If the A/B test results are robustly supported, the work is significant for cs.IR as it supplies real-world production evidence that legacy media can adopt limited personalization to improve engagement metrics without fully ceding editorial control, offering a practical template for traditional outlets.
major comments (2)
- [Abstract] Abstract: the claims of positive A/B test outcomes on CTR, navigation, diversity, and bias are stated without sample sizes, statistical significance details, effect sizes, algorithm description, or controls for confounds, preventing assessment of the data support for the central claim.
- [Experimental Setup] The A/B test description (Experimental Setup or Methods) does not confirm that randomization produced balanced groups on pre-test behavior, that no concurrent editorial or platform changes occurred, and that personalization was the sole difference between arms; without these, alternative explanations for the observed differences cannot be excluded.
minor comments (2)
- [Introduction] The term 'controlled personalization' is introduced in the abstract but would benefit from an explicit operational definition (e.g., the exact fraction of algorithmic vs. editorial items) in the introduction or methods.
- Figure or table captions for the A/B results should include exact sample sizes per arm and the precise statistical tests used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will incorporate clarifications and additional details into the revised manuscript where the points are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of positive A/B test outcomes on CTR, navigation, diversity, and bias are stated without sample sizes, statistical significance details, effect sizes, algorithm description, or controls for confounds, preventing assessment of the data support for the central claim.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to assess the strength of the claims. The full manuscript reports sample sizes (approximately 1.2 million users per arm), statistical tests (t-tests with p < 0.001 for CTR and navigation metrics), effect sizes (Cohen's d ranging from 0.12 to 0.28), a description of the controlled personalization algorithm (editorial front page plus top-5 algorithmic recommendations), and controls (no concurrent platform changes during the 14-day test window). We will revise the abstract to include concise versions of these details while remaining within length limits. revision: yes
-
Referee: [Experimental Setup] The A/B test description (Experimental Setup or Methods) does not confirm that randomization produced balanced groups on pre-test behavior, that no concurrent editorial or platform changes occurred, and that personalization was the sole difference between arms; without these, alternative explanations for the observed differences cannot be excluded.
Authors: The referee correctly identifies gaps in the current Experimental Setup section. The manuscript states that users were randomly assigned but does not report pre-test balance checks (e.g., on prior CTR or session length) or explicitly rule out concurrent changes. We will add these elements: (1) summary statistics confirming balance on key pre-test metrics, (2) a statement that editorial curation and platform features remained unchanged during the test, and (3) confirmation that the only difference between arms was the presence of the modest algorithmic recommendations on the personalized arm. These additions will strengthen the causal interpretation. revision: yes
Circularity Check
Purely empirical A/B test reporting; no derivation chain present
full rationale
The paper is an industry case study that reports outcomes from an A/B test on a Norwegian news site. It contains no equations, no fitted parameters, no predictive models, and no derivation steps. Claims about CTR, navigation effort, diversity, coverage, and popularity bias are presented as direct experimental observations rather than outputs of any internal computation or self-referential definition. No self-citations are used to justify core premises, and the study setup is described at a high level without reducing to fitted inputs or renamed known results. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Christine Bauer, Chandni Bagchi, Olusanmi A. Hundogan, and Karin van Es. 2024. Where Are the Values? A Systematic Literature Review on News Recommender Systems.ACM Trans. Recomm. Syst.2, 3, Article 23 (June 2024). https://doi.org/10.1145/3654805
-
[2]
Daniel Billsus and Michael J. Pazzani. 1999. A personal news agent that talks, learns and explains. InProceedings of the Third Annual Conference on Autonomous Agents (AGENTS ’99). 268–275. https://doi.org/10.1145/301136.301208
-
[3]
Robin Burke, Joseph Konstan, and Michael Ekstrand. 2024. Conducting Recommender Systems User Studies Using POPROX. InProceedings of the 18th ACM Conference on Recommender Systems(Bari, Italy)(RecSys ’24). 1277–1278. https://doi.org/10.1145/3640457.3687092
-
[4]
Tadeusz Caliński and Harabasz JA. 1974. A Dendrite Method for Cluster Analysis.Communications in Statistics - Theory and Methods3 (01 1974), 1–27. https://doi.org/10.1080/03610927408827101
-
[5]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and Debias in Recommender System: A Survey and Future Directions.ACM Trans. Inf. Syst.41, 3, Article 67 (2023). https://doi.org/10.1145/3564284
-
[6]
Sunshine Chong and Andrés Abeliuk. 2019. Quantifying the Effects of Recommendation Systems. In2019 IEEE International Conference on Big Data (Big Data). 3008–3015. https://doi.org/10.1109/BigData47090.2019.9005951
-
[7]
Das, Mayur Datar, Ashutosh Garg, and Shyam Rajaram
Abhinandan S. Das, Mayur Datar, Ashutosh Garg, and Shyam Rajaram. 2007. Google news personalization: scalable online collaborative filtering. In Proceedings of the 16th International Conference on World Wide Web (WWW ’07). 271–280. https://doi.org/10.1145/1242572.1242610
-
[8]
David L. Davies and Donald W. Bouldin. 1979. A Cluster Separation Measure.IEEE Transactions on Pattern Analysis and Machine IntelligencePAMI-1, 2 (1979), 224–227. https://doi.org/10.1109/TPAMI.1979.4766909
-
[9]
Yashar Deldjoo, Zhankui He, Julian McAuley, Anton Korikov, Scott Sanner, Arnau Ramisa, René Vidal, Maheswaran Sathiamoorthy, Atoosa Kasirzadeh, and Silvia Milano. 2024. A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys). InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’2...
