A Physics-Informed Fourier-Wavelet Transformer for Multiscale Computational Fluid Dynamics Surrogate Modeling
Pith reviewed 2026-06-25 22:45 UTC · model grok-4.3
The pith
A Fourier-wavelet transformer that biases attention using PDE residuals reconstructs multiscale fluid velocity fields more accurately than prior surrogate models on standard benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
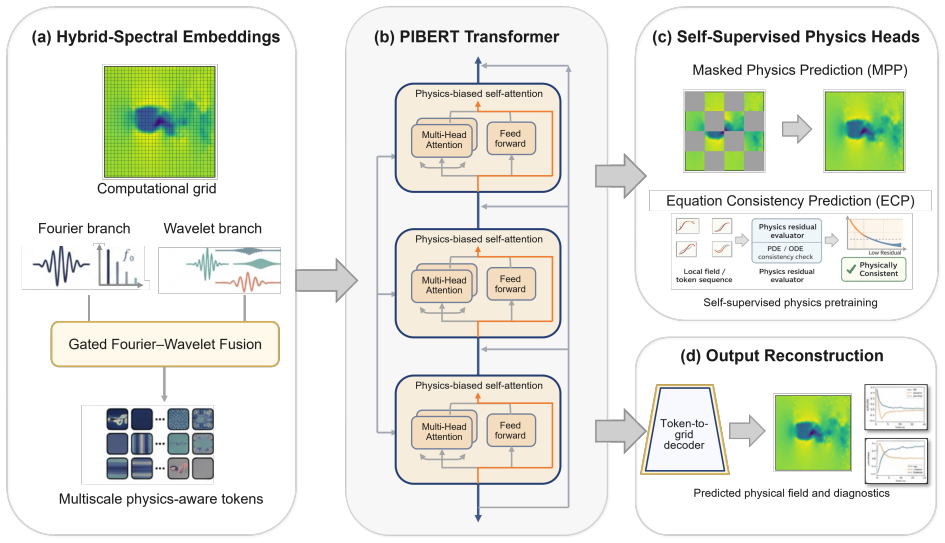
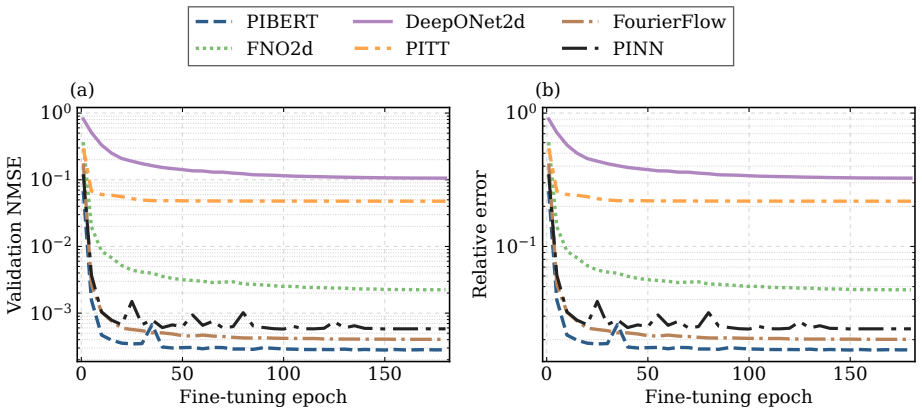
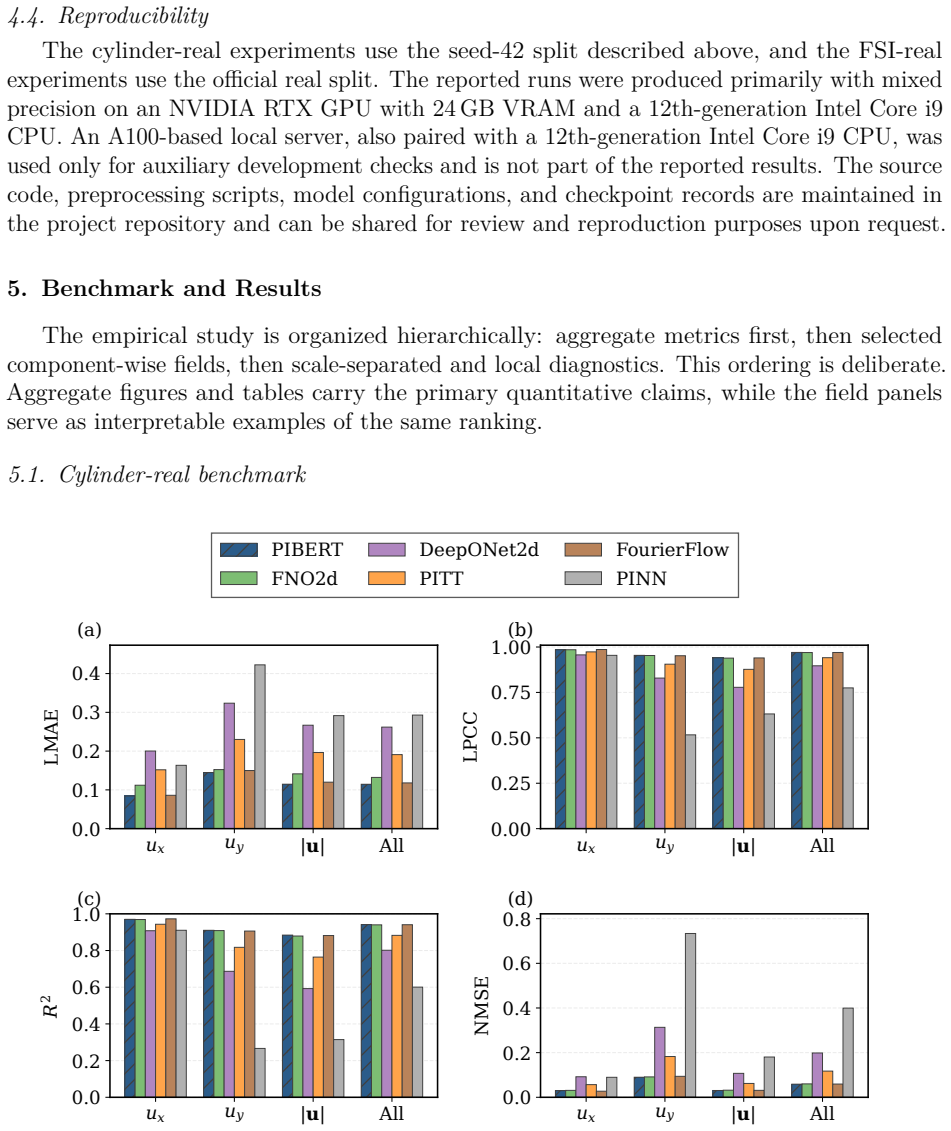
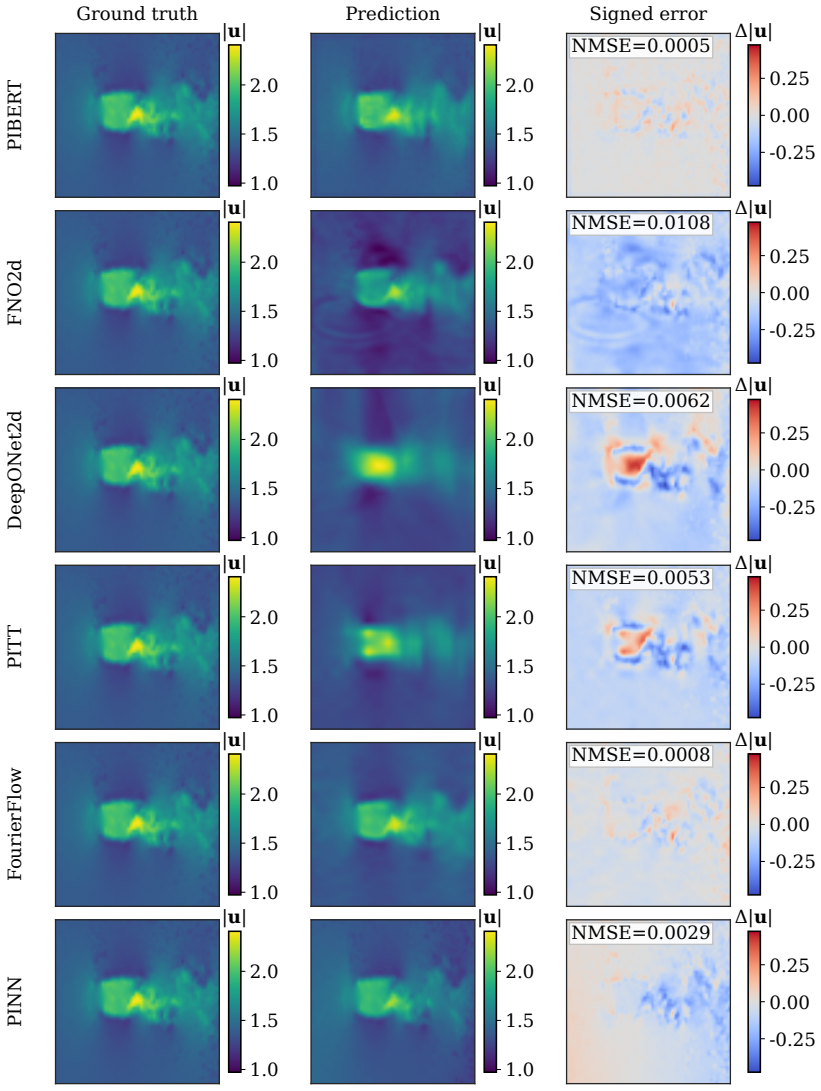
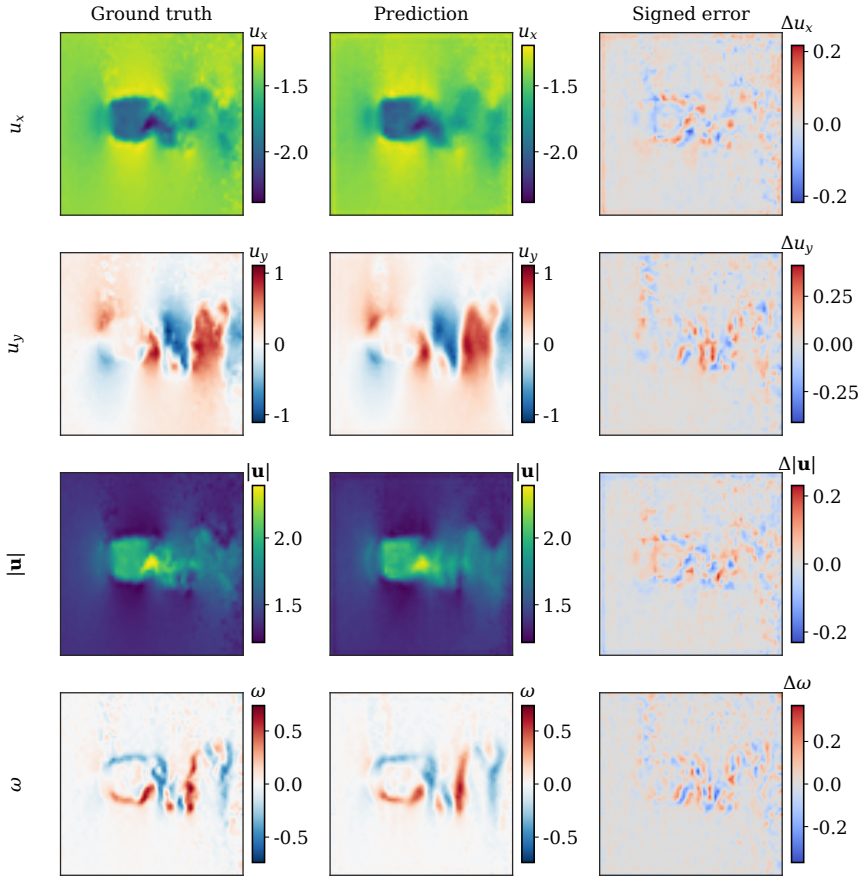
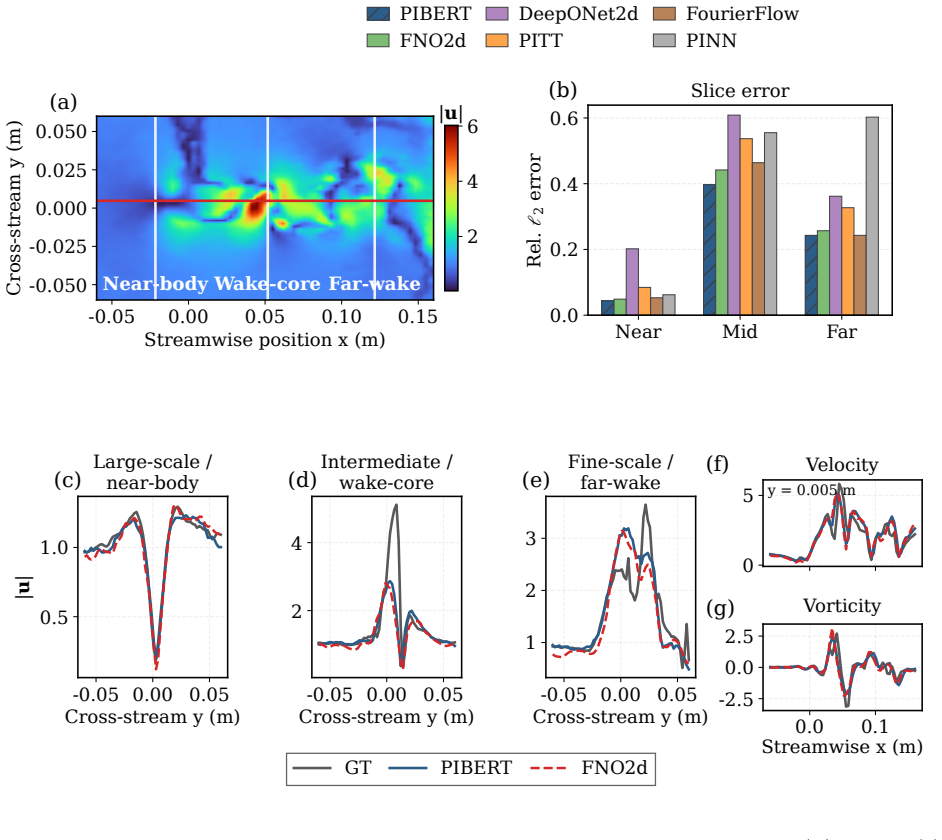
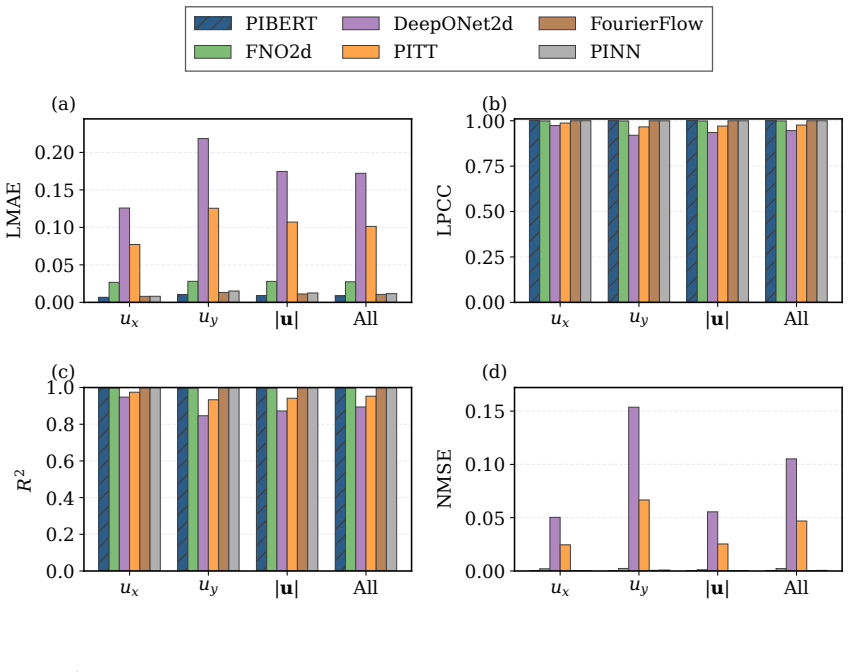
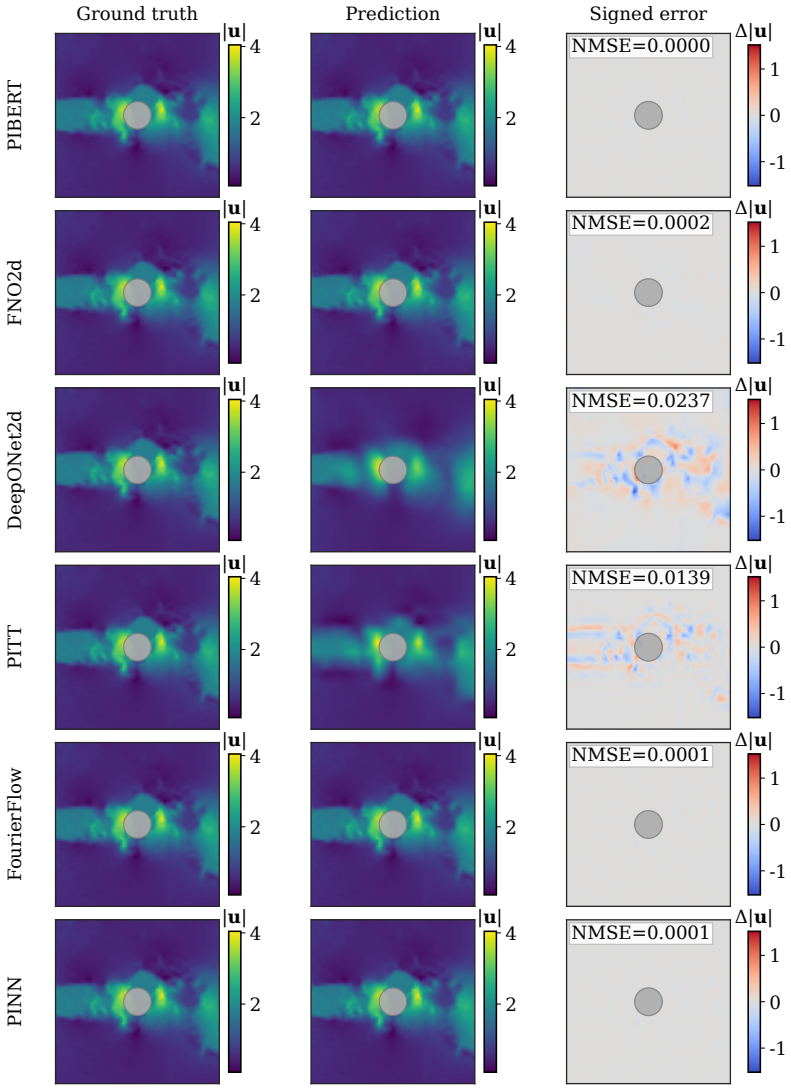
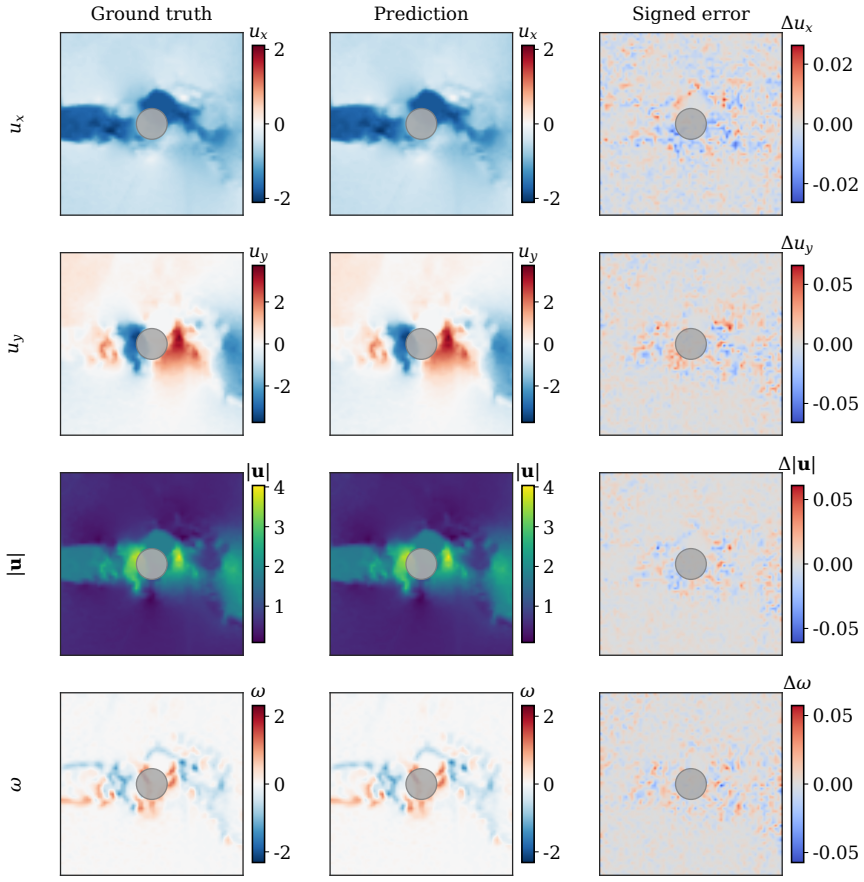
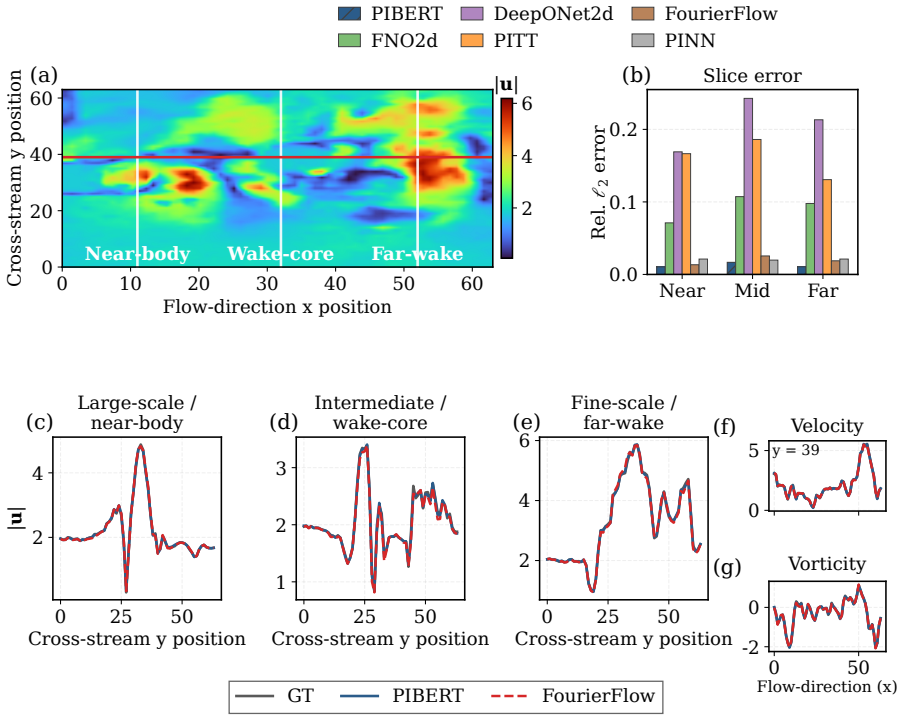
The authors claim that hybrid Fourier-wavelet spectral encoding together with physics-biased self-attention derived from PDE residual diagnostics, plus Masked Physics Prediction and Equation Consistency Prediction pretraining, produces next-step velocity-field reconstructions that outperform spectral, transformer, operator-learning, and physics-informed neural-network baselines on two real benchmarks while recovering localized multiscale structures including near-body, wake-core, and far-wake features.
What carries the argument
Physics-biased self-attention derived from partial differential equation residual diagnostics, which re-weights attention to emphasize locations where the predicted field deviates from the flow equations.
If this is right
- Component-wise comparisons show improved capture of near-body, wake-core, and far-wake localized structures.
- The model achieves the lowest all-channel normalized mean-squared error on both cylinder-wake and fluid-structure interaction benchmarks under a shared evaluation protocol.
- All-channel Pearson correlation reaches 0.97019 on the cylinder-wake case while maintaining a practical accuracy-cost balance.
- The approach generalizes across the two tested real-world flow regimes without case-by-case hyperparameter changes.
Where Pith is reading between the lines
- If the residual diagnostic generalizes, the same bias mechanism could be transferred to surrogate modeling of other PDE systems such as heat or mass transport.
- The two pretraining tasks may reduce data requirements when the model is applied to flows outside the original training distribution.
