Training-free Controllable Human Motion Generation under Heterogeneous Constraints
Pith reviewed 2026-07-03 15:30 UTC · model grok-4.3
The pith
Casting diffusion motion generation as stochastic control unifies handling of both differentiable objective constraints and non-differentiable criterion constraints without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MIC is the first training-free motion generation framework that handles both continuous objective-based and criterion-based motion constraints under a shared mechanism by casting diffusion-based motion generation as a stochastic control problem. This perspective provides principled and practically effective step-wise control laws that support criterion-based constraints without requiring differentiability and naturally accommodate objective-based constraints as a special case, while also motivating a control-oriented constraint coordination mechanism that adaptively balances and reconciles motion constraints during generation.
What carries the argument
The stochastic control formulation of the diffusion denoising process, which yields explicit step-wise control laws for enforcing constraints at each generation step.
If this is right
- Criterion-based constraints with only discontinuous or black-box feedback become enforceable during generation.
- Objective-based constraints with differentiable losses are handled as a direct special case.
- Multiple heterogeneous constraints are balanced adaptively by a control-oriented coordination mechanism at each step.
- Effectiveness holds across diverse constraint settings in reported experiments.
Where Pith is reading between the lines
- The control perspective may transfer to other diffusion generation domains where constraints mix smooth and discrete forms.
- Real-time user interaction could supply criterion feedback directly to the step-wise laws without retraining.
- Longer or multi-person sequences might reveal whether the coordination mechanism scales without additional tuning.
Load-bearing premise
The stochastic control view of diffusion motion generation produces effective step-wise laws that can enforce criterion-based constraints without differentiability.
What would settle it
Generate motions under a non-differentiable criterion constraint such as requiring a foot to land exactly on a discrete target point at a specific frame; measure whether the success rate exceeds that of random sampling or existing training-free baselines on the same constraint.
Figures
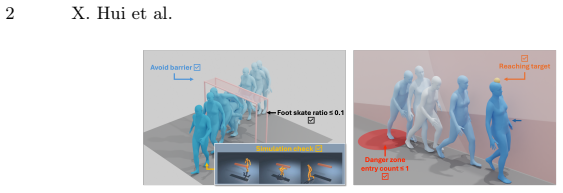
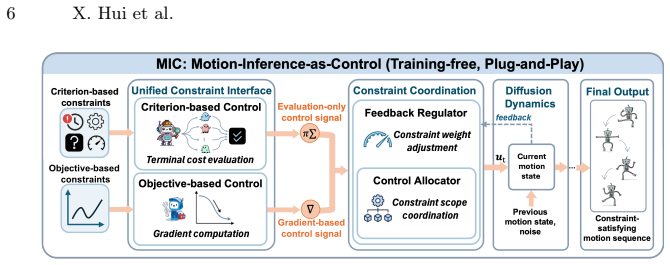
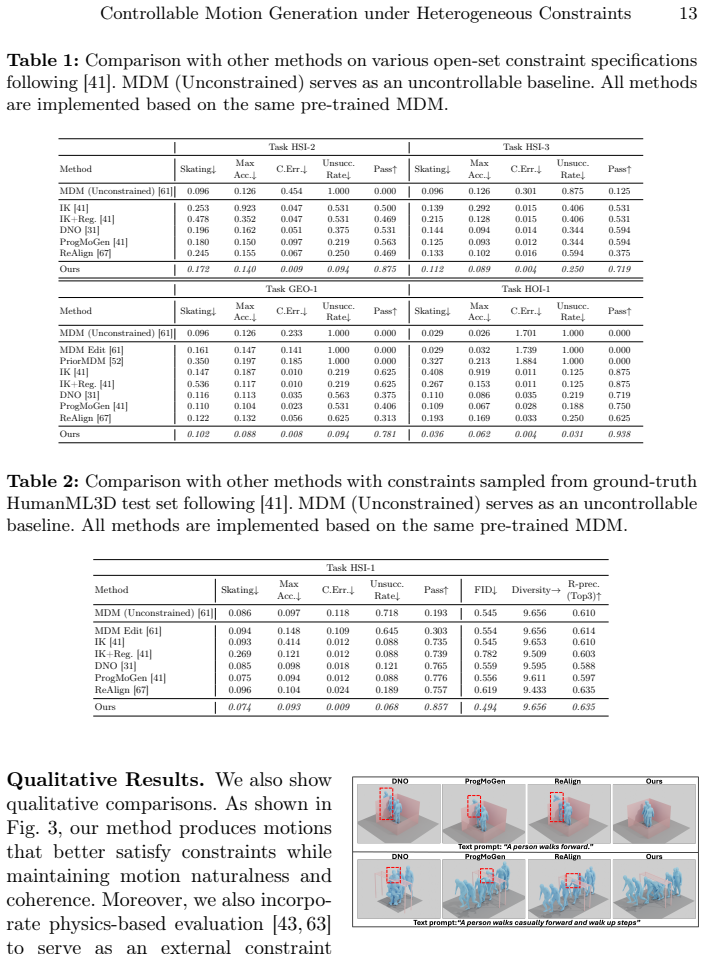
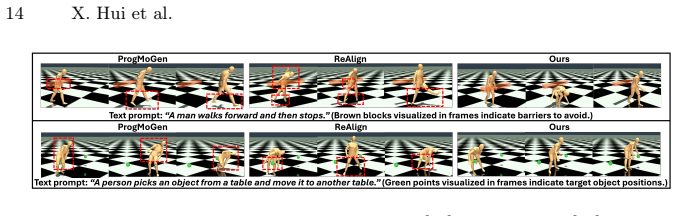

read the original abstract
Training-free controllable motion generation has attracted growing interest for enabling flexible constraint enforcement without constraint-specific training. However, existing training-free methods require constraints to be continuous objective-based with differentiable losses, while many real-world requirements are criterion-based and provide only discontinuous, sparse, or even black-box feedback. In this paper, we propose Motion-Inference-as-Control (MIC), the first training-free