ACPO: Agent-Chained Policy Optimization for Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-30 06:04 UTC · model grok-4.3
The pith
The joint policy gradient in cooperative MARL decomposes exactly into independent per-agent updates using decentralized critics and action-serialization beliefs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
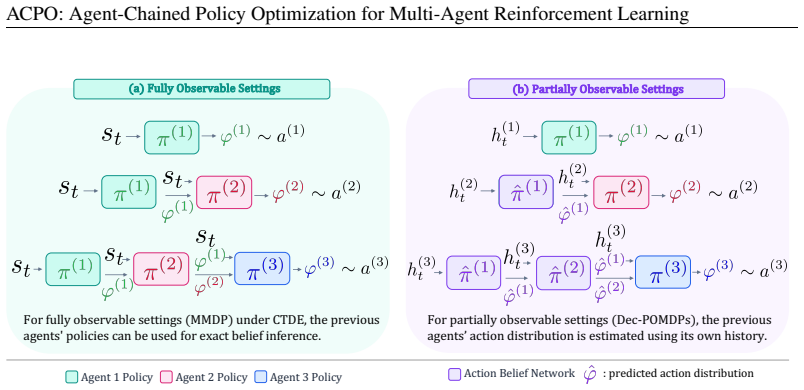
We show the joint policy gradient admits an exact decentralized decomposition of per-agent terms, each formed from per-agent score functions and decentralized critics. Based on this decomposition, we develop Agent-Chained Policy Optimization (ACPO), where actors are trained independently, with their updates together constituting a single step on the joint policy gradient. Central to this result is a serialized view of the simultaneous joint decision in which agents commit actions one at a time, each conditioning on a belief over preceding actions. The belief acts as the coordination mechanism which ties the independent per-agent updates into a joint gradient step.
What carries the argument
Exact decentralized decomposition of the joint policy gradient via serialized action commitment, where each agent conditions on a belief distribution over preceding agents' actions.
If this is right
- Independent actor training yields updates that together equal one exact step on the joint policy gradient.
- No value-decomposition assumptions are required to guarantee joint improvement.
- The method sidesteps convergence to suboptimal Nash equilibria that can occur with alternating best-response updates.
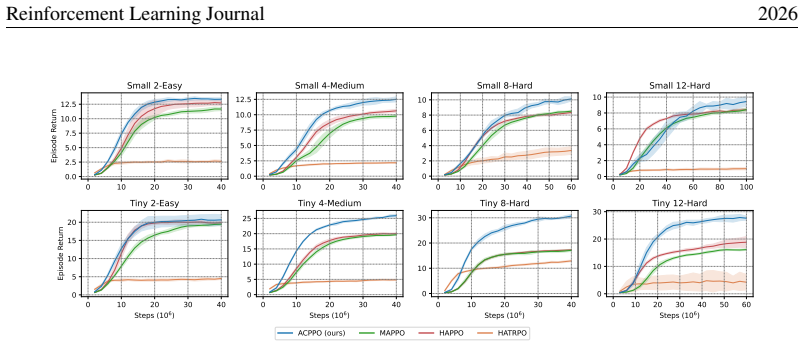
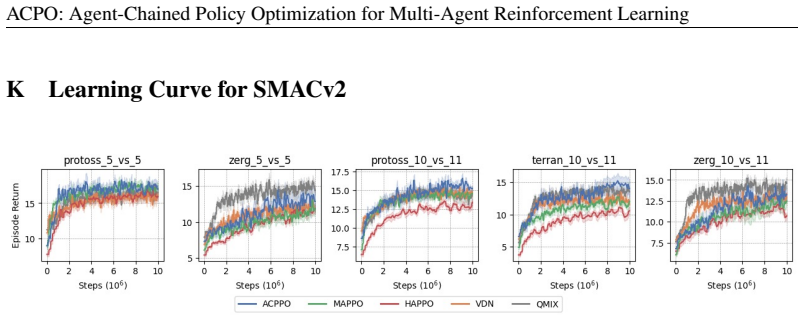
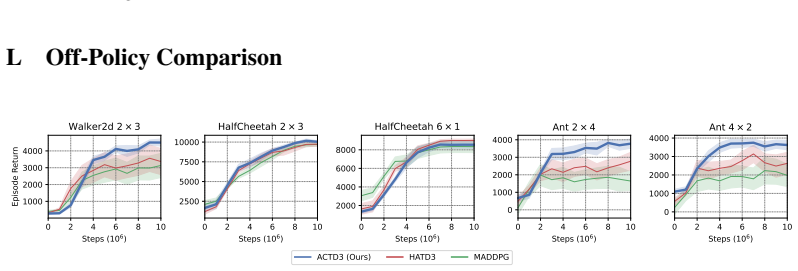
- Empirical gains appear on Multi-Robot Warehouse, SMACv2, and MA-MuJoCo, widening as the number of agents increases.
