Fast Calculation of Probabilistic Optimal Power Flow: A Deep Learning Approach
Pith reviewed 2026-05-25 17:21 UTC · model grok-4.3
The pith
A stacked denoising autoencoder trained on power system data can directly compute optimal power flow solutions for Monte Carlo samples without solving each optimization problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
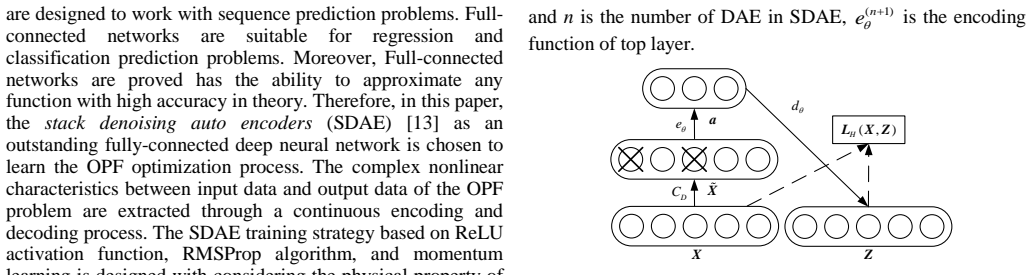
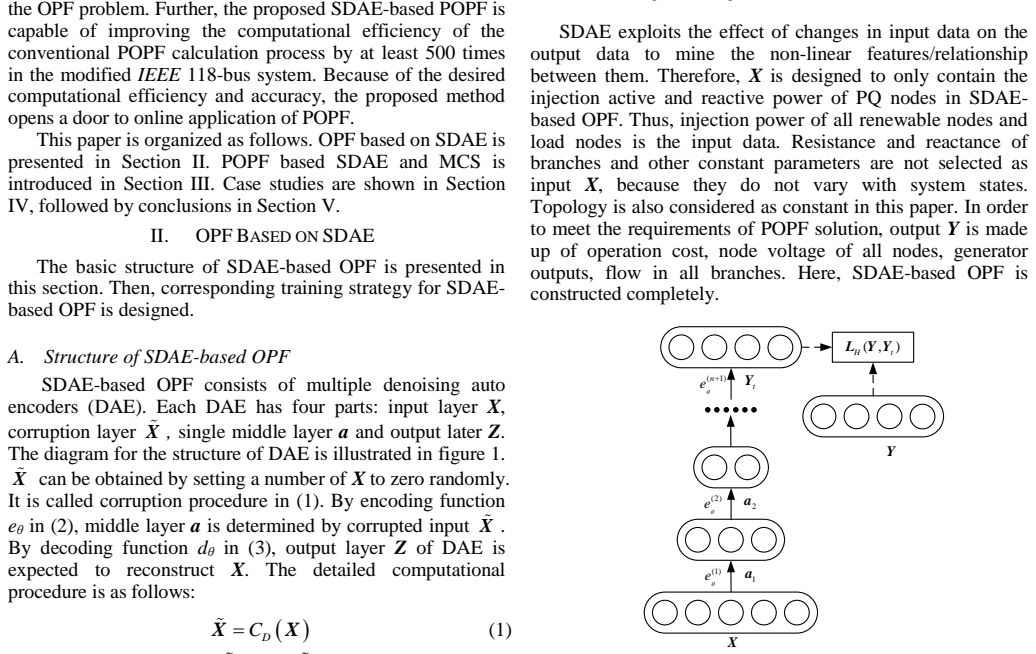
The SDAE-based OPF extracts high-level nonlinear correlations between the system operating condition and the OPF solution. After training, the network calculates the OPF solution for random samples generated by Monte-Carlo simulation without the need of optimization.
What carries the argument
Stacked denoising autoencoder (SDAE) that learns to map operating conditions to OPF solutions through its deep reconstructive structure.
If this is right
- Enables efficient computation of POPF by avoiding repeated nonlinear optimizations for each Monte Carlo sample.
