DRFLOW: A Deep Research Benchmark for Personalized Workflow Prediction
Pith reviewed 2026-06-27 00:43 UTC · model grok-4.3
The pith
DRFLOW shows that agents still fall short at turning scattered sources into correct personalized action-step sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
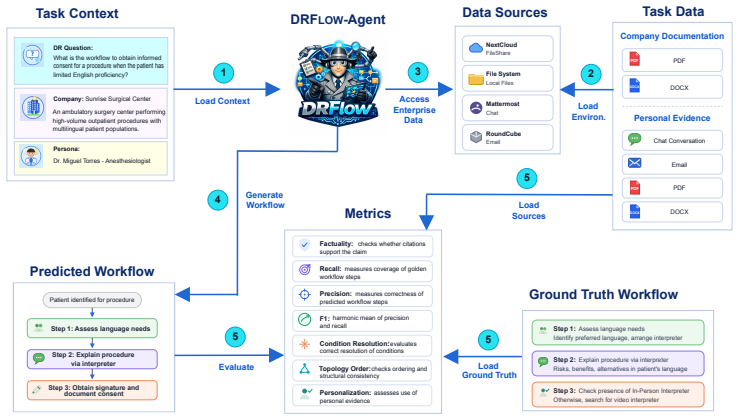
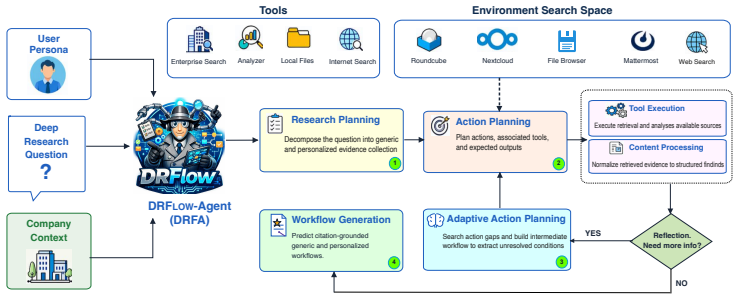
DRFLOW is presented as a benchmark in which each task requires an agent to identify relevant evidence from heterogeneous sources and then predict the correct personalized sequence of action steps. DRFA, the authors' workflow-oriented agent, improves over baselines by up to 10.02 percent average F1 score, yet substantial room for improvement remains across the workflow metrics, showing that predicting complete and correct personalized workflows remains a challenging frontier for deep research.
What carries the argument
The DRFLOW benchmark and its seven diagnostic metrics that separately score factual grounding, step recovery, structural ordering, condition resolution, and personalization when turning evidence into action-step sequences.
If this is right
- Agents must improve at pulling and combining evidence from many scattered sources.
- Workflow prediction requires explicit handling of ordering, conditions, and user-specific details.
- Future systems will need separate components for evidence search and step-sequence planning.
- Benchmarks focused only on report generation miss the concrete-action requirement of many tasks.
- Enterprise tools will remain limited until agents can output verifiable step lists rather than summaries.
Where Pith is reading between the lines
- The same evidence-to-sequence framing could be applied to other domains that need repeatable procedures, such as medical protocols or legal filings.
- Extending the benchmark to live, changing sources would test whether agents can adapt workflows when documents are updated.
- Success on DRFLOW might transfer to training agents that generate executable scripts or checklists for users.
- The gap between current agents and perfect scores suggests that hybrid search-plus-planning architectures will be needed.
Load-bearing premise
The 100 tasks and seven metrics are enough to capture the real difficulties of identifying evidence and predicting personalized workflows in enterprise settings.
What would settle it
A new agent that scores above 90 percent on every one of the seven metrics while recovering every reference step on all 100 tasks would show the frontier is no longer challenging.