motion generation framework that handles both continuous objective-based and criterion-based motion constraints under a shared mechanism. The key idea is to cast diffusion-based motion generation as a stochastic control problem. This perspective not only provides principled and practically effective step-wise control laws that support criterion-based constraints without requiring differentiability and naturally accommodate objective-based constraints as a special case, but also motivates a control-oriented constraint coordination mechanism that adaptively balances and reconciles motion constraints during generation. Experiments across diverse constraint settings demonstrate the effectiveness of our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Motion-Inference-as-Control (MIC), the first training-free framework for controllable human motion generation under heterogeneous constraints. It casts diffusion-based motion generation as a stochastic control problem to obtain step-wise control laws that handle both continuous objective-based constraints (treated as a special case) and criterion-based constraints (discontinuous, sparse, or black-box) without requiring differentiability. The approach also introduces a control-oriented mechanism to adaptively balance and reconcile multiple constraints during generation. Experiments across diverse constraint settings are reported to demonstrate effectiveness.
Significance. If the stochastic control reformulation yields effective step-wise laws for non-differentiable constraints, the work would meaningfully extend training-free motion generation to a wider range of real-world requirements that existing gradient-based methods cannot accommodate. The unified mechanism and adaptive coordination could reduce the need for constraint-specific engineering.
major comments (1)
- [Abstract] Abstract, paragraph 3: the central claim that the stochastic control perspective 'provides principled and practically effective step-wise control laws that support criterion-based constraints without requiring differentiability' is asserted without any derivation, approximation scheme, or explicit control-law equation. Standard diffusion guidance relies on constraint gradients; extending to non-differentiable feedback requires additional mechanisms (e.g., zeroth-order estimates) whose correctness is not secured by the framing alone. This is load-bearing for the 'first training-free framework handling both types under a shared mechanism' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 3: the central claim that the stochastic control perspective 'provides principled and practically effective step-wise control laws that support criterion-based constraints without requiring differentiability' is asserted without any derivation, approximation scheme, or explicit control-law equation. Standard diffusion guidance relies on constraint gradients; extending to non-differentiable feedback requires additional mechanisms (e.g., zeroth-order estimates) whose correctness is not secured by the framing alone. This is load-bearing for the 'first training-free framework handling both types under a shared mechanism' claim.