Where Pith is reading between the lines
- The belief-over-preceding-actions construction may allow coordination without explicit communication channels.
- The same serialization idea could be tested in non-cooperative or partially observable settings where joint gradients are otherwise intractable.
- If the beliefs themselves can be learned from local observations alone, centralized critics might be removed entirely in future variants.
Load-bearing premise
Simultaneous joint decisions can be treated as a strict sequence in which every agent conditions on a belief over the actions that preceded it.
What would settle it
A direct numerical check showing that the sum of the independent per-agent gradients computed under the belief conditioning does not recover the true joint policy gradient on a small cooperative task.
Figures



read the original abstract
Cooperative tasks in Multi-Agent Reinforcement Learning (MARL) require agents to collectively maximize a shared return. Under the Centralized Training with Decentralized Execution (CTDE) paradigm, policy gradients have remained difficult to compute directly. Prior methods largely follow two approaches: independent factorized updates with centralized critics, which lack general joint-improvement guarantees without value decomposition assumptions, or alternating best-response updates, which can converge to suboptimal Nash Equilibria. In this paper, we show the joint policy gradient admits an exact decentralized decomposition of per-agent terms, each formed from per-agent score functions and decentralized critics. Based on this decomposition, we develop Agent-Chained Policy Optimization (ACPO), where actors are trained independently, with their updates together constituting a single step on the joint policy gradient. Central to this result is a serialized view of the simultaneous joint decision in which agents commit actions one at a time, each conditioning on a belief over preceding actions. The belief acts as the coordination mechanism which ties the independent per-agent updates into a joint gradient step. We evaluate ACPO on Multi-Robot Warehouse, SMACv2, and MA-MuJoCo, where it outperforms strong baselines, with the gap widening as the number of agents grows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the joint policy gradient in cooperative MARL admits an exact decentralized decomposition into per-agent terms formed from per-agent score functions and decentralized critics. It introduces ACPO, in which independent actor training produces updates that together constitute a single step on the joint gradient. The key device is a serialized view of simultaneous actions in which each agent conditions on a belief over preceding agents' actions; this belief is presented as the coordination mechanism that preserves exactness. Empirical results on Multi-Robot Warehouse, SMACv2, and MA-MuJoCo are reported to show outperformance over strong baselines, with the advantage increasing with the number of agents.
Significance. If the claimed exact decomposition can be rigorously established and the belief mechanism shown to be realizable under fully independent training without reintroducing centralization or non-vanishing approximation error, the result would be significant. It would supply joint-improvement guarantees for decentralized execution without value-decomposition assumptions or alternating best-response dynamics, addressing a long-standing tension in CTDE methods.
major comments (3)
- [Abstract / §3] Abstract and §3 (decomposition): The claim that the joint policy gradient 'admits an exact decentralized decomposition' is asserted without a derivation or proof in the abstract; the full manuscript must supply the explicit expansion of the joint gradient and demonstrate term-by-term equality under the serialized belief construction.
