Variable-Width Transformers
Pith reviewed 2026-06-27 00:55 UTC · model grok-4.3
The pith
Transformers with wider early and late layers and narrower middles outperform uniform-width models on language modeling while using less compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
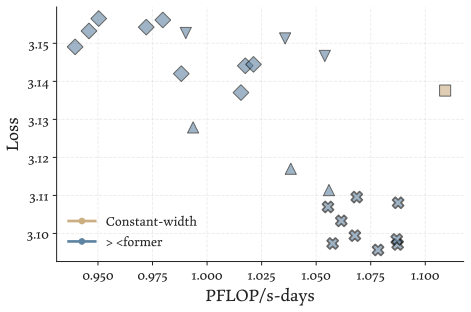
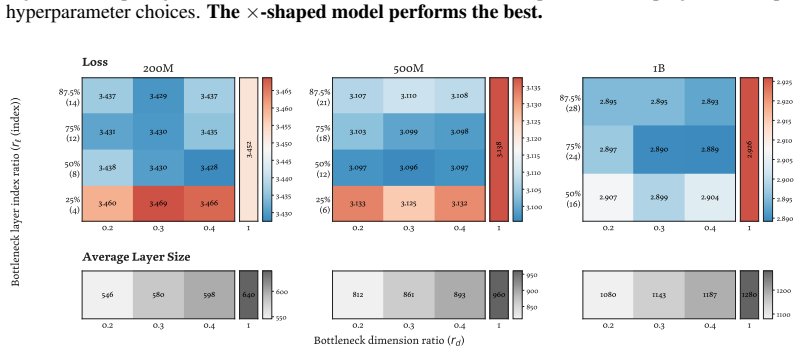
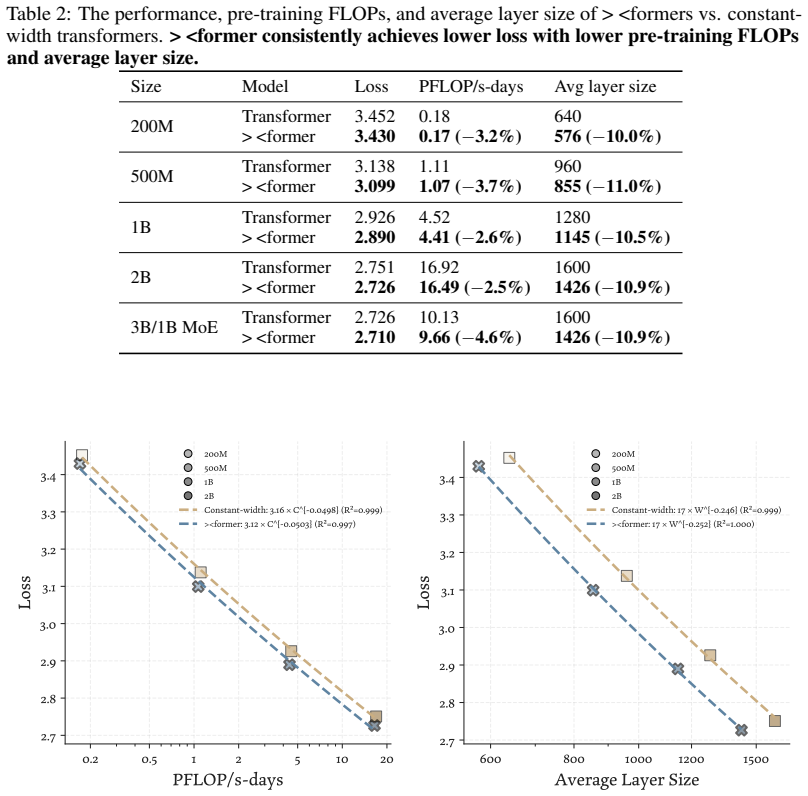
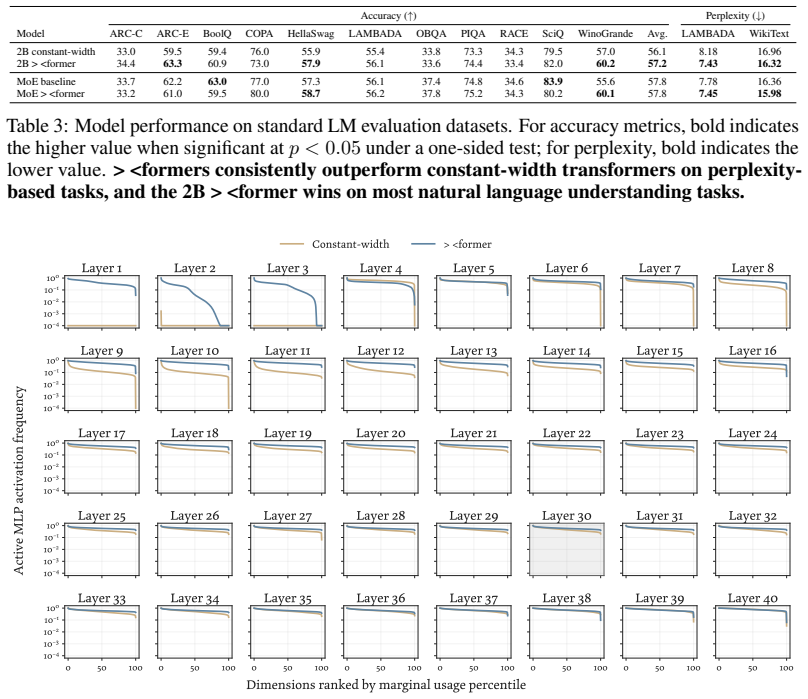
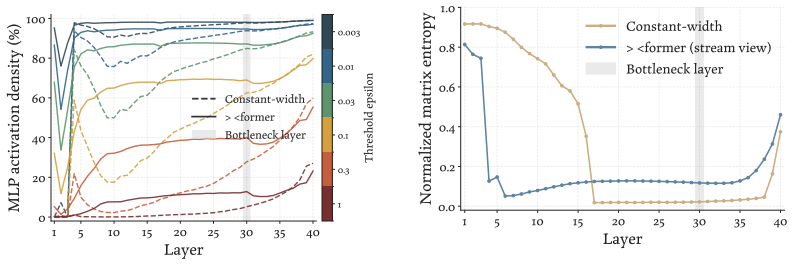
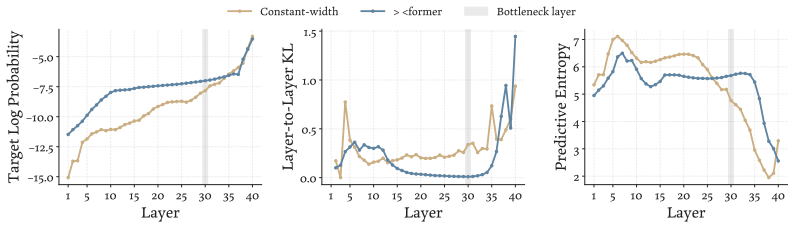
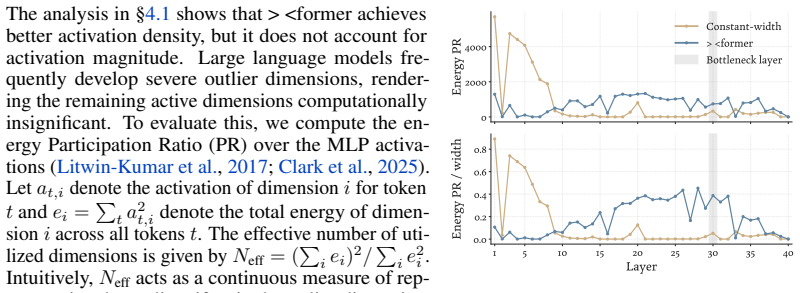
The authors introduce a ×-shaped transformer where layer widths form a bottleneck in the middle. Using a parameter-free mechanism to resize residuals, this architecture achieves lower language modeling loss than parameter-matched uniform baselines across scales from 200M to 3B parameters. The design also delivers a 22% reduction in FLOPs under loss-matched scaling and a 15% reduction in KV cache costs. Analysis shows the bottleneck produces qualitatively different representations in the residual stream.
