ActiveScope: Actively Seeking and Correcting Perception for MLLMs
Pith reviewed 2026-06-26 01:04 UTC · model grok-4.3
The pith
ActiveScope lets MLLMs actively locate multiple targets and correct for distractions in high-resolution images without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
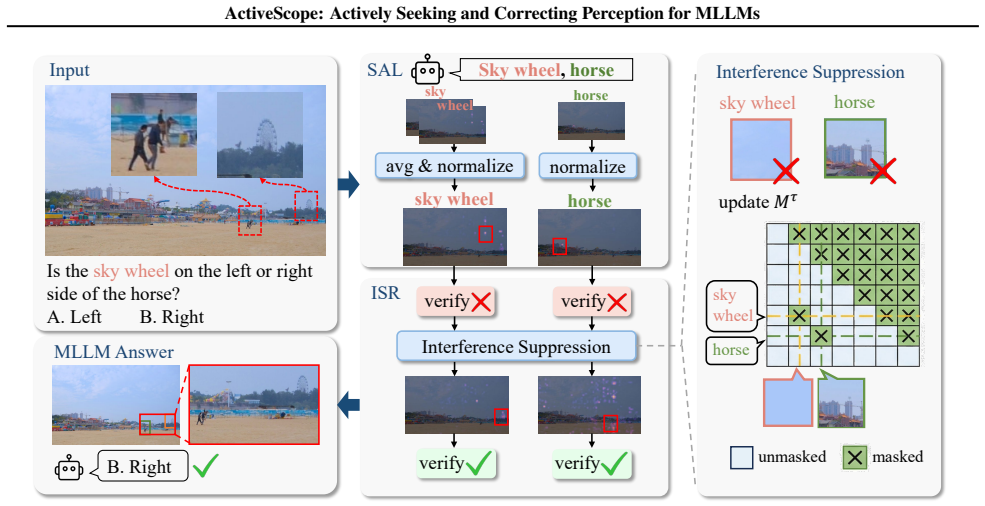
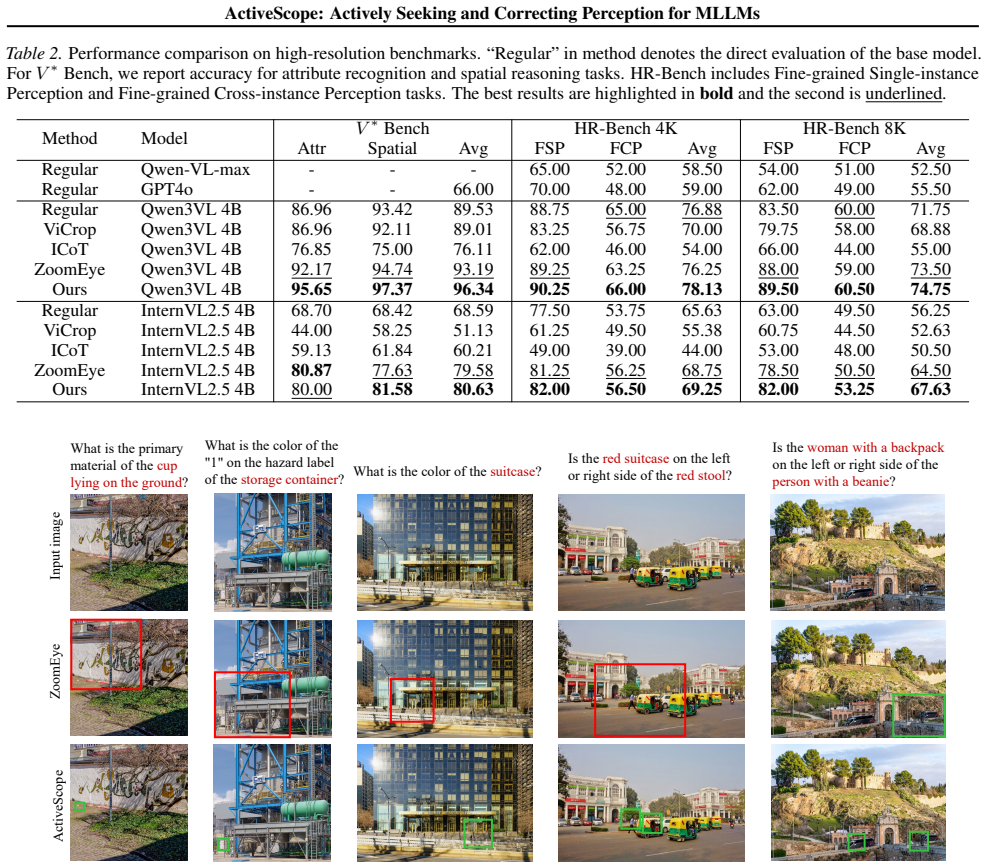
ActiveScope is a training-free framework that enhances MLLMs by actively seeking and correcting perception. Its Semantic Anchor Localization module uses fine-grained semantic anchors to independently localize key targets and thereby mitigate semantic bias. Its Interference-Suppressed Refinement module suppresses attention on salient distractions to overcome contextual dominance. Experiments on high-resolution image understanding benchmarks show it outperforms prior training-free methods, reaching 96.34 percent accuracy on V* Bench.
What carries the argument
Semantic Anchor Localization (SAL) and Interference-Suppressed Refinement (ISR) modules that together enable active target search and self-correction of perception.
If this is right
- MLLMs can localize multiple targets independently instead of defaulting to the most salient object.
- Attention to distracting elements is reduced during refinement, improving localization accuracy.
- Fine-grained perception improves on high-resolution benchmarks without any model retraining.
- The active-search-plus-self-correction pattern becomes a viable alternative to attention-based or coarse-to-fine methods.
Where Pith is reading between the lines
- The same correction steps could be inserted into pipelines for other vision-language tasks that suffer from attention capture by salient but irrelevant content.
- If the modules prove modular, they might be combined with existing localization tools to create hybrid inference strategies.
- The results imply that perception errors in large models are often addressable at inference time rather than requiring architectural changes.
Load-bearing premise
That the main failures of prior methods arise from contextual dominance and semantic bias, and that the two new modules fix those problems without creating comparable new failure modes.
What would settle it
