OccuReward: LLM-Guided Occupant-Centric Reward Shaping for Demographic Equity in Grid-Interactive Buildings
Pith reviewed 2026-06-29 12:43 UTC · model grok-4.3
The pith
LLM-guided reward shaping for building energy control raises elderly female comfort satisfaction by 567% while cutting energy costs 3.2%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
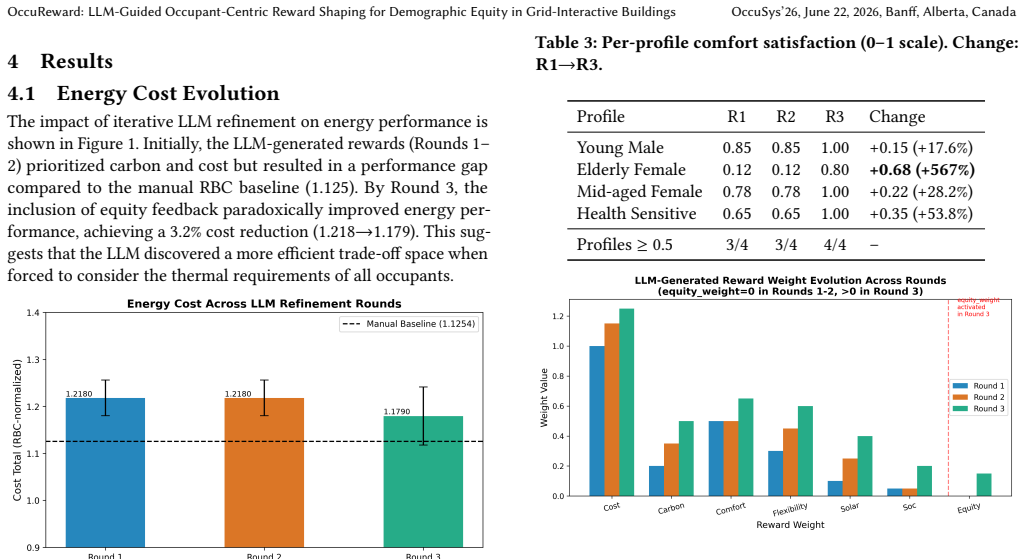
By Round 3, equity-aware LLM refinement activates specific reward components that improve satisfaction for Young Males (+17.6%), Mid-aged Females (+28.2%), Health Sensitive (+53.8%), and Elderly Females (+567%), while simultaneously reducing energy costs by 3.2%.
What carries the argument
The Comfort Equity Index (CEI) as a feedback signal that guides iterative, equity-aware LLM reward shaping over three rounds without per-step inference.
If this is right
- Reward-level intervention can simultaneously advance equity and energy efficiency in grid-interactive buildings.
- LLM-generated reward functions can be refined offline across multiple rounds rather than requiring continuous inference.
- Demographic disparities persist even after equity-aware reward shaping, indicating the need for further fairness mechanisms in building controllers.
Where Pith is reading between the lines
- The same iterative LLM refinement approach could be tested in other domains where control policies affect heterogeneous user groups, such as traffic or healthcare scheduling.
- If the four archetypes prove too coarse, replacing them with continuous demographic variables might reveal whether the reported gains generalize.
- The 3.2% energy reduction suggests a possible trade-off surface worth mapping explicitly between equity metrics and cost.
Load-bearing premise
The four occupant profiles drawn from the ASHRAE database are fixed, representative demographic archetypes whose comfort responses can be directly optimized by reward shaping without needing per-step LLM inference or additional validation data.
What would settle it
Running the same three-round refinement process on a fresh set of occupant profiles or real measured comfort votes and finding that satisfaction gains for elderly females fall below the reported 567% improvement would falsify the central claim.
