ELVA: Exploring Ranking-Driven Universal Multimodal Retrieval
Pith reviewed 2026-06-26 15:32 UTC · model grok-4.3
The pith
ELVA mitigates grain blindness in multimodal retrieval by ranking negative samples differently using rule-based reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
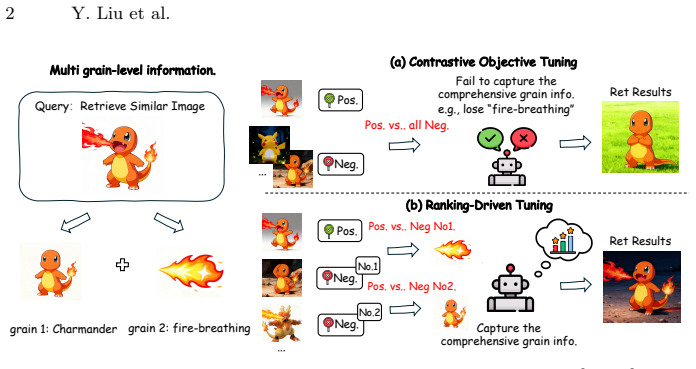
The central claim is that by treating negative samples differently according to their similarity to the positive sample in a ranking-driven RL setup, the model can learn distinct grain-level information, alleviating grain blindness in universal multimodal retrieval and improving performance on multi-grain query scenarios as demonstrated on MRBench.
What carries the argument
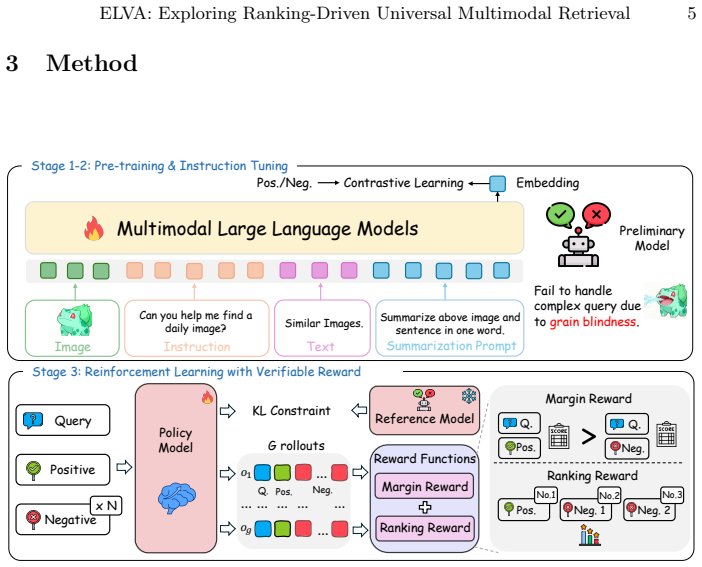
Rule-based RL with verifiable rewards that jointly optimizes negative ranking and positive-negative similarity gaps in MLLMs for retrieval.
Load-bearing premise
Differentiating negative samples by similarity to the positive will allow the model to extract distinct grain-level information from each negative.
What would settle it
Observing no performance gain on MRBench or failure to show better handling of multi-grain queries when using the ELVA framework compared to standard contrastive learning.
Figures


read the original abstract
Leveraging Multimodal Large Language Models (MLLMs) via contrastive learning has become a mainstream paradigm for improving the performance of Universal Multimodal Retrieval (UMR). However, previous works have ignored the grain blindness when adapting the contrastive paradigm into retrieval tasks. Grain blindness refers to the tendency of the model to overlook grain-level information contained in the query, which is crucial for effectively handling complex queries. This stems from contrastive learning treating samples as a binary classification (positive/negative), while ignoring the different information carried by each negative sample. To address this, we argue that negatives should be treated differently according to their similarity to the positive sample, enabling the model to learn distinct grain information from each negative. In this paper, we introduce a simple but effective framework, called ELVA, a novel rule-based RL framework that mitigates grain blindness through ranking-driven MLLMs. 1) Instead of relying on reward models, we extend Reinforcement Learning with Verifiable Rewards (RLVR) to retrieval tasks, allowing the model to explore new ranking behaviors without explicit ranking labels. 2) By utilizing rule-based rewards, our approach jointly optimizes the ranking of negative samples while enlarging the similarity gap between positive and negative. To more precisely measure grain blindness, we further introduce MRBench, a new benchmark specifically designed for multi-grain query scenarios. ELVA achieves state-of-the-art results across standard retrieval benchmarks, and its notable 13.1% improvement on MRBench further demonstrates its effectiveness in alleviating grain blindness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ELVA, a rule-based RL framework extending RLVR to universal multimodal retrieval with MLLMs. It identifies 'grain blindness' (the model's tendency to overlook grain-level query information due to binary positive/negative treatment in contrastive learning) as the core problem and claims that ranking negatives by similarity to the positive via rule-based rewards will enable distinct grain-level learning from each negative while enlarging the positive-negative similarity gap. The paper introduces MRBench for multi-grain queries and asserts SOTA results on standard benchmarks plus a 13.1% gain on MRBench as evidence of effectiveness.