Figures

read the original abstract
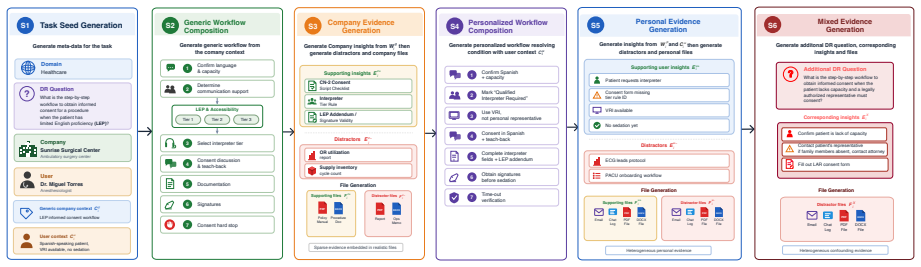
Deep research (DR) systems are increasingly used for complex information-seeking tasks, but existing works mainly focus on generating reports and summaries. In contrast, many enterprise tasks instead require an agent to identify concrete workflows which is a sequence of action-steps. For example, rather than summarizing budgeting policies, an agent should be able to determine the steps needed to answer a question such as: "How do I request new headcount given a fixed budget?". Therefore, we introduce DRFLOW, a benchmark for evaluating personalized workflows predicted by agents from heterogeneous sources. Each task requires the agent to identify relevant evidence from scattered sources, then use that evidence to predict the correct action-step sequence for the user's task. DRFLOW contains 100 tasks across five domains, with 1,246 reference workflow steps grounded in more than 3,900 sources. We define seven diagnostic metrics covering factual grounding, step recovery, structural ordering, condition resolution, and personalization. We further present DRFLOW-Agent (DRFA), a workflow-oriented reference agent to predict personalized workflow. We show that although DRFA improves over strong baseline agents (upto 10.02% average F1 score), there is substantial room for improvement remains across these workflow metrics, indicating that predicting complete and correct personalized workflows remains a challenging frontier for deep research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DRFLOW, a benchmark for personalized workflow prediction in deep research systems. It consists of 100 tasks across five domains, containing 1,246 reference workflow steps grounded in more than 3,900 sources. Seven diagnostic metrics are defined to evaluate factual grounding, step recovery, structural ordering, condition resolution, and personalization. The authors present DRFA, a workflow-oriented agent, which improves over strong baseline agents by up to 10.02% average F1 score, while concluding that substantial room for improvement remains and that predicting complete personalized workflows is a challenging frontier.
Significance. If the task construction and metric definitions hold, the benchmark shifts evaluation from report generation toward actionable, evidence-grounded workflow sequences in enterprise settings. The modest empirical gains with DRFA provide a concrete existence proof of headroom, which could usefully direct future agent research.
major comments (2)
- [Abstract] Abstract: the central claim that the 100 tasks, 1,246 steps, and >3,900 sources 'sufficiently capture the real challenges' of identifying evidence and predicting personalized action-step sequences is load-bearing for the 'challenging frontier' conclusion, yet the manuscript provides no description of task construction, inter-annotator validation of the reference steps, or how the seven metrics were derived from the data.
- [Abstract] Abstract: the reported 10.02% average F1 improvement is presented as evidence of both progress and remaining gaps, but without the specific baselines, per-metric breakdowns, or statistical significance tests, it is impossible to verify whether the improvement is robust or whether the 'substantial room for improvement' claim follows from the numbers.
minor comments (1)
- [Abstract] Abstract: the sentence 'there is substantial room for improvement remains across these workflow metrics' contains a grammatical error and should be rephrased for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The two major comments correctly identify areas where the abstract is too terse and where additional transparency on construction and results would strengthen the paper. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the 100 tasks, 1,246 steps, and >3,900 sources 'sufficiently capture the real challenges' of identifying evidence and predicting personalized action-step sequences is load-bearing for the 'challenging frontier' conclusion, yet the manuscript provides no description of task construction, inter-annotator validation of the reference steps, or how the seven metrics were derived from the data.
Authors: We agree the abstract does not contain these details. Section 3 of the manuscript describes task construction (enterprise scenarios collected from five domains, reference steps extracted and grounded from >3900 sources) and reports inter-annotator agreement (Cohen’s κ = 0.81 across three annotators). Section 4 explains the derivation of the seven metrics from observed failure modes in workflow prediction. To make this information immediately accessible, we will add a short paragraph summarizing construction and validation to the abstract and will expand the methods section with additional examples of the annotation protocol. revision: yes
-
Referee: [Abstract] Abstract: the reported 10.02% average F1 improvement is presented as evidence of both progress and remaining gaps, but without the specific baselines, per-metric breakdowns, or statistical significance tests, it is impossible to verify whether the improvement is robust or whether the 'substantial room for improvement' claim follows from the numbers.
