As You Wish: Mission Planning with Formal Verification using LLMs in Precision Agriculture
Pith reviewed 2026-06-27 00:03 UTC · model grok-4.3
The pith
Dual LLMs with LTL feedback loops ensure natural language robot missions meet user specifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that introducing multiple feedback loops leveraging linear temporal logic (LTL) with two different commercial LLMs for specification and verification subtasks ensures that the mission planning system meets the specifications formulated by the user while still using natural language.
What carries the argument
Multiple feedback loops in the planning architecture that leverage linear temporal logic (LTL) using two different commercial LLMs for specification and verification subtasks.
If this is right
- The mission planning system can now mitigate ambiguities inherent in natural language inputs.
- Formal verification via LTL becomes part of a fully autonomous pipeline.
- The architecture addresses and solves challenges in an LLM's ability to generate valuable LTL formulas.
- Extensive experiments reveal both strengths and remaining limitations of the integrated verification approach.
Where Pith is reading between the lines
- The dual-LLM LTL verification pattern could be tested in robot planning tasks outside agriculture.
- Switching between commercial LLMs might introduce variability in performance or cost that single-model systems avoid.
- Improved prompt engineering or fine-tuning could eventually reduce the need for separate specification and verification models.
Load-bearing premise
That LLMs can be made to generate valuable LTL formulas through the proposed feedback loops and dual-LLM architecture.
What would settle it
An experiment where the dual-LLM feedback system repeatedly produces an LTL formula that fails to match the user's natural language specification or incorrectly verifies a mission plan.
Figures




read the original abstract
Though robotic systems are now being commercialized and deployed in various industries, many of these systems are highly specialized and often require an advanced skill set to operate and ensure they perform as instructed. To mitigate this problem, we recently introduced a mission planner leveraging LLMs to synthesize mission plans in precision agriculture based on mission descriptions provided in natural language. While the system demonstrates impressive performance, it also suffers from the inherent ambiguities of natural language. In this paper, we extend our system to address this issue by introducing multiple feedback loops in the planning architecture that leverage linear temporal logic (LTL) to ensure the mission planning system meets the specifications formulated by the user while still using natural language. To mitigate potential bias, this is achieved by using two different commercial LLMs in charge of the specification and verification subtasks. Through extensive experiments, we highlight the strengths and limitations of integrating mission verification into a fully autonomous pipeline, particularly regarding an LLM's ability to generate valuable LTL formulas, and show how our proposed implementation addresses and solves these challenges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends a prior LLM-based mission planner for precision agriculture by adding multiple feedback loops that employ linear temporal logic (LTL). Two distinct commercial LLMs are used—one for generating LTL specifications from natural-language user input and one for verifying the synthesized plans—while the overall system remains driven by natural language. The authors state that extensive experiments demonstrate both the strengths and limitations of this LLM-centric verification approach and that the implementation solves the identified challenges.
Significance. If the dual-LLM feedback architecture can be shown to produce reliable LTL formulas and to detect violations with high fidelity, the work would provide a concrete bridge between accessible natural-language interfaces and formal-methods guarantees for field robots. The explicit choice of two different commercial LLMs to mitigate bias is a constructive design decision that merits recognition.
major comments (2)
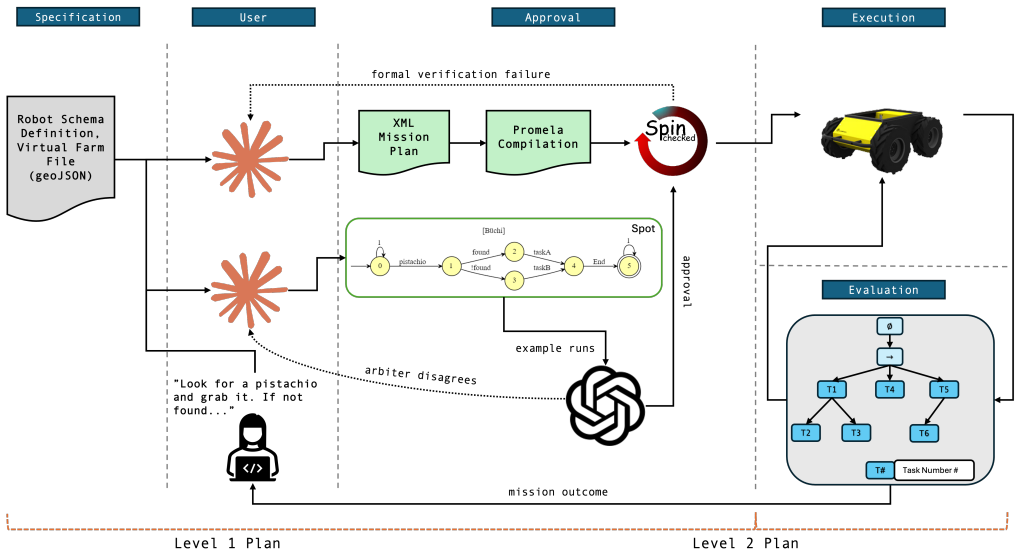
- [Architecture section] Architecture section (and associated figure): the verification subtask is performed by the second LLM rather than by an automated LTL model checker such as NuSMV or SPIN. The central claim that the system “ensures the mission planning system meets the specifications” therefore rests on the assumption that the verification LLM will correctly identify violations—an assumption that is not formally grounded.