Authors: We thank the referee for this observation. The abstract is a concise summary; the full derivation appears in Section 3, where the reverse diffusion process is recast as a finite-horizon stochastic control problem. The resulting step-wise control law is obtained by solving the associated stochastic Hamilton-Jacobi-Bellman equation (Eq. 7), which yields an explicit feedback form that depends only on the current state and the constraint value. For criterion-based (non-differentiable) constraints the same law is applied by evaluating the constraint directly inside the cost functional, without any gradient; the derivation shows that the optimality condition remains valid under the weaker assumption that the constraint is measurable. Objective-based constraints emerge as the special case in which the cost is differentiable. The shared mechanism therefore follows directly from the control formulation rather than from an ad-hoc extension of gradient guidance. If the editor wishes, we will add a parenthetical reference to Eq. 7 in the abstract. revision: partial
Circularity Check
No circularity detected; stochastic control framing is presented as independent perspective
full rationale
The abstract and description introduce MIC by casting diffusion motion generation as a stochastic control problem to obtain step-wise laws for heterogeneous constraints. No equations, fitted parameters, or self-citations are exhibited that reduce the claimed control laws or coordination mechanism to prior inputs by construction. The derivation chain is self-contained as a novel perspective rather than a renaming or statistical forcing of existing quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Princeton University Press (2021),https://books.google.co.uk/books? id=qZ0DEAAAQBAJ
Åström, K.J., Murray, R.: Feedback systems: an introduction for scientists and en- gineers. Princeton University Press (2021),https://books.google.co.uk/books? id=qZ0DEAAAQBAJ
2021
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bae, J., Hwang, I., Lee, Y.Y., Guo, Z., Liu, J., Ben-Shabat, Y., Kim, Y.M., Kapa- dia, M.: Less is more: Improving motion diffusion models with sparse keyframes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11069–11078 (2025)
2025
-
[3]
Actuators12(7) (2023).https://doi.org/10.3390/ act12070282,https://www.mdpi.com/2076-0825/12/7/282
Blaha, T.M., Smeur, E.J.J., Remes, B.D.W.: A survey of optimal control allocation for aerial vehicle control. Actuators12(7) (2023).https://doi.org/10.3390/ act12070282,https://www.mdpi.com/2076-0825/12/7/282
2023
-
[4]
In: Handbook of statistics, vol
Botev,Z.I.,Kroese,D.P.,Rubinstein,R.Y.,L’ecuyer,P.:Thecross-entropymethod for optimization. In: Handbook of statistics, vol. 31, pp. 35–59. Elsevier (2013)
2013
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cai, Y., Wang, Y., Zhu, Y., Cham, T.J., Cai, J., Yuan, J., Liu, J., Zheng, C., Yan, S., Ding, H., et al.: A unified 3d human motion synthesis model via condi- tional variational auto-encoder. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11645–11655 (2021)
2021
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cao, B., Zheng, S., Wang, Y., Xia, L., Wei, Q., Jin, Q., Liu, J., Lu, Z.: Motionc- trl: A real-time controllable vision-language-motion model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12253–12262 (2025)
2025
-
[7]
Caserman, P., Garcia-Agundez, A., Göbel, S.: A survey of full-body motion recon- struction in immersive virtual reality applications. IEEE Transactions on Visual- ization and Computer Graphics26(10), 3089–3108 (2020).https://doi.org/10. 1109/TVCG.2019.2912607
-
[8]
arXiv preprint arXiv:2410.18977 (2024)
Chen, L.H., Lu, S., Dai, W., Dou, Z., Ju, X., Wang, J., Komura, T., Zhang, L.: Pay attention and move better: Harnessing attention for interactive motion generation and training-free editing. arXiv preprint arXiv:2410.18977 (2024)
