Refploit: Facilitating Exploit Construction via Code-Agent Trajectory Repair
Pith reviewed 2026-07-03 09:06 UTC · model grok-4.3
The pith
Refploit repairs failed code-agent trajectories via differential execution validation to reproduce 80.2 percent of Java vulnerability exploits from incomplete public references.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Refploit is an LLM-based trajectory recovery framework that first validates an agent-generated exploit through differential execution between vulnerable and patched library versions. When the exploit proves ineffective, Refploit analyzes the reproduction progress within the trajectory, locates the segments tied to completed subtasks, and derives constraints to guide focused recovery of the remaining steps.
What carries the argument
Differential execution validator that compares outcomes on vulnerable versus patched library versions, combined with progress analysis to extract and apply recovery constraints from partial trajectories.
If this is right
- More public exploit references can be turned into working tests without full manual reconstruction.
- The same recovery process yields consistent gains when applied to a different underlying code agent.
- Automated reproduction becomes feasible at larger scale across open-source Java libraries.
- Exploit-generation pipelines that previously stopped at first failure can now continue from partial successes.
Where Pith is reading between the lines
- Security teams could integrate trajectory repair into continuous vulnerability scanning to produce proof-of-concept tests faster.
- The technique may extend to other languages if equivalent pairs of vulnerable and patched library builds are available for differential testing.
- Failed agent runs become a reusable source of negative examples that can improve future agent prompting without additional human labeling.
Load-bearing premise
Differential execution between vulnerable and patched library versions can reliably tell whether an agent-generated exploit actually triggers the vulnerable logic rather than producing superficially successful but ineffective code.
What would settle it
A collection of cases in which differential execution reports success but independent manual inspection or additional test oracles show the exploit never reaches the vulnerable code path.
Figures
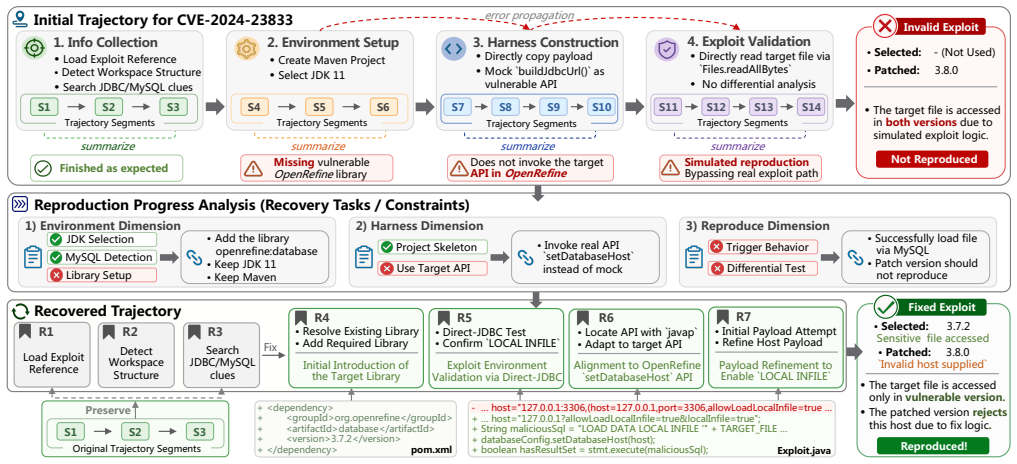
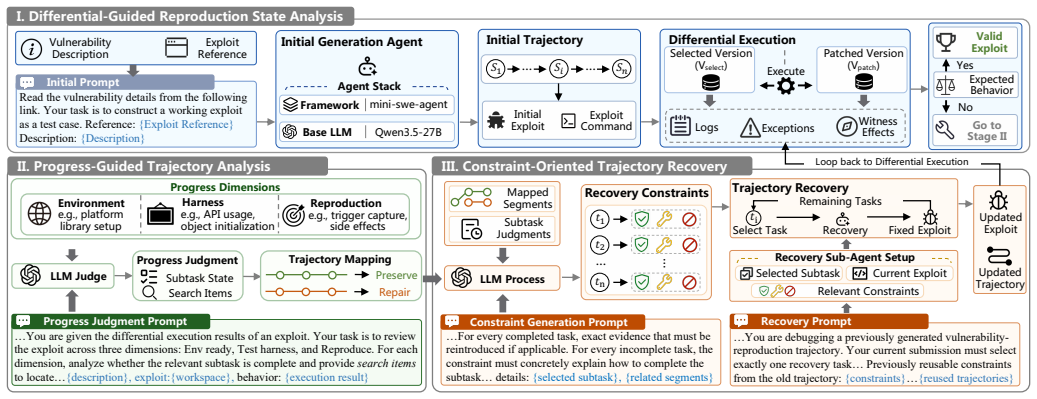
read the original abstract
Vulnerability exploits play a crucial role in assessing the downstream impact of Java library vulnerabilities. While some vulnerabilities are accompanied by disclosed exploit references, automatically reproducing such references into runnable exploits remains challenging because they are often incomplete, unstructured, or only describe partial reproduction steps. Recent code agents provide a promising way to automate this process, but our study shows that their generated exploits often appear successful without triggering the actual vulnerable logic, such as replacing vulnerable APIs with self-implemented functions. To address this, we propose Refploit, an LLM-based trajectory recovery framework for facilitating vulnerability reproduction from public exploit references. The key insight is that a failed agent trajectory is not entirely useless. It may have already completed some reproduction subtasks while also revealing misleading directions that should be avoided. Refploit first validates an agent-generated exploit through differential execution. When the exploit is ineffective, Refploit analyzes its reproduction progress, locates the trajectory segments associated with the reproduction progress, and derives constraints to guide focused recovery. We evaluate Refploit on three open-source