See Selectively, Act Adaptively: Dual-Level Structural Decomposition for Bimanual Robot Manipulation
Pith reviewed 2026-06-27 06:44 UTC · model grok-4.3
The pith
Dual-level decomposition of visual selection and bimanual modes raises manipulation success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
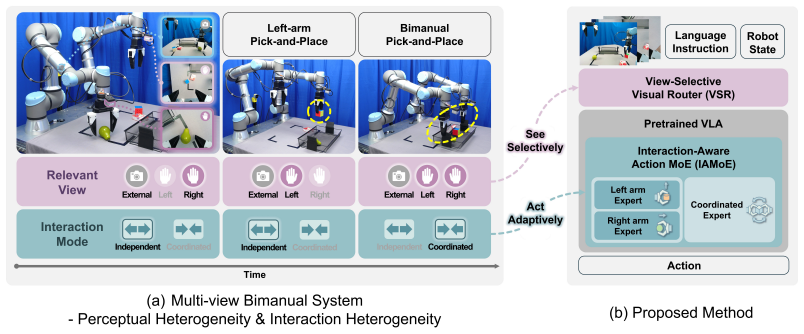
Jointly considering selective visual processing and explicit decomposition of bimanual interaction structures provides an effective inductive bias for robust bimanual manipulation.
What carries the argument
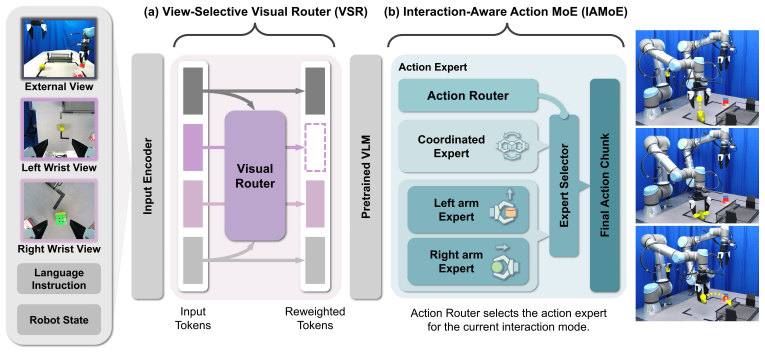
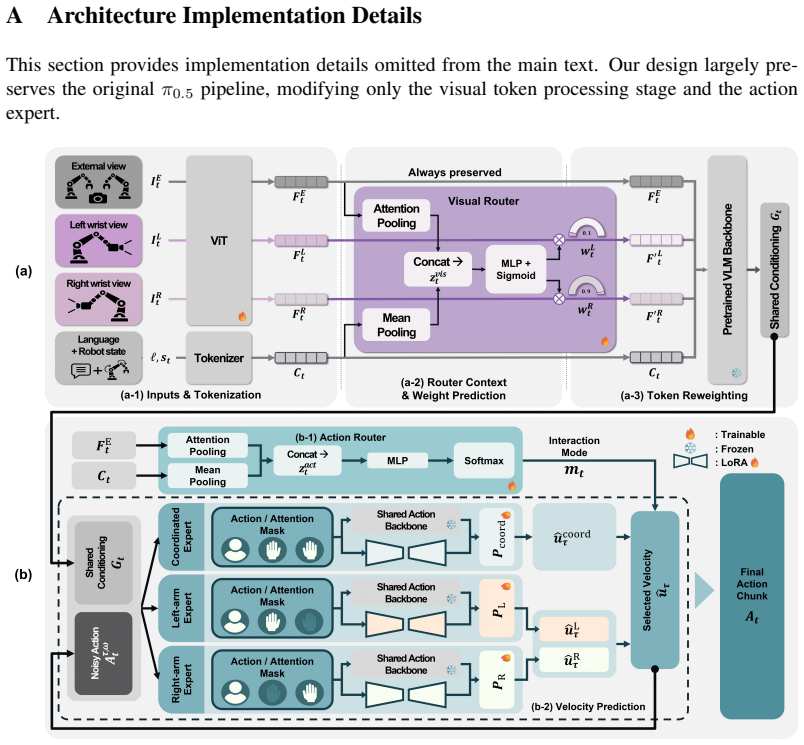
Dual-Level Structural Decomposition, implemented as a View-Selective Visual Router that adjusts wrist-view contributions and an Interaction-Aware Action Mixture-of-Experts that splits action generation into coordinated and arm-wise pathways.