-
[10]
Florent Garcin, Boi Faltings, Olivier Donatsch, Ayar Alazzawi, Christophe Bruttin, and Amr Huber. 2014. Offline and online evaluation of news recommender systems at swissinfo.ch. InProceedings of the 8th ACM Conference on Recommender Systems (RecSys ’14). 169–176. https: //doi.org/10.1145/2645710.2645745
-
[11]
Mouzhi Ge, Carla Delgado-Battenfeld, and Dietmar Jannach. 2010. Beyond accuracy: evaluating recommender systems by coverage and serendipity. InProceedings of the Fourth ACM Conference on Recommender Systems(Barcelona, Spain)(RecSys ’10). Association for Computing Machinery, New York, NY, USA, 257–260. https://doi.org/10.1145/1864708.1864761
-
[12]
Carlos A. Gomez-Uribe and Neil Hunt. 2016. The Netflix Recommender System: Algorithms, Business Value, and Innovation.ACM Trans. Manage. Inf. Syst.6, 4, Article 13 (2016). https://doi.org/10.1145/2843948
-
[13]
Naieme Hazrati and Francesco Ricci. 2023. Choice models and recommender systems effects on users’ choices.User Modeling and User-Adapted Interaction34, 1 (May 2023), 109–145. https://doi.org/10.1007/s11257-023-09366-x
-
[14]
Negative Generators of the Virasoro Constraints for the BKP Hierarchy
Lucien Heitz, Juliane A. Lischka, Alena Birrer, Bibek Paudel, Suzanne Tolmeijer, Laura Laugwitz, and Abraham Bernstein and. 2022. Benefits of Diverse News Recommendations for Democracy: A User Study.Digital Journalism10, 10 (2022), 1710–1730. https://doi.org/10.1080/21670811.2021.2021804
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/21670811.2021.2021804 2022
-
[15]
Jonathan Hendrickx, Annelien Smets, and Pieter Ballon. 2021. News Recommender Systems and News Diversity, Two of a Kind? A Case Study from a Small Media Market.Journalism and Media2, 3 (2021), 515–528. https://doi.org/10.3390/journalmedia2030031
-
[16]
Frank Hopfgartner, Torben Brodt, Jonas Seiler, Benjamin Kille, Andreas Lommatzsch, Martha Larson, Roberto Turrin, and András Serény. 2016. Benchmarking News Recommendations: The CLEF NewsREEL Use Case.SIGIR Forum49, 2 (Jan. 2016), 129–136. https://doi.org/10.1145/2888422. 2888443
-
[17]
Chengkai Huang, Hongtao Huang, Tong Yu, Kaige Xie, Junda Wu, Shuai Zhang, Julian Mcauley, Dietmar Jannach, and Lina Yao. 2025. A Survey of Foundation Model-Powered Recommender Systems: From Feature-Based, Generative to Agentic Paradigms. https://doi.org/10.48550/arXiv.2504. 16420 arXiv:2504.16420 [cs.IR]
-
[18]
Kojiro Iizuka, Yoshifumi Seki, and Makoto P. Kato. 2021. The Effect of News Article Quality on Ad Consumption. InProceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM ’21). 3107–3111. https://doi.org/10.1145/3459637.3482201
-
[19]
Dietmar Jannach and Michael Jugovac. 2019. Measuring the Business Value of Recommender Systems.ACM Transactions on Management Information Systems10, 4 (2019). https://doi.org/10.1145/3370082
-
[20]
Dietmar Jannach, Lukas Lerche, Iman Kamehkhosh, and Michael Jugovac. 2015. What recommenders recommend: an analysis of recommendation biases and possible countermeasures.User Modeling and User-Adapted Interaction25, 5 (Dec. 2015), 427–491. https://doi.org/10.1007/s11257-015- 26 Holzleitner et al. 9165-3
