From Drift to Coherence: Stabilizing Beliefs in LLMs
Pith reviewed 2026-06-27 01:31 UTC · model grok-4.3
The pith
LLM beliefs drift initially during resampling but converge to coherent distributions after sufficient steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
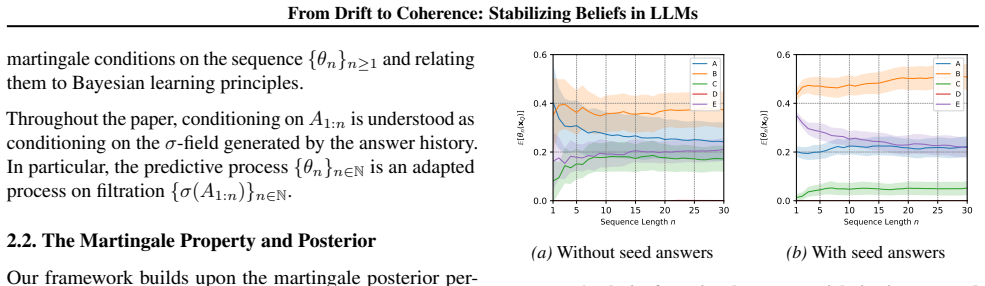
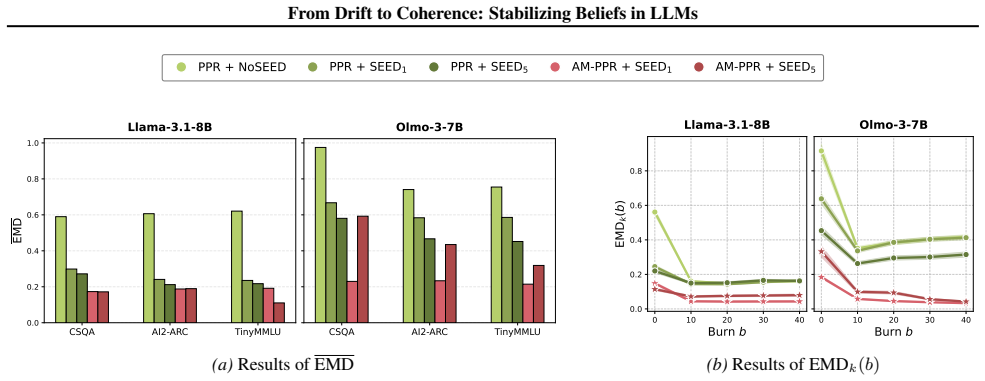
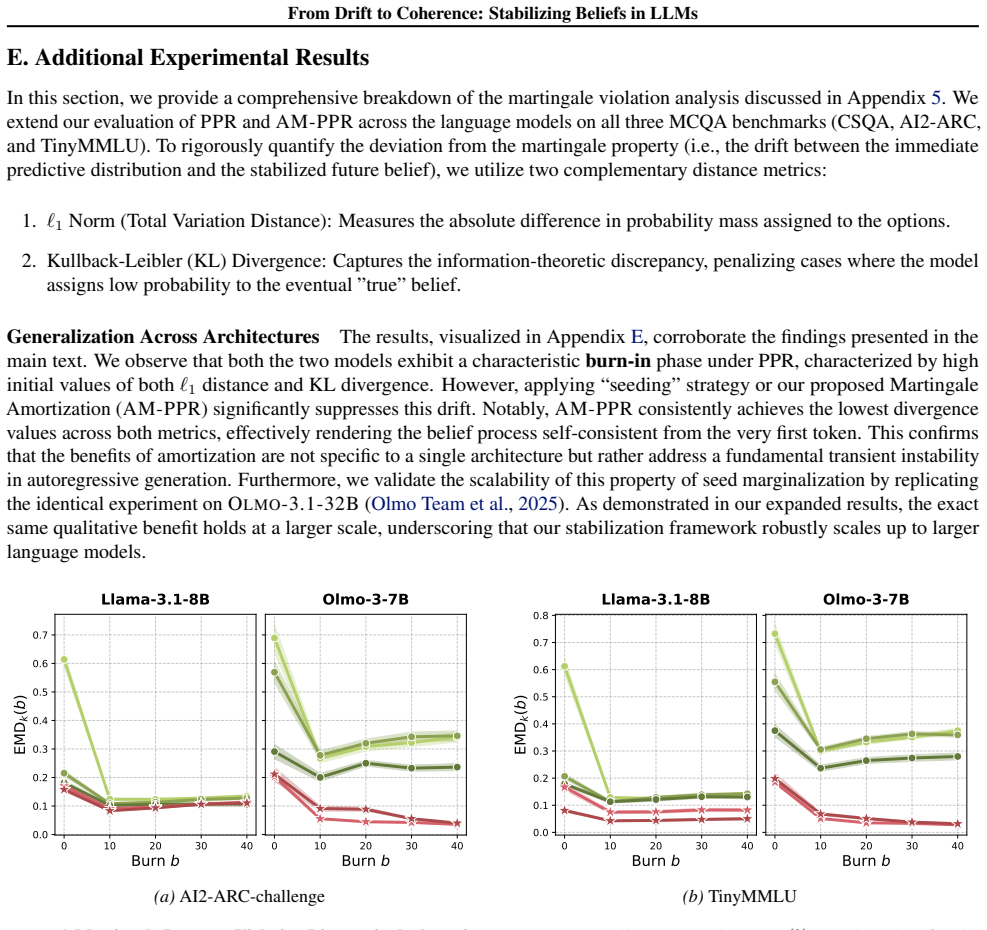
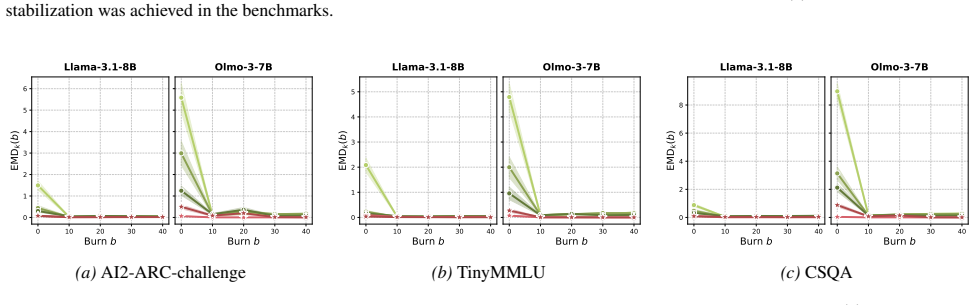