- Scale-separated error diagnostics could be used to design hybrid architectures that allocate different resolution levels to different physical regions.
Load-bearing premise
The physics-biased attention from PDE residuals improves recovery of localized structures without introducing new biases or requiring benchmark-specific tuning.
What would settle it
Apply the trained model to a third independent flow configuration and measure whether it still records the lowest all-channel normalized mean-squared error and visibly better scale-separated wake recovery than the strongest baseline.
Figures
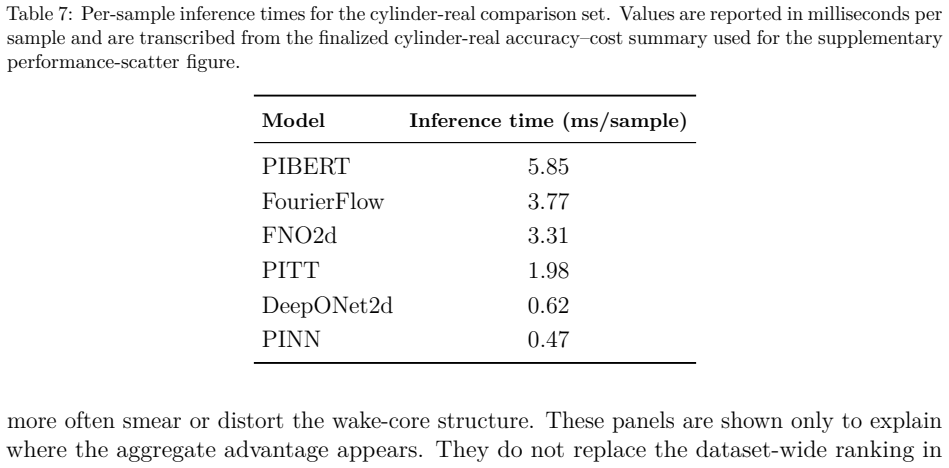
read the original abstract
Physics-informed surrogate models can accelerate computational fluid dynamics simulations. However, many existing methods reproduce global flow patterns more reliably than localized multiscale structures. This study presents a physics-informed Fourier-wavelet transformer for next-step velocity-field reconstruction in real-world flow benchmarks. The proposed formulation combines hybrid Fourier-wavelet spectral encoding with physics-biased self-attention based on partial differential equation residual diagnostics. It also uses self-supervised pretraining through Masked Physics Prediction and Equation Consistency Prediction. The experiments are conducted on two real benchmark cases: cylinder-wake flow and fluid-structure interaction. All approaches are evaluated under a shared local protocol and compared with spectral, transformer-based, operator-learning, and physics-informed neural-network baselines. On the cylinder-wake benchmark, the proposed model achieves the best aggregate accuracy, with an all-channel normalized mean-squared error of 0.05875 and an all-channel Pearson correlation coefficient of 0.97019. On the fluid-structure-interaction benchmark, it gives the lowest all-channel normalized mean-squared error of $2.70 \times 10^{-4}$, compared with $4.02 \times 10^{-4}$ for the strongest baseline. Component-wise field comparisons and scale-separated diagnostics further show stronger recovery of localized wake structures, including near-body, wake-core, and far-wake features. The results demonstrate improved real-world flow reconstruction while maintaining a practical accuracy-cost tradeoff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a physics-informed Fourier-wavelet transformer for next-step velocity-field reconstruction in CFD surrogate