- [Abstract] Abstract (belief mechanism): The exactness guarantee rests on each agent's belief over preceding actions equaling the marginal induced by the current policies of those agents. Because actors are trained independently, the manuscript must specify how these beliefs are obtained or sampled at each gradient step; any mechanism that requires joint rollouts or shared parameters would contradict the 'independent' training claim, while an approximation would require a separate error analysis showing that the bias vanishes in the limit.
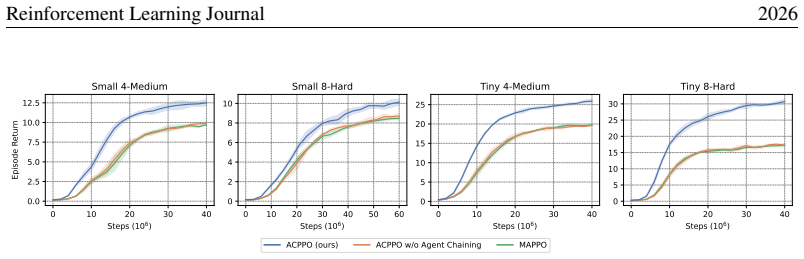
- [Evaluation] Evaluation section: The abstract states that ACPO 'outperforms strong baselines' with the gap widening as the number of agents grows, yet supplies no metrics, statistical tests, baseline descriptions, or ablation on the belief construction. These details are load-bearing for the empirical claim that the method scales.
minor comments (1)
- [§3] Notation for the per-agent score functions and decentralized critics should be introduced with explicit definitions before the decomposition is stated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (decomposition): The claim that the joint policy gradient 'admits an exact decentralized decomposition' is asserted without a derivation or proof in the abstract; the full manuscript must supply the explicit expansion of the joint gradient and demonstrate term-by-term equality under the serialized belief construction.
Authors: Section 3 already contains the derivation of the joint gradient and its per-agent decomposition under the serialized belief model, including the explicit expansion showing term-by-term equality. We will revise the abstract to briefly reference the key expansion steps and add a compact term-by-term equality display in §3 for improved readability. This is a partial revision. revision: partial
-
Referee: [Abstract] Abstract (belief mechanism): The exactness guarantee rests on each agent's belief over preceding actions equaling the marginal induced by the current policies of those agents. Because actors are trained independently, the manuscript must specify how these beliefs are obtained or sampled at each gradient step; any mechanism that requires joint rollouts or shared parameters would contradict the 'independent' training claim, while an approximation would require a separate error analysis showing that the bias vanishes in the limit.
Authors: Each agent forms its belief by sampling from the current policy parameters of preceding agents, which are exchanged once per gradient step (standard in CTDE without requiring joint rollouts or parameter sharing during actor updates). This yields an exact marginal match. We will insert a dedicated paragraph in §3.2 detailing the sampling procedure and confirming independence of the actor updates. revision: yes
-
Referee: [Evaluation] Evaluation section: The abstract states that ACPO 'outperforms strong baselines' with the gap widening as the number of agents grows, yet supplies no metrics, statistical tests, baseline descriptions, or ablation on the belief construction. These details are load-bearing for the empirical claim that the method scales.
Authors: The evaluation section already reports mean returns with standard errors, paired t-tests for significance, full baseline descriptions (MAPPO, HAPPO, etc.), and an ablation isolating the belief mechanism, with scaling trends shown across agent counts in all three domains. We will add a concise quantitative summary to the abstract and cross-reference the ablation explicitly. revision: partial
Circularity Check
No circularity; derivation self-contained under serialized belief model
full rationale
The paper derives an exact decentralized decomposition of the joint policy gradient by introducing a serialized action commitment view in which each agent conditions on a belief over preceding actions. This belief is explicitly posited as the coordination mechanism that makes independent per-agent updates sum to the joint gradient. No equations reduce by construction to fitted parameters, self-citations, or renamed empirical patterns; the result follows from the stated assumptions on the joint policy and the belief representation rather than presupposing the target decomposition. The claim is therefore not equivalent to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The CTDE paradigm is the appropriate setting and the serialized belief view over preceding actions serves as a valid coordination mechanism for independent updates.
