Two-Action Apple Tasting with Switching Costs
Pith reviewed 2026-06-28 11:31 UTC · model grok-4.3
The pith
In two-action apple tasting with switching costs the minimax regret against an oblivious adversary is Theta of sqrt(T).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
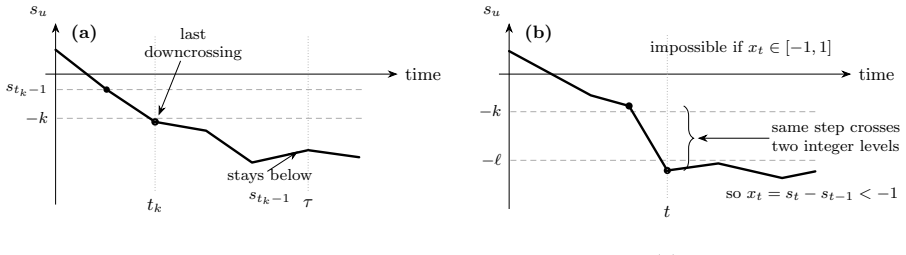
In the normalized formulation the learner repeatedly chooses either the revealing action (reward 0, reveals x_t in [-1,1]) or the blind action (reward x_t, reveals nothing) and pays one unit per switch; regret is measured against the single best fixed action in hindsight. The paper proves that the oblivious minimax expected regret R_T^* satisfies 1/(2 sqrt(3)) sqrt(T) less than or equal to R_T^* less than or equal to 2 sqrt(3) sqrt(T).
What carries the argument
The two-action apple-tasting feedback graph with unit switching costs, analyzed via direct construction of a strategy and a matching lower-bound argument for the oblivious adversary.
If this is right
- The two-action apple-tasting graph is not the source of an Omega(T^{2/3}) lower bound for feedback graphs with switching costs.
- Specialized algorithms for this exact setting achieve O(sqrt(T)) regret, improving on the general T^{2/3} guarantee.
- Any complete classification of feedback graphs under switching costs must locate its hard instances in other graph structures.
- The gap between oblivious and adaptive adversaries remains open for this problem.
Where Pith is reading between the lines
- The result suggests that certain two-action partial-feedback problems may escape the switching-cost penalty entirely, inviting checks on nearby graphs that differ only in reward revelation rules.
- It raises the question whether the same sqrt(T) rate holds when the adversary is allowed to adapt, which the paper leaves unresolved.
- A natural extension is to ask whether adding more than two actions restores the T^{2/3} barrier or keeps the rate at sqrt(T).
Load-bearing premise
The adversary commits to the entire sequence of hidden values x_t in advance and never adapts to the learner's observed choices.
What would settle it
A concrete sequence of x_t values (or a family of sequences) for which the expected regret of any learner exceeds the stated upper bound constant times sqrt(T) for sufficiently large T, or falls below the lower-bound constant.
Figures
read the original abstract
We study the two-action apple-tasting problem with switching costs against an oblivious adversary. In an equivalent normalized formulation, at each round the learner chooses between a revealing action and a blind action: the revealing action gives reward $0$ and reveals the hidden value $x_t\in[-1,1]$ of the blind action; the blind action gives reward $x_t$ but reveals nothing. The learner pays one unit whenever they switches actions, and regret is measured against the best fixed action in hindsight. General feedback-graph algorithms with switching costs give $\widetilde O(T^{2/3})$ regret guarantees for this problem. The two-action apple-tasting graph was the natural candidate for the missing $\Omega(T^{2/3})$ obstruction in the switching-cost classification: such a lower bound would have transferred to a large family of still-unclassified feedback graphs. We prove that this obstruction is not there: the oblivious minimax expected regret for this problem satisfies \[ \frac{1}{2\sqrt3}\cdot\sqrt T \le R_T^\star \le 2\sqrt{3}\cdot \sqrt{T}. \]
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the two-action apple-tasting problem with switching costs against an oblivious adversary. In the normalized formulation, the learner chooses at each round between a revealing action (reward 0, reveals x_t ∈ [-1,1]) and a blind action (reward x_t, no revelation), incurring a unit cost on switches; regret is measured against the best fixed action in hindsight. The central claim is that the oblivious minimax expected regret satisfies 1/(2√3)·√T ≤ R_T^* ≤ 2√3·√T, establishing matching Θ(√T) bounds via an explicit algorithm for the upper bound and a distributional construction for the lower bound.