modeling. It combines hybrid Fourier-wavelet spectral encoding, physics-biased self-attention derived from PDE residual diagnostics, and self-supervised pretraining (Masked Physics Prediction and Equation Consistency Prediction). On cylinder-wake and fluid-structure-interaction benchmarks, the model reports superior aggregate accuracy (all-channel NMSE 0.05875 / PCC 0.97019 on cylinder-wake; NMSE 2.70e-4 on FSI) versus spectral, transformer, operator-learning, and PINN baselines, with additional component-wise and scale-separated diagnostics.
Significance. If the performance gains are robustly attributable to the proposed components and the evaluation protocol is reproducible, the approach could advance multiscale flow surrogate modeling by improving recovery of localized wake structures while preserving practical accuracy-cost tradeoffs.
major comments (2)
- [Experiments / Results] The central attribution—that physics-biased self-attention improves localized multiscale recovery—lacks supporting evidence from controlled ablation; the manuscript reports only end-to-end benchmark comparisons without disabling the bias term while holding spectral encoding and pretraining objectives fixed.
- [Abstract / Experiments] Verification of the reported superiority is hindered by the absence of information on data splits, hyperparameter search procedures, statistical significance of metric differences, and whether baselines received equivalent tuning effort.
minor comments (1)
- [Abstract] The phrase 'shared local protocol' is used without definition or reference to supplementary material detailing the exact evaluation setup.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experiments / Results] The central attribution—that physics-biased self-attention improves localized multiscale recovery—lacks supporting evidence from controlled ablation; the manuscript reports only end-to-end benchmark comparisons without disabling the bias term while holding spectral encoding and pretraining objectives fixed.
Authors: We agree that the current manuscript presents only end-to-end benchmark results and does not include controlled ablations that isolate the physics-biased self-attention by disabling the bias term while holding spectral encoding and pretraining fixed. To strengthen the attribution, we will add these ablation experiments to the revised manuscript, reporting the resulting changes in NMSE and scale-separated metrics on both benchmarks. revision: yes
