When Does Mixing Help? Analyzing Query Embedding Interpolation in Multilingual Dense Retrieval
Pith reviewed 2026-06-27 06:56 UTC · model grok-4.3
The pith
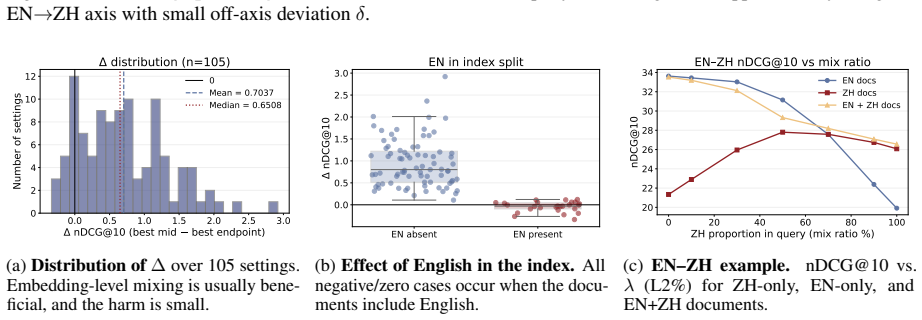
Interpolating parallel query embeddings at optimal ratios outperforms the best monolingual query in 88 of 105 retrieval tests on mMARCO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
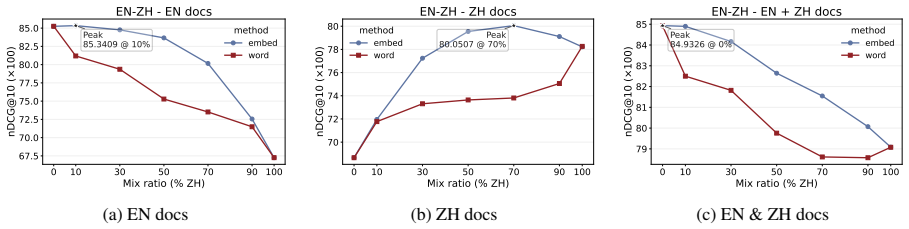
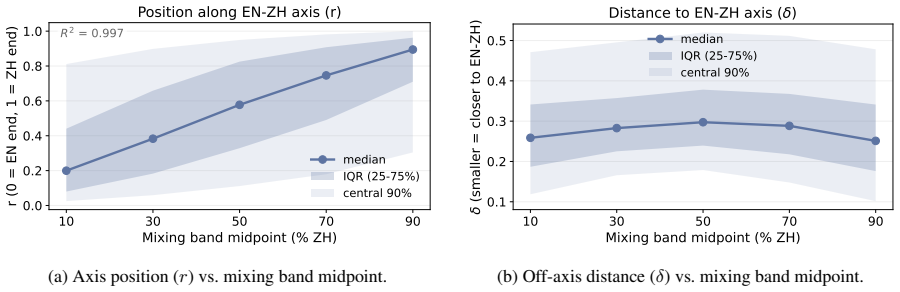
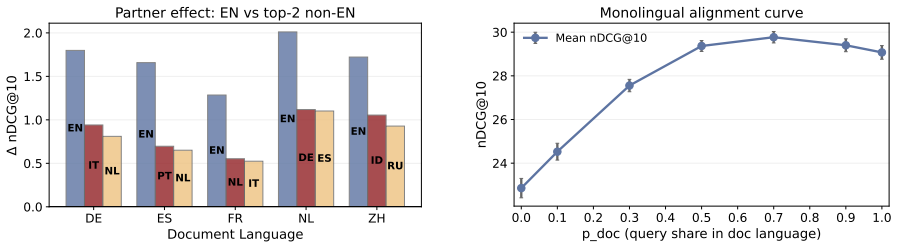
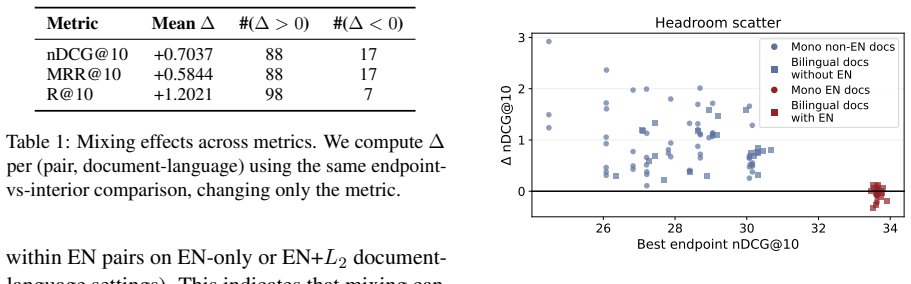
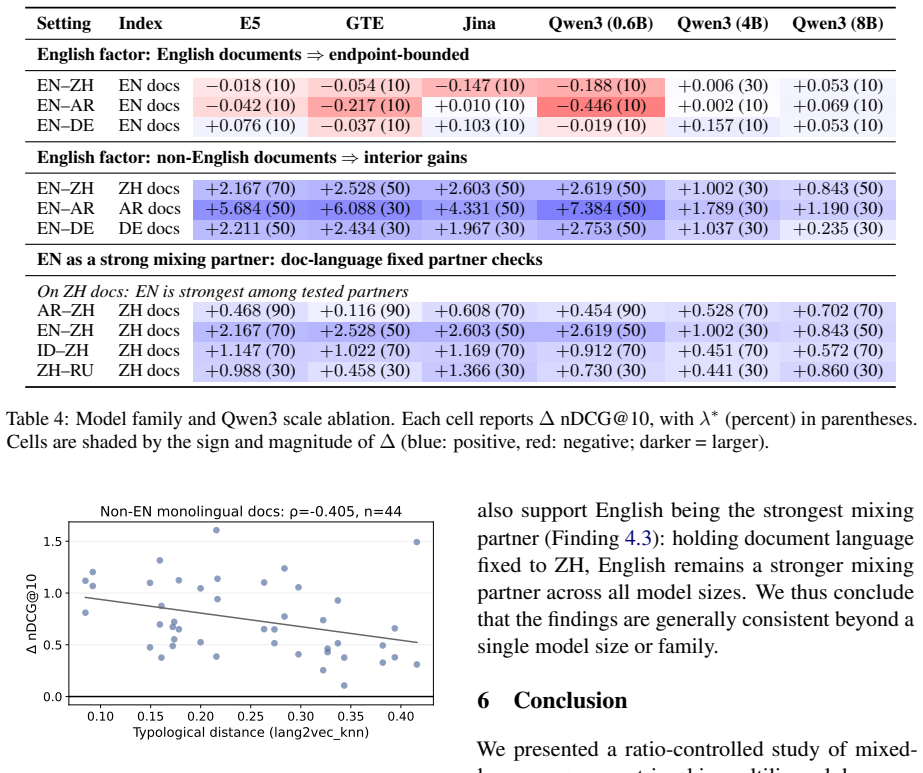
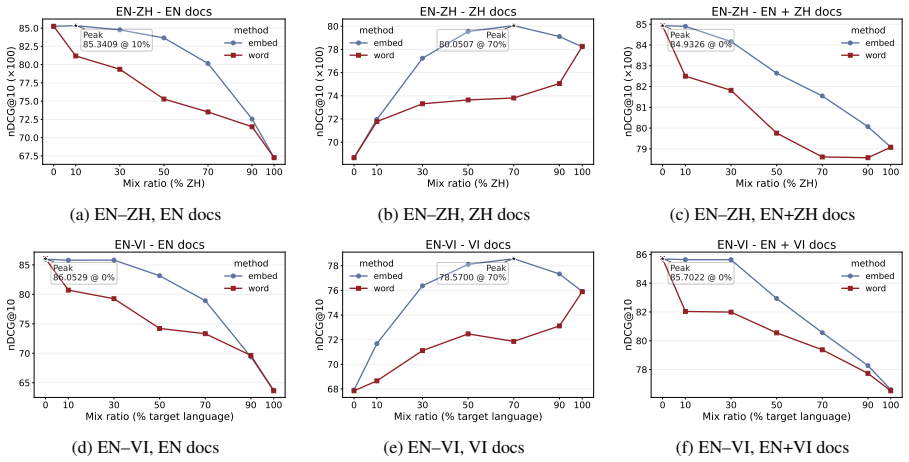
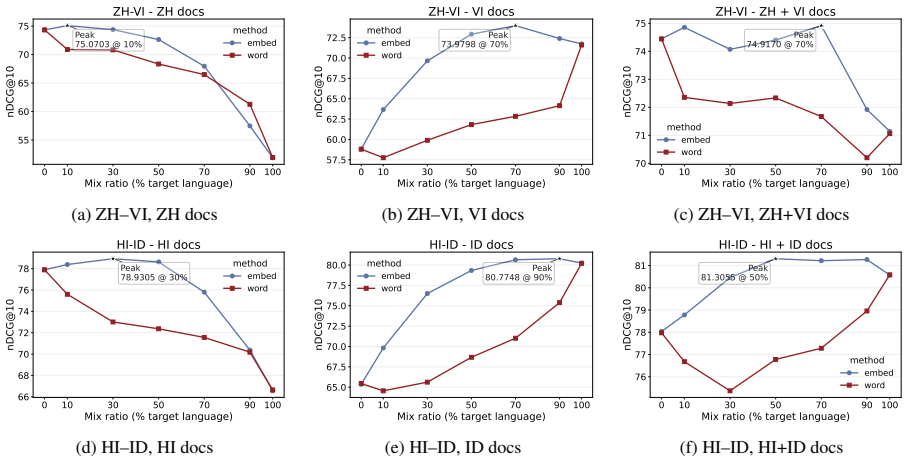
Linear interpolation of monolingual query embeddings at controlled ratios produces retrieval performance that exceeds the stronger monolingual endpoint in 88 of 105 language-pair and index combinations; the gains are uniformly positive for non-English document indices, English indices are optimized by unmixed English queries, English is the strongest mixing partner for every other language, and mixing gains correlate negatively with typological distance once English dominance is controlled.
What carries the argument
Embedding-level mixing: constructing a mixed query as a convex combination of two monolingual query embeddings produced by the same encoder.
If this is right
- Retrieval systems can improve accuracy on non-English document collections by mixing in a second language at inference time instead of using a single query language.
- For collections that already contain English documents, the system should default to the English query embedding without mixing.