-
[21]
Dietmar Jannach, Massimo Quadrana, and Paolo Cremonesi. 2021. Session-based Recommendation. InRecommender Systems Handbook, Francesco Ricci, Bracha Shapira, and Lior Rokach (Eds.). Springer US
work page 2021
-
[22]
Tomonari Kamba, Krishna Bharat, and Michael C. Albers. 1995. The Krakatoa Chronicle: An Interactive Personalized Newspaper on the Web. In Proceedings of the Fourth International Conference on World Wide Web. 159–170. https://doi.org/10.1145/3592626.3592638
-
[23]
Marius Kaminskas and Derek Bridge. 2016. Diversity, Serendipity, Novelty, and Coverage: A Survey and Empirical Analysis of Beyond-Accuracy Objectives in Recommender Systems.ACM Trans. Interact. Intell. Syst.7, 1 (Dec. 2016). https://doi.org/10.1145/2926720
-
[24]
Mozhgan Karimi, Dietmar Jannach, and Michael Jugovac. 2018. News Recommender Systems - Survey and Roads Ahead.Information Processing and Management54, 6 (2018), 1203–1227. https://doi.org/10.1016/j.ipm.2018.04.008
-
[25]
Evan Kirshenbaum, George Forman, and Michael Dugan. 2012. A Live Comparison of Methods for Personalized Article Recommendation at Forbes.com. InMachine Learning and Knowledge Discovery in Databases. 51–66. https://doi.org/10.1007/978-3-642-33486-3_4
-
[26]
Anastasiia Klimashevskaia, Mehdi Elahi, Dietmar Jannach, Christoph Trattner, and Simen Buodd. 2024. Empowering Editors: How Automated Recommendations Support Editorial Article Curation. InINRA 2024 Workshop at ACM RecSys
work page 2024
-
[27]
Anastasiia Klimashevskaia, Dietmar Jannach, Mehdi Elahi, and Christoph Trattner. 2024. A Survey on Popularity Bias in Recommender Systems. User Modeling and User-Adapted Interaction34 (2024), 1777–1834
work page 2024
-
[28]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix Factorization Techniques for Recommender Systems.Computer42, 8 (2009), 30–37. https://doi.org/10.1109/MC.2009.263
-
[29]
Lihong Li, Wei Chu, John Langford, and Robert E. Schapire. 2010. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th International Conference on World Wide Web(Raleigh, North Carolina, USA)(WWW ’10). 661–670. https://doi.org/10.1145/ 1772690.1772758
-
[30]
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. 2011. Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. InProceedings of the Fourth ACM International Conference on Web Search and Data Mining(Hong Kong, China)(WSDM ’11). 297–306. https://doi.org/10.1145/1935826.1935878
-
[31]
Miaomiao Li and Licheng Wang. 2019. A Survey on Personalized News Recommendation Technology.IEEE Access7 (2019), 145861–145879. https://doi.org/10.1109/ACCESS.2019.2944927
-
[32]
Hongjun Lim, Yeon-Chang Lee, Jin-Seo Lee, Sanggyu Han, Seunghyeon Kim, Yeon Jeong Jeong, Changbong Kim, Jaehun Kim, Sunghoon Han, Solbi Choi, Hanjong Ko, Dokyeong Lee, Jaeho Choi, Yungi Kim, Hong-Kyun Bae, Taeho Kim, Jeewon Ahn, Hyun-Soung You, and Sang-Wook Kim. 2022. AiRS: A Large-Scale Recommender System at NAVER News. In38th IEEE International Confere...