Java vulnerability datasets, covering 172 exploit references for 143 vulnerabilities. Under DeepSeek-V4-Flash, Refploit successfully reproduces 138 exploits, achieving a reproduction rate of 80.2%. It achieves a 64.3% relative improvement over the initially generated trajectories and outperforms both the SOTA exploit-generation method PoCGen and advanced code agents such as Codex with GPT-5.4. We further adapt Refploit to another code agent and observe consistent improvements, demonstrating its generality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Refploit, an LLM-based framework for repairing failed code-agent trajectories to reproduce Java library vulnerability exploits from incomplete public references. It validates generated exploits via differential execution on vulnerable vs. patched library versions; for ineffective cases, it analyzes reproduction progress in the trajectory, locates relevant segments, and derives constraints to guide recovery. Evaluated on 172 exploit references for 143 vulnerabilities from three open-source Java datasets, Refploit achieves an 80.2% reproduction rate with DeepSeek-V4-Flash (64.3% relative improvement over initial trajectories) and outperforms PoCGen as well as agents such as Codex with GPT-5.4; consistent gains are shown when adapted to another code agent.
Significance. If the differential execution oracle is shown to reliably identify trajectories that trigger the vulnerable logic (rather than superficial behavioral differences), the work offers a practical advance in automated exploit construction by salvaging partial progress from failed agent runs. The multi-dataset evaluation, direct comparisons to SOTA methods, and cross-agent generality provide a solid empirical foundation for the central claims.
major comments (2)
- [Abstract and method description] Abstract and method description: Differential execution is the load-bearing oracle for the reported 80.2% reproduction rate and 64.3% relative improvement. The abstract itself notes that naive agents can appear successful by replacing vulnerable APIs with self-implemented functions; the manuscript must specify (with concrete implementation details) how the differential check rules out analogous false positives arising from side effects, unrelated exception paths, or version-specific behavior orthogonal to the CVE.
- [Evaluation] Evaluation: The outperformance claims versus PoCGen and Codex with GPT-5.4 rest on the reproduction metric; without explicit controls (identical LLM back-ends, prompt templates, and success criteria across baselines) the 64.3% relative gain cannot be isolated from implementation differences.
minor comments (1)
- [Abstract] Clarify whether the 172 references map one-to-one with the 143 vulnerabilities or include multiple references per vulnerability, and report per-dataset breakdowns of the 138 successful reproductions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting areas where additional clarity will strengthen the manuscript. We address each major comment below and commit to revisions that improve the presentation of the differential execution oracle and the fairness of baseline comparisons.
read point-by-point responses
-
Referee: [Abstract and method description] Abstract and method description: Differential execution is the load-bearing oracle for the reported 80.2% reproduction rate and 64.3% relative improvement. The abstract itself notes that naive agents can appear successful by replacing vulnerable APIs with self-implemented functions; the manuscript must specify (with concrete implementation details) how the differential check rules out analogous false positives arising from side effects, unrelated exception paths, or version-specific behavior orthogonal to the CVE.