If this is right
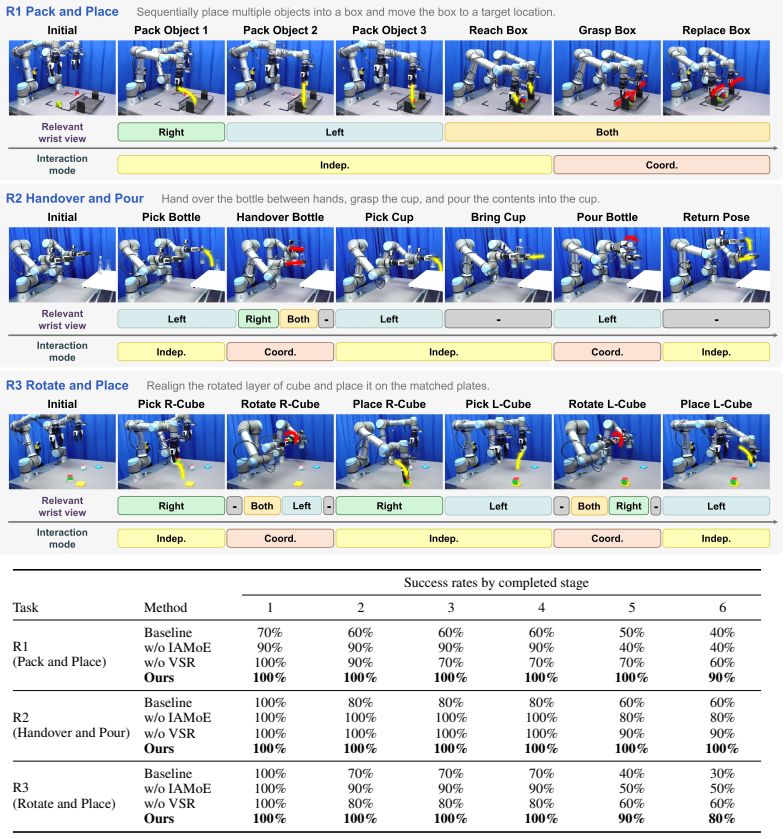
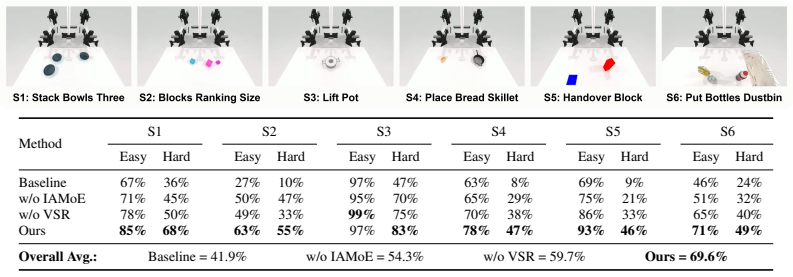
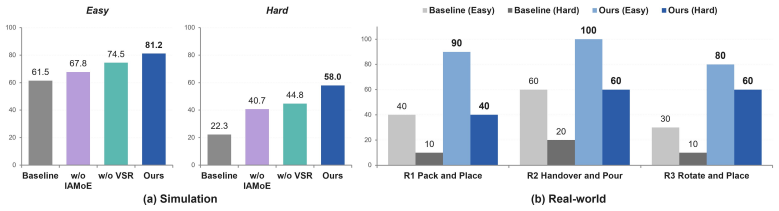
- The combined router and MoE yields a 27.7 percent higher average success rate across six simulated bimanual tasks.
- The same architecture produces a 43.3 percent higher average success rate on three long-horizon real-world tasks.
- Single-module ablations that remove either the visual router or the action MoE each underperform the full dual-level model.
