LEViL: Label-Efficient Video Learning via Zero-Shot Distillation over VLM-Generated Pseudo-Label Spaces
Pith reviewed 2026-06-26 14:37 UTC · model grok-4.3
The pith
A framework pretrains video encoders without any manual labels by distilling zero-shot targets from vision-language model descriptions of unlabeled videos, then adapts via target-label-aware fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
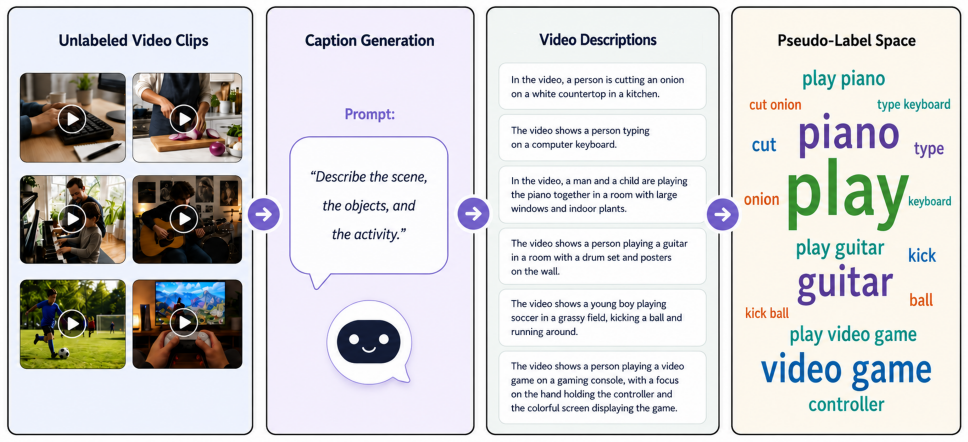
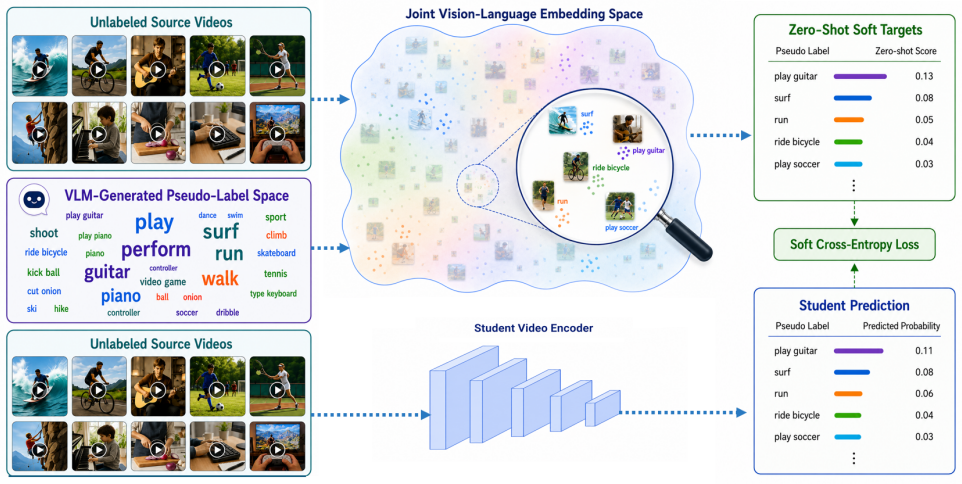
The LEViL framework performs annotation-free pretraining by having a vision-language model generate textual descriptions of unlabeled videos, constructing an interpretable semantic pseudo-label space from those descriptions, and training a student video encoder via zero-shot soft targets produced by a frozen video-language model over the same space; downstream adaptation then mixes supervised learning on labeled target videos with zero-shot distillation over the true target label set, producing representations that outperform semi-supervised video action recognition baselines on UCF101 and HMDB51 across all tested limited-label settings and serve as effective initializations for full-data fi
What carries the argument
Zero-shot distillation over a VLM-generated semantic pseudo-label space, which supplies soft training targets during annotation-free pretraining and is reused in target-label-set-aware fine-tuning.