-
Referee: [Abstract / Experiments] Verification of the reported superiority is hindered by the absence of information on data splits, hyperparameter search procedures, statistical significance of metric differences, and whether baselines received equivalent tuning effort.
Authors: We acknowledge that the manuscript lacks explicit details on these aspects. In the revision we will add a dedicated reproducibility section (or appendix) specifying the train/validation/test splits, the hyperparameter search procedure and ranges, statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) on the reported metric differences, and confirmation that all baselines were tuned under the same shared protocol with equivalent effort. revision: yes
Circularity Check
No circularity in derivation chain; empirical results are independent of model inputs
full rationale
The manuscript presents an architecture combining hybrid Fourier-wavelet encoding, physics-biased self-attention from PDE residuals, and two self-supervised pretraining tasks, then reports end-to-end NMSE and PCC numbers on cylinder-wake and FSI benchmarks against external baselines. No equations, fitted parameters, or self-citations are shown that reduce the reported accuracy figures to quantities defined by the model itself. The performance claims rest on direct numerical comparisons under a shared protocol, satisfying the criterion of being self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y. Liu, J. N. Kutz, S. L. Brunton, Hierarchical deep learning of multiscale differential equation time-steppers, Philosophical Transactions of the Royal Society A 380 (2229) (2022) 20210200
2022
-
[2]
Y. Wang, N. Ye, Z. Li, Physics-informed surrogate for cardiovascular flow extrapolation through transductive learning, Engineering Applications of Artificial Intelligence 159 (2025) 111458.doi:10.1016/j.engappai.2025.111458
-
[3]
Q. Liu, W. Zhong, S. Koric, H. Meidani, Sequential neural operator transformer for high- fidelity surrogates of time-dependent non-linear partial differential equations, Engineering Applications of Artificial Intelligence 172 (2026) 114428.doi:10.1016/j.engappai. 2026.114428
- [4]
-
[5]
L. Yi, S. Yang, Y. Cui, Z. Lai, Transforming physics-informed machine learning to convex optimization, Engineering Applications of Artificial Intelligence 161 (2025) 112149. doi:https://doi.org/10.1016/j.engappai.2025.112149. URLhttps://www.sciencedirect.com/science/article/pii/S0952197625021578