Significance. If the results and causal mechanism hold after validation, the work could advance UMR by providing a reproducible, reward-model-free method for handling complex queries; the new MRBench benchmark is a concrete, potentially reusable contribution. The rule-based RLVR extension is a methodological strength that supports reproducibility and avoids reliance on learned reward models.
major comments (2)
- [Abstract] Abstract: the central claim that ranking-driven RL alleviates grain blindness rests on the unverified assumption that differential negative treatment enables distinct grain-level learning; no mechanistic validation (representation analysis on multi-grain queries) or controlled ablations isolating the ranking component from the similarity-gap term is described, so the 13.1% MRBench gain cannot be attributed specifically to grain-blindness mitigation rather than generic ranking optimization.
- [Abstract] Abstract: the assertion of SOTA results across standard retrieval benchmarks and a 13.1% improvement on MRBench supplies no experimental details, baselines, ablation studies, or error analysis, rendering the data unverifiable against the claims.
minor comments (2)
- The term 'grain blindness' is introduced as a new concept without citations to related prior work on fine-grained or multi-level retrieval; its operational definition should be clarified with concrete examples of multi-grain queries.
- The precise formulation of the rule-based rewards (how ranking is scored and how the similarity gap is enlarged) is not specified in the provided description; an equation or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below, clarifying the support provided in the full manuscript while acknowledging where additional detail or analysis would strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ranking-driven RL alleviates grain blindness rests on the unverified assumption that differential negative treatment enables distinct grain-level learning; no mechanistic validation (representation analysis on multi-grain queries) or controlled ablations isolating the ranking component from the similarity-gap term is described, so the 13.1% MRBench gain cannot be attributed specifically to grain-blindness mitigation rather than generic ranking optimization.
Authors: The full manuscript presents ablation studies in Section 4.2 that isolate the contribution of the ranking-driven reward by comparing the complete ELVA objective against a variant that retains only the similarity-gap term. These results indicate an incremental benefit from the ranking component on MRBench. We agree, however, that representation-level analysis of grain-specific features on multi-grain queries is not included and would provide stronger mechanistic support for attributing the gain specifically to grain-blindness mitigation. We will add such analysis in the revision. revision: yes
-
Referee: [Abstract] Abstract: the assertion of SOTA results across standard retrieval benchmarks and a 13.1% improvement on MRBench supplies no experimental details, baselines, ablation studies, or error analysis, rendering the data unverifiable against the claims.
Authors: The abstract is a concise summary; the full paper supplies the requested details in Sections 4 and 5, including the complete list of baselines, evaluation metrics, ablation tables, and error bars across three random seeds. We will revise the abstract to include explicit references to these sections and to state the primary baselines and the exact MRBench metric that yields the reported 13.1% relative gain. revision: partial
Circularity Check
No circularity: empirical framework with no derivations or self-referential reductions
full rationale
The paper presents ELVA as a rule-based RL extension to retrieval tasks, motivated by an argument about grain blindness in contrastive learning, and reports benchmark results including a 13.1% gain on MRBench. No equations, derivations, or mathematical claims appear in the abstract. The central elements are a proposed framework (RLVR extension with rule-based rewards) and empirical evaluation; these do not reduce to fitted inputs or self-citations by construction. The assumption about differential negative treatment is stated as motivation rather than derived from prior results within the paper. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive learning treats samples as binary classification and therefore ignores grain-level information carried by different negative samples.