-
[33]
Jiahui Liu, Peter Dolan, and Elin Rønby Pedersen. 2010. Personalized news recommendation based on click behavior. InProceedings of the 15th International Conference on Intelligent User Interfaces (IUI ’10). 31–40. https://doi.org/10.1145/1719970.1719976
-
[34]
Feng Lu, Anca Dumitrache, and David Graus. 2020. Beyond Optimizing for Clicks: Incorporating Editorial Values in News Recommendation. In Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization (UMAP ’20). 145–153. https://doi.org/10.1145/3340631. 3394864
-
[35]
Cornelius A. Ludmann. 2017. Recommending News Articles in the CLEF News Recommendation Evaluation Lab with the Data Stream Management System Odysseus. InWorking Notes of CLEF 2017 - Conference and Labs of the Evaluation Forum (CEUR Workshop Proceedings, Vol. 1866). https: //ceur-ws.org/Vol-1866/paper_111.pdf
work page 2017
-
[36]
Joanna Misztal-Radecka, Dominik Rusiecki, Michal Zmuda, and Artur Bujak. 2019. Trend-responsive User Segmentation Enabling Traceable Publishing Insights. A Case Study of a Real-world Large-scale News Recommendation System.CoRRabs/1911.11070 (2019). http://arxiv.org/abs/ 1911.11070
-
[37]
Lynge Asbjørn Møller. 2022. Recommended for You: How Newspapers Normalise Algorithmic News Recommendation to Fit Their Gatekeeping Role.Journalism Studies23, 7 (2022), 800–817. https://doi.org/10.1080/1461670X.2022.2034522
-
[38]
2011.The filter bubble: What the Internet is hiding from you
Eli Pariser. 2011.The filter bubble: What the Internet is hiding from you. Penguin UK
work page 2011
-
[39]
Shaina Raza and Chen Ding. 2021. News recommender system: a review of recent progress, challenges, and opportunities.Artificial Intelligence Review55 (07 2021), 749–800. https://doi.org/10.1007/s10462-021-10043-x
-
[40]
Alan Said, Alejandro Bellogín, Jimmy Lin, and Arjen de Vries. 2014. Do recommendations matter? News recommendation in real life. InProceedings of the Companion Publication of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing(Baltimore, Maryland, USA) (CSCW Companion ’14). 237–240. https://doi.org/10.1145/2556420.2556510
-
[41]
Hidekazu Sakagami and Tomonari Kamba. 1997. Learning personal preferences on online newspaper articles from user behaviors.Computer Networks and ISDN Systems29, 8 (1997), 1447–1455. https://doi.org/10.1016/S0169-7552(97)00016-0
-
[42]
Atom Sonoda, Yoshifumi Seki, and Fujio Toriumi. 2022. Analyzing user engagement in news application considering popularity diversity and content diversity.Journal of Computational Social Science5, 2 (2022), 1595–1614. https://doi.org/10.1007/s42001-022-00179-3
-
[43]
Maartje ter Hoeve, Mathieu Heruer, Daan Odijk, Anne Schuth, Martijn Spitters, and Maarten de Rijke. [n. d.]. Do News Consumers Want Explanations for Personalized News Rankings?. InProceedings of the FATREC Workshop on Responsible Recommendation at RecSys 2017(Como, Italy, 2017-08-31) (FATREC ’17). Controlled Personalization in Legacy Media Online Services...