What carries the argument
The ×-shaped width profile with parameter-free residual resizing, which allocates more capacity to early and late layers while narrowing the middle.
If this is right
- The architecture outperforms parameter-matched uniform baselines on language modeling loss from 200M to 3B parameters.
- It requires 22% fewer FLOPs under fitted loss-matched scaling curves.
- It uses 15% less KV cache memory and I/O cost.
- It produces qualitatively different representations in the residual streams.
- Nonuniform width allocation enables more resource-optimal scaling of language models.
Where Pith is reading between the lines
- The pattern suggests middle layers may primarily compress or transform information rather than perform full-scale computation.
- Similar width variation could be tested in encoder-only or encoder-decoder models for tasks beyond language modeling.
- Scaling laws might be extended to treat layer-width profile as an explicit hyperparameter for efficiency.
- The bottleneck effect could interact with mixture-of-experts routing in ways that further reduce active parameters.
Load-bearing premise
The observed gains come from the nonuniform width profile itself rather than from differences in optimization dynamics, initialization, or the resizing implementation.
What would settle it
Training both the ×-shaped model and a uniform-width model from identical random seeds with the same optimizer schedule and observing whether the uniform model closes the loss gap.
Figures

read the original abstract
Scaling model size, specifically depth and width, has driven significant progress in transformer-based language models. However, most architectures maintain a constant width across all layers, allocating a fixed parameter and computation budget evenly despite different layers potentially playing distinct computational roles. In this work, we empirically investigate nonuniform capacity allocation across network depth by proposing a $\times$-shaped > <former architecture. This design maintains wider early and late layers while narrowing the middle layers, utilizing a parameter-free residual resizing mechanism. Across decoder-only language models ranging from 200M to 2B parameters (dense) and 3B parameters (MoE), our > <former consistently outperforms parameter-matched uniform baselines on language modeling loss. By reducing the average layer width, this architecture also requires fewer overall FLOPs (22% reduction under fitted loss-matched scaling curves) and smaller KV cache memory and I/O cost (15% reduction). In analysis, we show that this bottleneck structure results in qualitatively different representations in residual streams. Overall, our results demonstrate that nonuniform width allocation can result in more resource-optimal scaling of language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a ×-shaped > <former architecture that allocates wider layers early and late in the network while narrowing middle layers, using a parameter-free residual resizing mechanism. It reports that this design consistently outperforms parameter-matched uniform-width decoder-only transformers on language modeling loss across scales from 200M to 2B (dense) and 3B (MoE) parameters, while also achieving 22% fewer FLOPs under loss-matched scaling curves and 15% smaller KV cache costs, with analysis indicating qualitatively different residual-stream representations.
Significance. If the central empirical claim holds after addressing confounds, the work would provide evidence that nonuniform width allocation can improve resource efficiency in transformer scaling without increasing parameter count, with potential implications for model design in both dense and MoE settings. The cross-scale comparisons and representation analysis are strengths that could motivate follow-up on capacity allocation.
major comments (3)
- [Abstract] Abstract: the claim of consistent outperformance on language modeling loss (and the derived 22% FLOP and 15% KV reductions) is load-bearing for the central thesis, yet the manuscript provides no statistical significance tests, run-to-run variance, or exact training protocol details; this leaves moderate support for the result as noted in the soundness assessment.
- [Methods / Architecture] The architecture description (abstract and methods): the parameter-free residual resizing step is not isolated via ablation against alternative resizing operators or against uniform baselines that apply the same resizing; without this, it is impossible to attribute gains to the nonuniform ×-shaped width profile rather than to changes in gradient flow, initialization scale, or residual statistics introduced by the resizing implementation itself.