Authors: We agree that the current description of the differential execution oracle would benefit from more concrete implementation details to explicitly rule out the listed classes of false positives. In the revised manuscript we will add a new subsection (under Section 3.2) that provides: (1) the exact instrumentation points used to capture CVE-relevant API calls and exception signatures; (2) the trace-comparison logic that requires a behavioral divergence only on the vulnerable path while discarding unrelated side effects and orthogonal version differences; and (3) pseudocode together with a worked example from one of the evaluated CVEs. These additions will make the oracle’s false-positive rejection criteria fully reproducible. revision: yes
-
Referee: [Evaluation] Evaluation: The outperformance claims versus PoCGen and Codex with GPT-5.4 rest on the reproduction metric; without explicit controls (identical LLM back-ends, prompt templates, and success criteria across baselines) the 64.3% relative gain cannot be isolated from implementation differences.
Authors: We acknowledge the importance of explicit controls. The success criterion (differential execution on vulnerable vs. patched versions) was applied uniformly to all methods. However, the manuscript does not currently tabulate the precise prompt templates or back-end configurations used for each baseline. We will add an appendix that lists the exact prompts, confirms identical success criteria, and notes any unavoidable differences (e.g., Codex with GPT-5.4 uses its native agent interface). This will allow readers to isolate the contribution of Refploit’s recovery mechanism from implementation variance. revision: yes
Circularity Check
No circularity; evaluation uses external datasets and independent baselines
full rationale
The paper evaluates Refploit on three open-source Java vulnerability datasets (172 exploit references for 143 vulnerabilities) and reports reproduction rates against those fixed references. Success is measured via differential execution between vulnerable and patched library versions, with explicit comparisons to external methods (PoCGen, Codex+GPT-5.4). No parameters are fitted to the target metric, no self-citations form the load-bearing justification, and no derivation reduces to a renaming or self-definition of the reported 80.2% rate or 64.3% improvement. The central claims are therefore falsifiable against the cited external corpora and baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three open-source Java vulnerability datasets covering 172 exploit references are representative for evaluating reproduction methods.
Reference graph
Works this paper leans on
-
[1]
OPEN SOURCE SECURITY AND RISK ANALYSIS REPORT 2023
Synopsys. OPEN SOURCE SECURITY AND RISK ANALYSIS REPORT 2023. [Online]. Available: https://www.synopsys.com/software-integrity/resources/analyst-reports/ open-source-security-risk-analysis.html
2023
-
[2]
Cneps: A precise approach for examining dependencies among third-party c/c++ open-source components,
Y . Na, S. Woo, J. Lee, and H. Lee, “Cneps: A precise approach for examining dependencies among third-party c/c++ open-source components,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available: https://doi.org/10.1145/3597503.3639209
-
[3]
Do developers update their library dependencies? an empirical study on the impact of security advisories on library migration,
R. G. Kula, D. M. German, A. Ouni, T. Ishio, and K. Inoue, “Do developers update their library dependencies? an empirical study on the impact of security advisories on library migration,”Empirical Software Engineering, vol. 23, pp. 384–417, 2018
2018
-
[4]
Symbisect: accurate bisection for fuzzer-exposed vulner- abilities,
Z. Zhang, Y . Hao, W. Chen, X. Zou, X. Li, H. Li, Y . Zhai, Z. Qian, and B. Lau, “Symbisect: accurate bisection for fuzzer-exposed vulner- abilities,” inProceedings of the 33rd USENIX Conference on Security Symposium, ser. SEC ’24. USA: USENIX Association, 2024
2024
-
[5]
Fixing outside the box: Uncovering tactics for open-source security issue management,
L. Zhang, J. Wu, C. Liu, K. Li, X. Sun, L. Zhao, C. Wang, and Y . Liu, “Fixing outside the box: Uncovering tactics for open-source security issue management,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, Jun
-
[6]
Available: https://doi.org/10.1145/3728977
[Online]. Available: https://doi.org/10.1145/3728977
-
[7]
Nodemedic- fine: Automatic detection and exploit synthesis for node. js vulnerabili- ties
D. Cassel, N. Sabino, M.-C. Hsu, R. Martins, and L. Jia, “Nodemedic- fine: Automatic detection and exploit synthesis for node. js vulnerabili- ties.” inNDSS, 2025
2025
-
[8]
Smallworld with high risks: a study of security threats in the npm ecosystem,
M. Zimmermann, C.-A. Staicu, C. Tenny, and M. Pradel, “Smallworld with high risks: a study of security threats in the npm ecosystem,” in Proceedings of the 28th USENIX Conference on Security Symposium, ser. SEC’19. USA: USENIX Association, 2019, p. 995–1010
2019
-
[9]
Exploiting library vulnerability via migration based automating test generation,
S. Wu, W. Song, K. Huang, B. Chen, and X. Peng, “Identifying affected libraries and their ecosystems for open source software vulnerabilities,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available: https://doi.org/10.1145/35975...