work page 2017
-
[44]
Neil Thurman, Judith Moeller, Natali Helberger, and Damian Trilling. 2019. My Friends, Editors, Algorithms, and I.Digital Journalism7, 4 (2019), 447–469. https://doi.org/10.1080/21670811.2018.1493936 arXiv:https://doi.org/10.1080/21670811.2018.1493936
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/21670811.2018.1493936 2019
-
[45]
Hanne Vandenbroucke and Annelien Smets. 2024. It’s (not) all about that CTR: A Multi-Stakeholder Perspective on News Recommender Metrics. In Proceedings of the 18th ACM Conference on Recommender Systems(Bari, Italy)(RecSys ’24). 999–1003. https://doi.org/10.1145/3640457.3688183
-
[46]
Judith Vermeulen. 2022. To Nudge or Not to Nudge: News Recommendation as a Tool to Achieve Online Media Pluralism.Digital Journalism10, 10 (2022), 1671–1690. https://doi.org/10.1080/21670811.2022.2026796
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/21670811.2022.2026796 2022
-
[47]
Sanne Vrijenhoek, Mesut Kaya, Nadia Metoui, Judith Möller, Daan Odijk, and Natali Helberger. 2021. Recommenders with a Mission: Assessing Diversity in News Recommendations. InProceedings of the 2021 Conference on Human Information Interaction and Retrieval (CHIIR ’21). 173–183. https://doi.org/10.1145/3406522.3446019
- [48]
-
[49]
Chuhan Wu, Fangzhao Wu, Yongfeng Huang, and Xing Xie. 2023. Personalized News Recommendation: Methods and Challenges.ACM Trans. Inf. Syst.41, 1 (2023). https://doi.org/10.1145/3530257
-
[50]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, and Enhong Chen. 2024. A survey on large language models for recommendation.World Wide Web27, 5 (2024), 60. https://doi.org/10.1007/s11280-024-01291-2
-
[51]
Yunjia Xi, Weiwen Liu, Jianghao Lin, Xiaoling Cai, Hong Zhu, Jieming Zhu, Bo Chen, Ruiming Tang, Weinan Zhang, and Yong Yu. 2024. Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models. InProceedings of the 18th ACM Conference on Recommender Systems(Bari, Italy)(RecSys ’24). 12–22. https://doi.org/10.1145/3640457.3688104
-
[52]
Xing Yi, Liangjie Hong, Erheng Zhong, Nanthan Nan Liu, and Suju Rajan. 2014. Beyond clicks: dwell time for personalization. InProceedings of the 8th ACM Conference on Recommender Systems(Foster City, Silicon Valley, California, USA)(RecSys ’14). Association for Computing Machinery, New York, NY, USA, 113–120. https://doi.org/10.1145/2645710.2645724
-
[53]
Hongzhi Yin, Bin Cui, Jing Li, Junjie Yao, and Chen Chen. 2012. Challenging the long tail recommendation.Proc. VLDB Endow.5, 9 (May 2012), 896–907. https://doi.org/10.14778/2311906.2311916
-
[54]
Markus Zanker, Marcel Bricman, Sergiu Gordea, Dietmar Jannach, and Markus Jessenitschnig. 2006. Persuasive Online-Selling in Quality and Taste Domains. In7th International Conference on Electronic Commerce and Web Technologies (EC-Web 2006). Krakow, Poland, 51–60. https: //doi.org/10.1007/11823865_6
-
[55]
Hong Zhang, Ling Zhao, and Sumeet Gupta. 2018. The role of online product recommendations on customer decision making and loyalty in social shopping communities.International Journal of Information Management38, 1 (2018), 150–166. https://doi.org/10.1016/j.ijinfomgt.2017.07.006
-
[56]
Guanjie Zheng, Fuzheng Zhang, Zihan Zheng, Yang Xiang, Nicholas Jing Yuan, Xing Xie, and Zhenhui Li. 2018. DRN: A Deep Reinforcement Learning Framework for News Recommendation. InProceedings of the 2018 World Wide Web Conference (WWW ’18). 167–176. https://doi.org/10. 1145/3178876.3185994
-
[57]
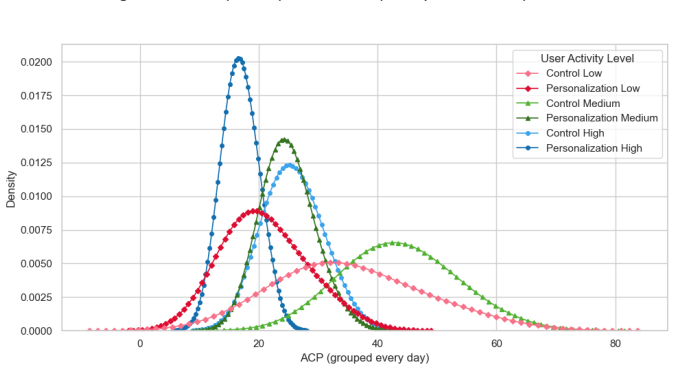
Menghui Zhu, Wei Xia, Weiwen Liu, Yifan Liu, Ruiming Tang, and Weinan Zhang. 2023. Integrated Ranking for News Feed with Reinforcement Learning. InCompanion Proceedings of the ACM Web Conference 2023(Austin, TX, USA)(WWW ’23 Companion). 480–484. https://doi.org/10.1145/ 3543873.3584651 28 Holzleitner et al. Appendix In the following, we present the distri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.