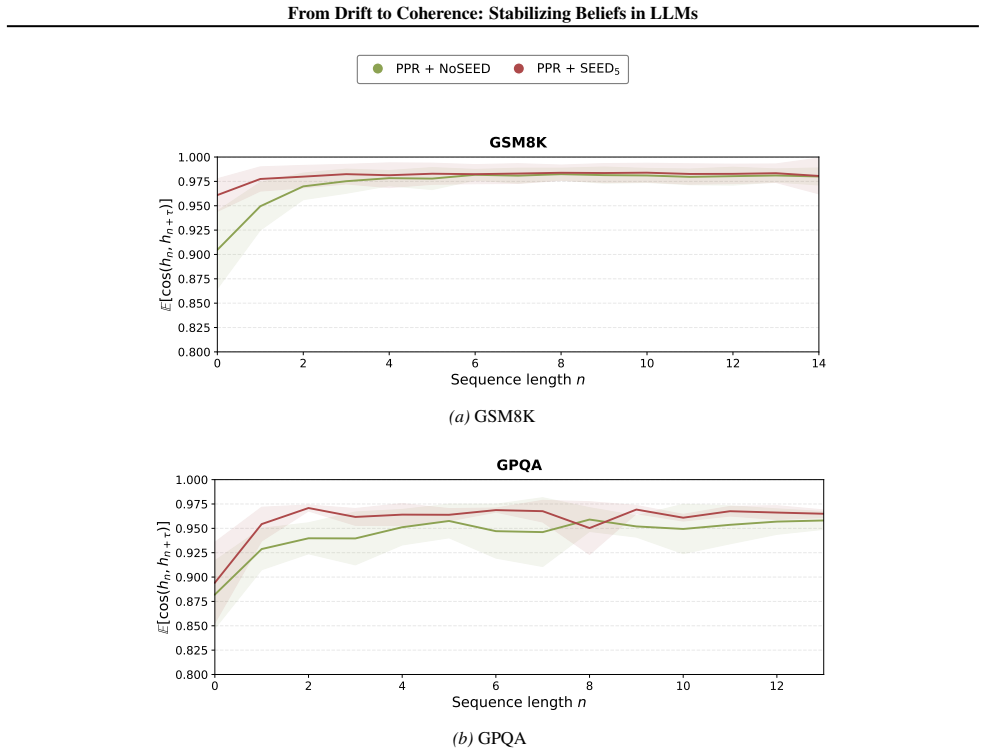
In generic multiple-choice QA, prompted predictive resampling reveals early belief drift indicating martingale violations, but after enough steps the belief process self-stabilizes and converges to a coherent predictive distribution. Seed-answer prompting accelerates this stabilization, and a self-consistency loss amortizes the drift into the model via fine-tuning, reducing drift and improving coherence on MCQA benchmarks.
