Beyond the Golden Teacher: Enhancing Graph Learning through LLM-GNN Co-teaching
Pith reviewed 2026-06-27 10:30 UTC · model grok-4.3
The pith
Abandoning the golden-teacher assumption through bidirectional LLM-GNN co-teaching improves few-shot graph learning on text-attributed graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
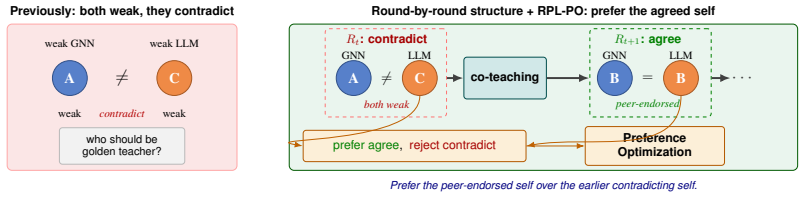
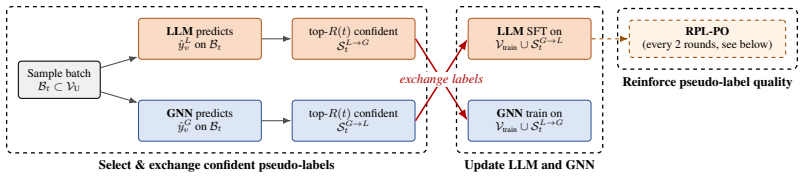
The central claim is that the golden-teacher assumption breaks under sparse supervision, and a bidirectional co-teaching framework where GNN and LLM exchange confident pseudo-labels, combined with Round-based Pseudo-Label Preference Optimization (RPL-PO) from cross-model agreement trajectories, enables effective graph learning and substantially improves the LLM's capability on challenging samples.
What carries the argument
The LLM-GNN Co-Teaching framework with RPL-PO, where pseudo-labels are exchanged based on architecture-specific small-loss and preference pairs are mined from contradiction-to-agreement transitions for DPO training.
Load-bearing premise
The small-loss criterion reliably identifies confident pseudo-labels under sparse supervision and the cross-model agreement trajectory produces valid preference pairs that improve the LLM without introducing new errors.
What would settle it
A result showing that the co-teaching method fails to improve or worsens performance on nodes that start with model disagreement would challenge the effectiveness of RPL-PO.
Figures


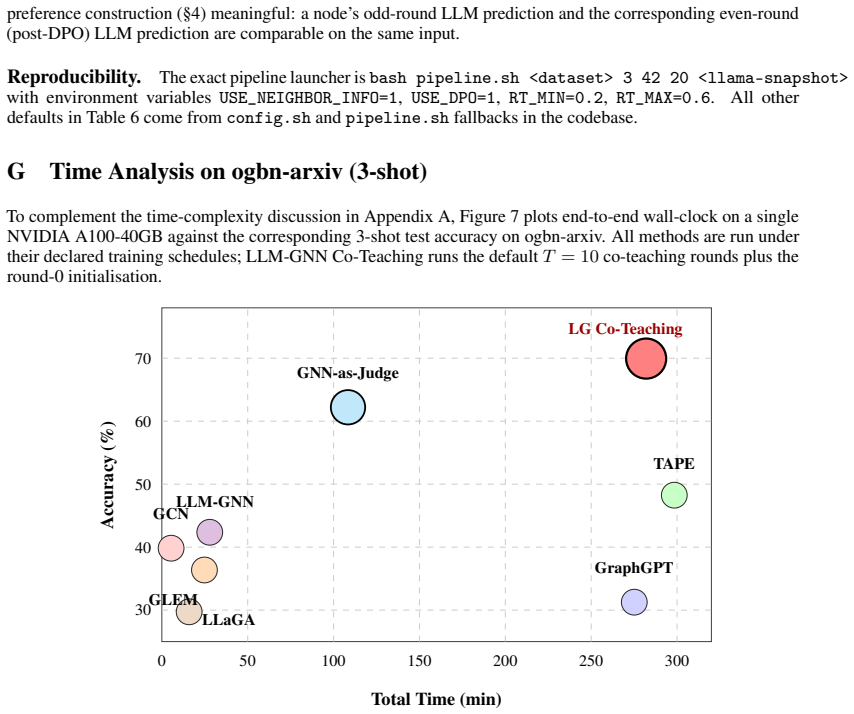
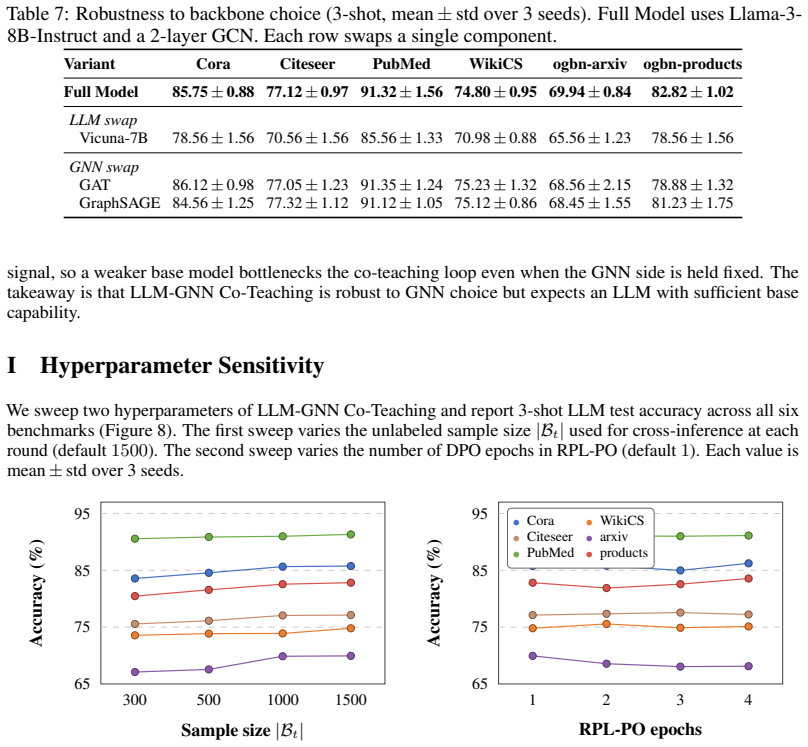
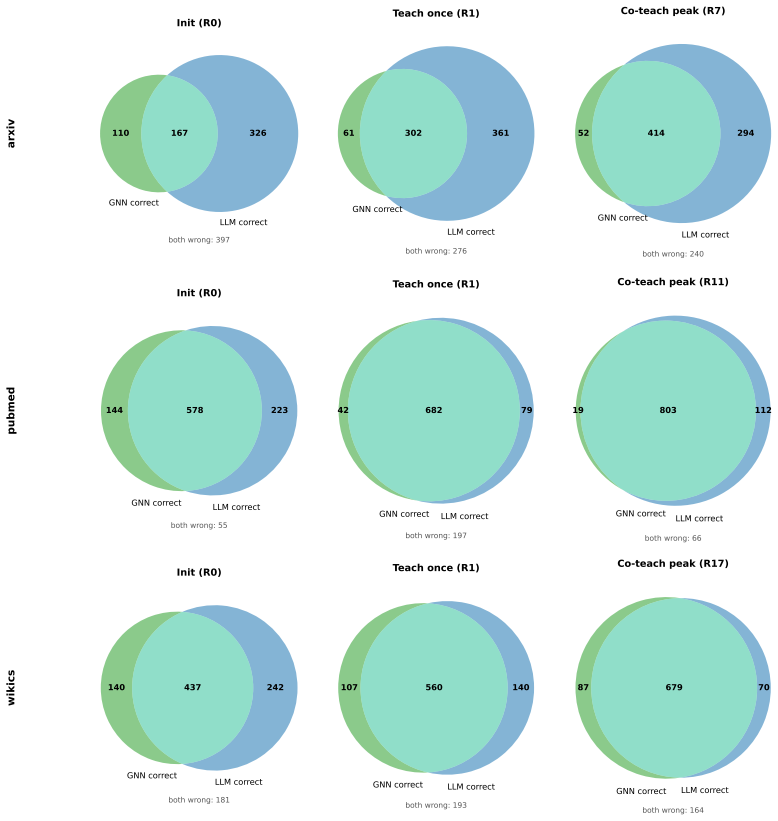
read the original abstract
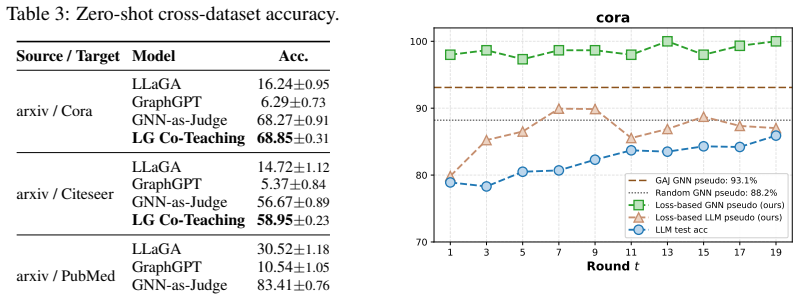
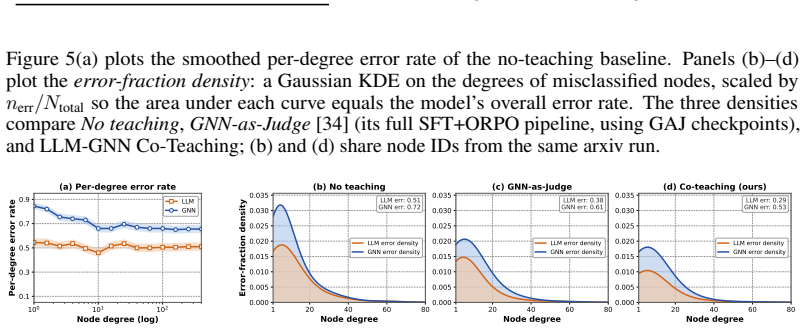