-
[10]
Exploiting library vulnerability via migration based automating test generation,
Z. Chen, X. Hu, X. Xia, Y . Gao, T. Xu, D. Lo, and X. Yang, “Exploiting library vulnerability via migration based automating test generation,” in2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). Los Alamitos, CA, USA: IEEE Computer Society, apr 2024, pp. 2820–2831. [Online]. Available: https://doi.ieeecomputersociety.org/10.1145/...
-
[11]
Automating dependency updates in practice: An exploratory study on github dependabot,
R. He, H. He, Y . Zhang, and M. Zhou, “Automating dependency updates in practice: An exploratory study on github dependabot,”IEEE Trans. Softw. Eng., vol. 49, no. 8, p. 4004–4022, Aug. 2023. [Online]. Available: https://doi.org/10.1109/TSE.2023.3278129
-
[12]
An empirical study on vulnerability disclosure management of open source software systems,
S. Liu, J. Zhou, X. Hu, F. R. Cogo, X. Xia, and X. Yang, “An empirical study on vulnerability disclosure management of open source software systems,”ACM Trans. Softw. Eng. Methodol., vol. 34, no. 7, Aug. 2025. [Online]. Available: https://doi.org/10.1145/3716822
-
[13]
How the apache community upgrades dependencies: an evolutionary study,
G. Bavota, G. Canfora, M. Di Penta, R. Oliveto, and S. Panichella, “How the apache community upgrades dependencies: an evolutionary study,” Empirical Software Engineering, vol. 20, pp. 1275–1317, 2015
2015
-
[14]
Libam: An area matching framework for detecting third-party libraries in binaries,
S. Li, Y . Wang, C. Dong, S. Yang, H. Li, H. Sun, Z. Lang, Z. Chen, W. Wang, H. Zhu, and L. Sun, “Libam: An area matching framework for detecting third-party libraries in binaries,”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 2, Dec. 2023. [Online]. Available: https://doi.org/10.1145/3625294
-
[15]
What are weak links in the npm supply chain?
N. Zahan, T. Zimmermann, P. Godefroid, B. Murphy, C. Maddila, and L. Williams, “What are weak links in the npm supply chain?” inProceedings of the 44th International Conference on Software Engineering: Software Engineering in Practice, ser. ICSE-SEIP ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 331–340. [Online]. Available: https...
-
[16]
Mvnrepository
MvnRepository, “Mvnrepository.” [Online]. Available: https: //mvnrepository.com/repos
-
[17]
T. Avgerinos, S. K. Cha, A. Rebert, E. J. Schwartz, M. Woo, and D. Brumley, “Automatic exploit generation,”Commun. ACM, vol. 57, no. 2, p. 74–84, feb 2014. [Online]. Available: https: //doi.org/10.1145/2560217.2560219
-
[18]
Facilitating vulnerability assessment through poc migration,
J. Dai, Y . Zhang, H. Xu, H. Lyu, Z. Wu, X. Xing, and M. Yang, “Facilitating vulnerability assessment through poc migration,” in Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 3300–3317. [Online]. Available: https://doi.org/10.1145/34601...
