Boundary Suppression Asymmetry in Post-trained Assistants: Over-expansion as a Controllability Cost
Pith reviewed 2026-06-29 12:34 UTC · model grok-4.3
The pith
Post-training makes suppressing over-expansion harder than invoking it in language model assistants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
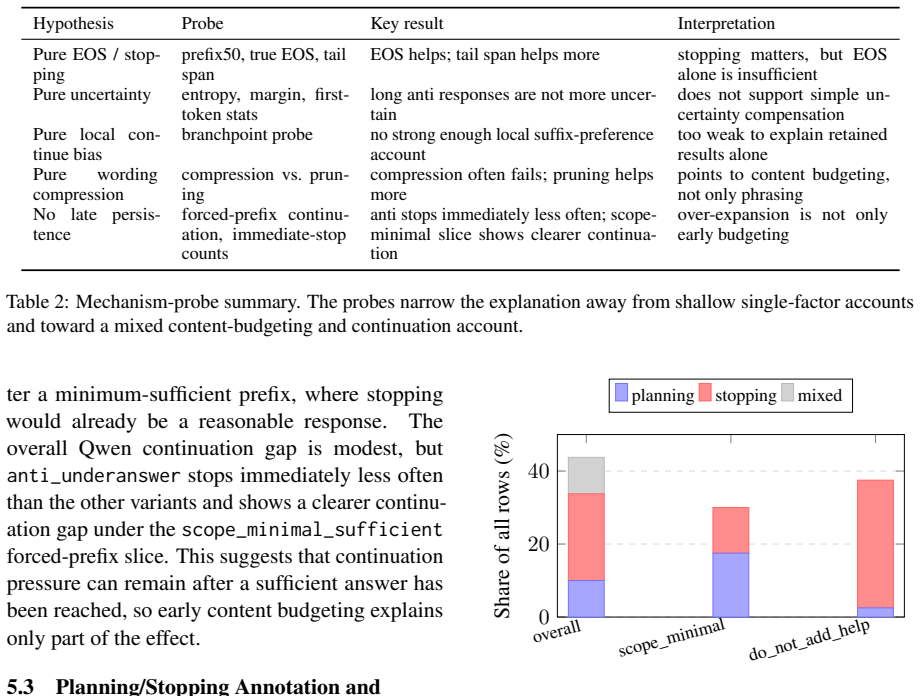
Post-trained language-model assistants exhibit boundary-suppression asymmetry. Anti-underanswering policies prove harder to pull back than the baseline under matched boundary-control evaluations, while minimal-boundary variants avoid the upward shift. Mechanism probes rule out simple length, EOS failure, uncertainty compensation, or local continuation bias as sole causes. The evidence favors a mixed planning/stopping account where content-budget overshoot and continuation persistence jointly make boundary correction harder.
What carries the argument
Boundary-suppression asymmetry: the selective resistance, concentrated on too-much-assistant directions such as over-completion and anti-underanswering, to explicit user requests for narrower response boundaries.
If this is right
- Anti-underanswering policies remain harder to suppress than baseline in direct boundary-control comparisons.
- Minimal-boundary variants generally avoid the anti-side upward shift observed in other variants.
- The anti-over-baseline ordering holds under shared-system and larger-scale robustness checks.
- The cost is direction-specific rather than uniform across all response dimensions.
Where Pith is reading between the lines
- Alignment objectives that reward completeness may require complementary training signals for local suppression.
- Prompting techniques for precise scope control could need to compensate for the observed persistence of over-expansion tendencies.
- The same directional cost might appear when post-training emphasizes other one-sided goals such as maximal caution or maximal proactivity.
Load-bearing premise
The prompt-side probes and controlled policy variants isolate suppression difficulty without residual confounding from the shared base model or from unmeasured differences in how the variants were derived.
What would settle it
An experiment in which anti-underanswering policies suppress as easily as baseline under varied prompt structures or alternative boundary metrics would falsify the claimed asymmetry.
Figures

read the original abstract
Post-trained language-model assistants are often optimized to avoid under-answering, encouraging complete, helpful, cautious, and proactive responses. We ask whether this optimization creates asymmetric controllability costs: when users explicitly request narrower answers, which assistant behaviors remain suppressible, and which continue to shape the response? We study this problem as boundary-suppression asymmetry. Prompt-side probes across multiple high-level response dimensions suggest a selective cost, concentrated around `too-much assistant' directions such as over-completion, extra help, and anti-underanswering. Using controlled assistant-policy variants derived from a shared base model, we find that anti-underanswering policies are harder to pull back than the baseline under matched boundary-control evaluations, while minimal-boundary variants generally avoid this anti-side upward shift in the direct boundary-control comparisons. Mechanism-oriented probes point beyond longer default outputs, pure EOS failure, uncertainty compensation, and local continuation bias, while robustness checks preserve the main anti-over-baseline ordering under shared-system and larger-scale settings. The evidence supports a mixed planning/stopping account, where content-budget overshoot and continuation persistence jointly make boundary correction harder. Overall, post-training may create direction-specific controllability costs: some helpful assistant tendencies remain easy to invoke, yet harder to locally suppress.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-training of language-model assistants for helpfulness, completeness, and proactivity creates asymmetric controllability costs. Specifically, when users request narrower responses, behaviors associated with over-expansion (over-completion, extra help, anti-underanswering) are harder to suppress than other dimensions. Prompt-side probes and controlled policy variants derived from a shared base model show that anti-underanswering policies are harder to pull back under matched boundary-control evaluations, while minimal-boundary variants avoid this shift. Mechanism probes rule out several simpler explanations, and the results support a mixed planning/stopping account in which content-budget overshoot and continuation persistence jointly increase boundary-correction difficulty. Robustness checks preserve the main ordering under shared-system and larger-scale conditions.