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, X., Jiang, B., Liu, W., Huang, Z., Fu, B., Chen, T., Yu, G.: Executing your commands via motion diffusion in latent space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18000–18010 (2023)
2023
-
[10]
In: Proceedings of Robotics: Science and Systems
Cheng, X., Ji, Y., Chen, J., Yang, R., Yang, G., Wang, X.: Expressive Whole-Body Control for Humanoid Robots. In: Proceedings of Robotics: Science and Systems. Delft, Netherlands (July 2024).https://doi.org/10.15607/RSS.2024.XX.107
-
[11]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Christopher, J.K., Baek, S., Fioretto, F.: Constrained synthesis with projected dif- fusion models. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neural Information Processing Sys- tems. vol. 37, pp. 89307–89333. Curran Associates, Inc. (2024).https://doi. org/10.52202/079017-2834,https://proce...
-
[12]
In: The Eleventh International Con- ference on Learning Representations (2023),https://openreview.net/forum?id= OnD9zGAGT0k
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sampling for general noisy inverse problems. In: The Eleventh International Con- ference on Learning Representations (2023),https://openreview.net/forum?id= OnD9zGAGT0k
2023
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Dabral, R., Mughal, M.H., Golyanik, V., Theobalt, C.: Mofusion: A framework for denoising-diffusion-based motion synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9760–9770 (2023)
2023
-
[14]
In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Degardin, B., Neves, J., Lopes, V., Brito, J., Yaghoubi, E., Proença, H.: Generative adversarial graph convolutional networks for human action synthesis. In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1150–1159 (2022) Controllable Motion Generation under Heterogeneous Constraints 17
2022
-
[15]
In: The Thirteenth International Conference on Learning Represen- tations (2025),https://openreview.net/forum?id=xQBRrtQM8u
Domingo-Enrich, C., Drozdzal, M., Karrer, B., Chen, R.T.Q.: Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic op- timal control. In: The Thirteenth International Conference on Learning Represen- tations (2025),https://openreview.net/forum?id=xQBRrtQM8u
2025
-
[16]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Dou, H., Chen, Z., Li, Z., Li, H., Yang, L., Deng, Y.: Constrained particle seeking: Solving diffusion inverse problems with just forward passes. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 20870–20878 (2026)
2026
-
[17]
Journal of the American Statistical Association106(496), 1602–1614 (2011)
Efron, B.: Tweedie’s formula and selection bias. Journal of the American Statistical Association106(496), 1602–1614 (2011)
2011
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Foo, L.G., Gong, J., Rahmani, H., Liu, J.: Distribution-aligned diffusion for hu- man mesh recovery. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9221–9232 (2023)
2023
-
[19]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Girolamo, M., Lorenzo, M., Bicchierai, M., Berretti, S., Bagdanov, A.D.: No mocap needed: Post-training motion diffusion models with reinforcement learning using only textual prompts. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 967–976 (2026)
2026
-
[20]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Gong, J., Foo, L.G., Fan, Z., Ke, Q., Rahmani, H., Liu, J.: Diffpose: Toward more reliable 3d pose estimation. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 13041–13051 (2023)
2023
-
[21]
Journal of the Royal Statistical Society: Series B (Methodological)56(4), 549–581 (1994)
Grenander, U., Miller, M.I.: Representations of knowledge in complex systems. Journal of the Royal Statistical Society: Series B (Methodological)56(4), 549–581 (1994)
1994