invented entities (1)
-
grain blindness
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 10
Pith/arXiv arXiv 2025
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Baldrati, A., Agnolucci, L., Bertini, M., Del Bimbo, A.: Zero-shot composed image retrieval with textual inversion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15338–15347 (2023) 4, 10
2023
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Baldrati, A., Bertini, M., Uricchio, T., Del Bimbo, A.: Effective conditioned and composed image retrieval combining clip-based features. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21466– 21474 (2022) 2
2022
-
[4]
Chen, D., Dolan, W.B.: Collecting highly parallel data for paraphrase evaluation (2011) 14
2011
-
[5]
arXiv preprint arXiv:2501.05952 (2025) 2
Dong, H., Kang, Z., Yin, W., Liang, X., Feng, C., Ran, J.: Scalable vision language model training via high quality data curation. arXiv preprint arXiv:2501.05952 (2025) 2
arXiv 2025
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fu, Z., Zhang, L., Xia, H., Mao, Z.: Linguistic-aware patch slimming framework for fine-grained cross-modal alignment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26307–26316 (2024) 2
2024
-
[7]
Gao, T., Yao, X., Chen, D.: Simcse: Simple contrastive learning of sentence em- beddings (2021) 6, 9
2021
-
[8]
arXiv preprint arXiv:2504.17432 (2025) 2, 9
Gu, T., Yang, K., Feng, Z., Wang, X., Zhang, Y., Long, D., Chen, Y., Cai, W., Deng, J.: Breaking the modality barrier: Universal embedding learning with mul- timodal llms. arXiv preprint arXiv:2504.17432 (2025) 2, 9
arXiv 2025
-
[9]
arXiv preprint arXiv:2510.13515 (2025) 3
Gu, T., Yang, K., Zhang, K., An, X., Feng, Z., Zhang, Y., Cai, W., Deng, J., Bing, L.: Unime-v2: Mllm-as-a-judge for universal multimodal embedding learning. arXiv preprint arXiv:2510.13515 (2025) 3
arXiv 2025
-
[10]
arXiv preprint arXiv:2510.07048 (2025) 4 16 Y
Gui, Y., Cheng, J.: Search-r3: Unifying reasoning and embedding generation in large language models. arXiv preprint arXiv:2510.07048 (2025) 4 16 Y. Liu et al
Pith/arXiv arXiv 2025
-
[11]
arXiv preprint arXiv:2501.12948 (2025) 5, 8
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025) 5, 8
Pith/arXiv arXiv 2025
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hong, M., Lu, Y., Ye, N., Lin, C., Zhao, Q., Liu, S.: Unsupervised homography es- timation with coplanarity-aware gan. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17663–17672 (2022) 8
2022
-
[13]
arXiv preprint arXiv:2503.06749 (2025) 10, 11
Huang, W., Jia, B., Zhai, Z., Cao, S., Ye, Z., Zhao, F., Xu, Z., Hu, Y., Lin, S.: Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749 (2025) 10, 11
Pith/arXiv arXiv 2025
-
[14]
Huang,X.,Peng,H.,Zou,D.,Liu,Z.,Li,J.,Liu,K.,Wu,J.,Su,J.,Yu,P.S.:Cosent: Consistentsentenceembeddingviasimilarityranking.IEEE/ACMTransactionson Audio, Speech, and Language Processing32, 2800–2813 (2024) 3
2024
-
[15]
ACM Transactions on Information Systems (TOIS)20(4), 422–446 (2002) 3
Järvelin, K., Kekälëinen, J.: Cumulated gain-based evaluation of ir techniques. ACM Transactions on Information Systems (TOIS)20(4), 422–446 (2002) 3
2002
-
[16]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021) 2, 4
2021
-
[17]
arXiv preprint arXiv:2307.16645 (2023) 7
Jiang, T., Huang, S., Luan, Z., Wang, D., Zhuang, F.: Scaling sentence embeddings with large language models. arXiv preprint arXiv:2307.16645 (2023) 7
arXiv 2023
-
[18]
arXiv preprint arXiv:2407.12580 (2024) 11
Jiang, T., Song, M., Zhang, Z., Huang, H., Deng, W., Sun, F., Zhang, Q., Wang, D., Zhuang, F.: E5-v: Universal embeddings with multimodal large language models. arXiv preprint arXiv:2407.12580 (2024) 11