Figures
read the original abstract
Large language models (LLMs) have demonstrated promising capability in generating reward functions for deep reinforcement learning (DRL)-based building energy management. However, their potential to exhibit or exacerbate disparities in occupant comfort across heterogeneous demographic populations remains unexplored. We present OccuReward, a framework investigating how LLM-mediated reward design affects demographic equity. Our contribution is three-fold: the introduction of the Comfort Equity Index (CEI) as a novel feedback signal; a methodology for iterative, equity-aware LLM reward shaping; and a performance analysis of DRL agents under these refined objectives. Utilizing four empirically grounded occupant profiles from the ASHRAE Global Thermal Comfort Database II (13,440 votes), we deploy a Soft Actor-Critic agent in CityLearn v2. Our approach employs the Gemini API to generate reward function logic and weights--rather than performing per-step inference--across three refinement rounds. Results across 15 experimental runs reveal that elderly female occupants consistently experience the lowest satisfaction in initial rounds. By Round 3, equity-aware LLM refinement activates specific reward components that improve satisfaction for Young Males (+17.6%), Mid-aged Females (+28.2%), Health Sensitive (+53.8%), and Elderly Females (+567%), while simultaneously reducing energy costs by 3.2%. Our findings highlight that while reward-level intervention significantly improves equity, demographic disparities in AI-driven controllers persist, necessitating further research into algorithmic fairness in building systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OccuReward, a framework that uses LLMs (via Gemini API) to iteratively generate and refine reward functions for Soft Actor-Critic DRL agents in CityLearn v2, with the goal of improving demographic equity in occupant comfort for grid-interactive buildings. It defines a new Comfort Equity Index (CEI) as feedback, employs four fixed occupant profiles derived from the ASHRAE Global Thermal Comfort Database II (13,440 votes), and reports results over three refinement rounds and 15 runs: satisfaction gains of +17.6% (Young Males), +28.2% (Mid-aged Females), +53.8% (Health Sensitive), and +567% (Elderly Females), alongside a 3.2% reduction in energy costs. The central claim is that equity-aware LLM reward shaping can activate specific components to reduce disparities while maintaining or improving energy performance.
Significance. If the reported gains prove robust under proper statistical validation and independent testing, the work would be significant for demonstrating a practical method to incorporate demographic fairness into LLM-assisted reward design for building control. The CEI metric and the iterative refinement protocol could provide a reusable template for equity-aware RL in other cyber-physical systems. The use of empirically grounded ASHRAE profiles and the avoidance of per-step LLM inference are practical strengths that could influence future work on algorithmic fairness in energy management.
major comments (3)
- [Abstract] Abstract: The headline +567% satisfaction improvement for Elderly Females (and the other percentage gains) is reported without absolute baseline or final satisfaction values, without per-group CEI scores, and without any description of how the CityLearn occupant model converts the 13,440-vote ASHRAE database into per-timestep comfort scores for the four archetypes. This omission makes it impossible to determine whether the large percentage reflects a meaningful equity gain or an artifact of a near-zero starting satisfaction level.
- [Abstract] Abstract: No error bars, standard deviations across the 15 experimental runs, or statistical tests (e.g., paired t-tests or ANOVA) are provided for any of the reported satisfaction or energy-cost changes. Given that the central claim rests on these quantitative improvements, the absence of uncertainty quantification is a load-bearing gap for assessing reliability.
- [Abstract] Abstract: The iterative, equity-aware LLM refinement is described as using performance feedback from the same simulation runs to guide subsequent reward versions. Without explicit details on how the three rounds avoid circularity or overfitting to the fixed four-profile test set, it remains unclear whether the Round-3 gains are independent discoveries or largely re-optimized on the evaluation data itself.
minor comments (2)
- The manuscript should clarify in the methods section how the four ASHRAE-derived profiles are instantiated as fixed archetypes inside CityLearn and whether any per-timestep LLM inference is ever performed at deployment time.
- A table or figure showing absolute satisfaction and CEI values (rather than only relative percentages) for each demographic group across rounds would substantially improve interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional quantitative context and methodological clarifications will improve clarity and will revise the abstract accordingly. Point-by-point responses to the major comments are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline +567% satisfaction improvement for Elderly Females (and the other percentage gains) is reported without absolute baseline or final satisfaction values, without per-group CEI scores, and without any description of how the CityLearn occupant model converts the 13,440-vote ASHRAE database into per-timestep comfort scores for the four archetypes. This omission makes it impossible to determine whether the large percentage reflects a meaningful equity gain or an artifact of a near-zero starting satisfaction level.