If this is right
- Reliance on large manually labeled source datasets for video pretraining can be removed.
- Transferable video representations can be obtained from a comparatively small pool of unlabeled videos.
- Performance gains appear consistently across all tested limited-label regimes on UCF101 and HMDB51.
- The pretrained encoder supplies a stronger starting point for subsequent full-data fine-tuning than random initialization.
Where Pith is reading between the lines
- The same pseudo-label construction step might be applied to other video tasks such as temporal action localization if the generated descriptions capture timing information.
- Domain shift between the unlabeled pretraining videos and the target dataset could be further reduced by filtering the pseudo-label space to emphasize categories known to appear in the target label set.
- Scaling the unlabeled pretraining pool while keeping the VLM fixed would test whether the current gains are limited by data volume or by the quality of the pseudo-label space itself.
Load-bearing premise
Textual descriptions produced by a vision-language model for unlabeled videos can be turned into a semantic pseudo-label space that yields useful zero-shot soft targets for training a video encoder.
What would settle it
Run the pretraining stage on a collection of videos whose VLM descriptions produce a pseudo-label space with no semantic alignment to action categories, then measure whether downstream accuracy still exceeds standard semi-supervised baselines on UCF101 or HMDB51.
Figures

read the original abstract
Supervised video pretraining is a common transfer learning practice for improving downstream action recognition performance. However, it requires large-scale labeled source datasets, and the effectiveness of the learned initialization is influenced by the similarity between the source and target domains. Constructing such labeled pretraining datasets for different target domains is costly and difficult to scale. To address these limitations, this study proposes a label-efficient video learning framework that combines annotation-free video pretraining with target-label-set-aware fine-tuning. During pretraining, a vision-language model (VLM) generates textual descriptions of unlabeled videos, which are processed to construct an interpretable semantic pseudo-label space. A frozen video-language model then produces zero-shot soft target distributions over this space, allowing a student video encoder to learn semantically rich representations without manual source annotations. During downstream adaptation, target-label-set-aware fine-tuning combines supervised learning from labeled target videos with zero-shot distillation over the actual target label set, helping preserve VLM-derived semantic guidance while adapting the pretrained encoder to the target task. Experiments on UCF101 and HMDB51 show that the proposed framework outperforms the compared semi-supervised video action recognition methods across all evaluated limited-label regimes. Moreover, the annotation-free pretraining stage learns transferable representations that provide an effective initialization for full-data fine-tuning, despite relying on a comparatively modest unlabeled pretraining pool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LEViL, a label-efficient video learning framework combining annotation-free pretraining with target-label-set-aware fine-tuning. In pretraining, a VLM generates textual descriptions of unlabeled videos to build an interpretable semantic pseudo-label space; a frozen video-language model then supplies zero-shot soft targets for distilling a student video encoder. Downstream, supervised learning on target labels is combined with zero-shot distillation over the actual target label set. Experiments on UCF101 and HMDB51 are reported to outperform compared semi-supervised video action recognition methods across limited-label regimes, with the pretraining stage also providing effective initialization for full-data fine-tuning despite a modest unlabeled pool.
Significance. If the empirical claims hold, the work demonstrates a practical route to domain-adaptable video pretraining that avoids large labeled source datasets and mitigates domain-shift issues by leveraging VLM-derived semantic structure. The explicit use of a modest unlabeled pretraining pool and the preservation of VLM guidance during fine-tuning are pragmatic strengths that could influence label-efficient pipelines in action recognition and related video tasks.
minor comments (2)
- Abstract: the claim of outperformance would be strengthened by naming the specific semi-supervised baselines and reporting at least one quantitative result (e.g., accuracy delta at a given label fraction) rather than a qualitative statement.
- The construction of the pseudo-label space from VLM descriptions is described at a high level; a short illustrative example or pseudocode in §3 would improve reproducibility without altering the central pipeline.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of LEViL, the recognition of its pragmatic strengths in avoiding large labeled source datasets, and the recommendation for minor revision. We appreciate the constructive framing of the work's potential influence on label-efficient video pipelines.
