"Don't Say It!": Constraints, Compliance, and Communication when Language Models Play Taboo
Pith reviewed 2026-07-02 13:10 UTC · model grok-4.3
The pith
Language models balance Taboo rule compliance and description effectiveness differently by intervention type but remain weaker than humans at guessing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
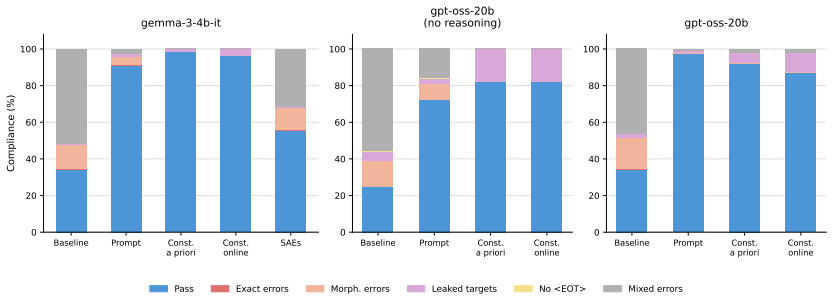
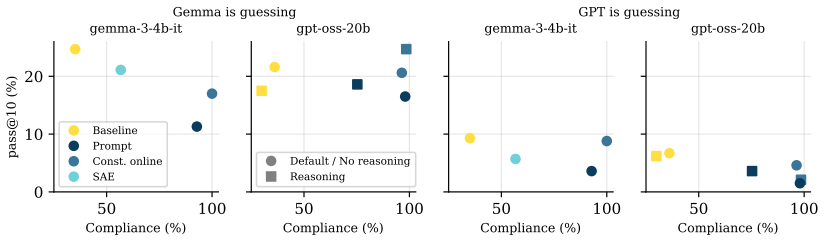
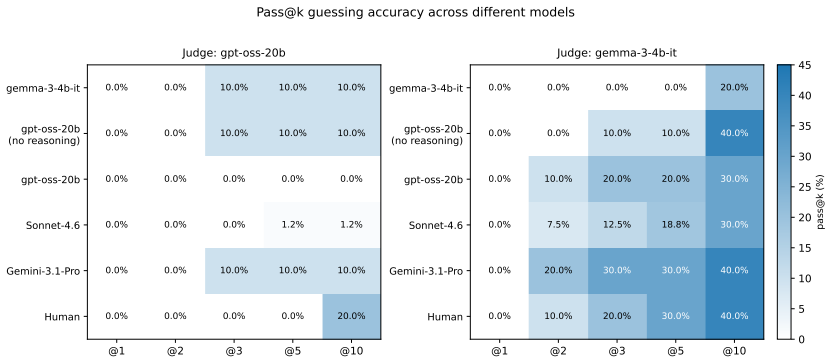
When language models play Taboo, compliance with forbidden-word rules and communicative effectiveness trade off differently across prompting, generation-time constraints, and internal representation manipulations, while models remain substantially weaker than humans as guessers, indicating that lexical grounding under constraint is an open challenge.
What carries the argument
The Taboo game evaluated through forbidden-word violation detection and LLM-as-a-judge scoring of how well descriptions evoke the target concept for human and machine guessers, with interventions applied at prompting, generation, and representation levels.
If this is right
- Compliance and communicative effectiveness trade off differently depending on whether constraints are applied via prompting, generation-time rules, or internal representation changes.
- Models perform substantially worse than humans when trying to guess the target word from constrained descriptions.
- Lexical grounding under constraint remains an open challenge for current language models.
Where Pith is reading between the lines
- Similar constraint-handling difficulties may appear in other tasks that require avoiding specific vocabulary while conveying meaning.
- Training approaches focused on explicit constraint satisfaction during generation could narrow the gap with human performance.
- The observed trade-offs suggest that internal model adjustments might offer different control levers than surface-level prompting.
Load-bearing premise
The LLM-as-a-judge metric and human comparisons accurately measure genuine communicative success rather than artifacts of the evaluation setup or prompt design.
What would settle it
A controlled experiment in which humans directly guess target words from the model's generated descriptions and their success rates are compared to both the LLM-as-a-judge scores and human player baselines.