Text-attributed graphs (TAGs) underlie real-world applications such as citation networks, social media, and e-commerce. Few-shot graph learning on TAGs is hard: with only a handful of labels per class and the rest of the graph unannotated, neither GNNs nor LLMs can learn well on their own. GNNs read topology and fail on cold nodes; LLMs read text and fail on text-ambiguous nodes. Existing LLM-GNN methods all follow the same recipe: designate one model as the golden teacher and use its outputs (e.g., features or pseudo-labels) to supervise the other. We argue this golden-teacher assumption breaks under sparse supervision: neither model is golden, and treating either as such transfers its blind spots into the student. We therefore ask: can we avoid designating either model as the golden teacher, and still perform effective graph learning? We answer with LLM-GNN Co-Teaching, a bidirectional co-teaching framework in which neither model is fixed as teacher. The GNN and LLM exchange their most confident pseudo-labels under an architecture-specific small-loss criterion, and both update every round. Supervision is then mined from the trajectory: whenever a node moves from cross-model contradiction at round t to cross-model agreement at round t+1, the LLM's two answers on the same input form a preference pair (old contradicting self < new peer-endorsed self) for DPO training. We call this Round-based Pseudo-Label Preference Optimization (RPL-PO). On six benchmarks, LLM-GNN Co-Teaching consistently outperforms GNN-as-Judge and all prior methods, with absolute 3-shot gains of 7.86% on Cora and 7.73% on ogbn-arxiv; improvements carry over to 5-shot and to zero-shot cross-dataset transfer. Error-structure analysis further