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guo, C., Mu, Y., Javed, M.G., Wang, S., Cheng, L.: Momask: Generative masked modeling of 3d human motions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1900–1910 (2024)
1900
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating di- verse and natural 3d human motions from text. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5152–5161 (June 2022)
2022
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Guo, Z., Hu, Z., Soh, D.W., Zhao, N.: Motionlab: Unified human motion gener- ation and editing via the motion-condition-motion paradigm. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13869–13879 (2025)
2025
-
[25]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Han, G., Liang, M., Tang, J., Cheng, Y., Liu, W., Huang, S.: Reindiffuse: Crafting physically plausible motions with reinforced diffusion model. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 2218–2227. IEEE (2025)
2025
-
[26]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[27]
In: International Conference on Machine Learning
Huang,Y.,Ghatare,A.,Liu,Y.,Hu,Z.,Zhang,Q.,Sastry,C.S.,Gururani,S.,Oore, S.,Yue,Y.:Symbolicmusicgenerationwithnon-differentiableruleguideddiffusion. In: International Conference on Machine Learning. pp. 19772–19797. PMLR (2024)
2024
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Hwang, I., Bae, J., Lim, D., Kim, Y.M.: Motion synthesis with sparse and flexible keyjoint control. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 13203–13213 (October 2025)
2025
-
[29]
In: The Thirteenth International Conferenceon LearningRepresentations(2025),https://openreview.net/forum? id=IEul1M5pyk 18 X
Jeong, M., Hwang, Y., Lee, J., Jung, S., Kim, W.H.: HGM³: Hierarchical generative masked motion modeling with hard token mining. In: The Thirteenth International Conferenceon LearningRepresentations(2025),https://openreview.net/forum? id=IEul1M5pyk 18 X. Hui et al
2025
-
[30]
Advances in Neural Information Processing Systems36, 20067–20079 (2023)
Jiang, B., Chen, X., Liu, W., Yu, J., Yu, G., Chen, T.: Motiongpt: Human motion as a foreign language. Advances in Neural Information Processing Systems36, 20067–20079 (2023)
2023
-
[31]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Karunratanakul, K., Preechakul, K., Aksan, E., Beeler, T., Suwajanakorn, S., Tang, S.: Optimizing diffusion noise can serve as universal motion priors. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 1334–1345 (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Karunratanakul, K., Preechakul, K., Suwajanakorn, S., Tang, S.: Guided mo- tion diffusion for controllable human motion synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 2151–2162 (October 2023)
2023
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kim, J., Kim, B.S., Ye, J.C.: Free2guide: Training-free text-to-video alignment using image lvlm. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 17920–17929 (October 2025)
2025
-
[34]
Journal of Global Optimization 37(1), 137–157 (2007)
Kroese, D.P., Rubinstein, R.Y., Taimre, T.: Application of the cross-entropy method to clustering and vector quantization. Journal of Global Optimization 37(1), 137–157 (2007)
2007
-
[35]
Lee, K., Lee, S., Lee, J.: Interactivecharacter animation by learning multi-objective control. ACM Trans. Graph.37(6) (Dec 2018).https://doi.org/10.1145/ 3272127.3275071,https://doi.org/10.1145/3272127.3275071
-
[36]
In: European Conference on Computer Vision
Li, J., Clegg, A., Mottaghi, R., Wu, J., Puig, X., Liu, C.K.: Controllable human- object interaction synthesis. In: European Conference on Computer Vision. pp. 54–72. Springer (2024)
2024
-