- [6]
-
[7]
Rui, Z.-W
E.-Z. Rui, Z.-W. Chen, Y.-Q. Ni, L. Yuan, G.-Z. Zeng, Reconstruction of 3d flow field around a building model in wind tunnel: a novel physics-informed neural network frame- work adopting dynamic prioritization self-adaptive loss balance strategy, Engineering Applications of Computational Fluid Mechanics 17 (1) (2023) 2238849
2023
-
[8]
Penwarden, A
M. Penwarden, A. D. Jagtap, S. Zhe, G. E. Karniadakis, R. M. Kirby, A unified scalable framework for causal sweeping strategies for physics-informed neural networks (pinns) and their temporal decompositions, Journal of Computational Physics 493 (2023) 112464
2023
-
[9]
J. Abbasi, A. D. Jagtap, B. Moseley, A. Hiorth, P. Østebø Andersen, Challenges and advancements in modeling shock fronts with physics-informed neural networks: A review and benchmarking study, Neurocomputing 657 (2025) 131440.doi:https: //doi.org/10.1016/j.neucom.2025.131440. URLhttps://www.sciencedirect.com/science/article/pii/S0925231225021125
-
[10]
Kovachki, Z
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stuart, A. Anand- kumar, Neural operator: Learning maps between function spaces with applications to pdes, Journal of Machine Learning Research 24 (89) (2023) 1–97
2023
-
[11]
Serrano, L
L. Serrano, L. Le Boudec, A. Kassaï Koupaï, T. X. Wang, Y. Yin, J.-N. Vittaut, P. Gallinari, Operator learning with neural fields: Tackling pdes on general geometries, Advances in Neural Information Processing Systems 36 (2023) 70581–70611. 41
2023
-
[12]
Raonic, R
B. Raonic, R. Molinaro, T. De Ryck, T. Rohner, F. Bartolucci, R. Alaifari, S. Mishra, E. de Bézenac, Convolutional neural operators for robust and accurate learning of pdes, Advances in Neural Information Processing Systems 36 (2023) 77187–77200
2023
-
[13]
G. Wen, Z. Li, K. Azizzadenesheli, A. Anandkumar, S. M. Benson, U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow, Advances in Water Resources 163 (2022) 104180
2022
-
[14]
Sinha, B
S. Sinha, B. Benton, P. Emami, On the effectiveness of neural operators at zero-shot weather downscaling, Environmental Data Science 4 (2025) e21
2025
-
[15]
H. Wang, Y. Cao, Z. Huang, Y. Liu, P. Hu, X. Luo, Z. Song, W. Zhao, J. Liu, J. Sun, et al., Recent advances on machine learning for computational fluid dynamics: A survey, arXiv preprint arXiv:2408.12171 (2024)
arXiv 2024
-
[16]
