InteractiveAvatar: Real-Time Streaming Video Generation for Consistent and Intent-Aware Avatars
Pith reviewed 2026-06-26 09:07 UTC · model grok-4.3
The pith
InteractiveAvatar generates visually consistent avatar videos in real time over arbitrary lengths while aligning with user intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
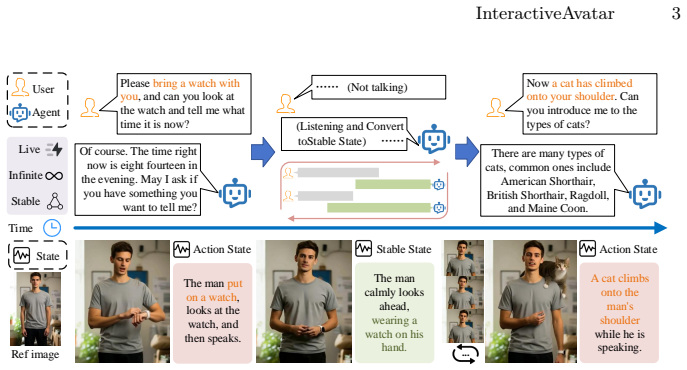
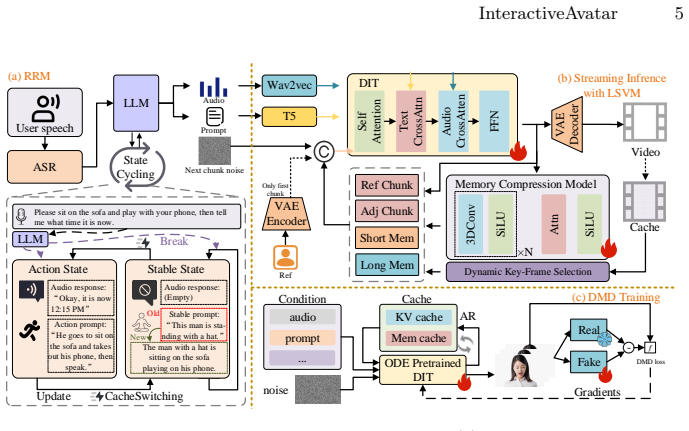
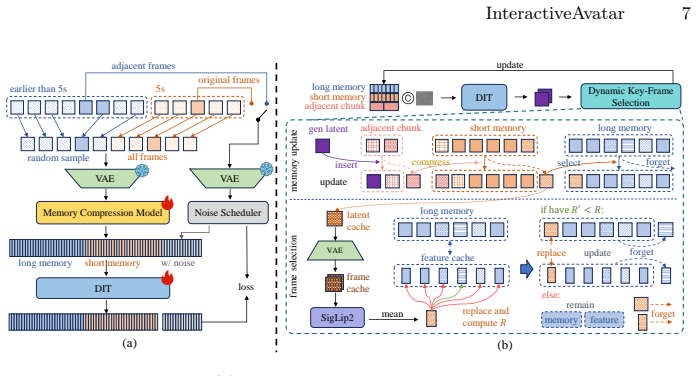
InteractiveAvatar is a real-time infinite-streaming video generation framework that supports visually consistent avatar video generation and intent-aware interactions. With autoregressive distillation, it achieves real-time streaming generation of human avatars over arbitrarily long durations. For visual consistency, the Long-Short Visual Memory mechanism flexibly compresses historical visual information into compact tokens, preserving both short-range coherence and long-term consistency. To generate avatars with speeches and actions aligned with user intent, the Reasoning-Reaction Module incorporates a State-Cycling strategy and a Cache-Switching mechanism.
What carries the argument
The Long-Short Visual Memory mechanism that compresses historical visual information into compact tokens to maintain coherence, together with the Reasoning-Reaction Module that uses State-Cycling and Cache-Switching to align outputs with user intent.
If this is right
- Achieves state-of-the-art visual consistency in long-duration generation.
- Enables complex user-avatar interaction in real time.
- Supports arbitrarily long avatar video streams without interruption.