- [Results] Experimental results section: the loss-matched scaling curves used to derive the 22% FLOP reduction are not accompanied by details on the fitting procedure, number of points, or sensitivity to the functional form; this makes the efficiency claim difficult to reproduce or stress-test independently.
minor comments (2)
- [Architecture] Notation for the ×-shaped profile and the resizing operator should be defined with an equation or diagram in the main text rather than left implicit.
- [Analysis] The analysis of residual-stream representations would benefit from quantitative metrics (e.g., cosine similarity or rank) in addition to the qualitative description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of consistent outperformance on language modeling loss (and the derived 22% FLOP and 15% KV reductions) is load-bearing for the central thesis, yet the manuscript provides no statistical significance tests, run-to-run variance, or exact training protocol details; this leaves moderate support for the result as noted in the soundness assessment.
Authors: We agree that explicit statistical tests and variance reporting would strengthen the claims. In the revision we will report results from multiple independent runs (with standard deviations) across the 200M–2B scales and include p-values for the loss differences versus uniform baselines. We will also expand the training protocol section with exact hyperparameters, data order, and initialization details to improve reproducibility. revision: yes
-
Referee: [Methods / Architecture] The architecture description (abstract and methods): the parameter-free residual resizing step is not isolated via ablation against alternative resizing operators or against uniform baselines that apply the same resizing; without this, it is impossible to attribute gains to the nonuniform ×-shaped width profile rather than to changes in gradient flow, initialization scale, or residual statistics introduced by the resizing implementation itself.
Authors: This is a valid concern. The current experiments compare ×-shaped models only against uniform-width models without the resizing operator. In the revision we will add two targeted ablations: (1) uniform-width models that apply the identical parameter-free resizing at the same layer positions, and (2) alternative resizing operators (e.g., learned linear projections) within the ×-shaped profile. These will clarify whether the performance gains derive from the width schedule itself. revision: yes
-
Referee: [Results] Experimental results section: the loss-matched scaling curves used to derive the 22% FLOP reduction are not accompanied by details on the fitting procedure, number of points, or sensitivity to the functional form; this makes the efficiency claim difficult to reproduce or stress-test independently.
Authors: We will revise the results section to document the exact fitting procedure, the number of data points per curve, the functional form employed (including any alternatives tested), and a sensitivity analysis showing how the 22% FLOP reduction estimate changes under different fitting choices or subsets of points. revision: yes
Circularity Check
No significant circularity; empirical comparisons are self-contained
full rationale
The paper advances an architectural proposal (×-shaped width allocation with parameter-free resizing) and supports it solely via direct training runs that measure loss, FLOP, and KV-cache metrics against explicitly parameter-matched uniform baselines. No equations, scaling laws, or first-principles derivations appear in the abstract or described claims; reported gains are presented as observed experimental outcomes rather than quantities obtained by fitting or self-citation. The central claim therefore does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A parameter-free residual resizing operation can connect layers of different widths while preserving sufficient information for end-to-end training.
invented entities (1)
-
×-shaped > <former architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Baroian, A. and Notebomer, K. Crown, frame, reverse: Layer-wise scaling variants for llm pre-training. arXiv preprint arXiv:2509.06518, 2025
arXiv 2025
-
[2]
L., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Tamkin, A., Nguyen, K., McLean, B., Burke, J
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N. L., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Tamkin, A., Nguyen, K., McLean, B., Burke, J. E., Hume, T., Carter, S., Henighan, T., and Olah, C. Towards monosemanticity: Decomposing language models with dic...
2023
-
[3]
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., Reif, E., Du, N., Hutchinson, B., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levska...