Q. Luo, W. Zeng, M. Chen, G. Peng, X. Yuan, Q. Yin, Self-attention and transformers: Driving the evolution of large language models, in: 2023 IEEE 6th International Confer- ence on Electronic Information and Communication Technology (ICEICT), IEEE, 2023, pp. 401–405
2023
-
[17]
Z. Zhao, X. Ding, B. A. Prakash, Pinnsformer: A transformer-based framework for physics-informed neural networks, arXiv preprint arXiv:2307.11833 (2023)
arXiv 2023
-
[18]
C. Lorsung, Z. Li, A. Barati Farimani, Physics informed token transformer for solving partial differential equations, Machine Learning: Science and Technology 5 (1) (2024) 015032.doi:10.1088/2632-2153/ad27e3. URLhttps://dx.doi.org/10.1088/2632-2153/ad27e3
-
[19]
P. Hu, H. Feng, H. Liu, T. Yan, W. Deng, T. Gao, R. Zheng, H. Zheng, C. Yu, C. Wang, K. Li, Z.-M. Ma, D. Zhou, X. Lu, D. Fan, T. Wu, RealPDEBench: A benchmark for complex physical systems with real-world data, in: The Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=y3oHMcoItR
2026
-
[20]
Y. Luo, Y. Chen, Z. Zhang, Cfdbench: A large-scale benchmark for machine learning methods in fluid dynamics, arXiv preprint arXiv:2310.05963 (2023)
arXiv 2023
-
[21]
G. Daly, J. Fieldsend, G. Hassall, G. Tabor, Data-driven plasma modelling: Fluorocarbon icp data set, dataset (2023).doi:10.5281/zenodo.7704879
-
[22]
Janny, A
S. Janny, A. Bénéteau, M. Nadri, J. Digne, N. Thome, C. Wolf, Eagle: Large-scale learning of turbulent fluid dynamics with mesh transformers, in: International Conference on Learning Representations, 2023, dataset and benchmark
2023
-
[23]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational physics 378 (2019) 686–707. 42
2019
-
[24]
A. M. Roy, S. Guha, A data-driven physics-constrained deep learning computational framework for solving von mises plasticity, Engineering Applications of Artificial Intelli- gence 122 (2023) 106049.doi:10.1016/j.engappai.2023.106049
-
[25]
S. J. Anagnostopoulos, J. D. Toscano, N. Stergiopulos, G. E. Karniadakis, Residual-based attention in physics-informed neural networks, Computer Methods in Applied Mechanics and Engineering 421 (2024) 116805.doi:10.1016/j.cma.2024.116805
-
[26]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via deeponet based on the universal approximation theorem of operators, Nature Machine Intelligence 3 (3) (2021) 218–229.doi:10.1038/s42256-021-00302-5. URLhttps://doi.org/10.1038/s42256-021-00302-5
-
[27]