-
[19]
Aem: Facilitating cross-version exploitability assessment of linux kernel vul- nerabilities,
Z. Jiang, Y . Zhang, J. Xu, X. Sun, Z. Liu, and M. Yang, “Aem: Facilitating cross-version exploitability assessment of linux kernel vul- nerabilities,” in2023 IEEE Symposium on Security and Privacy (SP), 2023, pp. 2122–2137
2023
-
[20]
Diffploit: Facilitating cross-version exploit migration for open source library vulnerabilities,
Z. Chen, Z. Xue, J. Zhou, X. Hu, X. Xia, and X. Yang, “Diffploit: Facilitating cross-version exploit migration for open source library vulnerabilities,” 2025. [Online]. Available: https: //arxiv.org/abs/2511.12950
-
[21]
Z. Zhou, Y . Yang, S. Wu, Y . Huang, B. Chen, and X. Peng, “Magneto: A step-wise approach to exploit vulnerabilities in dependent libraries via llm-empowered directed fuzzing,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ser. ASE ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 1633–...
-
[22]
Test mimicry to assess the exploitability of library vulnerabilities,
H. J. Kang, T. G. Nguyen, B. Le, C. S. P ˘as˘areanu, and D. Lo, “Test mimicry to assess the exploitability of library vulnerabilities,” in Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2022. New York, NY , USA: Association for Computing Machinery, 2022, p. 276–288. [Online]. Available: https://doi...
-
[23]
Chainfuzz: exploiting upstream vulnerabilities in open-source supply chains,
P. Deng, L. Zhang, Y . Meng, Z. Yang, Y . Zhang, and M. Yang, “Chainfuzz: exploiting upstream vulnerabilities in open-source supply chains,” inProceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
2025
-
[24]
Secbench.js: An executable security benchmark suite for server-side javascript,
M. H. M. Bhuiyan, A. S. Parthasarathy, N. Vasilakis, M. Pradel, and C.-A. Staicu, “Secbench.js: An executable security benchmark suite for server-side javascript,” in2023 IEEE/ACM 45th International Confer- ence on Software Engineering (ICSE), 2023, pp. 1059–1070
2023
-
[25]
PoCGen: Generating Proof-of-Concept Exploits for Vulnerabilities in Npm Packages
D. Simsek, A. Eghbali, and M. Pradel, “Pocgen: Generating proof-of- concept exploits for vulnerabilities in npm packages,” 2025. [Online]. Available: https://arxiv.org/abs/2506.04962
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Faultline: Automated proof-of-vulnerability generation using llm agents,
V . Nitin, B. Ray, and R. Z. Moghaddam, “Faultline: Automated proof-of-vulnerability generation using llm agents,” 2025. [Online]. Available: https://arxiv.org/abs/2507.15241
-
[27]
IRIS: LLM-assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “IRIS: LLM-assisted static analysis for detecting security vulnerabilities,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=9LdJDU7E91
2025
-
[28]
Vision: Identifying affected library versions for open source software vulnerabilities,
S. Wu, R. Wang, K. Huang, Y . Cao, W. Song, Z. Zhou, Y . Huang, B. Chen, and X. Peng, “Vision: Identifying affected library versions for open source software vulnerabilities,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ser. ASE ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 1447–1...