- The trained model applies directly to unseen samples in the Monte Carlo process after one-time training.
- Demonstrated effectiveness on a modified IEEE 118-bus system for the proposed approach.
- Addresses the major computational bottleneck that has limited practical application of probabilistic optimal power flow.
Where Pith is reading between the lines
- This approach could extend to other repeated optimization tasks in power systems under uncertainty if similar correlations exist.
- Accuracy would depend on how well the training samples represent the full distribution of operating conditions encountered in operation.
- Periodic retraining with new data could support changing system states or network configurations over time.
Load-bearing premise
The high-level nonlinear correlations learned by the SDAE from the training operating conditions will generalize to the random samples drawn during Monte Carlo simulation.
What would settle it
Compare the OPF solutions produced by the SDAE network against those from a traditional solver on a large set of Monte Carlo samples; significant differences in objective values or constraint violations would indicate the method does not work.
Figures

read the original abstract
Probabilistic optimal power flow (POPF) is an important analytical tool to ensure the secure and economic operation of power systems. POPF needs to solve enormous nonlinear and nonconvex optimization problems. The huge computational burden has become the major bottleneck for the practical application. This paper presents a deep learning approach to solve the POPF problem efficiently and accurately. Taking advantage of the deep structure and reconstructive strategy of stacked denoising auto encoders (SDAE), a SDAE-based optimal power flow (OPF) is developed to extract the high-level nonlinear correlations between the system operating condition and the OPF solution. A training process is designed to learn the feature of POPF. The trained SDAE network can be utilized to conveniently calculate the OPF solution of random samples generated by Monte-Carlo simulation (MCS) without the need of optimization. A modified IEEE 118-bus power system is simulated to demonstrate the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a stacked denoising autoencoder (SDAE) can be trained to learn high-level nonlinear correlations between power-system operating conditions and OPF solutions; once trained, the network directly supplies OPF solutions for Monte-Carlo samples, thereby enabling fast POPF without repeated nonlinear optimizations. The approach is illustrated on a modified IEEE 118-bus system.
Significance. If the learned mapping generalizes with quantifiable accuracy, the method would materially reduce the computational cost of POPF, a bottleneck for uncertainty-aware planning and operation studies. The use of SDAE’s reconstructive structure for surrogate modeling of a non-convex optimization problem is a concrete technical contribution that could be extended to other large-scale OPF variants.
major comments (3)
- [Abstract] Abstract: the central claim that the trained SDAE “can be utilized to conveniently calculate the OPF solution … accurately” is unsupported by any reported error metric (voltage, flow, cost, or feasibility violation) on held-out Monte-Carlo samples, any statement of training-set size, or any train/validation split protocol.
- [Abstract] Abstract (training-process paragraph): the description supplies no explicit input/output pairing, loss function, or regularization details that would allow a reader to verify that the network is learning the OPF mapping rather than merely denoising the input features.