O. Ovadia, A. Kahana, P. Stinis, E. Turkel, D. Givoli, G. E. Karniadakis, Vito: Vision transformer-operator, Computer Methods in Applied Mechanics and Engineering 428 (2024) 117109.doi:10.1016/j.cma.2024.117109
-
[28]
W. Zhong, H. Meidani, Physics-informed geometry-aware neural operator, Computer Methods in Applied Mechanics and Engineering 434 (2025) 117540.doi:10.1016/j. cma.2024.117540
work page doi:10.1016/j 2025
-
[29]
Z. Li, N. B. Kovachki, K. Azizzadenesheli, B. liu, K. Bhattacharya, A. Stuart, A. Anand- kumar, Fourier neural operator for parametric partial differential equations, in: Interna- tional Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=c8P9NQVtmnO
2021
-
[30]
G. Wen, Z. Li, K. Azizzadenesheli, A. Anandkumar, S. M. Benson, U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow, Advances in Water Resources 163 (2022) 104180. doi:https://doi.org/10.1016/j.advwatres. 2022.104180. URLhttps://www.sciencedirect.com/science/article/pii/S0309170822000562
-
[31]
Q. Xu, N. Thuerey, Y. Shi, J. Bamber, C. Ouyang, X. X. Zhu, Physics-embedded fourier neural network for partial differential equations, arXiv preprint arXiv:2407.11158 (2024)
arXiv 2024
-
[32]
Y. Li, L. Xu, S. Ying, Dwnn: Deep wavelet neural network for solving partial differential equations, Mathematics 10 (12) (2022).doi:10.3390/math10121976. URLhttps://www.mdpi.com/2227-7390/10/12/1976
-
[33]
J. Su, J. Ma, S. Tong, E. Xu, M. Chen, Multiscale attention wavelet neural operator for capturing steep trajectories in biochemical systems, Proceedings of the AAAI Conference onArtificialIntelligence38(13)(2024)15100–15107. doi:10.1609/aaai.v38i13.29432. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/29432
-
[34]
Wang, J.-S
H. Wang, J.-S. Pan, H. Wu, F. Zhang, T. Wu, Fourierflow: Frequency-aware flow matching for generative turbulence modeling (2026). URLhttps://openreview.net/forum?id=a3sRspQ62b 43
2026
-
[35]
P. Hu, R. Wang, X. Zheng, T. Zhang, H. Feng, R. Feng, L. Wei, Y. Wang, Z.-M. Ma, T. Wu, Wavelet diffusion neural operator, in: The Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=FQhDIGuaJ4
2025
-
[36]
A. Hemmasian, A. Barati Farimani, Multi-scale time-stepping of partial differential equations with transformers, Computer Methods in Applied Mechanics and Engineering 426 (2024) 116983.doi:10.1016/j.cma.2024.116983
-
[37]
T.-Y. Yang, J. Rosca, K. Narasimhan, P. J. Ramadge, Learning physics constrained dynamics using autoencoders, Advances in Neural Information Processing Systems 35 (2022) 17157–17172