shows that abandoning the golden-teacher assumption substantially improves the LLM's graph learning capability on challenging samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LLM-GNN Co-Teaching, a bidirectional framework in which the GNN and LLM exchange their most confident pseudo-labels under an architecture-specific small-loss criterion (with both models updating every round) and mine supervision from agreement trajectories via Round-based Pseudo-Label Preference Optimization (RPL-PO) for DPO training; it reports absolute 3-shot gains of 7.86% on Cora and 7.73% on ogbn-arxiv over golden-teacher baselines, with gains persisting in 5-shot and zero-shot transfer settings, plus error-structure analysis showing improved LLM performance on challenging samples.
Significance. If the empirical results and underlying assumptions hold after verification, the work is significant for demonstrating that abandoning the golden-teacher assumption can yield mutual gains in sparse-supervision TAG learning; the multi-benchmark evaluation and explicit error-structure analysis constitute strengths that allow assessment of where the co-teaching helps most.
major comments (2)
- [Methods (small-loss criterion)] Methods section (small-loss criterion and pseudo-label exchange): the central claim that architecture-specific small-loss reliably surfaces high-accuracy pseudo-labels rather than over-confident errors is load-bearing, yet the manuscript provides no quantitative check (e.g., accuracy of selected labels versus random or baseline on held-out nodes) under the 3-shot regime where both models begin with high error rates; without this, reported gains could reflect error reinforcement rather than genuine improvement.