Significance. If the result holds, it is significant for the classification of feedback graphs with switching costs: it shows that the two-action apple-tasting graph does not furnish the anticipated Ω(T^{2/3}) obstruction, as general feedback-graph algorithms only guarantee Õ(T^{2/3}). The paper supplies self-contained, matching bounds that correctly incorporate the unit switching cost and measure regret against the best fixed action, using a potential-function analysis for the upper bound and the Yao principle for the lower bound.
minor comments (2)
- [§3] §3, Algorithm 1: the potential function Φ_t is defined with a specific scaling constant; a brief remark on how this constant is chosen to balance the switching penalty and the estimation error would improve readability.
- [§4] §4, Lemma 4.2: the distributional construction for the lower bound uses a specific bias parameter; clarifying why this bias yields exactly the 1/(2√3) factor (rather than a looser constant) would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and their recommendation to accept. We appreciate the recognition of the result's significance for the classification of feedback graphs with switching costs.
Circularity Check
No significant circularity; bounds derived independently via algorithm and Yao construction
full rationale
The central claim establishes matching Θ(√T) oblivious minimax regret bounds. The upper bound follows from an explicit algorithm analyzed via potential functions in the normalized two-action setting; the lower bound follows from an explicit distributional construction over sequences and application of Yao's principle. Neither reduces to a fitted parameter, self-definition, or load-bearing self-citation. The analysis incorporates the unit switching cost and measures regret against the best fixed action in hindsight, remaining self-contained against the problem formulation without external unverified premises.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard definition of minimax expected regret R_T^* against an oblivious adversary in the normalized revealing/blind action setup
Reference graph
Works this paper leans on
-
[1]
Online learning with feedback graphs: Beyond bandits
Noga Alon, Nicolo Cesa-Bianchi, Ofer Dekel, and Tomer Koren. Online learning with feedback graphs: Beyond bandits. InConference on Learning Theory, pages 23–35. PMLR, 2015
2015
-
[2]
Bandits with feedback graphs and switching costs.Advances in Neural Information Processing Systems, 32, 2019
Raman Arora, Teodor Vanislavov Marinov, and Mehryar Mohri. Bandits with feedback graphs and switching costs.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[3]
Regret minimization under partial monitoring.Mathematics of Operations Research, 31(3):562–580, 2006
Nicol` o Cesa-Bianchi, G´ abor Lugosi, and Gilles Stoltz. Regret minimization under partial monitoring.Mathematics of Operations Research, 31(3):562–580, 2006
2006
-
[4]
Bandits with switching costs: T 2/3 regret
Ofer Dekel, Jian Ding, Tomer Koren, and Yuval Peres. Bandits with switching costs: T 2/3 regret. InProceedings of the forty-sixth annual ACM symposium on Theory of computing, pages 459–467, 2014. 18
2014
-
[5]
Regret minimization for online buffering problems using the weighted majority algorithm
Sascha Geulen, Berthold V¨ ocking, and Melanie Winkler. Regret minimization for online buffering problems using the weighted majority algorithm. InProceedings of the 23rd Annual Conference on Learning Theory, pages 132–143, 2010
2010
-
[6]
Helmbold, Nick Littlestone, and Philip M
David P. Helmbold, Nick Littlestone, and Philip M. Long. Apple tasting and nearly one-sided learning. InProceedings of the 33rd Annual Symposium on Foundations of Computer Science, pages 493–502. IEEE Computer Society, 1992
1992
-
[7]
Apple tasting.Information and Computation, 161(2):85–139, 2000
David P Helmbold, Nicholas Littlestone, and Philip M Long. Apple tasting.Information and Computation, 161(2):85–139, 2000
2000
-
[8]
Efficient algorithms for online decision problems
Adam Kalai and Santosh Vempala. Efficient algorithms for online decision problems. Journal of Computer and System Sciences, 71(3):291–307, 2005
2005
-
[9]
From bandits to experts: On the value of side-observations
Shie Mannor and Ohad Shamir. From bandits to experts: On the value of side-observations. Advances in neural information processing systems, 24, 2011
2011
-
[10]
Apple tasting: Combinatorial dimensions and minimax rates
Vinod Raman, Unique Subedi, Ananth Raman, and Ambuj Tewari. Apple tasting: Combinatorial dimensions and minimax rates. InThe Thirty Seventh Annual Conference on Learning Theory, pages 4358–4380. PMLR, 2024. 19
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.