Reference graph
Works this paper leans on
-
[1]
Albrecht and Filippos Christianos and Lukas Sch
Stefano V. Albrecht and Filippos Christianos and Lukas Sch. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches , publisher =. 2024 , url =
2024
-
[2]
2022 , url=
Jianhong Wang and Yuan Zhang and Yunjie Gu and Tae-Kyun Kim , booktitle=. 2022 , url=
2022
-
[3]
2008 , publisher =
Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations , author =. 2008 , publisher =
2008
-
[4]
Advances in Neural Information Processing Systems , editor=
Agent Modelling under Partial Observability for Deep Reinforcement Learning , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[5]
and Doshi, Prashant , title =
Gmytrasiewicz, Piotr J. and Doshi, Prashant , title =. 2005 , publisher =
2005
-
[6]
and Tuyls, Karl and Graepel, Thore , title =
Sunehag, Peter and Lever, Guy and Gruslys, Audrunas and Czarnecki, Wojciech Marian and Zambaldi, Vinicius and Jaderberg, Max and Lanctot, Marc and Sonnerat, Nicolas and Leibo, Joel Z. and Tuyls, Karl and Graepel, Thore , title =. Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems , pages =. 2018 , publisher =
2018
-
[7]
NeurIPS , year=
Multi-Agent Reinforcement Learning for Active Voltage Control on Power Distribution Networks , author=. NeurIPS , year=
-
[8]
2024 , eprint=
Multi-Agent Reinforcement Learning for Autonomous Driving: A Survey , author=. 2024 , eprint=
2024
-
[9]
Addressing Function Approximation Error in Actor-Critic Methods , booktitle =
Scott Fujimoto and Herke van Hoof and David Meger , editor =. Addressing Function Approximation Error in Actor-Critic Methods , booktitle =. 2018 , url =
2018
-
[10]
Multi-Agent Deep Reinforcement Learning for Large-Scale Traffic Signal Control , year=
Chu, Tianshu and Wang, Jie and Codecà, Lara and Li, Zhaojian , journal=. Multi-Agent Deep Reinforcement Learning for Large-Scale Traffic Signal Control , year=
-
[11]
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages =
Lin, Kaixiang and Zhao, Renyu and Xu, Zhe and Zhou, Jiayu , title =. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages =. 2018 , publisher =
2018
-
[12]
2022 , isbn =
Wen, Muning and Kuba, Jakub Grudzien and Lin, Runji and Zhang, Weinan and Wen, Ying and Wang, Jun and Yang, Yaodong , title =. 2022 , isbn =
2022
-
[13]
2023 , eprint=
Towards Global Optimality in Cooperative MARL with the Transformation And Distillation Framework , author=. 2023 , eprint=
2023
-
[14]
2018 , url=
Benchmarks for Spinning Up Implementations , author=. 2018 , url=
2018
-
[15]
Dimitri P. Bertsekas , title =. CoRR , volume =. 2019 , url =. 1910.00120 , timestamp =
-
[16]
2001 , publisher =
Guestrin, Carlos and Koller, Daphne and Parr, Ronald , title =. 2001 , publisher =
2001
-
[17]
2012 , booktitle =
Raghavan, Aswin and Joshi, Saket and Fern, Alan and Tadepallia, Prasad and Khardonb, Roni , title =. 2012 , booktitle =
2012
-
[18]
Albrecht and Peter Stone , keywords =
Stefano V. Albrecht and Peter Stone , keywords =. Autonomous agents modelling other agents: A comprehensive survey and open problems , journal =. 2018 , issn =. doi:https://doi.org/10.1016/j.artint.2018.01.002 , url =
-
[19]
2025 , eprint=
LLM Collaboration With Multi-Agent Reinforcement Learning , author=. 2025 , eprint=
2025
-
[20]
AutoGen: Enabling Next-Gen
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and Ahmed Hassan Awadallah and Ryen W White and Doug Burger and Chi Wang , booktitle=. AutoGen: Enabling Next-Gen. 2024 , url=