Figures
read the original abstract
The game of Taboo requires describing a target word without using a set of forbidden words, so that other players can guess it. This deceptively simple task combines strict lexical constraints with the need for communicatively effective descriptions, making it a compelling playground for examining how LLMs navigate competing demands at inference time. We evaluate two open-weight models under conditions that intervene at progressively deeper levels of the generative process, from prompting to generation-time constraints to internal representations manipulations. We assess their outputs through forbidden word violation detection, LLM-as-a-judge measuring the degree to which generated descriptions successfully evoke the target concept for both human and machine guessers, and examining whether the strategies models adopt under constraint align with those of human players. Our results show that compliance with the rules of the game and communicative effectiveness trade off differently across conditions, and that models remain substantially weaker than humans as guessers, suggesting that lexical grounding under constraint is an open challenge for current language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates two open-weight language models on the Taboo game, which requires generating descriptions of a target word while avoiding a set of forbidden words. Interventions are applied at prompting, generation-time constraints, and internal representation levels. Outputs are assessed via forbidden-word violation detection and an LLM-as-a-judge metric that scores how successfully descriptions evoke the target for human and machine guessers; model strategies are also compared to those of human players. The central claims are that compliance and communicative effectiveness trade off differently across the tested conditions and that models remain substantially weaker than humans as guessers, indicating that lexical grounding under constraint is an open challenge.
Significance. If the results hold after addressing evaluation concerns, the work offers a structured empirical probe of how LLMs navigate competing lexical constraints and communicative goals at inference time. The progressive intervention design (prompting through representation manipulation) is a constructive way to isolate effects, and the direct human comparison provides a clear benchmark. No machine-checked proofs or parameter-free derivations are present, but the multi-condition empirical setup is a strength for testing claims about trade-offs.
major comments (1)
- [Abstract and Evaluation sections] The strongest claims—that compliance-effectiveness trade-offs differ across conditions and that models are substantially weaker than humans as guessers—rest entirely on the LLM-as-a-judge scores for communicative success. The manuscript reports no calibration of this judge against held-out human guessing data, no inter-annotator agreement with human raters, and no sensitivity analyses to prompt wording or forbidden-word list variations. Without such validation, it is impossible to determine whether the reported trade-offs and human-model gap reflect genuine differences in lexical grounding or artifacts of the automated metric.
minor comments (1)
- [Abstract] The abstract omits sample sizes, statistical tests used for the trade-off comparisons, the exact composition of forbidden-word lists, and the number of human participants, all of which are needed to assess the reliability of the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our evaluation approach. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and Evaluation sections] The strongest claims—that compliance-effectiveness trade-offs differ across conditions and that models are substantially weaker than humans as guessers—rest entirely on the LLM-as-a-judge scores for communicative success. The manuscript reports no calibration of this judge against held-out human guessing data, no inter-annotator agreement with human raters, and no sensitivity analyses to prompt wording or forbidden-word list variations. Without such validation, it is impossible to determine whether the reported trade-offs and human-model gap reflect genuine differences in lexical grounding or artifacts of the automated metric.
Authors: We concur that validating the LLM-as-a-judge metric against human data is essential for robust claims. Although our metric is used uniformly to compare conditions and the human-model gap is corroborated by direct human guessing performance and strategy alignment analyses, we did not include calibration, IAA, or sensitivity checks in the submitted manuscript. We will revise the manuscript to incorporate a calibration study on held-out human guessing data, report inter-annotator agreement, and perform sensitivity analyses on prompt wording and forbidden-word variations to ensure the results reflect true differences rather than metric artifacts. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential fitting
full rationale
The paper is an empirical study comparing LLMs on the Taboo game under various interventions. It reports results from violation detection, LLM-as-a-judge scoring, and human comparisons, with no equations, parameter fitting, derivations, or self-citation chains that reduce claims to inputs by construction. The reader's assessment of score 0.0 is consistent with the absence of any load-bearing mathematical or definitional steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sangati, A
F. Sangati, A. Pascucci, J. Monti, The challenge of the TV game la ghigliottina to NLP, in: S. M. Lukin (Ed.), Workshop on Games and Natural Language Processing, European Language Resources Association, Marseille, France, 2020, pp. 34–38. URL: https://aclanthology.org/2020.gamnlp-1.5/
2020
-
[2]
Manna, M
R. Manna, M. P. di Buono, J. Monti, Riddle me this: Evaluating large language models in solving word-based games, in: C. Madge, J. Chamberlain, K. Fort, U. Kruschwitz, S. Lukin (Eds.), Proceedings of the 10th Workshop on Games and Natural Language Processing @ LREC-COLING 2024, ELRA and ICCL, Torino, Italia, 2024, pp. 97–106. URL: https://aclanthology.org...