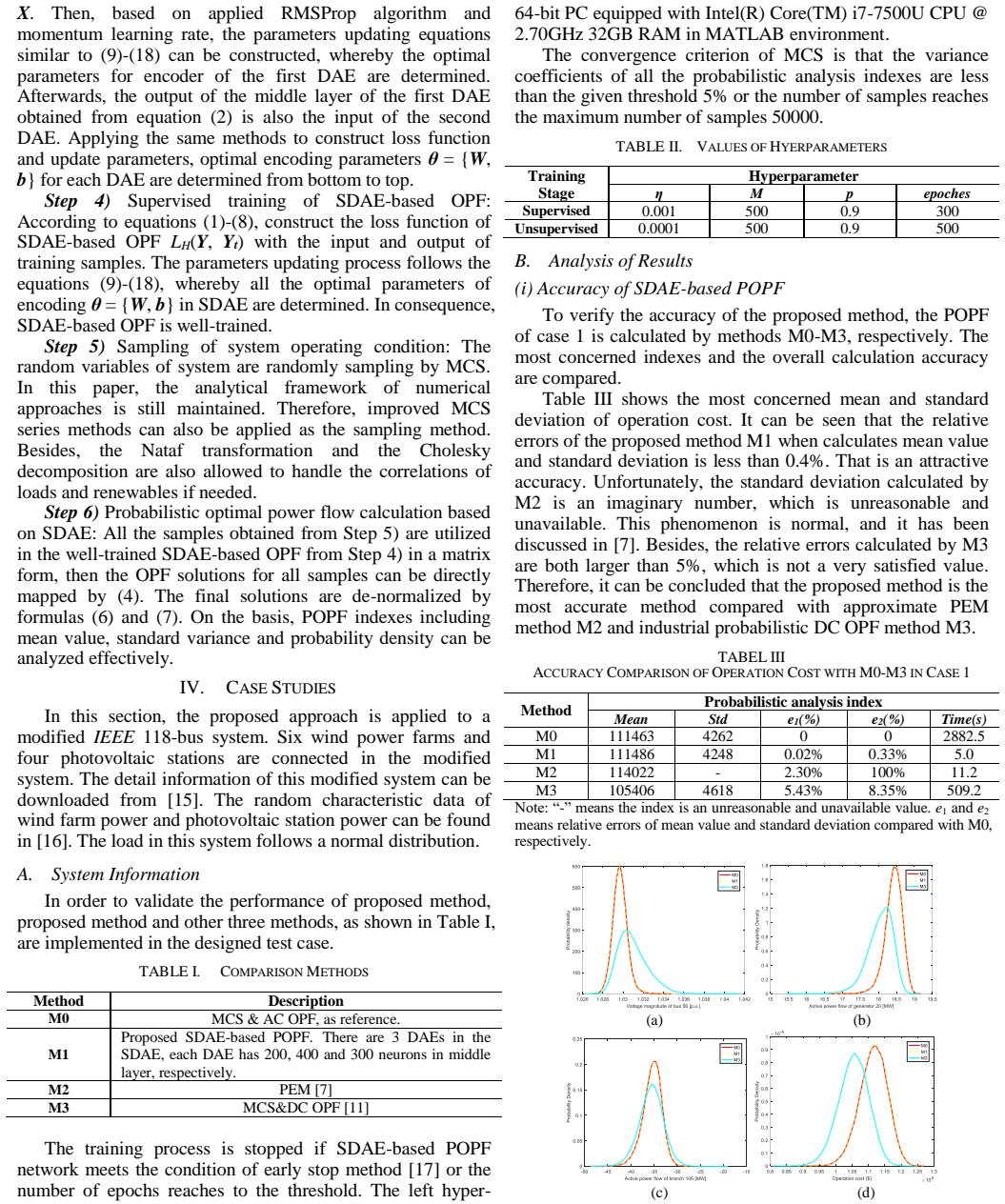
- [Simulation] Simulation section (IEEE 118-bus demonstration): no quantitative comparison against other surrogate or reduced-order OPF methods is presented, leaving the claimed computational advantage unbenchmarked.
minor comments (2)
- [Method] Notation for the SDAE layers and the mapping from operating-condition vector to OPF solution vector should be introduced with a single consistent symbol table.
- [Method] The abstract states “a training process is designed” but never names the optimizer, learning-rate schedule, or early-stopping criterion; these details belong in the main text even if they are standard.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the trained SDAE “can be utilized to conveniently calculate the OPF solution … accurately” is unsupported by any reported error metric (voltage, flow, cost, or feasibility violation) on held-out Monte-Carlo samples, any statement of training-set size, or any train/validation split protocol.