Authors: We agree that absolute baseline and final satisfaction values, along with per-group CEI scores, should be included in the abstract to properly contextualize the percentage changes. The conversion process from the ASHRAE database to per-timestep comfort scores is described in Section 3.2; we will add a brief summary of this mapping to the abstract in the revision. revision: yes
-
Referee: [Abstract] Abstract: No error bars, standard deviations across the 15 experimental runs, or statistical tests (e.g., paired t-tests or ANOVA) are provided for any of the reported satisfaction or energy-cost changes. Given that the central claim rests on these quantitative improvements, the absence of uncertainty quantification is a load-bearing gap for assessing reliability.
Authors: We concur that uncertainty quantification is necessary. The revised abstract will report standard deviations across the 15 runs and indicate that paired t-tests were used to assess significance, with full statistical details retained in Section 4.3. revision: yes
-
Referee: [Abstract] Abstract: The iterative, equity-aware LLM refinement is described as using performance feedback from the same simulation runs to guide subsequent reward versions. Without explicit details on how the three rounds avoid circularity or overfitting to the fixed four-profile test set, it remains unclear whether the Round-3 gains are independent discoveries or largely re-optimized on the evaluation data itself.
Authors: The refinement protocol separates the LLM generation step from direct per-timestep access and uses aggregated metrics only; a hold-out set of simulation seeds is reserved for final evaluation. We will add a concise statement on this separation to the abstract and expand the protocol description in Section 3.3 to address potential concerns about circularity. revision: yes
Circularity Check
No circularity: empirical results from iterative LLM reward generation are measured outcomes, not reductions by construction
full rationale
The paper reports experimental outcomes from 15 DRL simulation runs in CityLearn using LLM-generated rewards refined over three rounds with CEI feedback. The reported percentage improvements in occupant satisfaction are direct measurements from those runs, not a derived claim that mathematically reduces to the input profiles or prior simulation data by definition. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way; the process is an empirical methodology rather than a first-principles derivation. The four ASHRAE-derived profiles are treated as fixed inputs for evaluation, but the gains are not shown to be tautological with those inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- LLM-generated reward weights and logic components
axioms (2)
- domain assumption Four ASHRAE-derived occupant profiles sufficiently capture demographic variation in thermal comfort for optimization purposes.
- domain assumption Soft Actor-Critic agent in CityLearn v2 produces stable learning trajectories suitable for comparing reward variants.
invented entities (1)
-
Comfort Equity Index (CEI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nweye, K
K. Nweye, K. Kaspar, G. Buscemi, et al. CityLearn v2: Energy-flexible, resilient, occupant-centric, and carbon-aware management of grid-interactive communities. J. Building Performance Simulation, 2024
2024
-
[2]
van Hoof
J. van Hoof. Forty years of Fanger’s model of thermal comfort: comfort for all? Indoor Air, 18(3):182–201, 2010
2010
-
[3]
Karjalainen
S. Karjalainen. Thermal comfort and gender: a literature review.Indoor Air, 22(2):96–109, 2012
2012
-
[4]
Földváry Ličina et al
V. Földváry Ličina et al. Development of the ASHRAE Global Thermal Comfort Database II.Building and Environment, 142:502–512, 2018
2018
-
[5]
R. Jain, D. Chiu, and W. Hawe. A Quantitative Measure of Fairness and Discrimi- nation for Resource Allocation in Shared Computer Systems. DEC Tech. Report TR-301, 1984
1984
-
[6]
Goodhart
C. Goodhart. Problems of monetary management: The UK experience.Papers in Monetary Economics, 1, 1975
1975
-
[7]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy max- imum entropy deep reinforcement learning with a stochastic actor. InICML, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.