2024
-
[3]
Sarti, T
G. Sarti, T. Caselli, M. Nissim, A. Bisazza, Non verbis, sed rebus: Large language mod- els are weak solvers of Italian rebuses, in: F. Dell’Orletta, A. Lenci, S. Montemagni, R. Sprugnoli (Eds.), Proceedings of the Tenth Italian Conference on Computational Lin- guistics (CLiC-it 2024), CEUR Workshop Proceedings, Pisa, Italy, 2024, pp. 888–897. URL: https:...
2024
-
[4]
Sarti, T
G. Sarti, T. Caselli, A. Bisazza, M. Nissim, EurekaRebus - verbalized rebus solving with LLMs: A CALAMITA challenge, in: F. Dell’Orletta, A. Lenci, S. Montemagni, R. Sprugnoli (Eds.), Proceedings of the Tenth Italian Conference on Computational Linguistics (CLiC- it 2024), CEUR Workshop Proceedings, Pisa, Italy, 2024, pp. 1202–1208. URL: https:// aclantho...
2024
-
[5]
Ciaccio, G
C. Ciaccio, G. Sarti, A. Miaschi, F. Dell’Orletta, Crossword space: Latent manifold learning for Italian crosswords and beyond, in: C. Bosco, E. Jezek, M. Polignano, M. Sanguinetti (Eds.), Proceedings of the Eleventh Italian Conference on Computational Linguistics (CLiC-it 2025), CEUR Workshop Proceedings, Cagliari, Italy, 2025, pp. 245–255. URL: https://...
2025
-
[6]
Ciaccio, G
C. Ciaccio, G. Sarti, A. Miaschi, F. Dell’Orletta, M. Nissim, Cruciverb-IT at EVALITA 2026: Overview of the crossword solving in italian task, in: Proceedings of the 9th Evaluation Campaign of Natural Language Processing and Speech Tools for Italian (EVALITA 2026), volume 4195, CEUR Workshop Proceedings, Bari, Italy, 2026. URL: https://ceur-ws.org/ Vol-41...
2026
-
[7]
A. Y. Loredo Lopez, T. McDonald, A. Emami, NYT-connections: A deceptively simple text classification task that stumps system-1 thinkers, in: O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, S. Schockaert (Eds.), Proceedings of the 31st International Conference on Computational Linguistics, Association for Computational Linguistics, Abu D...
2025
-
[8]
Stephenson, M
M. Stephenson, M. Sidji, B. Ronval, Codenames as a benchmark for large language models,
- [9]
-
[10]
N. Horst, D. Mazzaccara, A. Schmidt, M. Sullivan, F. Momentè, L. Franceschetti, P. Sadler, S. Hakimov, A. Testoni, R. Bernardi, R. Fernández, A. Koller, O. Lemon, D. Schlangen, M. Giulianelli, A. Suglia, Playpen: An environment for exploring learning from dialogue game feedback, in: C. Christodoulopoulos, T. Chakraborty, C. Rose, V. Peng (Eds.), Pro- ceed...
-
[11]
Towards eliciting latent knowledge from llms with mechanistic interpretability, 2025 a
B. Cywiński, E. Ryd, S. Rajamanoharan, N. Nanda, Towards eliciting latent knowledge from llms with mechanistic interpretability, 2025. URL: https://arxiv.org/abs/2505.14352. arXiv:2505.14352
-
[12]
S. Yao, H. Chen, A. W. Hanjie, R. Yang, K. R. Narasimhan, COLLIE: Systematic construction of constrained text generation tasks, in: The Twelfth International Conference on Learning Representations, 2024. URL: https://openreview.net/forum?id=kxgSlyirUZ
2024
-
[13]
Z. R. Tam, C.-K. Wu, Y.-L. Tsai, C.-Y. Lin, H.-y. Lee, Y.-N. Chen, Let me speak freely? a study on the impact of format restrictions on large language model performance., in: F. Der- noncourt, D. Preoţiuc-Pietro, A. Shimorina (Eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, Association for Com...
-
[14]
Ciaccio, F
C. Ciaccio, F. Dell’orletta, A. Miaschi, G. Venturi, Controllable text generation to eval- uate linguistic abilities of Italian LLMs, in: F. Dell’Orletta, A. Lenci, S. Montemagni, R. Sprugnoli (Eds.), Proceedings of the Tenth Italian Conference on Computational Lin- guistics (CLiC-it 2024), CEUR Workshop Proceedings, Pisa, Italy, 2024, pp. 221–232. URL: h...