- [RPL-PO (trajectory-to-preference mapping)] RPL-PO construction (trajectory-to-preference mapping): the assumption that a node moving from cross-model disagreement at round t to agreement at t+1 yields a valid DPO preference pair (old contradicting answer < new peer-endorsed answer) is load-bearing for the LLM optimization claim, but shared text or topology biases could cause convergence on the same incorrect label; the manuscript must demonstrate that agreement trajectories correlate with ground-truth correctness on held-out data to support that the preference pairs are not training toward errors.
minor comments (2)
- [Abstract] Abstract: absolute gains are stated without accompanying error bars, number of runs, or statistical significance tests; adding these would strengthen the presentation of the empirical results.
- [Methods] Notation for the small-loss threshold and preference-pair construction should be made fully explicit with equations to allow reproduction and to clarify any dependence on model outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the small-loss criterion and RPL-PO. The comments highlight important aspects of the empirical validation. We address each point below and will incorporate additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Methods (small-loss criterion)] Methods section (small-loss criterion and pseudo-label exchange): the central claim that architecture-specific small-loss reliably surfaces high-accuracy pseudo-labels rather than over-confident errors is load-bearing, yet the manuscript provides no quantitative check (e.g., accuracy of selected labels versus random or baseline on held-out nodes) under the 3-shot regime where both models begin with high error rates; without this, reported gains could reflect error reinforcement rather than genuine improvement.
Authors: We agree that a direct quantitative check on the accuracy of pseudo-labels selected by the architecture-specific small-loss criterion (versus random or baseline selection) on held-out nodes would strengthen the central claim, particularly in the 3-shot regime. While the reported absolute gains (e.g., 7.86% on Cora) and the error-structure analysis already indicate that co-teaching improves performance on challenging samples rather than simply reinforcing errors, we will add this explicit validation experiment to the revised manuscript. revision: yes
-
Referee: [RPL-PO (trajectory-to-preference mapping)] RPL-PO construction (trajectory-to-preference mapping): the assumption that a node moving from cross-model disagreement at round t to agreement at t+1 yields a valid DPO preference pair (old contradicting answer < new peer-endorsed answer) is load-bearing for the LLM optimization claim, but shared text or topology biases could cause convergence on the same incorrect label; the manuscript must demonstrate that agreement trajectories correlate with ground-truth correctness on held-out data to support that the preference pairs are not training toward errors.
Authors: We acknowledge that demonstrating the correlation between agreement trajectories and ground-truth correctness on held-out data would directly support the validity of the RPL-PO preference pairs. The current results rely on consistent outperformance across benchmarks and the observed LLM improvements on challenging samples to indicate that the optimization is effective. To address the concern explicitly, we will include an additional analysis in the revision measuring the precision of agreement trajectories against ground-truth labels on held-out nodes. revision: yes
Circularity Check
No circularity: empirical method with no self-referential derivation or fitted-input predictions
full rationale
The paper presents an algorithmic framework (bidirectional co-teaching + RPL-PO) whose performance claims are empirical gains on benchmarks. The abstract and described method define small-loss selection and preference-pair construction as procedural steps operating on model outputs, but no equations, derivations, or self-citations are exhibited that reduce the reported accuracy improvements to those same outputs by construction. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear. The central claim therefore remains an independent empirical assertion rather than a tautological reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
RPL-PO (Round-based Pseudo-Label Preference Optimization)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
2020
-
[2]
Revisiting semi-supervised learning with graph embeddings
Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. InInternational conference on machine learning, pages 40–48. PMLR, 2016
2016
-
[3]