Pith/arXiv arXiv 2022
-
[4]
G., Marschall, O., van Meegen, A., and Litwin-Kumar, A
Clark, D. G., Marschall, O., van Meegen, A., and Litwin-Kumar, A. Connectivity structure and dynamics of nonlinear recurrent neural networks. Phys. Rev. X, 15: 0 041019, Nov 2025. doi:10.1103/2jt7-c8cq. URL https://link.aps.org/doi/10.1103/2jt7-c8cq
-
[5]
Dai, Z., Lai, G., Yang, Y., and Le, Q. V. Funnel-transformer: Filtering out sequential redundancy for efficient language processing. In Advances in Neural Information Processing Systems, volume 33, pp.\ 4271--4282. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/2cd2915e69546904e4e5d4a2ac9e1652-Paper.pdf
2020
-
[6]
Q., Arroyo, A., Barbero, F., Dong, X., Bronstein, M
de Llano, E. Q., Arroyo, A., Barbero, F., Dong, X., Bronstein, M. M., LeCun, Y., and Shwartz-Ziv, R. Attention sinks and compression valleys in LLM s are two sides of the same coin. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=c5TFhCJ6fs
2026
-
[7]
DeepSeek-V4 : Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. DeepSeek-V4 : Towards highly efficient million-token context intelligence, 2026
2026
-
[8]
The language model evaluation harness, 07 2024
Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Le Noac'h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., and Zou, A. The language model evaluation harness, 07 2024. URL https://zenodo.or...
arXiv 2024
-
[9]
D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., and Wu, J
Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., and Wu, J. Scaling and evaluating sparse autoencoders. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=tcsZt9ZNKD
2025
-
[10]
Transformer Feed-Forward Layers Are Key-Value Memories
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 5484--5495, Online and Punta Cana, Dominican Republic, November 2021. Association for Computa...
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[11]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Geva, M., Caciularu, A., Wang, K., and Goldberg, Y. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In Goldberg, Y., Kozareva, Z., and Zhang, Y. (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 30--45, Abu Dhabi, United Arab Emirates, December 2022. Associ...
-
[12]
OLMo: Accelerating the science of language models
Groeneveld, D., Beltagy, I., Walsh, E., Bhagia, A., Kinney, R., Tafjord, O., Jha, A., Ivison, H., Magnusson, I., Wang, Y., Arora, S., Atkinson, D., Authur, R., Chandu, K., Cohan, A., Dumas, J., Elazar, Y., Gu, Y., Hessel, J., Khot, T., Merrill, W., Morrison, J., Muennighoff, N., Naik, A., Nam, C., Peters, M., Pyatkin, V., Ravichander, A., Schwenk, D., Sha...
-
[13]
The unreasonable ineffectiveness of the deeper layers
Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P., and Roberts, D. The unreasonable ineffectiveness of the deeper layers. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=ngmEcEer8a
2025
-
[14]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 770--778, 2016
2016
-
[15]
Hill, M. O. Diversity and evenness: A unifying notation and its consequences. Ecology, 54 0 (2): 0 427--432, 1973. doi:https://doi.org/10.2307/1934352. URL https://esajournals.onlinelibrary.wiley.com/doi/abs/10.2307/1934352
-
[16]
A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Vinyals, O., Rae, J
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Vinyals, O., Rae, J. W., and Sifre, L. Training compute-optimal large language models. In Proce...
2022
-
[17]
Layerwise importance analysis of feed-forward networks in transformer-based language models
Ikeda, W., Yano, K., Takahashi, R., Lee, J., Shibata, K., and Suzuki, J. Layerwise importance analysis of feed-forward networks in transformer-based language models. arXiv preprint arXiv:2508.17734, 2025
arXiv 2025
-
[18]
Perceiver: General perception with iterative attention
Jaegle, A., Gimeno, F., Brock, A., Zisserman, A., Vinyals, O., and Carreira, J. Perceiver: General perception with iterative attention. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp.\ 4651--4664. PMLR, 2021. URL https://proceedings.mlr.press/v139/jaegle21a.html
2021
-
[19]
B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models, 2020. URL https://arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2020
-
[20]
Limits to depth efficiencies of self-attention
Levine, Y., Wies, N., Sharir, O., Bata, H., and Shashua, A. Limits to depth efficiencies of self-attention. Advances in Neural Information Processing Systems, 33: 0 22640--22651, 2020
2020
-
[21]
Y., Bansal, H., Guha, E
Li, J., Fang, A., Smyrnis, G., Ivgi, M., Jordan, M., Gadre, S. Y., Bansal, H., Guha, E. K., Keh, S., Arora, K., Garg, S., Xin, R., Muennighoff, N., Heckel, R., Mercat, J., Chen, M. F., Gururangan, S., Wortsman, M., Albalak, A., Bitton, Y., Nezhurina, M., Abbas, A. K. M., Hsieh, C.-Y., Ghosh, D., Gardner, J. P., Kilian, M., Zhang, H., Shao, R., Pratt, S. M...