Pith/arXiv arXiv 2024
-
[19]
Kaufmann, T., Weng, P., Bengs, V., Hüllermeier, E.: A survey of reinforcement learning from human feedback (2024) 8
2024
-
[20]
arXiv preprint arXiv:2505.19650 (2025) 1, 4
Kong, F., Zhang, J., Liu, Y., Zhang, H., Feng, S., Yang, X., Wang, D., Tian, Y., Zhang, F., Zhou, G., et al.: Modality curation: Building universal embeddings for advanced multimodal information retrieval. arXiv preprint arXiv:2505.19650 (2025) 1, 4
arXiv 2025
-
[21]
arXiv preprint arXiv:2503.04812 (2025) 4
Lan, Z., Niu, L., Meng, F., Zhou, J., Su, J.: Llave: Large language and vision embedding models with hardness-weighted contrastive learning. arXiv preprint arXiv:2503.04812 (2025) 4
arXiv 2025
-
[22]
In: Proceedings of the European conference on computer vision (ECCV)
Lee, K.H., Chen, X., Hua, G., Hu, H., He, X.: Stacked cross attention for image- text matching. In: Proceedings of the European conference on computer vision (ECCV). pp. 201–216 (2018) 4
2018
-
[23]
arXiv preprint arXiv:2407.07895 (2024) 2
Li, F., Zhang, R., Zhang, H., Zhang, Y., Li, B., Li, W., Ma, Z., Li, C.: Llava-next- interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895 (2024) 2
Pith/arXiv arXiv 2024
-
[24]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 4, 10, 11
2023
-
[25]
In: International confer- ence on machine learning
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International confer- ence on machine learning. pp. 12888–12900. PMLR (2022) 10
2022
-
[26]
Advances in neural information processing systems34, 9694–9705 (2021) 4
Li,J.,Selvaraju,R.,Gotmare,A.,Joty,S.,Xiong,C.,Hoi,S.C.H.:Alignbeforefuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems34, 9694–9705 (2021) 4
2021
-
[27]
In: ICCV (2023) 12, 14 ELVA: Exploring Ranking-Driven Universal Multimodal Retrieval 17
Li, K., Wang, Y., Li, Y., Wang, Y., He, Y., Wang, L., Qiao, Y.: Unmasked teacher: Towards training-efficient video foundation models. In: ICCV (2023) 12, 14 ELVA: Exploring Ranking-Driven Universal Multimodal Retrieval 17
2023
-
[28]
arXiv (2026) 3
Li, M., Zhang, Y., Long, D., Chen, K., Song, S., Bai, S., Yang, Z., Xie, P., Yang, A., Liu, D., Zhou, J., Lin, J.: Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. arXiv (2026) 3
2026
-
[29]
arXiv preprint arXiv:2507.14902 (2025) 9
Li, X., Li, C., Chen, S.Z., Chen, X.: U-marvel: Unveiling key factors for uni- versal multimodal retrieval via embedding learning with mllms. arXiv preprint arXiv:2507.14902 (2025) 9
arXiv 2025
-
[30]
arXiv preprint arXiv:2510.12709 (2025) 2
Lin, L., Long, J., Wan, Z., Wang, Y., Yang, D., Yang, S., Yao, Y., Chen, X., Guo, Z., Li, S., et al.: Sail-embedding technical report: Omni-modal embedding foundation model. arXiv preprint arXiv:2510.12709 (2025) 2
arXiv 2025
-
[31]
arXiv preprint arXiv:2411.02571 (2024) 2, 4, 10, 11, 12, 14
Lin, S.C., Lee, C., Shoeybi, M., Lin, J., Catanzaro, B., Ping, W.: Mm-embed: Uni- versal multimodal retrieval with multimodal llms. arXiv preprint arXiv:2411.02571 (2024) 2, 4, 10, 11, 12, 14
arXiv 2024
-
[32]
arXiv preprint arXiv:2410.18451 (2024) 8
Liu, C.Y., Zeng, L., Liu, J., Yan, R., He, J., Wang, C., Yan, S., Liu, Y., Zhou, Y.: Skywork-reward: Bag of tricks for reward modeling in llms. arXiv preprint arXiv:2410.18451 (2024) 8
Pith/arXiv arXiv 2024
-
[33]
Advances in neural information processing systems36, 34892–34916 (2023) 4
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 4
2023
-
[34]
arXiv preprint arXiv:2508.07050 (2025) 4