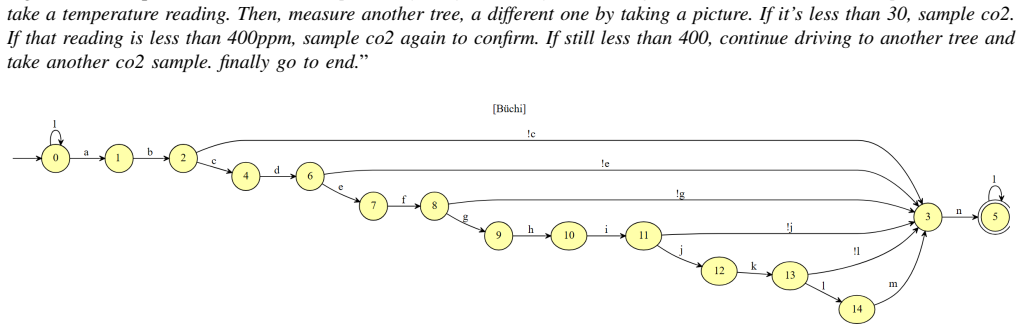
- [Experiments section] Experiments section: the abstract asserts that “extensive experiments” highlight strengths and limitations, yet the manuscript supplies neither quantitative metrics (e.g., LTL-generation success rate, false-positive rate on violation detection, comparison against a model-checker baseline) nor error bars. Without these data the evaluation of whether the feedback loops solve the LLM limitations remains incomplete.
minor comments (2)
- Clarify the precise LTL fragment supported and whether generated formulas undergo syntactic validation before being passed to the verification LLM.
- Add an explicit information-flow diagram showing the two LLMs, the planner, and the feedback loops.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We value the recognition of the dual-LLM architecture as a bridge toward accessible formal guarantees. We respond point-by-point to the major comments below and will make targeted revisions to address the concerns about formal grounding and quantitative evaluation.
read point-by-point responses
-
Referee: [Architecture section] Architecture section (and associated figure): the verification subtask is performed by the second LLM rather than by an automated LTL model checker such as NuSMV or SPIN. The central claim that the system “ensures the mission planning system meets the specifications” therefore rests on the assumption that the verification LLM will correctly identify violations—an assumption that is not formally grounded.
Authors: We agree that verification is performed by the second LLM and that this renders the claim of 'ensures' informal rather than formally grounded. The design deliberately avoids model checkers to preserve a fully natural-language pipeline for non-expert agricultural users; translating plans into a model-checker input would require additional formalization steps that undermine the accessibility goal. We will revise the architecture section, abstract, and conclusion to replace 'ensures' with 'provides LLM-based verification whose reliability is assessed empirically,' add an explicit limitations paragraph on the absence of formal guarantees, and discuss the trade-off versus traditional model checkers. revision: yes
-
Referee: [Experiments section] Experiments section: the abstract asserts that “extensive experiments” highlight strengths and limitations, yet the manuscript supplies neither quantitative metrics (e.g., LTL-generation success rate, false-positive rate on violation detection, comparison against a model-checker baseline) nor error bars. Without these data the evaluation of whether the feedback loops solve the LLM limitations remains incomplete.