Circularity Check
No significant circularity
full rationale
The paper describes a pipeline that ingests external VLM outputs to build a pseudo-label space and then performs zero-shot distillation; no equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or result to the method's own inputs by construction. The abstract and described framework contain no self-definitional steps, no renaming of known results, and no load-bearing uniqueness theorems imported from the authors' prior work. The central claim therefore remains independent of internal circular fitting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The kinetics human action video dataset,
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsevet al., “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
Pith/arXiv arXiv 2017
-
[2]
Large-scale video classification with convolutional neural networks,
A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, “Large-scale video classification with convolutional neural networks,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2014, pp. 1725–1732
2014
-
[3]
Transfer learning for video action recognition: A comparative overview of weight initialization strategies: A. c ¸elik,
A. C ¸ elik, “Transfer learning for video action recognition: A comparative overview of weight initialization strategies: A. c ¸elik,”Signal, Image and Video Processing, vol. 19, no. 15, p. 1306, 2025
2025
-
[4]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[5]
Danet: Semi-supervised differentiated auxiliaries guided network for video action recognition,
G. Gao, Z. Liu, G. Zhang, J. Li, and A. K. Qin, “Danet: Semi-supervised differentiated auxiliaries guided network for video action recognition,” Neural Networks, vol. 158, pp. 121–131, 2023
2023
-
[6]
Distinit: Learning video representations without a single labeled video,
R. Girdhar, D. Tran, L. Torresani, and D. Ramanan, “Distinit: Learning video representations without a single labeled video,” inProceedings of the IEEE/cvf international conference on computer vision, 2019, pp. 852–861
2019
-
[7]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[8]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. Le, Y .-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 4904–4916
2021
-
[9]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdul- mohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa et al., “Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[10]
Frozen in time: A joint video and image encoder for end-to-end retrieval,
M. Bain, A. Nagrani, G. Varol, and A. Zisserman, “Frozen in time: A joint video and image encoder for end-to-end retrieval,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 1728–1738
2021
-
[11]
A clip-hitchhiker’s guide to long video retrieval,
——, “A clip-hitchhiker’s guide to long video retrieval,”arXiv preprint arXiv:2205.08508, 2022
arXiv 2022
-
[12]
Fine- tuned clip models are efficient video learners,
H. Rasheed, M. U. Khattak, M. Maaz, S. Khan, and F. S. Khan, “Fine- tuned clip models are efficient video learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 6545–6554
2023
-
[13]
Vl-jepa: Joint em- bedding predictive architecture for vision-language,
D. Chen, M. Shukor, T. Moutakanni, W. Chung, J. Yu, T. Kasarla, Y . Bang, A. Bolourchi, Y . LeCun, and P. Fung, “Vl-jepa: Joint em- bedding predictive architecture for vision-language,”arXiv preprint arXiv:2512.10942, 2025
arXiv 2025
-
[14]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynoldset al., “Flamingo: a visual language model for few-shot learning,”Advances in neural information processing systems, vol. 35, pp. 23 716–23 736, 2022
2022
-
[15]
Qwen-vl: A frontier large vision-language model with versatile abilities,
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,”arXiv preprint arXiv:2308.12966, vol. 1, no. 2, p. 3, 2023
Pith/arXiv arXiv 2023
-
[16]
Grounding multimodal large language models to the world,
Z. Peng, W. Wang, L. Dong, Y . Hao, S. Huang, S. Ma, Q. Ye, and F. Wei, “Grounding multimodal large language models to the world,” in International Conference on Learning Representations, vol. 2024, 2024, pp. 51 575–51 598
2024
-
[17]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,”Advances in neural information processing systems, vol. 36, pp. 49 250–49 267, 2023