Authors: The results section (Table 2) already lists the exact baselines (ReAct, Reflexion, Plan-and-Execute, and two retrieval-augmented variants), reports per-metric F1 scores, and shows the 10.02% average improvement. We will add paired t-test p-values for all comparisons and will include a one-sentence summary of the per-metric gains in the abstract. These additions will allow readers to assess both the robustness of the gains and the remaining headroom directly from the abstract. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a benchmark (DRFLOW) and a reference agent (DRFA) with purely empirical comparisons to baselines on 100 tasks and seven metrics. No equations, derivations, fitted parameters, or self-citation chains are present that reduce any claim to its own inputs by construction. The central claim (room for improvement remains) follows directly from the reported F1 gains without any definitional or predictive circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Enabling large language models to generate text with citations. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 6465–6488, Singapore. Associa- tion for Computational Linguistics. Boyu Gou, Zanming Huang, Yuting Ning, Yu Gu, Michael Lin, Weijian Qi, Andrei Kopanev, Botao Yu, Bernal Jimenez Gutierrez, Yiheng...
-
[2]
arXiv preprint arXiv:2402.05930 , year=
Agentbench: Evaluating LLMs as agents. In The Twelfth International Conference on Learning Representations. Xing Han Lù, Zden ˇek Kasner, and Siva Reddy. 2024. Weblinx: Real-world website navigation with multi- turn dialogue.Preprint, arXiv:2402.05930. Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. GAIA: a benchma...
-
[3]
Plan and request a qual- ified interpreter (choose tier/mode)
that support the similar claim. G Qualitative Analysis G.1 Condition-aware personalization. With GPT-5.2 fixed we conduct qualitative analy- sis on the condition-aware personalization quality of agents. The comparison between the DRBA and DRFA on healthcare_01 task shows that DRFA improves on both Condition Resolution (58.33 to 75.00) and Personalized Com...
1928
-
[4]
There are 10 tabs, each for one task
-
[5]
Gold step id, task title, task description ii
Each tab contains the following: i. Gold step id, task title, task description ii. Title and task description for two models (model_1, model_2)
-
[6]
-For example, if you think the 4th step of the model_1 matches the 3rd gold step, you should assign 3 in the 4th step label of ‘model_1’
Your task is to assign gold step id numbers for the predicted steps by the models. -For example, if you think the 4th step of the model_1 matches the 3rd gold step, you should assign 3 in the 4th step label of ‘model_1’. Similar process for model_2 as well. Note:
-
[7]
If you think a predicted step does not match any of the gold step id, keep the label blank for that step
-
[8]
Try to check whether the action of the predicted step matches the action of the gold step
The matches do not have to be exact. Try to check whether the action of the predicted step matches the action of the gold step
-
[9]
Deletion Will Be Sent to MindMint’s Service Providers and Vendors
Do not assign the same gold step id for two different steps for the same model. -For example, do not assign 5 for in the two step labels of ‘model_2’. Figure F.1: Human evaluation guideline. healthcare_01 healthcare_04 b2c_06 b2c_10 b2b_04 b2b_10 education_04 education_10 legal_02 legal_04 Task ID 0.0 0.2 0.4 0.6 0.8 1.0F1 Score DRFA human avg. F1 DRFA LL...
2026
-
[10]
Create a COMPREHENSIVE research plan covering both generic workflow and user evidence
-
[11]
Drive action planning so it properly covers ALL items in the generic workflow (policy steps, conditional branches, prerequisites)
-
[12]
Drive action planning to collect necessary user/personal evidence to resolve conditional branches where possible
-
[13]
survey window
Produce both a generic workflow and a personalized workflow, each with detailed task descriptions under every to-do; conditional branches resolved by user evidence must be presented as resolved in the personalized workflow. Your plan MUST follow these 4 stages: ### STAGE 1: REQUIREMENT_COLLECTION (CRITICAL - EXTRACT FULL WORKFLOWS) **Goal**: Find INTERNAL...