Collective classification in network data.AI magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data.AI magazine, 29(3):93–93, 2008
2008
-
[4]
Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Perold, Yann LeCun, and Bryan Hooi. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning.arXiv preprint arXiv:2305.19523, 2023
-
[5]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[6]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Zhikai Chen, Haitao Mao, Hongzhi Wen, Haoyu Han, Wei Jin, Haiyang Zhang, Hui Liu, and Jiliang Tang. Label-free node classification on graphs with large language models (llms).arXiv preprint arXiv:2310.04668, 2023
-
[9]
Graphgpt: Graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 491–500, 2024
2024
-
[10]
Language is all a graph needs
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Language is all a graph needs. InFindings of the association for computational linguistics: EACL 2024, pages 1955–1973, 2024
2024
-
[11]
Llaga: Large language and graph assistant,
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. Llaga: Large language and graph assistant.arXiv preprint arXiv:2402.08170, 2024
-
[12]
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks.arXiv preprint arXiv:2310.00149, 2023
-
[13]
Jianan Zhao, Meng Qu, Chaozhuo Li, Hao Yan, Qian Liu, Rui Li, Xing Xie, and Jian Tang. Learning on large-scale text-attributed graphs via variational inference.arXiv preprint arXiv:2210.14709, 2022
-
[14]
Instructgraph: Boosting large language models via graph-centric instruction tuning and preference alignment
Jianing Wang, Junda Wu, Yupeng Hou, Yao Liu, Ming Gao, and Julian McAuley. Instructgraph: Boosting large language models via graph-centric instruction tuning and preference alignment. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13492–13510, 2024
2024
-
[15]
Graph prototypical networks for few-shot learning on attributed networks
Kaize Ding, Jianling Wang, Jundong Li, Kai Shu, Chenghao Liu, and Huan Liu. Graph prototypical networks for few-shot learning on attributed networks. InProceedings of the 29th ACM international conference on information & knowledge management, pages 295–304, 2020
2020
-
[16]
Meta propagation networks for graph few-shot semi-supervised learning
Kaize Ding, Jianling Wang, James Caverlee, and Huan Liu. Meta propagation networks for graph few-shot semi-supervised learning. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 6524–6531, 2022
2022
-
[17]
Graph few-shot learning with task-specific structures.Advances in Neural Information Processing Systems, 35:38925–38936, 2022
Song Wang, Chen Chen, and Jundong Li. Graph few-shot learning with task-specific structures.Advances in Neural Information Processing Systems, 35:38925–38936, 2022
2022
-
[18]
Graph meta learning via local subgraphs.Advances in neural information processing systems, 33:5862–5874, 2020
Kexin Huang and Marinka Zitnik. Graph meta learning via local subgraphs.Advances in neural information processing systems, 33:5862–5874, 2020
2020
-
[19]
Multi-stage self-supervised learning for graph convolutional networks on graphs with few labeled nodes
Ke Sun, Zhouchen Lin, and Zhanxing Zhu. Multi-stage self-supervised learning for graph convolutional networks on graphs with few labeled nodes. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 5892–5899, 2020. 10
2020
-
[20]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Simplifying graph convolutional networks
Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. InInternational conference on machine learning, pages 6861–6871. Pmlr, 2019
2019
-
[22]
Johannes Gasteiger, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank.arXiv preprint arXiv:1810.05997, 2018
-
[23]
Representation learning on graphs with jumping knowledge networks
Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. InInternational conference on machine learning, pages 5453–5462. pmlr, 2018
2018
-
[24]
Deeper insights into graph convolutional networks for semi-supervised learning
Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[25]
Beyond homophily in graph neural networks: Current limitations and effective designs.Advances in neural information processing systems, 33:7793–7804, 2020
Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs.Advances in neural information processing systems, 33:7793–7804, 2020
2020
-
[26]
Jin Huang, Xingjian Zhang, Qiaozhu Mei, and Jiaqi Ma. Can llms effectively leverage graph structural information through prompts, and why?arXiv preprint arXiv:2309.16595, 2023
-
[27]
When do llms help with node clas- sification? a comprehensive analysis,
Xixi Wu, Yifei Shen, Fangzhou Ge, Caihua Shan, Yizhu Jiao, Xiangguo Sun, and Hong Cheng. When do llms help with node classification? a comprehensive analysis.arXiv preprint arXiv:2502.00829, 2025