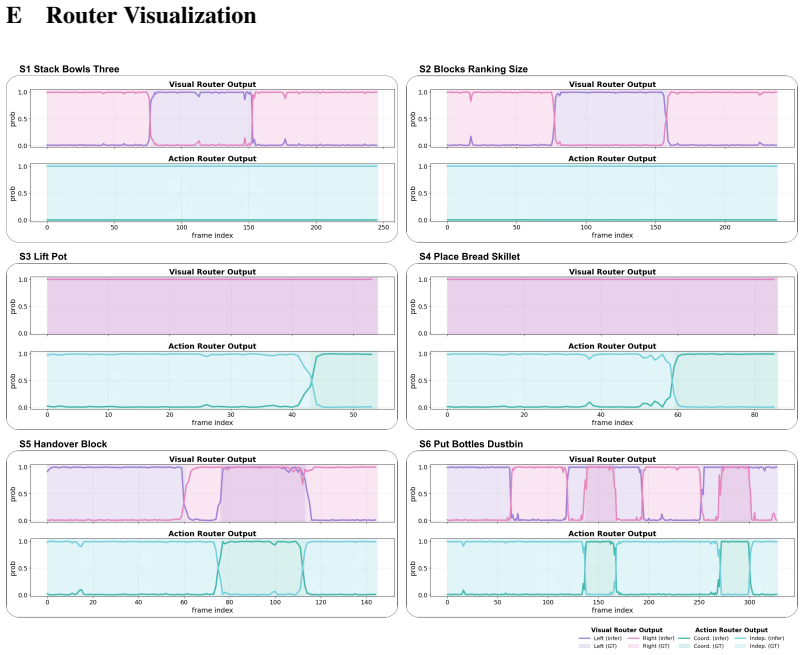
- The router learns to emphasize task-relevant wrist views at different stages while the MoE adapts to independent versus coordinated arm modes.
- Performance gains appear consistently in both simulation and real-world settings when both decomposition levels are present.
Where Pith is reading between the lines
- The same separation of visual gating from action routing could be tested on other multi-limb or multi-robot coordination problems where mode switching occurs.
- If the router and MoE are kept lightweight, the approach may reduce the data volume needed to reach high success on new bimanual tasks.
- A natural extension would measure whether the learned routing decisions align with human intuition about when each arm should act independently.
Load-bearing premise
Visual relevance and bimanual interaction modes vary in ways that a learnable router and mixture-of-experts can capture without losing critical cross-modal information or causing training instability.
What would settle it
Run the full model against the monolithic baseline on the same six simulated tasks; if average success rate improvement falls below 10 percent while training remains stable, the claimed inductive bias does not hold.
Figures


read the original abstract
In bimanual robotic manipulation, task-relevant visual information varies with the task stage and context, while the interaction of the two arms shifts between independent and coordinated modes, making policy learning challenging. However, existing monolithic Vision-Language-Action (VLA) policies process diverse visual inputs and interaction patterns through a single shared representation and action generation pathway, often failing to separately account for visual relevance and bimanual interaction structure. To address this issue, we propose a bimanual manipulation VLA framework based on Dual-Level Structural Decomposition. The View-Selective Visual Router dynamically adjusts wrist-view contributions to emphasize relevant visual cues, while the Interaction-Aware Action Mixture-of-Experts (MoE) decomposes action generation into coordinated and arm-wise pathways to adapt to varying bimanual interaction modes. We evaluate the proposed method on six simulated bimanual manipulation tasks in RoboTwin 2.0 and three long-horizon real-world tasks. Our model improves the overall average success rate over a monolithic baseline by 27.7% in simulation and 43.3% in real-world evaluation, while consistently outperforming single-module variants across both settings. These results demonstrate that jointly considering selective visual processing and explicit decomposition of bimanual interaction structures provides an effective inductive bias for robust bimanual manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that jointly considering selective visual processing and explicit decomposition of bimanual interaction structures via a Dual-Level Structural Decomposition framework (View-Selective Visual Router plus Interaction-Aware Action MoE) supplies an effective inductive bias for robust bimanual manipulation. This is supported by reported average success-rate gains of 27.7% in simulation (six RoboTwin 2.0 tasks) and 43.3% in real-world evaluation (three long-horizon tasks) over a monolithic VLA baseline, with consistent outperformance of single-module variants.
Significance. If the empirical gains are shown to arise specifically from the claimed structural decomposition rather than capacity or tuning effects, the work would supply a concrete inductive bias for handling stage-dependent visual relevance and shifting independent/coordinated bimanual modes, which is a recurring challenge in VLA policy learning for manipulation.
major comments (2)
- [Evaluation] Abstract and Evaluation section: the reported 27.7 % / 43.3 % gains are presented without error bars, statistical significance tests, or details on baseline architectures and data-split ablations; these omissions are load-bearing because the central claim rests on the assertion that the dual-level modules, rather than other factors, produce the observed improvements.