-
[14]
Do NOT suggest queries that overlap >50% in keywords with any already-used query above
-
[15]
people, dates, specific systems, regulatory bodies, incident IDs) - not just rephrase the topic
Each new action MUST explore a DIFFERENT evidence dimension (e.g. people, dates, specific systems, regulatory bodies, incident IDs) - not just rephrase the topic
-
[16]
If REQUIREMENT_COLLECTION already has 7+ actions, do NOT add more for that stage
-
[17]
If PERSONAL_EVIDENCE_COLLECTION already has 7+ actions, do NOT add more for that stage
-
[18]
type": "local_document_search
If both policy documents AND personal evidence are found, return []. Available Tools: {available_tool_names} Return a JSON array (0-2 actions). Return [] if no genuine gaps exist: [ {{ "type": "local_document_search", "description": "A genuinely different search angle not covered above", "parameters": {{"query": "novel keywords not used before", "top_k": ...
-
[19]
**SAME NUMBER OF STEPS** as generic workflow
-
[20]
**PERSONALIZE task/task_description** with user's specific facts (dates, names, numbers, entities)
-
[21]
If the condition is NOT resolved by evidence, keep the conditional text in subtask_description so the user sees both branches
**Conditional branches**: If a condition in the generic workflow is RESOLVED by user's personal evidence, present the personalized workflow accordingly: use the single resolved path in the step title/task and leave subtask_description EMPTY. If the condition is NOT resolved by evidence, keep the conditional text in subtask_description so the user sees bot...
-
[22]
**subtask_description**: - EMPTY ("") when user evidence resolves which path to take (condition is Resolved in table) - KEEP conditional text when evidence does NOT determine the path (condition is Unresolved)
-
[23]
[ ] Action detail [DOC:src_N]
**justification**: - Explain why this step belongs in the personalized workflow, not just what to do - Reference user's SPECIFIC facts that determine the applicable path - If the step is unconditional, explain what policy or user circumstance still makes it necessary - MUST cite both policy and personal evidence using [DOC:src_N] ### CITATION REQUIREMENTS...
-
[24]
If you have fewer than 10, you are merging steps; if you have more than 15, consolidate only where actions are truly atomic together
Generate **10-15 DETAILED steps** in generic workflow - extract EVERY distinct procedural step from policy documents. If you have fewer than 10, you are merging steps; if you have more than 15, consolidate only where actions are truly atomic together
-
[25]
For each step that has an if/then/else or decision or conditional in the policy, you MUST put that COMPLETE condition text in subtask_description with ALL branches listed
-
[26]
Condition Resolution Table: one row per conditional step, search ALL user evidence to resolve conditions
-
[27]
Personalized workflow has IDENTICAL number of steps as generic (10-15)
-
[28]
Personalize task/task_description with USER'S SPECIFIC FACTS (actual names, counts, systems, dates, constraints from evidence)
-
[29]
subtask_description in personalized: EMPTY when resolved by user evidence, KEEP condition text when NOT resolved
-
[30]
Every justification must reference specific user facts with citations
-
[31]
In the PERSONALIZED WORKFLOW (Section 2): every step's task, task_description, and justification MUST contain at least one [DOC:src_N]
**CITATIONS (MANDATORY)**: Use [DOC:src_N] format. In the PERSONALIZED WORKFLOW (Section 2): every step's task, task_description, and justification MUST contain at least one [DOC:src_N]. In Section 3 (Step-by-Step Guidance): every step's Description and at least one Action Item per step MUST contain [DOC:src_N]. Only use source IDs from the AVAILABLE SOUR...
-
[32]
Each question should be **simple to understand** and clearly ask about **what workflow or steps need to be taken** to accomplish a goal or resolve an issue
-
[33]
Questions should be realistic, actionable, and require multi-step research or analysis to answer
-
[34]
including A, B, C
Each question should be at most 10-15 words, in plain English, easy to understand for non-technical people and without any leading phrases (e.g., "including A, B, C") and end with a question mark
-
[35]
What steps do I need to follow to ...?
Questions should focus on understanding a process, procedure, or sequence of actions - e.g., "What steps do I need to follow to ...?", "What is the workflow for ...?", "What exact steps should I take to ...?"
-
[36]
Questions should not be ambiguous and should lead to concrete, step-by-step answers
-
[37]
What workflow should we follow to evaluate a positive blood culture, choose empiric antibiotics, de- escalate therapy, and document stewardship decisions?