-
[28]
How do large language models understand graph patterns? a benchmark for graph pattern comprehension
Xinnan Dai, Haohao Qu, Yifei Shen, Bohang Zhang, Qihao Wen, Wenqi Fan, Dongsheng Li, Jiliang Tang, and Caihua Shan. How do large language models understand graph patterns? a benchmark for graph pattern comprehension. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[29]
Jiayan Guo, Lun Du, Hengyu Liu, Mengyu Zhou, Xinyi He, and Shi Han. Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking.arXiv preprint arXiv:2305.15066, 2023
-
[30]
Grenade: Graph-centric language model for self-supervised representation learning on text-attributed graphs
Yichuan Li, Kaize Ding, and Kyumin Lee. Grenade: Graph-centric language model for self-supervised representation learning on text-attributed graphs. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 2745–2757, 2023
2023
-
[31]
Graphformers: Gnn-nested transformers for representation learning on textual graph
Junhan Yang, Zheng Liu, Shitao Xiao, Chaozhuo Li, Defu Lian, Sanjay Agrawal, Amit Singh, Guangzhong Sun, and Xing Xie. Graphformers: Gnn-nested transformers for representation learning on textual graph. Advances in Neural Information Processing Systems, 34:28798–28810, 2021
2021
-
[32]
Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37: 5950–5973, 2024
Duo Wang, Yuan Zuo, Fengzhi Li, and Junjie Wu. Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37: 5950–5973, 2024
2024
-
[33]
Let’s ask gnn: Empowering large language model for graph in-context learning
Zhengyu Hu, Yichuan Li, Zhengyu Chen, Jingang Wang, Han Liu, Kyumin Lee, and Kaize Ding. Let’s ask gnn: Empowering large language model for graph in-context learning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1396–1409, 2024
2024
-
[34]
GNN-as-Judge: Unleashing the Power of LLMs for Graph Learning with GNN Feedback
Ruiyao Xu and Kaize Ding. Gnn-as-judge: Unleashing the power of llms for graph learning with gnn feedback.arXiv preprint arXiv:2604.08553, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[36]
Augmenting low-resource text classification with graph-grounded pre-training and prompting
Zhihao Wen and Yuan Fang. Augmenting low-resource text classification with graph-grounded pre-training and prompting. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 506–516, 2023
2023
-
[37]
Leveraging large language models for node generation in few-shot learning on text-attributed graphs
Jianxiang Yu, Yuxiang Ren, Chenghua Gong, Jiaqi Tan, Xiang Li, and Xuecang Zhang. Leveraging large language models for node generation in few-shot learning on text-attributed graphs. InProceedings of the AAAI conference on artificial intelligence, volume 39, pages 13087–13095, 2025
2025
-
[38]
Llms are noisy oracles! llm-based noise-aware graph active learning for node classification
Zeang Sheng, Weiyang Guo, Yingxia Shao, Wentao Zhang, and Bin Cui. Llms are noisy oracles! llm-based noise-aware graph active learning for node classification. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 2526–2537, 2025. 11
2025
-
[39]
Co-teaching: Robust training of deep neural networks with extremely noisy labels.Advances in neural information processing systems, 31, 2018
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels.Advances in neural information processing systems, 31, 2018
2018
-
[40]
How does disagreement help generalization against label corruption? InInternational conference on machine learning, pages 7164–7173
Xingrui Yu, Bo Han, Jiangchao Yao, Gang Niu, Ivor Tsang, and Masashi Sugiyama. How does disagreement help generalization against label corruption? InInternational conference on machine learning, pages 7164–7173. PMLR, 2019
2019
-
[41]
Junnan Li, Richard Socher, and Steven CH Hoi. Dividemix: Learning with noisy labels as semi-supervised learning.arXiv preprint arXiv:2002.07394, 2020
-
[42]
Deep co-training for semi-supervised image recognition
Siyuan Qiao, Wei Shen, Zhishuai Zhang, Bo Wang, and Alan Yuille. Deep co-training for semi-supervised image recognition. InProceedings of the european conference on computer vision (eccv), pages 135–152, 2018
2018
-
[43]
Self-paced co-training
Fan Ma, Deyu Meng, Qi Xie, Zina Li, and Xuanyi Dong. Self-paced co-training. InInternational Conference on Machine Learning, pages 2275–2284. PMLR, 2017
2017
-
[44]
Self-paced learning for latent variable models.Advances in neural information processing systems, 23, 2010
M Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models.Advances in neural information processing systems, 23, 2010
2010
-
[45]
Natarajan, I
N. Natarajan, I. S. Dhillon, P. Ravikumar, and A. Tewari. Learning with noisy labels. InNeurIPS, 2013
2013
-
[46]