2022
-
[38]
Calvello, N
E. Calvello, N. B. Kovachki, M. E. Levine, A. M. Stuart, Continuum attention for neural operators, Journal of Machine Learning Research 26 (300) (2025) 1–52
2025
-
[39]
Cao, Choose a transformer: Fourier or galerkin, Advances in neural information processing systems 34 (2021) 24924–24940
S. Cao, Choose a transformer: Fourier or galerkin, Advances in neural information processing systems 34 (2021) 24924–24940
2021
-
[40]
H. Wu, H. Luo, H. Wang, J. Wang, M. Long, Transolver: A fast transformer solver for pdes on general geometries, in: International Conference on Machine Learning, PMLR, 2024, pp. 53681–53705
2024
-
[41]
G. Berend, Masked latent semantic modeling: an efficient pre-training alternative to masked language modeling, in: Findings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 13949–13962
2023
-
[42]
Garnier, V
P. Garnier, V. Lannelongue, J. Viquerat, E. Hachem, Meshmask: Physics-based simula- tions with masked graph neural networks, in: The Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=bFHR8hNk4I
2025
-
[43]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[44]
M. V. Koroteev, Bert: a review of applications in natural language processing and understanding, arXiv preprint arXiv:2103.11943 (2021)
arXiv 2021
-
[45]
S. Qin, F. Lyu, W. Peng, D. Geng, J. Wang, X. Tang, S. Leroyer, N. Gao, X. Liu, L. L. Wang, Toward a better understanding of fourier neural operators from a spectral perspective, arXiv preprint arXiv:2404.07200 (2024).arXiv:2404.07200
arXiv 2024
-
[46]
Z.Hao, S.Liu, Y.Zhang, C.Ying, Y.Feng, H.Su, J.Zhu, Physics-informedmachinelearn- ing: A survey on problems, methods and applications, arXiv preprint arXiv:2211.08064 (2022). 44
arXiv 2022
-
[47]
A. Zhou, A. B. Farimani, Masked autoencoders are PDE learners, Transactions on Machine Learning Research (2024). URLhttps://openreview.net/forum?id=rZNuiFwXVs
2024
-
[48]
Taghizadeh, M
M. Taghizadeh, M. A. Nabian, N. Alemazkoor, Multi-fidelity physics-informed generative adversarial network for solving partial differential equations, Journal of Computing and Information Science in Engineering 24 (11) (2024) 111003
2024
-
[49]
H. Xue, A. Araujo, B. Hu, Y. Chen, Diffusion-based adversarial sample generation for improved stealthiness and controllability, Advances in Neural Information Processing Systems 36 (2023) 2894–2921. 45
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.