Significance. If the reported ordering holds under the controlled variants and probes, the work identifies a concrete, direction-specific cost of post-training that is relevant to alignment and user control. The use of policy variants from a shared base model and the explicit comparison against multiple alternative mechanisms (longer defaults, EOS failure, uncertainty compensation, local continuation bias) are strengths. The mixed planning/stopping account offers a falsifiable framing that could guide follow-up experiments on controllability.
major comments (2)
- [§4] §4 (controlled policy variants): the claim that anti-underanswering policies are harder to pull back rests on the boundary-control evaluations; the manuscript should report the exact prompt templates, the definition of 'matched' conditions, and the statistical test used to establish the ordering, as residual differences in how the variants were derived could confound the isolation of suppression difficulty.
- [§5.2] §5.2 (mechanism-oriented probes): the ruling-out of pure EOS failure, uncertainty compensation, and local continuation bias is central to the mixed account; the paper should include the quantitative thresholds or effect sizes at which these alternatives were rejected, because the abstract states they are ruled out but does not indicate whether the tests had sufficient power to detect moderate effects.
minor comments (2)
- [Abstract / §6] The abstract refers to 'robustness checks' preserving the ordering; the main text should explicitly list which checks (shared-system, larger-scale) were performed and report the corresponding effect sizes or p-values.
- [§3] Notation for the response dimensions (over-completion, extra help, anti-underanswering) should be defined once in a table or glossary to avoid repeated descriptive phrases.
Simulated Author's Rebuttal
Thank you for the constructive feedback and the recommendation for minor revision. We address the major comments point-by-point below, agreeing to incorporate additional details for improved clarity and reproducibility.
read point-by-point responses
-
Referee: [§4] §4 (controlled policy variants): the claim that anti-underanswering policies are harder to pull back rests on the boundary-control evaluations; the manuscript should report the exact prompt templates, the definition of 'matched' conditions, and the statistical test used to establish the ordering, as residual differences in how the variants were derived could confound the isolation of suppression difficulty.
Authors: We agree with this suggestion. The revised manuscript will include the exact prompt templates used in the boundary-control evaluations in a new appendix section. We will define 'matched' conditions explicitly as using the same set of boundary-control prompts, identical decoding parameters, and the shared base model for all policy variants. Additionally, we will report the statistical test (paired t-tests across matched prompt sets) and associated p-values to establish the ordering, thereby addressing potential confounds from variant derivation differences. revision: yes
-
Referee: [§5.2] §5.2 (mechanism-oriented probes): the ruling-out of pure EOS failure, uncertainty compensation, and local continuation bias is central to the mixed account; the paper should include the quantitative thresholds or effect sizes at which these alternatives were rejected, because the abstract states they are ruled out but does not indicate whether the tests had sufficient power to detect moderate effects.
Authors: We concur that specifying the quantitative thresholds and effect sizes will strengthen the claims. In the revision, we will expand §5.2 to include effect sizes (e.g., mean differences and standard errors) and the rejection criteria (such as non-significant results with p > 0.1 and power calculations for moderate effects) for each alternative mechanism. This will demonstrate the tests' ability to detect moderate effects and better support the mixed planning/stopping account. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical results from prompt-side probes and controlled policy variants derived from a shared base model. The central claim of boundary-suppression asymmetry and the mixed planning/stopping account rest on the observed ordering of experimental outcomes under boundary-control evaluations, with no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the result to its inputs by construction. The design uses independent comparisons across response dimensions and robustness checks, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SteerLM: Attribute conditioned SFT as an al- ternative to RLHF.arXiv preprint arXiv:2310.05344. Heshan Fernando, Han Shen, Parikshit Ram, Yi Zhou, Horst Samulowitz, Nathalie Baracaldo, and Tianyi Chen. 2024. Understanding forgetting in LLM su- pervised fine-tuning and preference learning – a convex optimization perspective.arXiv preprint arXiv:2410.15483....
-
[2]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290. Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Adam Stiegler, Teven Le Scao, Arya Raja, and 1 others. 2021. Multitask prompted training en- ables zero-shot task generalization.arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
arXiv preprint arXiv:2406.17744
Following length constraints in instructions. arXiv preprint arXiv:2406.17744. Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Hu, Song- fang Huang, and Fei Huang. 2023. RRHF: Rank responses to align language models with human feed- back without tears. InAdvances in Neural Informa- tion Processing Systems, volume 36. Hanqing Zhang, Ji Liu, Chen Pan, Yiming Long...
-
[4]
A survey of controllable text generation us- ing transformer-based pre-trained language models. ACM Computing Surveys. Early version available as arXiv:2201.05337. Qinyan Zhang, Xinping Lei, Ruijie Miao, Yu Fu, Hao- jie Fan, Le Chang, Jiafan Hou, Dingling Zhang, Zhongfei Hou, Ziqiang Yang, Changxin Pu, Fei Hu, Jingkai Liu, Mengyun Liu, Yang Liu, Xiang Gao...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.