2023
-
[18]
Internvideo2: Scaling foundation models for multimodal video understanding,
Y . Wang, K. Li, X. Li, J. Yu, Y . He, G. Chen, B. Pei, R. Zheng, Z. Wang, Y . Shiet al., “Internvideo2: Scaling foundation models for multimodal video understanding,” inEuropean conference on computer vision. Springer, 2024, pp. 396–416
2024
-
[19]
Videochat: Chat-centric video understanding,
K. Li, Y . He, Y . Wang, Y . Li, W. Wang, P. Luo, Y . Wang, L. Wang, and Y . Qiao, “Videochat: Chat-centric video understanding,”Science China Information Sciences, vol. 68, no. 10, p. 200102, 2025
2025
-
[20]
Video-chatgpt: Towards detailed video understanding via large vision and language models,
M. Maaz, H. Rasheed, S. Khan, and F. Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 12 585– 12 602
2024
-
[21]
Video-llama: An instruction-tuned audio- visual language model for video understanding,
H. Zhang, X. Li, and L. Bing, “Video-llama: An instruction-tuned audio- visual language model for video understanding,” inProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, 2023, pp. 543–553
2023
-
[22]
Speednet: Learning the speediness in videos,
S. Benaim, A. Ephrat, O. Lang, I. Mosseri, W. T. Freeman, M. Ru- binstein, M. Irani, and T. Dekel, “Speednet: Learning the speediness in videos,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9922–9931
2020
-
[23]
Self-supervised spatiotem- poral feature learning via video rotation prediction,
L. Jing, X. Yang, J. Liu, and Y . Tian, “Self-supervised spatiotem- poral feature learning via video rotation prediction,”arXiv preprint arXiv:1811.11387, 2018
Pith/arXiv arXiv 2018
-
[24]
Self-supervised video representation learning with space-time cubic puzzles,
D. Kim, D. Cho, and I. S. Kweon, “Self-supervised video representation learning with space-time cubic puzzles,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 8545– 8552
2019
-
[25]
Self- supervised spatiotemporal learning via video clip order prediction,
D. Xu, J. Xiao, Z. Zhao, J. Shao, D. Xie, and Y . Zhuang, “Self- supervised spatiotemporal learning via video clip order prediction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10 334–10 343
2019
-
[26]
Videomoco: Contrastive video representation learning with temporally adversarial examples,
T. Pan, Y . Song, T. Yang, W. Jiang, and W. Liu, “Videomoco: Contrastive video representation learning with temporally adversarial examples,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 205–11 214
2021
-
[27]
Tclr: Temporal con- trastive learning for video representation,
I. Dave, R. Gupta, M. N. Rizve, and M. Shah, “Tclr: Temporal con- trastive learning for video representation,”Computer Vision and Image Understanding, vol. 219, p. 103406, 2022
2022
-
[28]
Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,
Z. Tong, Y . Song, J. Wang, and L. Wang, “Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,” Advances in neural information processing systems, vol. 35, pp. 10 078– 10 093, 2022
2022
-
[29]
Motionmae: Self-supervised video representation learning with motion-aware masked autoencoders
H. Yang, D. Huang, B. Wen, J. Wu, H. Yao, Y . Jiang, X. Zhu, and Z. Yuan, “Motionmae: Self-supervised video representation learning with motion-aware masked autoencoders.” inBMVC, 2024
2024
-
[30]
Videossl: Semi- supervised learning for video classification,
L. Jing, T. Parag, Z. Wu, Y . Tian, and H. Wang, “Videossl: Semi- supervised learning for video classification,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 1110–1119
2021
-
[31]
Feature distillation from vision-language model for semisupervised action classification,
A. Celik, A. K ¨uc ¸¨ukmanisa, and O. Urhan, “Feature distillation from vision-language model for semisupervised action classification,”Turkish Journal of Electrical Engineering and Computer Sciences, vol. 31, no. 6, pp. 1129–1145, 2023
2023
-
[32]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Luet al., “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 24 185–24 198
2024
-
[33]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites,
Z. Chen, W. Wang, H. Tian, S. Ye, Z. Gao, E. Cui, W. Tong, K. Hu, J. Luo, Z. Maet al., “How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites,”Science China Information Sciences, vol. 67, no. 12, p. 220101, 2024
2024
-
[34]