Liu, W., Ma, X., Sun, W., Zhu, Y., Li, Y., Yin, D., Dou, Z.: Reasonrank: Empower- ing passage ranking with strong reasoning ability. arXiv preprint arXiv:2508.07050 (2025) 4
Pith/arXiv arXiv 2025
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, Y., Zhang, Y., Cai, J., Jiang, X., Hu, Y., Yao, J., Wang, Y., Xie, W.: Lamra: Large multimodal model as your advanced retrieval assistant. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4015–4025 (2025) 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12
2025
-
[36]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Liu, Y., Huang, Q., Hui, S., Fu, J., Zhou, S., Wu, K., Li, P., Wang, J.: Semantic- aware representation learning for homography estimation. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 2506–2514 (2024) 8
2024
-
[37]
arXiv preprint arXiv:2503.01785 (2025) 4
Liu, Z., Sun, Z., Zang, Y., Dong, X., Cao, Y., Duan, H., Lin, D., Wang, J.: Visual- rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785 (2025) 4
Pith/arXiv arXiv 2025
-
[38]
arXiv preprint arXiv:2507.08064 (2025) 1, 2, 3, 4, 6, 7, 9, 10, 12, 14
Lyu, Y., Shao, R., Chen, G., Zhu, Y., Guan, W., Nie, L.: Puma: Layer-pruned language model for efficient unified multimodal retrieval with modality-adaptive learning. arXiv preprint arXiv:2507.08064 (2025) 1, 2, 3, 4, 6, 7, 9, 10, 12, 14
Pith/arXiv arXiv 2025
-
[39]
In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
Ma, X., Wang, L., Yang, N., Wei, F., Lin, J.: Fine-tuning llama for multi-stage text retrieval. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2421–2425 (2024) 2
2024
-
[40]
arXiv preprint arXiv:2507.04590 (2025) 2
Meng, R., Jiang, Z., Liu, Y., Su, M., Yang, X., Fu, Y., Qin, C., Chen, Z., Xu, R., Xiong, C., et al.: Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents. arXiv preprint arXiv:2507.04590 (2025) 2
Pith/arXiv arXiv 2025
-
[41]
arXiv preprint arXiv:1807.03748 (2018) 7
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018) 7
Pith/arXiv arXiv 2018
-
[42]
Advances in Neural Information Processing Systems34, 1256–1272 (2021) 6
Pezeshki, M., Kaba, O., Bengio, Y., Courville, A.C., Precup, D., Lajoie, G.: Gra- dient starvation: A learning proclivity in neural networks. Advances in Neural Information Processing Systems34, 1256–1272 (2021) 6
2021
-
[43]
arXiv preprint arXiv:2603.05869 (2026) 4
Qi, Y., Fu, P., Li, H., Liu, Y., Jiang, C., Qin, B., Luo, Z., Luan, J.: Patchcue: Enhancing vision-language model reasoning with patch-based visual cues. arXiv preprint arXiv:2603.05869 (2026) 4
arXiv 2026
-
[44]
arXiv preprint arXiv:2504.07956 (2025) 14 18 Y
Qi, Y., Zhao, Y., Zeng, Y., Bao, X., Huang, W., Chen, L., Chen, Z., Zhao, J., Qi, Z., Zhao, F.: Vcr-bench: A comprehensive evaluation framework for video chain- of-thought reasoning. arXiv preprint arXiv:2504.07956 (2025) 14 18 Y. Liu et al
arXiv 2025
-
[45]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 4, 10, 11
2021
-
[46]
Robinson, J., Sun, L., Yu, K., Batmanghelich, K., Jegelka, S., Sra, S.: Can con- trastive learning avoid shortcut solutions? Advances in neural information process- ing systems34, 4974–4986 (2021) 6
2021
-
[47]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Saito, K., Sohn, K., Zhang, X., Li, C.L., Lee, C.Y., Saenko, K., Pfister, T.: Pic2word: Mapping pictures to words for zero-shot composed image retrieval. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 19305–19314 (2023) 2
2023
-
[48]
arXiv preprint arXiv:2402.03300 (2024) 3
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024) 3
Pith/arXiv arXiv 2024
-
[49]
arXiv preprint arXiv:2504.07615 (2025) 4, 10, 11