- Produces speeches and actions aligned with user intent through explicit reasoning.
Where Pith is reading between the lines
- The same memory compression approach could apply to other streaming video tasks like virtual meetings or game characters.
- Intent alignment might extend to multi-user scenarios where the system tracks several participants simultaneously.
- Integration with language models could strengthen the reasoning step for more nuanced intent detection.
- Real-world deployment would require testing latency under varying network conditions to confirm the real-time claim.
Load-bearing premise
The Long-Short Visual Memory and Reasoning-Reaction Module mechanisms will deliver the claimed consistency and intent alignment when implemented.
What would settle it
A side-by-side comparison of generated videos that shows visible drift in avatar appearance or clothing after extended streaming, or actions and speech that do not match explicit user commands in complex multi-turn interactions.
Figures


read the original abstract
Recent diffusion-based models have enabled realistic audio-driven avatar generation in real-time streaming. However, existing approaches struggle to maintain visual temporal consistency and fail to explicitly perceive user intent in complex interactive streaming scenarios. To address these challenges, we propose InteractiveAvatar, a real-time infinite-streaming video generation framework that supports visually consistent avatar video generation and intent-aware interactions. With autoregressive distillation, InteractiveAvatar achieves real-time str-eaming generation of human avatars over arbitrarily long durations. For visual consistency, we introduce a Long-Short Visual Memory (LSVM) mechanism that flexibly compresses historical visual information into compact tokens, preserving both short-range coherence and long-term consistency. To generate avatars with speeches and actions aligned with user intent, we propose a Reasoning-Reaction Module (RRM), which incorporates a State-Cycling strategy and a Cache-Switching mechanism. Extensive experimental results over diverse scenarios demonstrate that our method achieves state-of-the-art visual consistency in long-duration generation, while enabling complex user-avatar interaction in real time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce InteractiveAvatar, a real-time infinite-streaming video generation framework for consistent and intent-aware avatars. It addresses limitations in visual temporal consistency and user intent perception in diffusion-based models using autoregressive distillation, a Long-Short Visual Memory (LSVM) mechanism for compressing historical visual information to preserve short-range and long-term consistency, and a Reasoning-Reaction Module (RRM) incorporating State-Cycling and Cache-Switching for intent-aligned speeches and actions. Extensive experiments demonstrate state-of-the-art performance in long-duration generation and real-time complex interactions.
Significance. If the central claims hold, this work offers a significant contribution to the field of real-time avatar video generation by enabling arbitrarily long consistent streaming and explicit intent-aware interactions, which prior methods struggle with. The LSVM token compression and RRM strategies, supported by autoregressive distillation, provide a practical and internally consistent solution to the identified challenges. The reported experimental results over diverse scenarios add credibility to the approach, potentially advancing applications in interactive virtual environments.
minor comments (3)
- [Abstract] Abstract: the phrase 'real-time str-eaming generation' contains an apparent typographical error and should read 'streaming'.
- [Method] The description of the LSVM token compression in the method section would benefit from explicit discussion of the compression ratios used and their effect on memory usage to support reproducibility.
- [Experiments] Figure captions in the experimental section are often brief; expanding them to note which specific consistency or interaction aspects are visualized would improve reader comprehension.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of InteractiveAvatar and for recommending minor revision. The summary correctly identifies the core challenges addressed (visual temporal consistency and intent perception) as well as the proposed solutions via autoregressive distillation, LSVM, and RRM.
Circularity Check
No circularity; architectural proposals are self-contained descriptions without derivations or self-referential reductions.