Running the same benchmarks and finding that ActiveScope accuracy does not exceed existing training-free baselines or that localization still misses multiple targets in high-resolution scenes.
Figures



read the original abstract
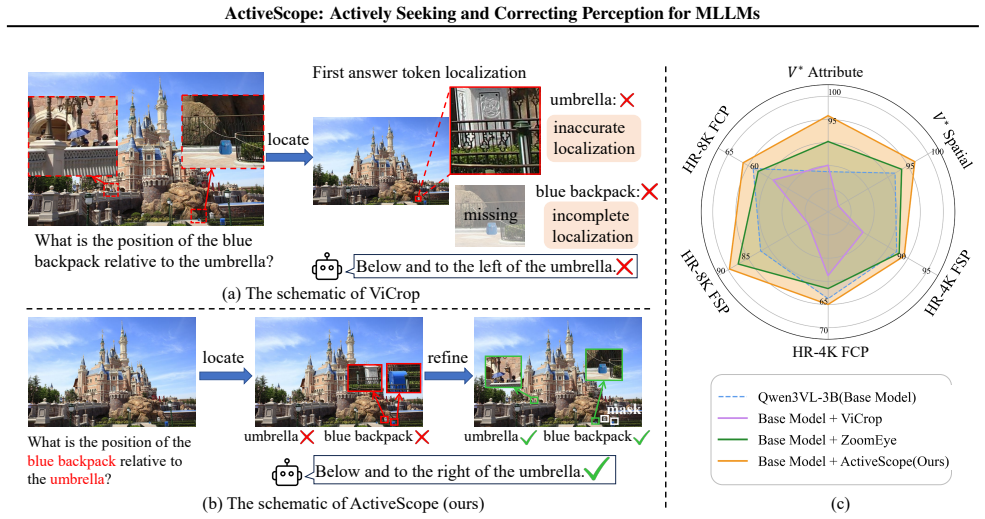
Multimodal Large Language Models (MLLMs) have demonstrated impressive vision-language understanding, yet still struggle with fine-grained perception in high-resolution images. While existing training-free methods typically rely on attention-based localization or coarse-to-fine search, they are often misled by distractors and fail to locate multiple targets. Our investigation attributes these failures to Contextual Dominance, where salient distractors overwhelm target attention and cause inaccurate localization, and Semantic Bias, where global semantics cause the model to fixate on the most salient concept, resulting in incomplete localization in multi-object scenarios. Built on these insights, we propose ActiveScope, a training-free framework that enhances MLLMs by actively seeking and correcting perception. ActiveScope features two modules. The Semantic Anchor Localization (SAL) utilizes fine-grained semantic anchors to independently localize key targets, thereby mitigating semantic bias. The Interference-Suppressed Refinement (ISR) refines localization by suppressing attention on salient distractions to overcome contextual dominance. Extensive experiments on high-resolution image understanding benchmarks demonstrate that ActiveScope outperforms existing training-free methods (e.g., 96.34 percent accuracy on $V^{*}$ Bench), validating the superiority of the active search and self-correction paradigm. Our code is available at https://github.com/jasmine-ww/ActiveScope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ActiveScope, a training-free framework for improving MLLMs' fine-grained perception on high-resolution images. It attributes failures in prior methods to Contextual Dominance (salient distractors overwhelming attention) and Semantic Bias (fixation on the most salient concept in multi-object scenes), and introduces two modules: Semantic Anchor Localization (SAL) to independently localize targets via fine-grained semantic anchors, and Interference-Suppressed Refinement (ISR) to suppress attention on distractions. The central claim is that these modules enable active search and self-correction, yielding superior results such as 96.34% accuracy on V* Bench over existing training-free baselines.