Shen, H., Liu, P., Li, J., Fang, C., Ma, Y., Liao, J., Shen, Q., Zhang, Z., Zhao, K., Zhang, Q., et al.: Vlm-r1: A stable and generalizable r1-style large vision-language model. arXiv preprint arXiv:2504.07615 (2025) 4, 10, 11
Pith/arXiv arXiv 2025
-
[50]
arXiv preprint arXiv:2402.04252 (2024) 11
Sun, Q., Wang, J., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, X.: Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252 (2024) 11
arXiv 2024
-
[51]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, Y., Yu, J., Gai, K., Zhuang, J., Xiong, G., Gou, G., Wu, Q.: Missing target- relevant information prediction with world model for accurate zero-shot composed image retrieval. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24785–24795 (2025) 4
2025
-
[52]
arXiv preprint arXiv:2409.12191 (2024) 2, 4, 10, 11, 12
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024) 2, 4, 10, 11, 12
Pith/arXiv arXiv 2024
-
[53]
In: ICLR (2024) 12
Wang, Y., He, Y., Li, Y., Li, K., Yu, J., Ma, X., Li, X., Chen, G., Chen, X., Wang, Y., et al.: Internvid: A large-scale video-text dataset for multimodal understanding and generation. In: ICLR (2024) 12
2024
-
[54]
In: ECCV (2024) 12, 14
Wang, Y., Li, K., Li, X., Yu, J., He, Y., Chen, G., Pei, B., Zheng, R., Xu, J., Wang, Z., et al.: Internvideo2: Scaling video foundation models for multimodal video understanding. In: ECCV (2024) 12, 14
2024
-
[55]
arXiv preprint arXiv:2212.03191 (2022) 12, 14
Wang, Y., Li, K., Li, Y., He, Y., Huang, B., Zhao, Z., Zhang, H., Xu, J., Liu, Y., Wang, Z., et al.: Internvideo: General video foundation models via generative and discriminative learning. arXiv preprint arXiv:2212.03191 (2022) 12, 14
Pith/arXiv arXiv 2022
-
[56]
Wei, C., Chen, Y., Chen, H., Hu, H., Zhang, G., Fu, J., Ritter, A., Chen, W.: Uniir: Trainingandbenchmarkinguniversalmultimodalinformationretrievers.In:ECCV (2024) 3, 6, 9, 10, 11
2024
-
[57]
In: European Conference on Computer Vision
Wei, C., Chen, Y., Chen, H., Hu, H., Zhang, G., Fu, J., Ritter, A., Chen, W.: Uniir: Training and benchmarking universal multimodal information retrievers. In: European Conference on Computer Vision. pp. 387–404. Springer (2024) 4, 10
2024
-
[58]
Wu, K., Li, P., Fu, J., Li, Y., Wu, Y., Liu, Y., Wang, J., Zhou, S.: Event-equalized densevideocaptioning.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR). pp. 8417–8427 (June 2025) 14
2025
-
[59]
Knowledge-Based Systems p
Wu, Y., Deng, Y., Hui, S., Liu, Y., Wu, K., Huang, W., Wang, J.: Hierarchical frequency adaptation for all-in-one image restoration. Knowledge-Based Systems p. 116049 (2026) 14
2026
-
[60]
IEEE Transactions on Geoscience and Remote Sensing62, 1–14 (2024) 14 ELVA: Exploring Ranking-Driven Universal Multimodal Retrieval 19
Wu, Y., Deng, Y., Zhou, S., Liu, Y., Huang, W., Wang, J.: Cr-former: Single-image cloud removal with focused taylor attention. IEEE Transactions on Geoscience and Remote Sensing62, 1–14 (2024) 14 ELVA: Exploring Ranking-Driven Universal Multimodal Retrieval 19
2024
-
[61]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Xiao, T., Wang, S.: Towards off-policy learning for ranking policies with logged feedback. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 8700–8707 (2022) 4
2022
-
[62]
arXiv preprint arXiv:2505.07608 (2025) 2
Xiaomi, L., Xia, B., Shen, B., Zhu, D., Zhang, D., Wang, G., Zhang, H., Liu, H., Xiao, J., Dong, J., et al.: Mimo: Unlocking the reasoning potential of language model–from pretraining to posttraining. arXiv preprint arXiv:2505.07608 (2025) 2
arXiv 2025
-
[63]
In: CVPR (2016) 14
Xu, J., Mei, T., Yao, T., Rui, Y.: Msr-vtt: A large video description dataset for bridging video and language. In: CVPR (2016) 14