Authors: The current experiments consist of qualitative case studies that demonstrate both successful LTL generation/verification and failure modes. We accept that quantitative metrics are needed for a complete evaluation. In revision we will add success rates for LTL formula generation over repeated trials, precision/recall for violation detection, and, where feasible, a limited comparison against a model-checker baseline on the subset of cases that can be manually formalized. Revised figures will include error bars or confidence intervals. revision: yes
Circularity Check
No circularity: systems architecture paper with no derivations or self-referential reductions
full rationale
The paper is a systems description extending prior work with feedback loops, dual LLMs for LTL specification/verification, and natural language interfaces. No equations, fitted parameters, predictions, or uniqueness theorems appear. The self-citation to prior mission planner work is not load-bearing for any derivation; the new architecture's claims rest on experimental evaluation rather than reducing to the citation by construction. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Baier and J.P
C. Baier and J.P. Katoen.Principless of model checking. MIT Press, 2008
2008
-
[2]
Carpin and T
S. Carpin and T. C. Thayer. Solving stochastic orienteering problems with chance constraints using monte carlo tree search. InProceedings of the IEEE International Conference on Automation Science and Engineering, pages 1170–1177, 2022
2022
-
[3]
G. Cheng et al. Empowering Large Language Models on Robotic Ma- nipulation with Affordance Prompting, April 2024. arXiv:2404.11027 [cs] version: 1
-
[4]
R. Emsley. ChatGPT: these are not hallucinations – they’re fabrications and falsifications.Schizophrenia, 9(1):1–2, August 2023. Publisher: Nature Publishing Group
2023
-
[5]
He et al
K. He et al. Towards manipulation planning with temporal logic specifications. InPRoceedings of the IEEE International Conference on Robotics and Automation, pages 346–352, Seattle, W A, USA, May
-
[6]
Holzmann.The SPIN Model Checker: Primer and Reference Manual
G. Holzmann.The SPIN Model Checker: Primer and Reference Manual. Addison-Wesley, 2003
2003
-
[7]
arXiv preprint arXiv:2201.07207 , doi =
W. Huang et al. Language Models as Zero-Shot Planners: Ex- tracting Actionable Knowledge for Embodied Agents, March 2022. arXiv:2201.07207 [cs]
-
[8]
IEEE Standard for Robot Task Representation.IEEE Std 1872.1-2024, pages 1–32, 2024
IEEE. IEEE Standard for Robot Task Representation.IEEE Std 1872.1-2024, pages 1–32, 2024
2024
-
[9]
Can ChatGPT support software verification?
C. Janßen et al. Can ChatGPT support software verification?, Novem- ber 2023. arXiv:2311.02433 [cs]
-
[10]
S. Kalluraya et al. Multi-robot Mission Planning in Dynamic Semantic Environments, March 2023. arXiv:2209.06323 [cs, eess]
-
[11]
S. Kalluraya et al. Resilient Temporal Logic Planning in the Presence of Robot Failures, October 2023. arXiv:2305.05485 [cs]
-
[12]
S.S. Kannan et al. SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models, March 2024. arXiv:2309.10062 [cs]
-
[13]
Kumar and R
A. Kumar and R. Kala. Linear Temporal Logic-based Mission Plan- ning.International Journal of Interactive Multimedia and Artificial Intelligence, 3(7):32, 2016
2016
-
[14]
LaValle.Planning algorithms
S.M. LaValle.Planning algorithms. Cambridge academic press, 2006
2006
-
[15]
Liang et al
J. Liang et al. Code as Policies: Language Model Programs for Em- bodied Control. InProceedings of the IEEE International Conference on Robotics and Automation, pages 9493–9500, 2023
2023
-
[16]
A.D Lutz et al. From Spot 2.0 to Spot 2.10: What’s new? In Proceedings of the 34th International Conference on Computer Aided Verification (CAV’22), volume 13372 ofLecture Notes in Computer Science, pages 174–187. Springer, August 2022
2022
-
[17]
ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
C.E. Mower et al. ROS-LLM: A ROS framework for embod- ied AI with task feedback and structured reasoning, July 2024. arXiv:2406.19741 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
W. Murphy et al. Guiding LLM Temporal Logic Generation with Explicit Separation of Data and Control, June 2024. arXiv:2406.07400 [cs] version: 1
- [19]
-
[20]
P.P. Ray. ChatGPT: A comprehensive review on background, ap- plications, key challenges, bias, ethics, limitations and future scope. Internet of Things and Cyber-Physical Systems, 3:121–154, January 2023
2023
-
[21]
Zuzu ´arregui and S
M.A. Zuzu ´arregui and S. Carpin. Leveraging LLMs for mission plan- ning in precision agriculture. InProceedings of the IEEE International Conference on Robotics and Automation, 2025 (to appear)
2025
-
[22]
Zuzu ´arregui, M.M
M.A. Zuzu ´arregui, M.M. Toslak, and S. Carpin. One for all: Llm- based heterogeneous mission planning in precision agriculture. In Proceedeings of the IFAC Conference on Sensing, Control and Au- tomation Technologies for Agriculture, submitted
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.