full rationale
The manuscript introduces InteractiveAvatar as a framework using autoregressive distillation plus two new modules (LSVM for memory compression and RRM with State-Cycling/Cache-Switching). No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The consistency and intent-alignment claims rest on the explicit design of the modules rather than any reduction to prior fitted results or self-defined quantities. The argument is therefore internally consistent and non-circular by the stated criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.12479 (2025)
An, H., Hu, W., Huang, S., Huang, S., Li, R., Liang, Y., Shao, J., Song, Y., Wang, Z., Yuan, C., et al.: Ai flow: Perspectives, scenarios, and approaches (2025). arXiv preprint arXiv:2506.12479 (2025)
arXiv 2025
-
[2]
arXiv preprint arXiv:2505.20156 (2025)
Chen, Y., Liang, S., Zhou, Z., Huang, Z., Ma, Y., Tang, J., Lin, Q., Zhou, Y., Lu, Q.: Hunyuanvideo-avatar: High-fidelity audio-driven human animation for multiple characters. arXiv preprint arXiv:2505.20156 (2025)
arXiv 2025
-
[3]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Cao, J., Chen, Z., Li, Y., Ma, C.: Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2403–2410 (2025)
2025
-
[4]
In: INTERSPEECH (2018)
Chung, J.S., Nagrani, A., Zisserman, A.: Voxceleb2: Deep speaker recognition. In: INTERSPEECH (2018)
2018
-
[5]
In: Asian conference on computer vision
Chung, J.S., Zisserman, A.: Out of time: automated lip sync in the wild. In: Asian conference on computer vision. pp. 251–263. Springer (2016)
2016
-
[6]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cui, J., Li, H., Zhan, Y., Shang, H., Cheng, K., Ma, Y., Mu, S., Zhou, H., Wang, J., Zhu, S.: Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21086–21095 (2025)
2025
-
[7]
arXiv preprint arXiv:2510.02283 (2025)
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y., Hsieh, C.J.: Self-forcing++: Towards minute-scale high-quality video generation. arXiv preprint arXiv:2510.02283 (2025)
Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2505.10238 (2025)
Ding, Y., Hu, X., Guo, Z., Zhang, C., Wang, Y.: Mtvcrafter: 4d motion tokenization for open-world human image animation. arXiv preprint arXiv:2505.10238 (2025)
arXiv 2025
-
[9]
arXiv preprint arXiv:2506.18866 (2025)
Gan, Q., Yang, R., Zhu, J., Xue, S., Hoi, S.: Omniavatar: Efficient audio- driven avatar video generation with adaptive body animation. arXiv preprint arXiv:2506.18866 (2025)
arXiv 2025
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ginosar, S., Bar, A., Kohavi, G., Chan, C., Owens, A., Malik, J.: Learning individ- ual styles of conversational gesture. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3497–3506 (2019)
2019
-
[11]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[12]
arXiv preprint arXiv:2506.08009 (2025)
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
Pith/arXiv arXiv 2025
-
[13]
arXiv preprint arXiv:2512.04677 (2025)
Huang, Y., Guo, H., Wu, F., Zhang, S., Huang, S., Gan, Q., Liu, L., Zhao, S., Chen, E., Liu, J., et al.: Live avatar: Streaming real-time audio-driven avatar generation with infinite length. arXiv preprint arXiv:2512.04677 (2025)
Pith/arXiv arXiv 2025
-
[14]
Vicinagearth1(1), 8 (2024)
Jiang, W., Zhang, Y., Zheng, S., Liu, S., Yan, S.: Data augmentation in human- centric vision. Vicinagearth1(1), 8 (2024)
2024
-
[15]
arXiv preprint arXiv:2505.22647 (2025)
Kong, Z., Gao, F., Zhang, Y., Kang, Z., Wei, X., Cai, X., Chen, G., Luo, W.: Let them talk: Audio-driven multi-person conversational video generation. arXiv preprint arXiv:2505.22647 (2025)
arXiv 2025
-
[16]
arXiv preprint arXiv:2412.00115 (2024)