[37]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Li, Z., Cheng, K., Ghosh, A., Bhattacharya, U., Gui, L., Bera, A.: Simmotionedit: Text-based human motion editing with motion similarity prediction. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 27827–27837 (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Z., Luo, M., Hou, R., Zhao, X., Liu, H., Chang, H., Liu, Z., Li, C.: Morph: A motion-free physics optimization framework for human motion generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14580–14589 (2025)
2025
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, Z., Rahmani, H., Ke, Q., Liu, J.: Longdiff: Training-free long video generation in one go. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17789–17798 (June 2025)
2025
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Rahmani, H., Zhang, J., Xue, Y., Mirmehdi, M., Kuen, J., Gu, J., Liu, J.: Diffgraph: An automated agent-driven model merging framework for in-the- wild text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 36713–36723 (2026)
2026
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, H., Zhan, X., Huang, S., Mu, T.J., Shan, Y.: Programmable motion generation for open-set motion control tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1399–1408 (2024)
2024
-
[42]
In: 35th British Machine Vision Confer- ence 2024, BMVC 2024, Glasgow, UK, November 25-28, 2024
Louis, N., Khoshlessan, M., Corso, J.J.: Measuring physical plausibility of 3d human poses using physics simulation. In: 35th British Machine Vision Confer- ence 2024, BMVC 2024, Glasgow, UK, November 25-28, 2024. BMVA (2024), https://bmva-archive.org.uk/bmvc/2024/papers/Paper_615/paper.pdf
2024
-
[43]
Advances in Neural Information Processing Systems35, 6815–6828 (2022)
Luo, Z., Iwase, S., Yuan, Y., Kitani, K.: Embodied scene-aware human pose esti- mation. Advances in Neural Information Processing Systems35, 6815–6828 (2022)
2022
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Meng, Z., Xie, Y., Peng, X., Han, Z., Jiang, H.: Rethinking diffusion for text-driven human motion generation: Redundant representations, evaluation, and masked au- toregression. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27859–27871 (2025) Controllable Motion Generation under Heterogeneous Constraints 19
2025
-
[45]
Electrical Engineering Series, CRC press (2018),https://books.google.co.uk/books?id=Kn50DwAAQBAJ
Naidu, D.S.: Optimal control systems. Electrical Engineering Series, CRC press (2018),https://books.google.co.uk/books?id=Kn50DwAAQBAJ
2018
-
[46]
Universitext, Springer Science & Business Media (2013),https://books.google
Oksendal, B.: Stochastic differential equations: an introduction with applications. Universitext, Springer Science & Business Media (2013),https://books.google. co.uk/books?id=gizqCAAAQBAJ
2013
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision
Ota, S., Yu, Q., Fujiwara, K., Ikehata, S., Sato, I.: Pino: Person-interaction noise optimization for long-duration and customizable motion generation of arbitrary- sized groups. In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision. pp. 10676–10685 (2025)
2025
-
[48]
In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id=Z0ffRRtOim
Pandey, K., Sofian, F.M., Draxler, F., Karaletsos, T., Mandt, S.: Variational con- trol for guidance in diffusion models. In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id=Z0ffRRtOim
2025
-
[49]
Ap- plied Mathematics and Optimization19(1), 187–202 (1989)
Pavon, M.: Stochastic control and nonequilibrium thermodynamical systems. Ap- plied Mathematics and Optimization19(1), 187–202 (1989)
1989
-
[50]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pinyoanuntapong, E., Saleem, M., Karunratanakul, K., Wang, P., Xue, H., Chen, C., Guo, C., Cao, J., Ren, J., Tulyakov, S.: Maskcontrol: Spatio-temporal con- trol for masked motion synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9955–9965 (2025)
2025
-
[51]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Salimans, T., Ho, J., Chen, X., Sidor, S., Sutskever, I.: Evolution strategies as a scalable alternative to reinforcement learning. arXiv preprint arXiv:1703.03864 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