What carries the argument
Prompted predictive resampling (PPR), in which the LLM generates a sequence of answers to the identical question, allowing observation of belief dynamics and convergence.
If this is right
- Seed-answer prompting accelerates stabilization of beliefs.
- Self-consistency loss reduces early-stage drift through fine-tuning.
- Predictive coherence improves on multiple-choice QA benchmarks.
- Accuracy on those benchmarks remains unchanged.
Where Pith is reading between the lines
- Similar resampling techniques might stabilize beliefs in open-ended generation tasks.
- Models could be trained to satisfy coherence conditions from the start rather than post-hoc.
- Belief stabilization might affect performance on tasks requiring consistent reasoning over time.
Load-bearing premise
The self-stabilization under prompted predictive resampling in multiple-choice settings reflects a general property of LLM predictive beliefs.
What would settle it
Finding that belief drift persists or fails to converge in a different question format, model architecture, or resampling procedure would challenge the claim.
Figures





read the original abstract
Large language models (LLMs) are often hypothesized to perform implicit Bayesian inference, yet a key coherence condition, the martingale property of predictive beliefs, has been shown to fail in controlled synthetic in-context learning settings. We revisit this question in a more typical usage regime: generic multiple-choice question answering. Exploiting the discrete answer space, we compute exact predictive distributions and study belief dynamics induced by autoregressive answer resampling. We introduce prompted predictive resampling (PPR), where an LLM generates a sequence of answers to the same question. Empirically, PPR reveals early-stage belief drift, indicating martingale violations. However, after sufficient resampling steps, the belief process self-stabilizes and converges to a coherent predictive distribution. Based on this observation, we further propose (i) a seed-answer prompting strategy to accelerate stabilization, and (ii) a self-consistency loss that amortizes early-stage drift into the model via fine-tuning. Experiments on multiple-choice QA benchmarks show that our methods substantially reduce belief drift and improve predictive coherence without sacrificing accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit initial belief drift (martingale violations) under prompted predictive resampling (PPR) in multiple-choice QA, but the process self-stabilizes after sufficient steps to a coherent predictive distribution. It proposes seed-answer prompting to accelerate stabilization and a self-consistency loss for fine-tuning to amortize early drift, reporting that these reduce drift and improve coherence on MCQA benchmarks without accuracy loss. The work exploits the discrete answer space for exact predictive distribution computation.
Significance. If the self-stabilization result holds beyond the specific experimental regime, the paper contributes an empirical diagnostic for coherence failures in LLM beliefs and practical interventions (prompting and loss) that could improve reliability in reasoning tasks. The strength lies in the exact-distribution analysis in a controlled discrete setting, which allows direct measurement of martingale properties rather than relying on proxies.
major comments (2)
- [Abstract and Experiments] The central claim that PPR reveals a general trajectory of early drift followed by self-stabilization (and that the proposed fixes address an intrinsic LLM property) rests on observations confined to discrete MCQA with small answer spaces where exact distributions are computable. No evidence is provided that this trajectory persists in regimes with larger or continuous answer spaces, where the resampling dynamics may differ; this is load-bearing for the title's broader claim of 'stabilizing beliefs in LLMs'.
- [Experiments] Experiments section: the reported benchmark improvements lack details on the number of models evaluated, number of runs per experiment, statistical significance tests, or controls for prompt variations and temperature settings. Without these, it is unclear whether the reductions in belief drift are robust or could be artifacts of specific model-prompt combinations.
minor comments (2)
- [Methods] Notation for the self-consistency loss and the definition of 'coherent predictive distribution' should be introduced with explicit equations in the methods section for reproducibility.
- [Figures] Figure captions for the belief trajectory plots should include the exact number of resampling steps shown and the models used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the value of exact-distribution analysis in the discrete setting. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central claim that PPR reveals a general trajectory of early drift followed by self-stabilization (and that the proposed fixes address an intrinsic LLM property) rests on observations confined to discrete MCQA with small answer spaces where exact distributions are computable. No evidence is provided that this trajectory persists in regimes with larger or continuous answer spaces, where the resampling dynamics may differ; this is load-bearing for the title's broader claim of 'stabilizing beliefs in LLMs'.