- [Methods] Methods section: the precise architectures of the View-Selective Visual Router and Interaction-Aware Action MoE, together with training dynamics and capacity-matched controls, are not verifiable from the supplied text, preventing confirmation that the inductive bias is the operative mechanism.
minor comments (1)
- The abstract would benefit from explicit naming of the monolithic baseline and the six simulated tasks to allow immediate assessment of task diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger statistical reporting and more verifiable methodological details. We address each major comment below and commit to revisions that directly strengthen the empirical claims without altering the core contributions.
read point-by-point responses
-
Referee: [Evaluation] Abstract and Evaluation section: the reported 27.7 % / 43.3 % gains are presented without error bars, statistical significance tests, or details on baseline architectures and data-split ablations; these omissions are load-bearing because the central claim rests on the assertion that the dual-level modules, rather than other factors, produce the observed improvements.
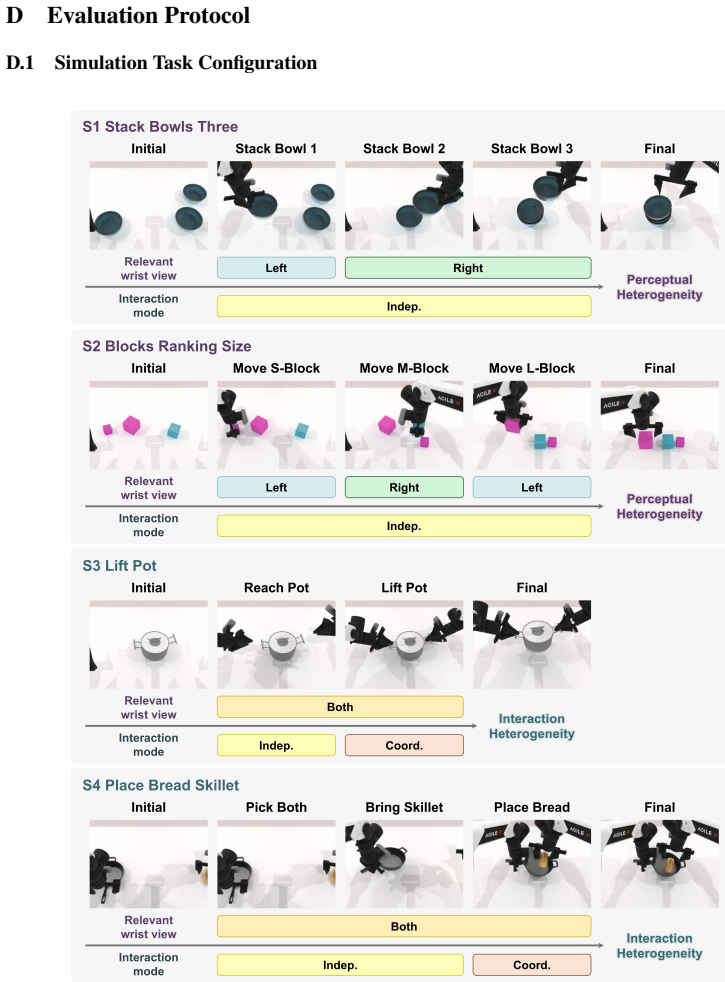
Authors: We agree that the absence of error bars and significance testing weakens the load-bearing claim. In the revised manuscript we will report mean success rates with standard deviations computed over at least three random seeds for all methods, include paired t-test p-values between our model and the monolithic baseline, and expand Section 4 to detail the exact baseline architectures (including parameter counts and training protocols) as well as the train/validation/test splits used for the six RoboTwin 2.0 tasks. We will also add an explicit data-split ablation table. These additions will be placed in the main evaluation section rather than the appendix. revision: yes
-
Referee: [Methods] Methods section: the precise architectures of the View-Selective Visual Router and Interaction-Aware Action MoE, together with training dynamics and capacity-matched controls, are not verifiable from the supplied text, preventing confirmation that the inductive bias is the operative mechanism.