Significance. If the experimental results and attribution hold under proper controls, the work would be significant for demonstrating a training-free active-perception paradigm that could improve MLLM reliability on detailed visual tasks without retraining. The public code release supports reproducibility, which is a strength.
major comments (2)
- [Abstract] Abstract: The abstract asserts performance gains (e.g., 96.34% on V* Bench) and attributes them to the SAL and ISR modules, yet supplies no experimental protocol, baselines, error bars, ablation details, or statistical tests; verification of the central claim is impossible from the given text.
- [Abstract] Abstract: The claim that prior-method failures stem from Contextual Dominance and Semantic Bias, and that SAL/ISR directly mitigate them without new failure modes, is presented as an axiom without supporting analysis, failure-case studies, or controls that would make the attribution load-bearing.
minor comments (1)
- [Abstract] The abstract mentions 'extensive experiments on high-resolution image understanding benchmarks' but provides no list of datasets, metrics, or comparison methods.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript. We address the major comments on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts performance gains (e.g., 96.34% on V* Bench) and attributes them to the SAL and ISR modules, yet supplies no experimental protocol, baselines, error bars, ablation details, or statistical tests; verification of the central claim is impossible from the given text.
Authors: Abstracts by convention provide a concise overview without full methodological details or statistics. The experimental protocol, baselines, ablations, and results are detailed in Sections 4 and 5 of the manuscript, with code released for reproducibility. The 96.34% figure is from the V* Bench evaluation reported there. revision: no
-
Referee: [Abstract] Abstract: The claim that prior-method failures stem from Contextual Dominance and Semantic Bias, and that SAL/ISR directly mitigate them without new failure modes, is presented as an axiom without supporting analysis, failure-case studies, or controls that would make the attribution load-bearing.