2024
-
[22]
D., Axel, R., Sompolinsky, H., and Abbott, L
Litwin-Kumar, A., Harris, K. D., Axel, R., Sompolinsky, H., and Abbott, L. Optimal degrees of synaptic connectivity. Neuron, 93 0 (5): 0 1153--1164.e7, 2017. ISSN 0896-6273. doi:https://doi.org/10.1016/j.neuron.2017.01.030. URL https://www.sciencedirect.com/science/article/pii/S0896627317300545
-
[23]
Y., Singh, S., Bhatele, A., Goldblum, M., Panda, A., and Goldstein, T
McLeish, S., Kirchenbauer, J., Miller, D. Y., Singh, S., Bhatele, A., Goldblum, M., Panda, A., and Goldstein, T. Gemstones: A model suite for multi-faceted scaling laws. arXiv preprint arXiv:2502.06857, 2025
arXiv 2025
-
[24]
Delight: Deep and light-weight transformer
Mehta, S., Ghazvininejad, M., Iyer, S., Zettlemoyer, L., and Hajishirzi, H. Delight: Deep and light-weight transformer. arXiv preprint arXiv:2008.00623, 2020
arXiv 2008
-
[25]
Mehta, S., Sekhavat, M. H., Cao, Q., Horton, M., Jin, Y., Sun, C., Mirzadeh, I., Najibi, M., Belenko, D., Zatloukal, P., et al. OpenELM : An efficient language model family with open training and inference framework. arXiv preprint arXiv:2404.14619, 2024
arXiv 2024
-
[26]
J., and Belinkov, Y
Meng, K., Bau, D., Andonian, A. J., and Belinkov, Y. Locating and editing factual associations in GPT . In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=-h6WAS6eE4
2022
-
[27]
Pointer sentinel mixture models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=Byj72udxe
2017
-
[28]
Hierarchical transformers are more efficient language models
Nawrot, P., Tworkowski, S., Tyrolski, M., Kaiser, L., Wu, Y., Szegedy, C., and Michalewski, H. Hierarchical transformers are more efficient language models. In Carpuat, M., de Marneffe, M.-C., and Meza Ruiz, I. V. (eds.), Findings of the Association for Computational Linguistics: NAACL 2022, pp.\ 1559--1571, Seattle, United States, July 2022. Association ...