2024
-
[21]
Al and Yogamani, Senthil and Pérez, Patrick , journal=
Kiran, B Ravi and Sobh, Ibrahim and Talpaert, Victor and Mannion, Patrick and Sallab, Ahmad A. Al and Yogamani, Senthil and Pérez, Patrick , journal=. Deep Reinforcement Learning for Autonomous Driving: A Survey , year=
-
[22]
2022 , publisher=
Training language models to follow instructions with human feedback , author=. 2022 , publisher=
2022
-
[23]
ICML , pages =
Trust Region Policy Optimization , author =. ICML , pages =. 2015 , volume =
2015
-
[24]
JMLR , year =
Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang , title =. JMLR , year =
-
[25]
ICML , pages =
Individual Reward Assisted Multi-Agent Reinforcement Learning , author =. ICML , pages =. 2022 , volume =
2022
-
[26]
2021 , url=
Yihan Wang and Beining Han and Tonghan Wang and Heng Dong and Chongjie Zhang , booktitle=. 2021 , url=
2021
-
[27]
Proceedings of the 35th International Conference on Machine Learning , pages =
Mean Field Multi-Agent Reinforcement Learning , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[28]
Jordan and Pieter Abbeel , title =
John Schulman and Philipp Moritz and Sergey Levine and Michael I. Jordan and Pieter Abbeel , title =. ICLR , year =
-
[29]
2020 , eprint=
Multiagent Value Iteration Algorithms in Dynamic Programming and Reinforcement Learning , author=. 2020 , eprint=
2020
-
[30]
Lillicrap and Jonathan J
Timothy P. Lillicrap and Jonathan J. Hunt and Alexander Pritzel and Nicolas Heess and Tom Erez and Yuval Tassa and David Silver and Daan Wierstra , title =. 4th International Conference on Learning Representations,. 2016 , url =
2016
-
[31]
2020 , eprint=
Open Problems in Cooperative AI , author=. 2020 , eprint=
2020
-
[32]
Reinforcement Learning: Theory and Algorithms , author =
-
[34]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[35]
Shani, Guy and Pineau, Joelle and Kaplow, Robert , title =. 2013 , issue_date =. doi:10.1007/s10458-012-9200-2 , journal =
-
[36]
and Tsitsiklis, John N
Papadimitriou, Christos H. and Tsitsiklis, John N. , title =. Math. Oper. Res. , month = aug, pages =. 1987 , issue_date =
1987
-
[37]
When Do Transformers Shine in
Tianwei Ni and Michel Ma and Benjamin Eysenbach and Pierre-Luc Bacon , booktitle=. When Do Transformers Shine in. 2023 , url=
2023
-
[38]
Recurrent Model-Free
Tianwei Ni and Benjamin Eysenbach and Sergey Levine and Ruslan Salakhutdinov , publisher=. Recurrent Model-Free. 2022 , url=
2022
-
[39]
Proceedings of the 35th International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[40]
A Comprehensive Survey of Multiagent Reinforcement Learning , year=
Busoniu, Lucian and Babuska, Robert and De Schutter, Bart , journal=. A Comprehensive Survey of Multiagent Reinforcement Learning , year=
-
[41]
Proceedings of the 6th Conference on Theoretical Aspects of Rationality and Knowledge , pages =
Boutilier, Craig , title =. Proceedings of the 6th Conference on Theoretical Aspects of Rationality and Knowledge , pages =. 1996 , isbn =
1996
-
[42]
2022 , eprint=
Revisiting Some Common Practices in Cooperative Multi-Agent Reinforcement Learning , author=. 2022 , eprint=
2022
-
[43]
The Complexity of Decentralized Control of Markov Decision Processes , volume =
Bernstein, Daniel and Givan, Robert and Immerman, Neil and Zilberstein, Shlomo , year =. The Complexity of Decentralized Control of Markov Decision Processes , volume =. Mathematics of Operations Research , doi =
-
[44]