Authors: We agree that the study is deliberately restricted to discrete MCQA to enable exact computation of predictive distributions and direct assessment of martingale properties. This controlled regime is presented as a strength rather than a limitation of the method. The title describes the empirical trajectory observed under PPR in this setting. We do not claim the identical dynamics hold universally. To clarify scope, we will revise the abstract to explicitly qualify results as applying to discrete answer spaces and add a dedicated limitations paragraph noting that extension to continuous or larger spaces remains open. revision: yes
-
Referee: [Experiments] Experiments section: the reported benchmark improvements lack details on the number of models evaluated, number of runs per experiment, statistical significance tests, or controls for prompt variations and temperature settings. Without these, it is unclear whether the reductions in belief drift are robust or could be artifacts of specific model-prompt combinations.
Authors: We apologize for insufficient detail in the experimental protocol. We will expand the Experiments section to report: evaluation across 4 models, 10 independent runs per condition using different random seeds, statistical significance via paired Wilcoxon tests with reported p-values, temperature fixed at 1.0, and ablation across 3 distinct prompt templates. These additions will substantiate robustness. revision: yes
- Whether the self-stabilization trajectory observed under PPR holds in regimes with larger or continuous answer spaces
Circularity Check
No circularity: purely observational empirical study with no derivations or self-referential reductions
full rationale
The paper's central claims rest on direct computation of exact predictive distributions over discrete answer spaces under prompted predictive resampling, followed by empirical measurement of drift and subsequent stabilization. No equations, parameters, or uniqueness results are fitted to subsets of the target data and then re-presented as independent predictions. No load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results appear in the derivation chain. The methods (seed-answer prompting and self-consistency loss) are motivated by, but not definitionally equivalent to, the observed trajectories. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Wang, Z
Falck, F. and Wang, Z. and Holmes, C. , title =
-
[2]
arXiv preprint arXiv:2507.21874 , year=
Bayesian Predictive Inference Beyond Martingales , author=. arXiv preprint arXiv:2507.21874 , year=
-
[3]
and Holmes, C
Fong, E. and Holmes, C. and Walker, S. G. , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume = 85, issue = 5, pages =
-
[4]
Rethinking aleatoric and epistemic uncertainty , author =
-
[5]
Language Models are Few-Shot Learners , year =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[6]
Xie, S. M. and Raghunathan, A. and Liang, P. and Ma, T. , title =
-
[7]
and Yang, H
Ye, N. and Yang, H. and Siah, A. and Namkoong, H. , title =
-
[8]
and Zhu, W
Wang, X. and Zhu, W. and Saxon, M. and Steyvers, M. and Wang, W. Y. , title =
-
[9]
LLMs are Bayesian, In Expectation, Not in Realization
LLMs are Bayesian, in expectation, not in realization , author=. arXiv preprint arXiv:2507.11768 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
and Petrone, S
Fortini, S. and Petrone, S. , title =. Statistical Science , volume = 40, number = 1, pages =
-
[11]
and Pratelli, L
Berti, P. and Pratelli, L. and Rigo, P. , title =
-
[12]
Commonsenseqa: A question answering challenge targeting commonsense knowledge , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[13]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Brier, Glenn W , journal=
-
[17]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[18]
1991 , publisher=
Probability with martingales , author=. 1991 , publisher=
1991
-
[19]
Tohoku Mathematical Journal, Second Series , volume=
Weighted sums of certain dependent random variables , author=. Tohoku Mathematical Journal, Second Series , volume=. 1967 , publisher=
1967
-
[20]
Le calcul des probabilites et ses applications , pages=
Application of the theory of martingales , author=. Le calcul des probabilites et ses applications , pages=. 1949 , publisher=
1949
-
[21]
2024 , eprint=
tinyBenchmarks: evaluating LLMs with fewer examples , author=. 2024 , eprint=
2024
-
[22]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[25]
Holden-Day , year=
Information and information stability of random variables and processes , author=. Holden-Day , year=
-
[26]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
A survey on in-context learning , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[27]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
2020
-
[28]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[29]
2000 , publisher=
Asymptotics in statistics: some basic concepts , author=. 2000 , publisher=
2000
-
[30]
Naeini, Mahdi Pakdaman and Cooper, Gregory and Hauskrecht, Milos , journal=
-
[31]
arXiv preprint arXiv:2305.19420 , year=
What and how does in-context learning learn? bayesian model averaging, parameterization, and generalization , author=. arXiv preprint arXiv:2305.19420 , year=
-
[32]
What learning algorithm is in-context learning? Investigations with linear models
What learning algorithm is in-context learning? investigations with linear models , author=. arXiv preprint arXiv:2211.15661 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2306.04891 , year=
In-context learning through the bayesian prism , author=. arXiv preprint arXiv:2306.04891 , year=
-
[34]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=
-
[35]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.