-
[29]
Stacked hourglass networks for human pose estimation
Newell, A., Yang, K., and Deng, J. Stacked hourglass networks for human pose estimation. In European conference on computer vision, pp.\ 483--499. Springer, 2016
2016
-
[30]
Interpreting GPT : the logit lens
nostalgebraist. Interpreting GPT : the logit lens. LessWrong, 2020. URL https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
2020
-
[31]
The impact of depth on compositional generalization in transformer language models
Petty, J., Steenkiste, S., Dasgupta, I., Sha, F., Garrette, D., and Linzen, T. The impact of depth on compositional generalization in transformer language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 7239--7252, 2024
2024
-
[32]
U-net: Convolutional networks for biomedical image segmentation
Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pp.\ 234--241. Springer, 2015
2015
-
[33]
and Vetterli, M
Roy, O. and Vetterli, M. The effective rank: A measure of effective dimensionality. In 2007 15th European Signal Processing Conference, pp.\ 606--610, 2007
2007
-
[34]
On the effect of dropping layers of pre-trained transformer models
Sajjad, H., Dalvi, F., Durrani, N., and Nakov, P. On the effect of dropping layers of pre-trained transformer models. Comput. Speech Lang., 77 0 (C), January 2023. ISSN 0885-2308. doi:10.1016/j.csl.2022.101429. URL https://doi.org/10.1016/j.csl.2022.101429
-
[35]
MobileNetV2 : Inverted residuals and linear bottlenecks
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and Chen, L.-C. MobileNetV2 : Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 4510--4520, 2018
2018
-
[36]
GLU variants improve transformer, 2020
Shazeer, N. GLU variants improve transformer, 2020. URL https://arxiv.org/abs/2002.05202
Pith/arXiv arXiv 2020
-
[37]
R., Zhao, D., Patel, N
Skean, O., Arefin, M. R., Zhao, D., Patel, N. N., Naghiyev, J., LeCun, Y., and Shwartz-Ziv, R. Layer by layer: Uncovering hidden representations in language models. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=WGXb7UdvTX
2025
-
[38]
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., and Liu, Y. Roformer: Enhanced transformer with rotary position embedding. Neurocomput., 568 0 (C), February 2024. ISSN 0925-2312. doi:10.1016/j.neucom.2023.127063. URL https://doi.org/10.1016/j.neucom.2023.127063
-
[39]
W., Narang, S., Yogatama, D., Vaswani, A., and Metzler, D
Tay, Y., Dehghani, M., Rao, J., Fedus, W., Abnar, S., Chung, H. W., Narang, S., Yogatama, D., Vaswani, A., and Metzler, D. Scale efficiently: Insights from pre-training and fine-tuning transformers. arXiv preprint arXiv:2109.10686, 2021
arXiv 2021
-
[40]
Team, K., Chen, G., Zhang, Y., Su, J., Xu, W., Pan, S., Wang, Y., Wang, Y., Chen, G., Yin, B., Chen, Y., Yan, J., Wei, M., Zhang, Y., Meng, F., Hong, C., Xie, X., Liu, S., Lu, E., Tai, Y., Chen, Y., Men, X., Guo, H., Charles, Y., Lu, H., Sui, L., Zhu, J., Zhou, Z., He, W., Huang, W., Xu, X., Wang, Y., Lai, G., Du, Y., Wu, Y., Yang, Z., and Zhou, X. Attent...
Pith/arXiv arXiv 2026
-
[41]
BERT rediscovers the classical NLP pipeline
Tenney, I., Das, D., and Pavlick, E. BERT rediscovers the classical NLP pipeline. In Korhonen, A., Traum, D., and M \`a rquez, L. (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp.\ 4593--4601, Florence, Italy, July 2019. Association for Computational Linguistics. doi:10.18653/v1/P19-1452. URL https://acla...
-
[42]
mhc: Manifold-constrained hyper-connections, 2026
Xie, Z., Wei, Y., Cao, H., Zhao, C., Deng, C., Li, J., Dai, D., Gao, H., Chang, J., Yu, K., Zhao, L., Zhou, S., Xu, Z., Zhang, Z., Zeng, W., Hu, S., Wang, Y., Yuan, J., Wang, L., and Liang, W. mhc: Manifold-constrained hyper-connections, 2026. URL https://arxiv.org/abs/2512.24880
Pith/arXiv arXiv 2026
-
[43]
Tensor programs VI : Feature learning in infinite depth neural networks
Yang, G., Yu, D., Zhu, C., and Hayou, S. Tensor programs VI : Feature learning in infinite depth neural networks. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=17pVDnpwwl
2024
-
[44]
Hyper-connections
Zhu, D., Huang, H., Huang, Z., Zeng, Y., Mao, Y., Wu, B., Min, Q., and Zhou, X. Hyper-connections. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=9FqARW7dwB
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.