In: The Twelfth International Conference on Learning Represen- tations (2024),https://openreview.net/forum?id=dTpbEdN9kr
Shafir, Y., Tevet, G., Kapon, R., Bermano, A.H.: Human motion diffusion as a generative prior. In: The Twelfth International Conference on Learning Represen- tations (2024),https://openreview.net/forum?id=dTpbEdN9kr
2024
-
[53]
Shen, Y., Jiang, X., Yang, Y., Wang, Y., Han, D., Li, D.: Understanding and im- provingtraining-freeloss-baseddiffusionguidance.AdvancesinNeuralInformation Processing Systems37, 108974–109002 (2024)
2024
-
[54]
In: International Conference on Machine Learning
Song, J., Zhang, Q., Yin, H., Mardani, M., Liu, M.Y., Kautz, J., Chen, Y., Vah- dat, A.: Loss-guided diffusion models for plug-and-play controllable generation. In: International Conference on Machine Learning. pp. 32483–32498. PMLR (2023)
2023
-
[55]
In: Interna- tional Conference on Learning Representations (2021),https://openreview.net/ forum?id=PxTIG12RRHS
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: Interna- tional Conference on Learning Representations (2021),https://openreview.net/ forum?id=PxTIG12RRHS
2021
-
[56]
Spall, J.: Multivariate stochastic approximation using a simultaneous perturbation gradient approximation. IEEE Transactions on Automatic Control37(3), 332–341 (1992).https://doi.org/10.1109/9.119632
-
[57]
Estimation of the mean of a multivariate normal distribution,
Stein, C.M.: Estimation of the mean of a multivariate normal distribution. The An- nals of Statistics9(6), 1135–1151 (1981),http://www.jstor.org/stable/2240405
-
[58]
In: Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N
Tan, X., Wang, H., Geng, X., Zhou, P.: Sopo: Text-to-motion generation us- ing semi-online preference optimization. In: Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N. (eds.) Advances in Neural Information Processing Systems. vol. 38, pp. 60714–60747. Curran Associates, Inc. (2025),https://proceedings.neurips.cc/paper_fi...
2025
-
[59]
arXiv preprint arXiv:2501.16778 (2025)
Tashakori, A., Tashakori, A., Yang, G., Wang, Z.J., Servati, P.: Flexmotion: Lightweight, physics-aware, and controllable human motion generation. arXiv preprint arXiv:2501.16778 (2025)
-
[60]
Hui et al
Tevet, G., Raab, S., Cohan, S., Reda, D., Luo, Z., Peng, X.B., Bermano, A.H., van de Panne, M.: CLoSD: Closing the loop between simulation and diffu- 20 X. Hui et al. sion for multi-task character control. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= pZISppZSTv
2025
-
[61]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SJ1kSyO2jwu
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SJ1kSyO2jwu
2023
-
[62]
The Journal of Machine Learning Research11, 3137– 3181 (2010)
Theodorou, E., Buchli, J., Schaal, S.: A generalized path integral control approach to reinforcement learning. The Journal of Machine Learning Research11, 3137– 3181 (2010)
2010
-
[63]
In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 5026–5033 (2012).https://doi.org/10.1109/IROS.2012.6386109
-
[64]
In: Proceedings of the AAAI conference on artificial intelligence
Wang, Z., Yu, P., Zhao, Y., Zhang, R., Zhou, Y., Yuan, J., Chen, C.: Learning diverse stochastic human-action generators by learning smooth latent transitions. In: Proceedings of the AAAI conference on artificial intelligence. vol. 34, pp. 12281– 12288 (2020)
2020
-
[65]
arXiv preprint arXiv:2509.20927 (2025)
Watanabe, A., Ren, J., Siyao, L., Peng, Y., Wu, E., Simo-Serra, E.: Simdiff: Simulator-constrained diffusion model for physically plausible motion generation. arXiv preprint arXiv:2509.20927 (2025)
-
[66]
arXiv preprint arXiv:2512.23464 (2025)
Wen, Y., Shuai, Q., Kang, D., Li, J., Wen, C., Qian, Y., Jiao, N., Chen, C., Chen, W., Wang, Y., et al.: Hy-motion 1.0: Scaling flow matching models for text-to- motion generation. arXiv preprint arXiv:2512.23464 (2025)