Authors: The abstract summarizes our investigation into these failure modes, which is elaborated with qualitative examples, quantitative analysis, and ablation studies in the main text (Introduction and Section 3). These demonstrate how SAL and ISR address the identified issues without introducing new failure modes, as shown by comparative results. revision: no
Circularity Check
No significant circularity
full rationale
The paper describes an empirical training-free framework whose core claims rest on benchmark performance numbers (e.g., 96.34% on V* Bench) rather than any derivation, equation, or fitted parameter. The attribution of failures to Contextual Dominance and Semantic Bias is presented as an investigative finding that motivates the design of SAL and ISR; those modules are not shown to be defined in terms of the performance metric they are later evaluated on. No self-citations, uniqueness theorems, or ansatzes appear in the supplied text. The result is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
-
[2]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023a
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023a. Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., and Zhou, J. Qwen-vl: A versatile vision- language model for understanding, localization, text reading, and beyond.a...
-
[3]
Chen, Z., Wang, W., Cao, Y ., Liu, Y ., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al. Expanding per- formance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024a. Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al. Intern...
-
[4]
Vision transformers need registers
Darcet, T., Oquab, M., Mairal, J., and Bojanowski, P. Vision transformers need registers. InInternational Conference on Learning Representations, volume 2024, pp. 2632– 2652,
2024
-
[5]
Ge, C., Cheng, S., Wang, Z., Yuan, J., Gao, Y ., Song, J., Song, S., Huang, G., and Zheng, B. Convllava: Hierar- chical backbones as visual encoder for large multimodal models.arXiv preprint arXiv:2405.15738,
-
[6]
Liu, X., Hu, Y ., Zou, Y ., Wu, L., Xu, J., and Zheng, B. Hide: Rethinking the zoom-in method in high resolu- tion mllms via hierarchical decoupling.arXiv preprint arXiv:2510.00054,
-
[7]
Liu, Z., Dong, Y ., Rao, Y ., Zhou, J., and Lu, J. Chain-of-spot: Interactive reasoning improves large vision-language models.arXiv preprint arXiv:2403.12966,
-
[8]
Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models
Luo, G., Zhou, Y ., Zhang, Y ., Zheng, X., Sun, X., and Ji, R. Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models. InInternational Conference on Learning Representations, volume 2025, pp. 84491–84506,
2025
-
[9]
Mao, S., Zhang, C., and Cai, W. Through the magnifying glass: Adaptive perception magnification for hallucination-free vlm decoding.arXiv preprint arXiv:2503.10183,
-
[10]
Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based im- age exploration
Shen, H., Zhao, K., Zhao, T., Xu, R., Zhang, Z., Zhu, M., and Yin, J. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based im- age exploration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 6613–6629,
2025
-
[11]
Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
-
[12]
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
-
[13]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[14]
Yang, F. and Zhang, K. Mrd: Multi-resolution retrieval- detection fusion for high-resolution image understanding. arXiv preprint arXiv:2512.02906,
-
[15]
Zhai, Y ., Tong, S., Li, X., Cai, M., Qu, Q., Lee, Y . J., and Ma, Y . Investigating the catastrophic forgetting in multimodal large language models.arXiv preprint arXiv:2309.10313,
-
[16]
Mllms know where to look: Training-free perception of small visual details with multimodal llms
Zhang, J., Khayatkhoei, M., Chhikara, P., and Ilievski, F. Mllms know where to look: Training-free perception of small visual details with multimodal llms. InInterna- tional Conference on Learning Representations, volume 2025, pp. 68194–68213, 2025a. Zhang, Y ., Zhang, H., Tian, H., Fu, C., Zhang, S., Wu, J., Li, F., Wang, K., Wen, Q., Zhang, Z., et al. M...
2025
-
[17]
Zhou, Y ., Jiang, C., Yuan, C., and Li, J. Look where it matters: Training-free ultra-hr remote sensing vqa via adaptive zoom search.arXiv preprint arXiv:2511.20460,
-
[18]
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
-
[19]
11 ActiveScope: Actively Seeking and Correcting Perception for MLLMs A. Algorithm of ActiveScope The pseudocode for the ActiveScope method is provided below. Algorithm 1Complete Algorithm Workflow of ActiveScope Require:ImageI, QueryQ, MLLM maskM, Iteration LimitC Ensure:Final responseY response 1:S← M.generate(I, p extract) 2:S bbox ← ∅ 3:Initialize Atte...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.