Samuel Sokota and Edward Lockhart and Finbarr Timbers and Elnaz Davoodi and Ryan D'Orazio and Neil Burch and Martin Schmid and Michael Bowling and Marc Lanctot , title =. Thirty-Fifth. 2021 , url =. doi:10.1609/AAAI.V35I11.17166 , timestamp =
-
[45]
Johan Peralez and Aur. Optimally Solving Simultaneous-Move Dec-POMDPs: The Sequential Central Planning Approach , booktitle =. 2025 , url =. doi:10.1609/AAAI.V39I22.34494 , biburl =
-
[46]
Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages =
Common Information based Approximate State Representations in Multi-Agent Reinforcement Learning , author =. Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages =. 2022 , editor =
2022
-
[47]
2024 , eprint=
A First Introduction to Cooperative Multi-Agent Reinforcement Learning , author=. 2024 , eprint=
2024
-
[48]
NeurIPS Datasets and Benchmarks Track (Round 1) , year=
Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks , author=. NeurIPS Datasets and Benchmarks Track (Round 1) , year=
-
[49]
A unified game-theoretic approach to multiagent reinforcement learning , year =
Lanctot, Marc and Zambaldi, Vinicius and Gruslys, Audr\=. A unified game-theoretic approach to multiagent reinforcement learning , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[50]
Kova. Rethinking formal models of partially observable multiagent decision making (extended abstract) , year =. doi:10.24963/ijcai.2023/783 , booktitle =
-
[51]
Lyu, Xueguang and Baisero, Andrea and Xiao, Yuchen and Daley, Brett and Amato, Christopher , title =. 2023 , issue_date =. doi:10.1613/jair.1.14386 , journal =
-
[52]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Yang, Yaodong and Wen, Ying and Chen, Liheng and Wang, Jun and Shao, Kun and Mguni, David and Zhang, Weinan , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[53]
NeurIPS , year=
Settling the Variance of Multi-Agent Policy Gradients , author=. NeurIPS , year=
-
[54]
ICLR , year=
Maximum Entropy Heterogeneous-Agent Reinforcement Learning , author=. ICLR , year=
-
[55]
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games , url =
Brown, Noam and Bakhtin, Anton and Lerer, Adam and Gong, Qucheng , booktitle =. Combining Deep Reinforcement Learning and Search for Imperfect-Information Games , url =. 2020 , Bdsk-Url-1 =
2020
-
[56]
and Zilberstein, Shlomo and Immerman, Neil , title =
Bernstein, Daniel S. and Zilberstein, Shlomo and Immerman, Neil , title =. Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence , pages =. 2000 , isbn =
2000
-
[57]
2024 , eprint=
Large Language Model based Multi-Agents: A Survey of Progress and Challenges , author=. 2024 , eprint=
2024
-
[58]
2021 , url=
Bei Peng and Tabish Rashid and Christian Schroeder de Witt and Pierre-Alexandre Kamienny and Philip Torr and Wendelin Boehmer and Shimon Whiteson , booktitle=. 2021 , url=
2021
-
[59]
2023 , url=
Benjamin Ellis and Jonathan Cook and Skander Moalla and Mikayel Samvelyan and Mingfei Sun and Anuj Mahajan and Jakob Nicolaus Foerster and Shimon Whiteson , booktitle=. 2023 , url=
2023
-
[60]
Foerster and Sarath Chandar and Neil Burch and Marc Lanctot and H
Nolan Bard and Jakob N. Foerster and Sarath Chandar and Neil Burch and Marc Lanctot and H. Francis Song and Emilio Parisotto and Vincent Dumoulin and Subhodeep Moitra and Edward Hughes and Iain Dunning and Shibl Mourad and Hugo Larochelle and Marc G. Bellemare and Michael Bowling , doi =. The Hanabi challenge: A new frontier for AI research , url =. Artif...