Xian-Jin Gui, Wei Wang, and Zhang-Hao Tian. Towards understanding deep learning from noisy labels with small-loss criterion.arXiv preprint arXiv:2106.09291, 2021
-
[47]
Understanding and utilizing deep neural networks trained with noisy labels
Pengfei Chen, Ben Ben Liao, Guangyong Chen, and Shengyu Zhang. Understanding and utilizing deep neural networks trained with noisy labels. InInternational conference on machine learning, pages 1062–1070. PMLR, 2019
2019
-
[48]
Hao Cheng, Zhaowei Zhu, Xingyu Li, Yifei Gong, Xing Sun, and Yang Liu. Learning with instance- dependent label noise: A sample sieve approach.arXiv preprint arXiv:2010.02347, 2020
-
[49]
Junyu Luo, Xiao Luo, Kaize Ding, Jingyang Yuan, Zhiping Xiao, and Ming Zhang. Robustft: Robust supervised fine-tuning for large language models under noisy response.arXiv preprint arXiv:2412.14922, 2024
-
[50]
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. The curse of recursion: Training on generated data makes models forget.arXiv preprint arXiv:2305.17493, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InWorkshop on challenges in representation learning, ICML, volume 3, page 896. Atlanta, 2013
2013
-
[52]
Uncertainty-aware self-training for few-shot text classifica- tion.Advances in Neural Information Processing Systems, 33:21199–21212, 2020
Subhabrata Mukherjee and Ahmed Awadallah. Uncertainty-aware self-training for few-shot text classifica- tion.Advances in Neural Information Processing Systems, 33:21199–21212, 2020
2020
-
[53]
Mamshad Nayeem Rizve, Kevin Duarte, Yogesh S Rawat, and Mubarak Shah. In defense of pseudo- labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning.arXiv preprint arXiv:2101.06329, 2021
-
[54]
Unifying graph convolutional neural networks and label propagation
Hongwei Wang and Jure Leskovec. Unifying graph convolutional neural networks and label propagation. arXiv preprint arXiv:2002.06755, 2020
-
[55]
Confidence may cheat: Self-training on graph neural networks under distribution shift
Hongrui Liu, Binbin Hu, Xiao Wang, Chuan Shi, Zhiqiang Zhang, and Jun Zhou. Confidence may cheat: Self-training on graph neural networks under distribution shift. InProceedings of the ACM web conference 2022, pages 1248–1258, 2022
2022
-
[56]
Active Learning for Graph Embedding
Hongyun Cai, Vincent W Zheng, and Kevin Chen-Chuan Chang. Active learning for graph embedding. arXiv preprint arXiv:1705.05085, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[57]
Rim: Reliable influence-based active learning on graphs.Advances in neural information processing systems, 34:27978–27990, 2021
Wentao Zhang, Yexin Wang, Zhenbang You, Meng Cao, Ping Huang, Jiulong Shan, Zhi Yang, and Bin Cui. Rim: Reliable influence-based active learning on graphs.Advances in neural information processing systems, 34:27978–27990, 2021
2021
-
[58]
Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017. 12
2017
-
[59]
Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[60]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[61]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. InInternational Conference on Artificial Intelligence and Statistics, pages 4447–4455. PMLR, 2024
2024
-
[62]
Model alignment as prospect theoretic optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Model alignment as prospect theoretic optimization. InForty-first International Conference on Machine Learning, 2024
2024
-
[63]
Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
2024
-
[64]
Siyan Zhao, John Dang, and Aditya Grover. Group preference optimization: Few-shot alignment of large language models.arXiv preprint arXiv:2310.11523, 2023
-
[65]
Direct preference optimization with an offset
Afra Amini, Tim Vieira, and Ryan Cotterell. Direct preference optimization with an offset. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9954–9972, 2024
2024
-
[66]
Orpo: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11170–11189, 2024
2024
-
[67]
Wiki-cs: A wikipedia-based benchmark for graph neural networks,
Péter Mernyei and C˘at˘alina Cangea. Wiki-cs: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv:2007.02901, 2020
-
[68]
Graph attention networks
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations, 2018
2018
-
[69]
Inductive representation learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017
2017
-
[70]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[71]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[72]
both wrong
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. A Limitations Time complexity.LLM-GNN Co-Teaching increases time complexity over a single-shot LLM-on-graph pipeline by a factor of T , the number of co-teaching rounds, ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.