2016
-
[64]
arXiv preprint arXiv:2506.12364 (2025) 4
Xu, M., Dong, J., Hou, J., Wang, Z., Li, S., Gao, Z., Zhong, R., Cai, H.: Mm-r5: Multimodal reasoning-enhanced reranker via reinforcement learning for document retrieval. arXiv preprint arXiv:2506.12364 (2025) 4
arXiv 2025
-
[65]
arXiv preprint arXiv:2605.09271 (2026) 4
Yang, Z., Liu, Y., Fu, J., Sugiyama, M., Zheng, N., et al.: Shaping schema via language representation as the next frontier for llm intelligence expanding. arXiv preprint arXiv:2605.09271 (2026) 4
Pith/arXiv arXiv 2026
-
[66]
arXiv preprint arXiv:2503.14476 (2025) 9
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al.: Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476 (2025) 9
Pith/arXiv arXiv 2025
-
[67]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, T., Yao, Y., Zhang, H., He, T., Han, Y., Cui, G., Hu, J., Liu, Z., Zheng, H.T., Sun, M., et al.: Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13807–13816 (2024) 4
2024
-
[68]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023) 10
2023
-
[69]
In: European Conference on Computer Vision (2024) 10, 11
Zhang, B., Zhang, P., Dong, X., Zang, Y., Wang, J.: Long-clip: Unlocking the long- text capability of clip. In: European Conference on Computer Vision (2024) 10, 11
2024
-
[70]
Zhang, K., Luan, Y., Hu, H., Lee, K., Qiao, S., Chen, W., Su, Y., Chang, M.W.: Magiclens: Self-supervised image retrieval with open-ended instructions (2024) 11
2024
-
[71]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, Q., Lei, Z., Zhang, Z., Li, S.Z.: Context-aware attention network for image- text retrieval. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3536–3545 (2020) 2
2020
-
[72]
arXiv preprint arXiv:2501.03895 (2025) 14
Zhang, S., Fang, Q., Yang, Z., Feng, Y.: Llava-mini: Efficient image and video large multimodal models with one vision token. arXiv preprint arXiv:2501.03895 (2025) 14
arXiv 2025
-
[73]
arXiv preprint arXiv:2506.05176 (2025) 2
Zhang, Y., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., et al.: Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176 (2025) 2
Pith/arXiv arXiv 2025
-
[74]
ACM Transactions on Information Systems42(4), 1–60 (2024) 2
Zhao, W.X., Liu, J., Ren, R., Wen, J.R.: Dense text retrieval based on pretrained language models: A survey. ACM Transactions on Information Systems42(4), 1–60 (2024) 2
2024
-
[75]
arXiv preprint arXiv:2410.18127 (2024) 4
Zhou, J., Wang, X., Yu, J.: Optimizing preference alignment with differentiable ndcg ranking. arXiv preprint arXiv:2410.18127 (2024) 4
arXiv 2024
-
[76]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Zhou, J., Xiong, Y., Liu, Z., Liu, Z., Xiao, S., Wang, Y., Zhao, B., Zhang, C.J., Lian, D.: Megapairs: Massive data synthesis for universal multimodal retrieval. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 19076–19095 (2025) 4
2025
-
[77]
arXiv preprint arXiv:2304.10592 (2023) 4 20 Y
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023) 4 20 Y. Liu et al
Pith/arXiv arXiv 2023
-
[78]
arXiv preprint arXiv:2510.02745 (2025) 1, 4
Zhu, L., Ji, D., Chen, T., Wu, H., Wang, S.: Retrv-r1: A reasoning-driven mllm framework for universal and efficient multimodal retrieval. arXiv preprint arXiv:2510.02745 (2025) 1, 4
arXiv 2025
-
[79]
In: Companion Proceedings of the ACM on Web Conference
Zhu, T., Jung, M.C., Clark, J.: Generalized contrastive learning for multi-modal retrieval and ranking. In: Companion Proceedings of the ACM on Web Conference
-
[80]
661–670 (2025) 2
pp. 661–670 (2025) 2
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.