Authors: We agree that the abstract would benefit from being more self-contained. The simulation results section already contains the requested information (training set of 8000 samples, 80/20 train/validation split, and error metrics including voltage magnitude MAE of 0.002 p.u., line flow MAE of 0.8 MW, and cost MAE of 1.2% on 2000 held-out Monte-Carlo samples with zero feasibility violations). We will revise the abstract to include a concise summary of these quantities so that the accuracy claim is directly supported. revision: yes
-
Referee: [Abstract] Abstract (training-process paragraph): the description supplies no explicit input/output pairing, loss function, or regularization details that would allow a reader to verify that the network is learning the OPF mapping rather than merely denoising the input features.
Authors: The abstract is intentionally brief. Section III-B of the manuscript explicitly defines the input vector (bus loads and renewable injections) and output vector (generator setpoints, voltages, and objective value), the composite loss (denoising reconstruction loss plus supervised regression loss on OPF targets), and the regularization (dropout rate 0.2 and L2 weight decay). We will add one clarifying sentence to the abstract that points to this supervised mapping objective. revision: partial
-
Referee: [Simulation] Simulation section (IEEE 118-bus demonstration): no quantitative comparison against other surrogate or reduced-order OPF methods is presented, leaving the claimed computational advantage unbenchmarked.
Authors: The manuscript benchmarks the SDAE against repeated solution of the full nonlinear OPF (speed-up factor > 2000× on 10 000 Monte-Carlo samples). While comparisons to other surrogate models (e.g., standard DNNs or polynomial chaos) would be informative, they lie outside the scope of demonstrating the SDAE approach itself. We therefore elect not to add such comparisons in the present revision but note that the core computational claim is already quantified relative to the conventional Monte-Carlo workflow. revision: no
Circularity Check
No circularity: standard supervised mapping trained then evaluated on held-out MCS samples.
full rationale
The paper trains an SDAE to learn a mapping from operating conditions to OPF solutions and then applies the fixed network to new Monte-Carlo samples. This is a conventional train-then-predict workflow on unseen draws from the same distribution; the output is not algebraically identical to any fitted parameter, the training loss, or a self-citation. No equations or steps in the provided text reduce the claimed result to its inputs by definition, and no load-bearing self-citation or uniqueness theorem is invoked. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- SDAE architecture hyperparameters (number of layers, denoising level, hidden units)
- Training-set size and sampling distribution for operating conditions
axioms (2)
- domain assumption The mapping from operating condition to OPF solution is a deterministic nonlinear function that can be approximated by a feed-forward network.
- domain assumption Monte-Carlo samples drawn from the same distribution as the training data remain inside the learned manifold.
Reference graph
Works this paper leans on
-
[1]
Z. Q. Xie, T. Y. Ji, M. S. Li and Q. H. Wu. “Quasi-Monte Carlo based probabilistic optimal power flow considering the correlation of wind speeds using Copula function,” IEEE Trans. Power Syst, vol. 33, no. 2, pp. 2239-2247, Mar. 2018
work page 2018
-
[2]
Yang Y, Yu J, Yang M, Ren P, Yang Z, Wang G. “Probabilistic modeling of ren ewable energy source based on spark platform with large‐scale sample data ,” Int Trans Electr . Energ. Syst. 2018; e2759. https://doi.org/10.1002/etep.2759
-
[3]
The generalized Cross-Entropy method in probabilistic optimal power flow,