Li, H., Xu, M., Zhan, Y., Mu, S., Li, J., Cheng, K., Chen, Y., Chen, T., Ye, M., Wang, J., et al.: Openhumanvid: A large-scale high-quality dataset for enhancing human-centric video generation. arXiv preprint arXiv:2412.00115 (2024)
arXiv 2024
-
[17]
Vicinagearth1(1), 9 (2024) InteractiveAvatar 17
Li, X., Wang, S., Zeng, S., Wu, Y., Yang, Y.: A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges. Vicinagearth1(1), 9 (2024) InteractiveAvatar 17
2024
-
[18]
IEEE Transactions on Neural Networks and Learn- ing Systems35(6), 8708–8714 (2022)
Li, X.: Positive-incentive noise. IEEE Transactions on Neural Networks and Learn- ing Systems35(6), 8708–8714 (2022)
2022
-
[19]
arXiv preprint arXiv:2506.03099 (2025)
Low, C., Wang, W.: Talkingmachines: Real-time audio-driven facetime-style video via autoregressive diffusion models. arXiv preprint arXiv:2506.03099 (2025)
arXiv 2025
-
[20]
arXiv preprint arXiv:2507.03905 (2025)
Meng, R., Wang, Y., Wu, W., Zheng, R., Li, Y., Ma, C.: Echomimicv3: 1.3 b pa- rameters are all you need for unified multi-modal and multi-task human animation. arXiv preprint arXiv:2507.03905 (2025)
arXiv 2025
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ng, E., Joo, H., Hu, L., Li, H., Darrell, T., Kanazawa, A., Ginosar, S.: Learning to listen: Modeling non-deterministic dyadic facial motion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20395– 20405 (2022)
2022
-
[22]
In: Proceedings of the 28th ACM international conference on multimedia
Prajwal, K., Mukhopadhyay, R., Namboodiri, V.P., Jawahar, C.: A lip sync expert is all you need for speech to lip generation in the wild. In: Proceedings of the 28th ACM international conference on multimedia. pp. 484–492 (2020)
2020
-
[23]
Journal of machine learning research21(140), 1–67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020)
2020
-
[24]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3 (2025),https://ar...
Pith/arXiv arXiv 2025
-
[25]
arXiv preprint arXiv:2512.22065 (2025)
Sun, Z., Peng, Z., Ma, Y., Chen, Y., Zhou, Z., Zhou, Z., Zhang, G., Zhang, Y., Zhou, Y., Lu, Q., et al.: Streamavatar: Streaming diffusion models for real-time interactive human avatars. arXiv preprint arXiv:2512.22065 (2025)
arXiv 2025
-
[26]
In: European Conference on Computer Vision
Tian, L., Wang, Q., Zhang, B., Bo, L.: Emo: Emote portrait alive generating ex- pressive portrait videos with audio2video diffusion model under weak conditions. In: European Conference on Computer Vision. pp. 244–260. Springer (2024)
2024
-
[27]
arXiv preprint arXiv:2502.14786 (2025)
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025)
Pith/arXiv arXiv 2025
-
[28]
Tu, S., Pan, Y., Huang, Y., Han, X., Xing, Z., Dai, Q., Luo, C., Wu, Z., Jiang, Y.G.: Stableavatar: Infinite-length audio-driven avatar video generation (2025), https://arxiv.org/abs/2508.08248
arXiv 2025
-
[29]
arXiv preprint arXiv:1812.01717 (2018)
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018)
Pith/arXiv arXiv 2018
-
[30]
arXiv preprint arXiv:2503.20314 (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
Pith/arXiv arXiv 2025
-
[31]
Wang, J., Wang, C., Huang, K., Huang, J., Jin, L.: Videoclip-xl: Advancing long description understanding for video clip models (2024),https://arxiv.org/abs/ 2410.00741
arXiv 2024
-
[32]
arXiv preprint arXiv:2601.10103 (2026)
Wang, L., Zhu, Y., Ge, Z., Zheng, Y., Zhang, L., Hu, T., Qin, S., Luo, M., Zhang, J., Chen, X., et al.: Flowact-r1: Towards interactive humanoid video generation. arXiv preprint arXiv:2601.10103 (2026)
arXiv 2026
-
[33]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang, M., Wang, Q., Jiang, F., Fan, Y., Zhang, Y., Qi, Y., Zhao, K., Xu, M.: Fantasytalking: Realistic talking portrait generation via coherent motion synthesis. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 9891–9900 (2025) 18 Q. Song et al