2024
-
[15]
Calderaro, A
S. Calderaro, A. Miaschi, F. Dell’Orletta, The OuLiBench benchmark: Formal constraints as a lens into LLM linguistic competence, in: C. Bosco, E. Jezek, M. Polignano, M. Sanguinetti (Eds.), Proceedings of the Eleventh Italian Conference on Computational Linguistics (CLiC-it 2025), CEUR Workshop Proceedings, Cagliari, Italy, 2025, pp. 124–133. URL: https:/...
2025
-
[16]
B. T. Willard, R. Louf, Efficient guided generation for large language models, 2023. URL: https://arxiv.org/abs/2307.09702.arXiv:2307.09702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
C. Hokamp, Q. Liu, Lexically constrained decoding for sequence generation using grid beam search, in: R. Barzilay, M.-Y. Kan (Eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Vancouver, Canada, 2017, pp. 1535–1546. URL: https:// aclanthology.o...
-
[18]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
H. Cunningham, A. Ewart, L. Riggs, R. Huben, L. Sharkey, Sparse autoencoders find highly interpretable features in language models, 2023. URL: https://arxiv.org/abs/2309.08600. arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Templeton, et al., Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet, Transformer Circuits Thread, 2024
A. Templeton, et al., Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet, Transformer Circuits Thread, 2024. URL: https://transformer-circuits. pub/2024/scaling-monosemanticity/index.html
2024
-
[20]
Team, Gemma 3 (2025)
G. Team, Gemma 3 (2025). URL: https://goo.gle/Gemma3Report
2025
-
[21]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.N
T. Lieberum, S. Rajamanoharan, A. Conmy, L. Smith, N. Sonnerat, V. Varma, J. Kramar, A. Dragan, R. Shah, N. Nanda, Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, in: Y. Belinkov, N. Kim, J. Jumelet, H. Mohebbi, A. Mueller, H. Chen (Eds.), Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for ...
-
[22]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, gpt-oss-120b & gpt-oss-20b model card, 2025. URL: https://arxiv.org/abs/2508. 10925.arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
M. Honnibal, I. Montani, S. Van Landeghem, A. Boyd, spaCy: Industrial-strength natural language processing in python, 2020. doi:10.5281/zenodo.1212303
-
[24]
S. Bird, E. Loper, NLTK: The natural language toolkit, in: Proceedings of the ACL Interactive Poster and Demonstration Sessions, Association for Computational Linguistics, Barcelona, Spain, 2004, pp. 214–217. URL: https://aclanthology.org/P04-3031/
2004
-
[25]
A. Bavaresco, R. Bernardi, L. Bertolazzi, D. Elliott, R. Fernández, A. Gatt, E. Ghaleb, M. Giulianelli, M. Hanna, A. Koller, A. Martins, P. Mondorf, V. Neplenbroek, S. Pezzelle, B. Plank, D. Schlangen, A. Suglia, A. K. Surikuchi, E. Takmaz, A. Testoni, LLMs instead of human judges? a large scale empirical study across 20 NLP evaluation tasks, in: W. Che, ...
-
[26]
URL: https://www.anthropic.com/claude-sonnet-4-6-system-card
Anthropic, System Card: Claude Sonnet 4.6, Technical Report, Anthropic, 2026. URL: https://www.anthropic.com/claude-sonnet-4-6-system-card
2026
-
[27]
URL: https:// deepmind.google/models/model-cards/gemini-3-1-pro/
Google DeepMind, Gemini 3.1 pro model card, Google DeepMind, 2026. URL: https:// deepmind.google/models/model-cards/gemini-3-1-pro/
2026
-
[28]
Kahneman, Thinking, Fast and Slow, Farrar, Straus and Giroux, New York, 2011
D. Kahneman, Thinking, Fast and Slow, Farrar, Straus and Giroux, New York, 2011
2011
-
[29]
what a misery
O. Skean, M. R. Arefin, D. Zhao, N. N. Patel, J. Naghiyev, Y. LeCun, R. Shwartz-Ziv, Layer by layer: Uncovering hidden representations in language models, in: Forty-second International Conference on Machine Learning, 2025. URL: https://openreview.net/forum? id=WGXb7UdvTX. A. Appendix A: prompt details, generation parameters and repetition penalty This ap...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.