Do not combine multiple processes or procedures (E.g., do not ask questions like"What workflow should we follow to evaluate a positive blood culture, choose empiric antibiotics, de- escalate therapy, and document stewardship decisions?") into a single question. Keep it simple and focused
-
[38]
Do not make it complex and long
The questions should be in the simple sentence. Do not make it complex and long
-
[39]
Make questions diverse (different sub-areas or angles within the domain) rather than repetitive
-
[40]
dr_questions
Make the questions from each domain unique, creative, and realistic. ### Guidelines for company and user metadata: - For each question, generate realistic company and user information that fits the domain and the question scenario. - The company and user should be contextually appropriate for the question being asked. - Company persona represents a point ...
-
[42]
Be concise and do not itemize the task description
A detailed low-level description of how to perform the task (e.g., fill out name, address of form X, ignore section B, etc). Be concise and do not itemize the task description
-
[43]
If there are no conditional branches, leave this field empty
Any subtask descriptions or conditional branches (e.g., if P happens submit A, if Q happens go to B, etc). If there are no conditional branches, leave this field empty
-
[44]
If none, keep empty
Which item is a prerequisite for this item. If none, keep empty
-
[45]
If none, keep empty
A detailed low-level description of the prerequisite (e.g., user needs to collect the confirmation number from page X, user needs to submit form Y first before doing this item). If none, keep empty
-
[46]
This implies that the previous item is a prerequisite for the current item
For determining the prerequisite, you may look for the clues like 'after that','then', etc. This implies that the previous item is a prerequisite for the current item. Remember, - The steps should be in the order of the generic context. - Number of steps should be equal to the number of steps in the generic context. - You do not need to create separate st...
-
[47]
The specific task to be performed
-
[48]
A detailed low-level description of the task
-
[49]
If none, keep empty
Any subtask descriptions or conditional branches. If none, keep empty. Return the output as a JSON object with a'steps'key containing an array of items following the format specified. Figure K.4: Prompt for company distractor generation. User Support-Evidence Generation Prompt You are an expert QA analyst. Your task is to analyze the user's personal conte...
-
[50]
Do not summarize or rephrase the answer; it must be a verbatim extraction
The'answer'for each pair MUST be extracted from the context and must be an exact statement or event directly present in the given User Context. Do not summarize or rephrase the answer; it must be a verbatim extraction
-
[51]
The'question'should be formulated such that the extracted' answer'provides a direct response to it
-
[52]
You may synthesize this justification, but keep it realistic and professional
The'justification'should explain why this event is relevant to the user's situation or the DR question. You may synthesize this justification, but keep it realistic and professional
-
[53]
Do not miss any single sentence from the context
You must cover the entire context within the {n_supports} question-answering-justification pairs. Do not miss any single sentence from the context
-
[54]
You must generate exactly {n_supports} question-answering- justification pairs
-
[55]
If necessary, you can merge multiple questions to cover the entire context within the {n_supports} question-answering- justification pairs
-
[56]
Do not miss any single point/information from the context
Remember, You MUST COVER every points/information of the context within the {n_supports} question-answering-justification pairs . Do not miss any single point/information from the context. Return the output as a JSON object with an'items'key containing an array of events following the format specified. Figure K.5: Prompt for user support-evidence genera- ...
-
[57]
If X, then do Y; else do Z
**Resolve Conditional Paths**: The Generic Insights often contain conditional branches (e.g., "If X, then do Y; else do Z"). Use the provided User Context to determine which path the user should take. If resolved, the'subtask_description'will be empty. If information to resolve conditional path does not exist in the provided user insights, keep the'subtas...
-
[58]
**Personalize Instructions**: Adapt the'task','task_description'to be specific to the user's situation where possible. For example, if there are multiple conditions and only one of them is applicable for the user, then you should modify the'task'and 'task_description'to clearly define which path the user should take to make it more personalized. ,→,→,→,→
-
[59]
**Justify Applicability**: For each step, provide a'justification'that explains why this step is relevant to the user, citing specific facts from the User Insights.,→
-
[60]
**Maintain Structure**: Keep the same sequence and logical flow as the Generic Insights, but remove irrelevant conditional branches.,→
-
[61]
**Preserve Required Detail**: Every step must include a non-empty'task_description'and non-empty'justification'. Keep'prerequisite'and'prerequisite_description'populated whenever they exist in the Generic Insights unless you are intentionally updating them to a more specific user-resolved version. Only leave'subtask_description'empty when the Generic Insi...