Authors: We acknowledge that the current text does not supply sufficient architectural specificity or capacity-matched controls. In revision we will insert (i) a detailed diagram and layer-by-layer specification of the View-Selective Visual Router (including the gating network, feature dimensions, and how wrist-view weights are computed from task-stage embeddings), (ii) the expert specialization, router architecture, and load-balancing loss for the Interaction-Aware Action MoE, (iii) a hyperparameter table and training curve appendix, and (iv) a new capacity-matched ablation in which the MoE is replaced by a single feed-forward network whose parameter count equals the sum of the experts. These changes will allow readers to verify that performance gains arise from the structural decomposition rather than capacity differences. revision: yes
Circularity Check
No circularity: empirical inductive bias claim rests on held-out task evaluation
full rationale
The paper introduces a View-Selective Visual Router and Interaction-Aware Action MoE as architectural components for bimanual VLA policies. Its central claim—that this dual-level decomposition supplies an effective inductive bias—is supported solely by reported success-rate gains (27.7 % simulation, 43.3 % real-world) over a monolithic baseline and single-module ablations on six simulated and three real tasks. No equations, parameter-fitting steps, or self-citations appear in the provided text that would reduce these empirical outcomes to quantities defined inside the model itself. The evaluation uses held-out tasks, so the performance numbers are not forced by construction from the training data or internal definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing monolithic VLA policies process diverse visual inputs and interaction patterns through a single shared representation and action generation pathway
invented entities (2)
-
View-Selective Visual Router
no independent evidence
-
Interaction-Aware Action Mixture-of-Experts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
F. Krebs and T. Asfour. A bimanual manipulation taxonomy.IEEE Robotics and Automation Letters, 7(4):11031–11038, 2022. doi:10.1109/LRA.2022.3196158
-
[2]
Smith, Y
C. Smith, Y . Karayiannidis, L. Nalpantidis, X. Gratal, P. Qi, D. V . Dimarogonas, and D. Kragic. Dual arm manipulation—a survey.Robotics and Autonomous Systems, 60(10):1340–1353,
-
[3]
doi:https://doi.org/10.1016/j.robot.2012.07.005
ISSN 0921-8890. doi:https://doi.org/10.1016/j.robot.2012.07.005
-
[4]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InProceedings of Robotics: Science and Systems, 2023. doi: 10.15607/RSS.2023.XIX.016
-
[5]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile ALOHA: Learning bimanual mobile manipulation using low-cost whole-body teleoperation. InConference on Robot Learning (CoRL), volume 270, pages 4066–4083. PMLR, 2024
2024
-
[6]
Grotz, M
M. Grotz, M. Shridhar, Y .-W. Chao, T. Asfour, and D. Fox. Peract2: Benchmarking and learning for robotic bimanual manipulation tasks. InCoRL Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond, 2024
2024
-
[7]
Y . Li, C. Pan, H. Xu, X. Wang, and Y . Wu. Efficient bimanual handover and rearrangement via symmetry-aware actor-critic learning. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 3867–3874, 2023. doi:10.1109/ICRA48891.2023.10160739
-
[8]
A. Tung, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, Y . Zhu, L. Fei-Fei, and S. Savarese. Learn- ing multi-arm manipulation through collaborative teleoperation. InIEEE International Confer- ence on Robotics and Automation (ICRA), pages 9212–9219, 2021. doi:10.1109/ICRA48506. 2021.9561491
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Fos- ter, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model. In Conference on Robot Learning (CoRL), volume 270, pages 2679–2713. PMLR, 2025
2025
-
[10]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[11]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control. InRobotics: Science and Systems (RSS), 2025. doi:10.15607/RSS.2025.XXI.010
-
[12]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world general- ization. InConference on Robot Learning (CoRL), volume 305, pages 17–40. PMLR, 2025
2025
-
[13]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics Transformer for Real-World Control at Scale. InRobotics: Science and Systems (RSS), 2023. doi:10.15607/RSS.2023.XIX.025
-
[14]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), volume 229, pages 2165–2183. PMLR, 2023
2023
-
[15]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An Open-Source Generalist Robot Policy. InRobotics: Science and Systems (RSS), 2024. doi:10.15607/RSS.2024.XX.090. 10
-
[16]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. RDT-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[17]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[18]