-
[29]
You name it, i run it: An llm agent to execute tests of arbitrary projects,
I. Bouzenia and M. Pradel, “You name it, i run it: An llm agent to execute tests of arbitrary projects,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, Jun. 2025. [Online]. Available: https://doi.org/10.1145/3728922
-
[30]
Cxxcrafter: An llm-based agent for automated c/c++ open source software building,
Z. Yu, Y . Zhang, M. Wen, Y . Nie, W. Zhang, and M. Yang, “Cxxcrafter: An llm-based agent for automated c/c++ open source software building,”Proc. ACM Softw. Eng., vol. 2, no. FSE, Jun. 2025. [Online]. Available: https://doi.org/10.1145/3729386
-
[31]
Agentboard: An analytical evaluation board of multi-turn LLM agents,
C. Ma, J. Zhang, Z. Zhu, C. Yang, Y . Yang, Y . Jin, Z. Lan, L. Kong, and J. He, “Agentboard: An analytical evaluation board of multi-turn LLM agents,” inThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. [Online]. Available: https://openreview.net/forum?id=4S8agvKjle
2024
-
[32]
Z. Chen, Q. Zhan, J. Zhou, X. Hu, X. Xia, and X. Yang, “A large-scale empirical study on the generalizability of disclosed java library vulnerability exploits,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.25997
-
[33]
A. Xu, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, C. Linget al., “Deepseek-v4: Towards highly efficient million- token context intelligence,”arXiv preprint arXiv:2606.19348, 2026
-
[34]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February
-
[35]
Available: https://qwen.ai/blog?id=qwen3.5
[Online]. Available: https://qwen.ai/blog?id=qwen3.5
-
[36]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “Openhands: An open platform for ai software developers as generalist agents,” 2025. [Online]. Available: https://arxiv.org/ab...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Introducing codex,
OpenAI, “Introducing codex,” 2025. [Online]. Available: https: //openai.com/index/introducing-codex/
2025
-
[39]
Autogpt,
S. Gravitas, “Autogpt,” 2024. [Online]. Available: https://github.com/ Significant-Gravitas/AutoGPT
2024
-
[40]
Hirebuild: an automatic approach to history- driven repair of build scripts,
F. Hassan and X. Wang, “Hirebuild: an automatic approach to history- driven repair of build scripts,” inProceedings of the 40th International Conference on Software Engineering, ser. ICSE ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 1078–1089. [Online]. Available: https://doi.org/10.1145/3180155.3180181
-
[41]
Automatic building of java projects in software repositories: a study on feasibility and challenges,
F. Hassan, S. Mostafa, E. S. L. Lam, and X. Wang, “Automatic building of java projects in software repositories: a study on feasibility and challenges,” inProceedings of the 11th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, ser. ESEM ’17. IEEE Press, 2017, p. 38–47. [Online]. Available: https://doi.org/10.1109/ESEM.2017.11
-
[42]
Understanding build issue resolution in practice: symptoms and fix patterns,
Y . Lou, Z. Chen, Y . Cao, D. Hao, and L. Zhang, “Understanding build issue resolution in practice: symptoms and fix patterns,” in Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ser. ESEC/FSE 2020. New York, NY , USA: Association for Computing Machinery, 2020,...
-
[43]
Buildsheriff: change- aware test failure triage for continuous integration builds,
C. Zhang, B. Chen, X. Peng, and W. Zhao, “Buildsheriff: change- aware test failure triage for continuous integration builds,” in Proceedings of the 44th International Conference on Software Engineering, ser. ICSE ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 312–324. [Online]. Available: https://doi.org/10.1145/3510003.3510132
-
[44]
1dfuzz: Reproduce 1-day vulnerabilities with directed differential fuzzing,
S. Yang, Y . He, K. Chen, Z. Ma, X. Luo, Y . Xie, J. Chen, and C. Zhang, “1dfuzz: Reproduce 1-day vulnerabilities with directed differential fuzzing,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2023. New York, NY , USA: Association for Computing Machinery, 2023, p. 867–879. [Online]. Availabl...
-
[45]
Why do multi-agent llm systems fail?
M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ramchandranet al., “Why do multi-agent llm systems fail?”Advances in Neural Information Processing Systems, vol. 38, 2026
2026
-
[46]
Trail: Trace reasoning and agentic issue localization,
D. Deshpande, V . Gangal, H. Mehta, J. Krishnan, A. Kannappan, and R. Qian, “Trail: Trace reasoning and agentic issue localization,” 2025. [Online]. Available: https://arxiv.org/abs/2505.08638
-
[47]
Interactive debugging and steering of multi-agent ai systems,
W. Epperson, G. Bansal, V . C. Dibia, A. Fourney, J. Gerrits, E. E. Zhu, and S. Amershi, “Interactive debugging and steering of multi-agent ai systems,” inProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, ser. CHI ’25. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/37...
-
[48]
Dover: Intervention-driven auto debugging for llm multi- agent systems,
M. Ma, J. Zhang, F. Yang, Y . Kang, Q. Lin, S. Rajmohan, and D. Zhang, “Dover: Intervention-driven auto debugging for llm multi- agent systems,”arXiv preprint arXiv:2512.06749, 2025
-
[49]
Y . Ge, L. Xie, Z. Li, Y . Pei, and T. Zhang, “Who is introducing the failure? automatically attributing failures of multi-agent systems via spectrum analysis,” 2025. [Online]. Available: https://arxiv.org/abs/ 2509.13782
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.