-
[67]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Weng, W., Tan, X., Wang, J., Xie, G.S., Zhou, P., Wang, H.: Realign: text-to- motion generation via step-aware reward-guided alignment. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 10621–10629 (2026)
2026
-
[68]
Cambridge mathematical textbooks, Cambridge University Press (1991),https://books.google.co.uk/books?id= e9saZ0YSi-AC
Williams, D.: Probability with Martingales. Cambridge mathematical textbooks, Cambridge University Press (1991),https://books.google.co.uk/books?id= e9saZ0YSi-AC
1991
-
[69]
Machine learning8(3), 229–256 (1992)
Williams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning8(3), 229–256 (1992)
1992
-
[70]
In: The Twelfth International Conferenceon LearningRepresentations(2024),https://openreview.net/forum? id=gd0lAEtWso
Xie, Y., Jampani, V., Zhong, L., Sun, D., Jiang, H.: Omnicontrol: Control any joint at any time for human motion generation. In: The Twelfth International Conferenceon LearningRepresentations(2024),https://openreview.net/forum? id=gd0lAEtWso
2024
-
[71]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xu, L., Qu, H., Cai, Y., Liu, J.: 6d-diff: A keypoint diffusion framework for 6d object pose estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9676–9686 (2024)
2024
-
[72]
Yang,L.,Zhang,Z.,Song,Y.,Hong,S.,Xu,R.,Zhao,Y.,Zhang,W.,Cui,B.,Yang, M.H.: Diffusion models: A comprehensive survey of methods and applications. ACM Comput. Surv.56(4) (Nov 2023).https://doi.org/10.1145/3626235, https://doi.org/10.1145/3626235
-
[73]
Yin, T., Hoyet, L., Christie, M., Cani, M.P., Pettré, J.: The one-man-crowd: Single user generation of crowd motions using virtual reality. IEEE Transac- tions on Visualization and Computer Graphics28(5), 2245–2255 (2022).https: //doi.org/10.1109/TVCG.2022.3150507
-
[74]
Yong,J.,Zhou,X.Y.:Stochasticcontrols:HamiltoniansystemsandHJBequations, vol. 43. Springer Science & Business Media (1999)
1999
-
[75]
Yu, H., Liu, J., Gui, X., Wong, M., Hou, Y., Ong, Y.S.: A plug-and-play multi-criteria guidance for diverse in-betweening human motion generation. arXiv preprint arXiv:2508.01590 (2025) Controllable Motion Generation under Heterogeneous Constraints 21
-
[76]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Yuan, Y., Song, J., Iqbal, U., Vahdat, A., Kautz, J.: Physdiff: Physics-guided hu- man motion diffusion model. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 16010–16021 (2023)
2023
-
[77]
In: Proceedings of theIEEE/CVF conference on computer vision and pattern recognition
Zhang, J., Zhang, Y., Cun, X., Zhang, Y., Zhao, H., Lu, H., Shen, X., Shan, Y.: Generating human motion from textual descriptions with discrete representa- tions. In: Proceedings of theIEEE/CVF conference on computer vision and pattern recognition. pp. 14730–14740 (2023)
2023
-
[78]
IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024)
Zhang, M., Cai, Z., Pan, L., Hong, F., Guo, X., Yang, L., Liu, Z.: Motiondiffuse: Text-driven human motion generation with diffusion model. IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024)
2024
-
[79]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, R., Li, C., Lou, Y., Shi, Y., Wang, H., Huang, Y.: Steering where to dif- fuse: Generative modeling of phenotypic response simulation with steered diffusion bridge. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 27367–27377 (June 2026)
2026
-
[80]
In: The Thirteenth International Conference on Learning Represen- tations (2025),https://openreview.net/forum?id=HA0oLUvuGI
Zhang, S., Zhang, W., Gu, Q.: Energy-weighted flow matching for offline reinforce- ment learning. In: The Thirteenth International Conference on Learning Represen- tations (2025),https://openreview.net/forum?id=HA0oLUvuGI
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.