-
[62]
item": 1,
**Format**: Return the output as a JSON object with a'steps'key containing an array of UserWorkflowItem objects.,→ Return ONLY a valid JSON object. ### Example Workflow: DR Question: I'm the privacy/compliance lead at a multi-site hospital network and we just detected a potential PHI exposure involving a vendor-connected patient portal. I need a step-by-s...
-
[63]
Same workflow domain / industry as the target (same business processes, terminology, stakeholders)
-
[64]
Do NOT generate a re-phrasing of the target
DIFFERENT scenario, case, or sub-process. Do NOT generate a re-phrasing of the target
-
[65]
Should NOT be answered by ANY of the existing target user_insights below — the adjacent DR pertains to a different case, so its facts are different
-
[66]
Realistic — something a worker in this role might actually need to look up in this organization's knowledge base
-
[67]
What is the workflow when a patient withdraws consent at the last minute before anesthesia?
Concise: a single workflow-oriented question, 12–25 words. Examples of good adjacency (for a healthcare informed-consent / LEP target): - "What is the workflow when a patient withdraws consent at the last minute before anesthesia?" - "What to do when an emergency surgery patient does not have current insurance verification?" Both share the consent/periope...
2026
-
[68]
All key factual details (numbers, dates, names, percentages, specific facts) must be present in at least one source
-
[69]
The main substance and meaning of the claim must be supported by the source contexts
-
[70]
Company ABC reported $50M revenue in Q3 2023
No part of the claim should contradict the information in any of the sources ACCEPTABLE variations: - Different wording or phrasing that conveys the same meaning - Paraphrasing or summarization of the source information - Minor linguistic differences that don't change the factual content Mark as FALSE if: - Important factual details are missing, incorrect...
2023
-
[71]
**Score 1.0 (Fully Resolved)**: The predicted step correctly resolves the conditions by: - Choosing the appropriate condition path for the user's situation - Providing specific justification or evidence for the chosen path - Not just listing all possible conditions, but actually routing through one
-
[72]
**Score 0.5 (Partially Resolved)**: The predicted step mentions the conditions but: - Lists multiple possible paths without clearly choosing one - Mentions the correct path but lacks specific justification - Shows awareness of conditions but doesn't fully personalize the resolution
-
[73]
score": <0.0, 0.5, or 1.0>,
**Score 0.0 (Unresolved)**: The predicted step: - Does not address the conditions at all - Only provides generic description without condition awareness - Completely ignores the conditional routing Return ONLY a valid JSON object (no other text): {{ "score": <0.0, 0.5, or 1.0>, "level": "<resolved, partially_resolved, or unresolved>", "justification": "<d...
-
[74]
**Specificity** (0.0-1.0): Compared to the golden step answer, does the predicted description mention specific names, form numbers, data categories, institutions, study types, procedures, thresholds, and other concrete details from the golden answer? Or is it vague and generic?
-
[75]
**Personalization** (0.0-1.0): Compared to the golden step answer, is the description tailored to the user's specific situation (e.g., mentioning the specific study type, specific forms, specific data categories, specific numbers, specific PI or coordinator)? Or could it apply to many generic situations?
-
[76]
**Completeness** (0.0-1.0): Compared to the golden step answer, does the description cover the key action items and important details from the golden answer? Are major steps, conditions, branches, approvals, or required artifacts missing?
-
[77]
specificity
**Actionability** (0.0-1.0): Compared to the golden step answer, does the description provide clear, actionable instructions that a user could follow? Or is it too high-level to be useful? Scoring guidance: - Reserve 0.90-1.00 for near-complete, highly specific, clearly personalized steps with very few meaningful omissions. - Use 0.70-0.89 for good steps ...
2019
-
[78]
Qualified Interpreter Required
Verify consistency with FOP-1 and the offer, then save for routing. Step 4 · Route PDF-7 with Provost approval Attach the completed PDF-7 in the routing tool and confirm key fields match the offer. Because the appointment is tenure-track, include the Provost approval step in addition to dean and HR. Submit and log the workflow ID and current approver in t...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.