2020
-
[61]
2019 , eprint=
Soft Actor-Critic for Discrete Action Settings , author=. 2019 , eprint=
2019
-
[62]
JMLR , year =
Yifan Zhong and Jakub Grudzien Kuba and Xidong Feng and Siyi Hu and Jiaming Ji and Yaodong Yang , title =. JMLR , year =
-
[63]
2020 , eprint=
Is Independent Learning All You Need in the StarCraft Multi-Agent Challenge? , author=. 2020 , eprint=
2020
-
[64]
Counterfactual Multi-Agent Policy Gradients , url =
Foerster, Jakob and Farquhar, Gregory and Afouras, Triantafyllos and Nardelli, Nantas and Whiteson, Shimon , journal =. Counterfactual Multi-Agent Policy Gradients , url =
-
[65]
2018 , volume =
Rashid, Tabish and Samvelyan, Mikayel and Schroeder, Christian and Farquhar, Gregory and Foerster, Jakob and Whiteson, Shimon , booktitle =. 2018 , volume =
2018
-
[66]
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , url =
Lowe, Ryan and WU, YI and Tamar, Aviv and Harb, Jean and Pieter Abbeel, OpenAI and Mordatch, Igor , booktitle =. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , url =
-
[67]
ICLR , year=
More Centralized Training, Still Decentralized Execution: Multi-Agent Conditional Policy Factorization , author=. ICLR , year=
-
[68]
The Surprising Effectiveness of
Chao Yu and Akash Velu and Eugene Vinitsky and Jiaxuan Gao and Yu Wang and Alexandre Bayen and Yi Wu , booktitle=. The Surprising Effectiveness of. 2022 , url=
2022
-
[69]
ICLR , year=
Trust Region Policy Optimisation in Multi-Agent Reinforcement Learning , author=. ICLR , year=
-
[70]
2021 , volume =
Zhang, Tianhao and Li, Yueheng and Wang, Chen and Xie, Guangming and Lu, Zongqing , booktitle =. 2021 , volume =
2021
-
[71]
Hauskrecht, Milos , title =. J. Artif. Int. Res. , month = aug, pages =. 2000 , issue_date =
2000
-
[72]
2022 , eprint=
Optimistic Policy Optimization is Provably Efficient in Non-stationary MDPs , author=. 2022 , eprint=
2022
-
[73]
Reinforcement Learning for Control with Multiple Frequencies , url =
Lee, Jongmin and Lee, Byung-Jun and Kim, Kee-Eung , booktitle =. Reinforcement Learning for Control with Multiple Frequencies , url =
-
[74]
and Amato, Christopher , title =
Oliehoek, Frans A. and Amato, Christopher , title =. 2016 , isbn =
2016
-
[75]
2019 , url=
Reinforcement Learning: Theory and Algorithms , author=. 2019 , url=
2019
-
[76]
International Conference on Learning Representations , year=
On the Convergence of the Monte Carlo Exploring Starts Algorithm for Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[77]
Policy Iteration for Decentralized Control of Markov Decision Processes , volume =
Bernstein, Daniel and Amato, Christopher and Hansen, Eric and Zilberstein, Shlomo , year =. Policy Iteration for Decentralized Control of Markov Decision Processes , volume =. J. Artif. Intell. Res. (JAIR) , doi =
-
[78]
and Bernstein, Daniel S
Hansen, Eric A. and Bernstein, Daniel S. and Zilberstein, Shlomo , title =. 2004 , isbn =
2004
-
[79]
Optimally solving Dec-POMDPs as continuous-state MDPs , year =
Dibangoye, Jilles Steeve and Amato, Christopher and Buffet, Olivier and Charpillet, Fran. Optimally solving Dec-POMDPs as continuous-state MDPs , year =. J. Artif. Int. Res. , month =
-
[80]
and Powley, Edward J
Cowling, Peter I. and Powley, Edward J. and Whitehouse, Daniel , journal=. Information Set Monte Carlo Tree Search , year=
-
[81]
2013 , url=
An Introduction to Counterfactual Regret Minimization , author=. 2013 , url=
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.