spaCy: Industrial-strength natural language processing in python,
M. Honnibal, I. Montani, S. V . Landeghem, and A. Boyd, “spaCy: Industrial-strength natural language processing in python,” 2020
2020
-
[35]
ChatGPT,
OpenAI, “ChatGPT,” [Online]. Available: https://chatgpt.com/, 2026, accessed: Jun. 18, 2026
2026
-
[36]
Cross-model pseudo-labeling for semi-supervised action recognition,
Y . Xu, F. Wei, X. Sun, C. Yang, Y . Shen, B. Dai, B. Zhou, and S. Lin, “Cross-model pseudo-labeling for semi-supervised action recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2959–2968
2022
-
[37]
Learning from temporal gradient for semi-supervised action recognition,
J. Xiao, L. Jing, L. Zhang, J. He, Q. She, Z. Zhou, A. Yuille, and Y . Li, “Learning from temporal gradient for semi-supervised action recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3252–3262
2022
-
[38]
Multiview pseudo-labeling for semi-supervised learning from video,
B. Xiong, H. Fan, K. Grauman, and C. Feichtenhofer, “Multiview pseudo-labeling for semi-supervised learning from video,” inProceed- ings of the IEEE/CVF international conference on computer vision, 2021, pp. 7209–7219
2021
-
[39]
Learn2augment: learning to composite videos for data augmentation in action recognition,
S. N. Gowda, M. Rohrbach, F. Keller, and L. Sevilla-Lara, “Learn2augment: learning to composite videos for data augmentation in action recognition,” inEuropean conference on computer vision. Springer, 2022, pp. 242–259
2022
-
[40]
Learning representational invariances for data-efficient action recognition,
Y . Zou, J. Choi, Q. Wang, and J.-B. Huang, “Learning representational invariances for data-efficient action recognition,”Computer Vision and Image Understanding, vol. 227, p. 103597, 2023
2023
-
[41]
Timebalance: Temporally-invariant and temporally-distinctive video representations for semi-supervised action recognition,
I. R. Dave, M. N. Rizve, C. Chen, and M. Shah, “Timebalance: Temporally-invariant and temporally-distinctive video representations for semi-supervised action recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2341–2352
2023
-
[42]
Would mega- scale datasets further enhance spatiotemporal 3d cnns?
H. Kataoka, T. Wakamiya, K. Hara, and Y . Satoh, “Would mega- scale datasets further enhance spatiotemporal 3d cnns?”arXiv preprint arXiv:2004.04968, 2020
arXiv 2004
-
[43]
Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics,
J. Wang, J. Jiao, L. Bao, S. He, Y . Liu, and W. Liu, “Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4006–4015
2019
-
[44]
Self-supervised video representation learning by pace prediction,
J. Wang, J. Jiao, and Y .-H. Liu, “Self-supervised video representation learning by pace prediction,” inEuropean conference on computer vision. Springer, 2020, pp. 504–521
2020
-
[45]
Contrastive spatio-temporal pretext learning for self- supervised video representation,
Y . Zhang, L.-M. Po, X. Xu, M. Liu, Y . Wang, W. Ou, Y . Zhao, and W.-Y . Yu, “Contrastive spatio-temporal pretext learning for self- supervised video representation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 3, 2022, pp. 3380–3389
2022
-
[46]
Ucf101: A dataset of 101 human actions classes from videos in the wild,
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
Pith/arXiv arXiv 2012
-
[47]
Hmdb: a large video database for human motion recognition,
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: a large video database for human motion recognition,” in2011 Interna- tional conference on computer vision. IEEE, 2011, pp. 2556–2563
2011
-
[48]
Sefar: Semi- supervised fine-grained action recognition with temporal perturbation and learning stabilization,
Y . Huang, H. Chen, Z. Xu, Z. Jia, H. Sun, and D. Shao, “Sefar: Semi- supervised fine-grained action recognition with temporal perturbation and learning stabilization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 3833–3841
2025
-
[49]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[50]
Svformer: Semi-supervised video transformer for action recognition,
Z. Xing, Q. Dai, H. Hu, J. Chen, Z. Wu, and Y .-G. Jiang, “Svformer: Semi-supervised video transformer for action recognition,” inProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 18 816–18 826
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.