Abolfazl Kazemdehdashti, Mohammad Mohammadi, Ali Reaz Seif i, “The generalized Cross-Entropy method in probabilistic optimal power flow,” IEEE Trans. Power Syst , vol. 33, no. 5, pp. 5738-5748, Mar. 2018
work page 2018
-
[4]
Probabilistic load flowincluding wind power generation,
D. Villanueva, J. L. Pazos, and A. Feijoo, “Probabilistic load flowincluding wind power generation,” IEEE Trans. Power Syst , vo1.26, no.3, pp.1659-1667, 2011
work page 2011
-
[5]
M. Fan, V. Vittal, G. T. Heydt, and R. Ayyanar, “Probabilistic power flow studies for transmission systems with photovoltaic generation using cumulants,” IEEE Trans. Power Syst. , vol. 27, no. 4, pp. 2251 – 2261, Nov. 2012
work page 2012
-
[6]
Evaluation methods and accuracy in probabilistic load flow solutions,
R.N. Allan, A.M. Leite da Silva, and R.C. Burchett, “Evaluation methods and accuracy in probabilistic load flow solutions,” IEEE Trans. Power App. Syst., voLPAS-100, no.5, pp.2539-2546, May 1981
work page 1981
-
[7]
Probabilistic load flow computing using p oint estimate method,
C. Su, “Probabilistic load flow computing using p oint estimate method,” IEEE Trans. on Power Syst., vol. 20, no. 4, pp. 1843 -1851, Nov. 2005
work page 2005
-
[8]
Probabilistic Load Flow in Correlated Uncertain Environment Using Unscented Transformation,
M. Aien, M. Fotuhi -Firuzabad and F. Aminifar, “Probabilistic Load Flow in Correlated Uncertain Environment Using Unscented Transformation,” IEEE Trans. on Power Sy st., vol. 27, no. 4, Nov. 2012
work page 2012
-
[9]
Simulation and the Monte Carlo method,
R. Y. Rubinstein and D. P. Kroese, “Simulation and the Monte Carlo method,” Hoboken, NJ, USA, Wiley, 2011
work page 2011
-
[10]
Probabilistic power flow by Monte Carlo simulation with latin supercube sampling,
M. Hajian, W. D. Rosehart, and H. Zareipour, “Probabilistic power flow by Monte Carlo simulation with latin supercube sampling,” IEEE Trans. Power Syst., vol. 28, no. 2, pp. 1550–1559, May 2013
work page 2013
-
[11]
Energy Storage Application for Performance Enhancement of Wind Integration,
M. Ghofrani, A. Arabali, M. Etezadi -Amoli and et al, “Energy Storage Application for Performance Enhancement of Wind Integration,” IEEE Trans. on Power Syst., vol. 28, no. 4, pp. 4803-4811, Nov. 2013
work page 2013
-
[12]
GPU -accelerated algorithm for online probabilistic power flow
Gan Zhou, Rui Bo, Lungsheng Chien, Xu Zhang, Shengchun Yang, and Dawei Su, “GPU -accelerated algorithm for online probabilistic power flow”, IEEE Trans. on Power Syst. , vol. 33, no. 1, pp. 1132 -1135, Jan. 2013
work page 2013
-
[13]
Stacked denoise autoencoder based feature extraction and classification for hyperspectral images,
Chen Xing , Li Ma , Xiaoquan Yang, “Stacked denoise autoencoder based feature extraction and classification for hyperspectral images,” J. Sensors, vol. 2016, pp. 1-10, Jan. 2016
work page 2016
-
[14]
Deep Spar se Rectifier Neural Networks,
Xavier Glorot, Antoine Bordes, Yoshua Bengio, “ Deep Spar se Rectifier Neural Networks,” J. Mach. Learn. Research, no.15, pp. 315- 323, Jan. 2011
work page 2011
-
[15]
Available: https://figshare.com/articles/Case_1_xlsx/7291769
Detailed information of renewables [Online]. Available: https://figshare.com/articles/Case_1_xlsx/7291769
-
[16]
Zhilong Qin, Wenyuan Li, Xiaofu Xiong, “Incorporating multiple correlations among wind speeds, photovoltaic powers and bus loads in composite system reliability evaluation,” Appl. Energy, vol. 110, no. 5, pp. 285-294, Oct. 2013
work page 2013
-
[17]
Early stopping for non-parametric regression: an optimal data -dependent stopping rule,
Garvesh Raskutti, Martin J. Wainwright, Bin Yu, “Early stopping for non-parametric regression: an optimal data -dependent stopping rule,” Journal of Machine Learning Research , vol. 15, no. 1, pp. 1318 -1325, Jan. 2014
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.