F. Krebs and T. Asfour. Formalization of temporal and spatial constraints of bimanual manipu- lation categories. InInternational Conference on Intelligent Robots and Systems (IROS), pages 1302–1309, 2024. doi:10.1109/IROS58592.2024.10801861
-
[19]
H. Deng, W. Guo, Q. Wang, Z. Wu, and Z. Wang. Safebimanual: Diffusion-based trajec- tory optimization for safe bimanual manipulation. InConference on Robot Learning (CoRL), volume 305, pages 3218–3238. PMLR, 2025
2025
-
[20]
I.-C. A. Liu, J. Chen, G. S. Sukhatme, and D. Seita. D-coda: Diffusion for coordinated dual- arm data augmentation. InConference on Robot Learning (CoRL), volume 305, pages 3569–
-
[21]
Z. Lan, W. Mao, H. Li, L. Wang, T. Wang, H. Fan, and O. Yoshie. Bfa: Best-feature-aware fusion for multi-view fine-grained manipulation.IEEE Robotics and Automation Letters, 10 (9):8930–8937, 2025. doi:10.1109/LRA.2025.3589149
-
[22]
Y . Bai, Z. Wang, Y . Liu, K. Luo, Y . Wen, M. Dai, W. Chen, Z. Chen, L. Liu, G. Li, and L. Lin. Learning to see and act: Task-aware virtual view exploration for robotic manipulation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[23]
Chuang, A
I. Chuang, A. Lee, D. Gao, M.-M. Naddaf-Sh, and I. Soltani. Active vision might be all you need: Exploring active vision in bimanual robotic manipulation. InIEEE International Conference on Robotics and Automation (ICRA), pages 7952–7959, 2025
2025
-
[24]
R. Feng, D. Hu, W. Ma, and X. Li. Play to the score: Stage-guided dynamic multi-sensory fusion for robotic manipulation. InConference on Robot Learning (CoRL), volume 270, pages 340–363. PMLR, 2025
2025
- [25]
-
[26]
X. Zhai, Z. Huang, L. Wu, Q. Zhao, Q. Yu, J. Ren, C. Hao, and H. Soh. Skillvla: Tackling com- binatorial diversity in dual-arm manipulation via skill reuse.arXiv preprint arXiv:2603.03836, 2026
arXiv 2026
-
[27]
Jiang, X.-M
J.-J. Jiang, X.-M. Wu, Y .-X. He, L.-A. Zeng, Y .-L. Wei, D. Zhang, and W.-S. Zheng. Re- thinking bimanual robotic manipulation: Learning with decoupled interaction framework. In IEEE/CVF International Conference on Computer Vision (ICCV), pages 12427–12437, 2025
2025
-
[28]
A. C.-W. Lee, I. Chuang, L.-Y . Chen, and I. Soltani. Interact: Inter-dependency aware action chunking with hierarchical attention transformers for bimanual manipulation. InConference on Robot Learning (CoRL), volume 270, pages 1730–1743. PMLR, 2025
2025
-
[29]
H. Xu, L. Lei, J. Gu, C. Tang, J. Chen, and R. Wang. Move-then-operate: Behavioral phasing for human-like robotic manipulation.arXiv preprint arXiv:2604.23620, 2026
Pith/arXiv arXiv 2026
-
[30]
J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi. Modeling task relationships in multi- task learning with multi-gate mixture-of-experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, page 1930–1939. Associa- tion for Computing Machinery, 2018. ISBN 9781450355520. doi:10.1145/3219819.3220007. 11
-
[31]
Xiong, X
H. Xiong, X. Xu, J. Wu, Y . Hou, J. Bohg, and S. Song. Vision in action: Learning active perception from human demonstrations. InConference on Robot Learning (CoRL), pages 5450–5463. PMLR, 2025
2025
-
[32]
I.-C. A. Liu, S. He, D. Seita, and G. S. Sukhatme. V oxact-b: V oxel-based acting and stabilizing policy for bimanual manipulation. InConference on Robot Learning (CoRL), volume 270, pages 4354–4370. PMLR, 2025
2025
-
[33]
H. Im, E. Jeong, A. Kolobov, J. Fu, and Y . Lee. Twinvla: Data-efficient bimanual manipulation with twin single-arm vision-language-action models.arXiv preprint arXiv:2511.05275, 2025
arXiv 2025
-
[34]
G. Lu, T. Yu, H. Deng, S. S. Chen, Y . Tang, and Z. Wang. Anybimanual: Transferring uni- manual policy for general bimanual manipulation. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 13662–13672, 2025
2025
-
[35]
Z. Yang, Y . Chai, X. Jia, Q. Li, Y . Shao, X. Zhu, H. Su, and J. Yan. Drivemoe: Mixture-of- experts for vision-language-action model in end-to-end autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10678–10688, 2026
2026
-
[36]
Grannen, Y
J. Grannen, Y . Wu, B. Vu, and D. Sadigh. Stabilize to act: Learning to coordinate for bimanual manipulation. InConference on Robot Learning (CoRL), volume 229, pages 563–576. PMLR, 2023
2023
-
[37]
Lipman, R
Y . Lipman, R. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[38]
A. Tong, K. FATRAS, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, G. Wolf, and Y . Ben- gio. Improving and generalizing flow-based generative models with minibatch optimal trans- port.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[39]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations (ICLR), 2022
2022
-
[40]
E. Jang, S. Gu, and B. Poole. Categorical reparameterization with gumbel-softmax. InInter- national Conference on Learning Representations (ICLR), 2017
2017
-
[41]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. 12 A Architecture Implementation Details This section provides implementation details omitted from ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.