2025
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Y., Fan, Y., Wang, X., Yu, G., Wang, F.: Diffusion-based realistic listening head generation via hybrid motion modeling. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15885–15895 (2025)
2025
-
[35]
arXiv preprint arXiv:2312.17090 (2023)
Wu, H., Zhang, Z., Zhang, W., Chen, C., Liao, L., Li, C., Gao, Y., Wang, A., Zhang, E., Sun, W., et al.: Q-align: Teaching lmms for visual scoring via discrete text-defined levels. arXiv preprint arXiv:2312.17090 (2023)
Pith/arXiv arXiv 2023
-
[36]
In: The IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2022)
Xie, L., Wang, X., Zhang, H., Dong, C., Shan, Y.: Vfhq: A high-quality dataset and benchmark for video face super-resolution. In: The IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2022)
2022
-
[37]
arXiv preprint arXiv:2509.21574 (2025)
Xie, Y., Gu, T., Li, Z., Zhang, C., Song, G., Zhao, X., Liang, C., Jiang, J., Xu, H., Luo, L.: X-streamer: Unified human world modeling with audiovisual interaction. arXiv preprint arXiv:2509.21574 (2025)
arXiv 2025
-
[38]
arXiv preprint arXiv:2509.17765 (2025)
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., et al.: Qwen3-omni technical report. arXiv preprint arXiv:2509.17765 (2025)
Pith/arXiv arXiv 2025
-
[39]
Advances in Neural Information Processing Systems37, 660–684 (2024)
Xu, S., Chen, G., Guo, Y.X., Yang, J., Li, C., Zang, Z., Zhang, Y., Tong, X., Guo, B.: Vasa-1: Lifelike audio-driven talking faces generated in real time. Advances in Neural Information Processing Systems37, 660–684 (2024)
2024
-
[40]
arXiv preprint arXiv:2509.22622 (2025)
Yang, S., Huang, W., Chu, R., Xiao, Y., Zhao, Y., Wang, X., Li, M., Xie, E., Chen, Y., Lu, Y., et al.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
Pith/arXiv arXiv 2025
-
[41]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Yin, T., Zhang, Q., Zhang, R., Freeman, W.T., Durand, F., Shechtman, E., Huang, X.: From slow bidirectional to fast autoregressive video diffusion models. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 22963–22974 (2025)
2025
-
[42]
In: CVPR (2023)
Yu, J., Zhu, H., Jiang, L., Loy, C.C., Cai, W., Wu, W.: CelebV-Text: A large-scale facial text-video dataset. In: CVPR (2023)
2023
-
[43]
IEEE Transactions on Pattern Analysis and Machine Intel- ligence (2025)
Zhang, H., Huang, S., Guo, Y., Li, X.: Variational positive-incentive noise: How noise benefits models. IEEE Transactions on Pattern Analysis and Machine Intel- ligence (2025)
2025
-
[44]
arXiv preprint arXiv:2512.23851 (2025)
Zhang, L., Cai, S., Li, M., Zeng, C., Lu, B., Rao, A., Han, S., Wetzstein, G., Agrawala, M.: Pretraining frame preservation in autoregressive video memory com- pression. arXiv preprint arXiv:2512.23851 (2025)
Pith/arXiv arXiv 2025
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, W., Cun, X., Wang, X., Zhang, Y., Shen, X., Guo, Y., Shan, Y., Wang, F.: Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8652–8661 (2023)
2023
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, Z., Li, L., Ding, Y., Fan, C.: Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3661–3670 (2021)
2021
-
[47]
arXiv preprint arXiv:2304.11277 (2023)
Zhao,Y.,Gu,A.,Varma,R.,Luo,L.,Huang,C.C.,Xu,M.,Wright,L.,Shojanazeri, H., Ott, M., Shleifer, S., et al.: Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277 (2023)
Pith/arXiv arXiv 2023
-
[48]
ACM Transactions On Graph- ics (TOG)39(6), 1–15 (2020)
Zhou, Y., Han, X., Shechtman, E., Echevarria, J., Kalogerakis, E., Li, D.: Makelttalk: speaker-aware talking-head animation. ACM Transactions On Graph- ics (TOG)39(6), 1–15 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.