- English can be used as a universal mixing partner regardless of the other language in the query.
- Typological distance between the two query languages predicts the magnitude of the mixing benefit once English is controlled for.
- The same mixing-ratio patterns appear across different dense retriever families and sizes.
Where Pith is reading between the lines
- Index builders could pre-compute and store a small set of mixed query vectors for common language pairs to avoid runtime interpolation.
- The observed negative correlation with typological distance suggests that mixing may be especially useful for closely related language pairs once English dominance is removed.
- If the linear-interpolation assumption holds only for certain encoder families, then newer contrastively trained models might show different optimal ratios or even different asymmetry patterns.
Load-bearing premise
Linear interpolation between two monolingual embeddings yields a vector whose retrieval behavior reflects a meaningful blend of the two languages' semantics.
What would settle it
A controlled experiment on the same model and index where the performance curve over mixing ratios is flat or peaks at an endpoint rather than an interior ratio.
Figures




read the original abstract
While mixed-language querying is ubiquitous in multilingual communities, the sensitivity of dense retrievers to such queries remains poorly understood. We present a ratio-controlled study on mMARCO that systematically evaluates retrieval performance by varying the mixing proportion of parallel query translations via embedding-level mixing -- constructing mixed queries as an interpolation of monolingual embeddings. Experiments with BGE-M3 demonstrate that an optimal mixing ratio outperforms the best monolingual endpoint in 88/105 cases. We uncover a distinct asymmetry driven by English dominance: mixing is uniformly beneficial when retrieving from non-English document indices, whereas indices containing English are best served by pure English queries. Furthermore, English acts as the strongest mixing partner for every non-English document language. Finally, when controlling for English dominance, mixing gains correlate negatively with typological distance. We conclude that language-mix sensitivity is structured and predictable, and we validate the robustness of these patterns across model families and scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a ratio-controlled empirical study on the mMARCO benchmark using embedding-level linear interpolation of parallel query translations in multilingual dense retrieval. With BGE-M3 (and other models), it reports that an optimal mixing ratio outperforms the best monolingual endpoint in 88/105 language-index pairs, identifies an English-dominance asymmetry (mixing helps uniformly for non-English document indices but pure English queries are best when English is present), shows English as the strongest mixing partner for all non-English languages, and finds that mixing gains correlate negatively with typological distance after controlling for English. The patterns are claimed to be robust across model families and scales.
Significance. If the results hold under a fully specified protocol, the work offers structured, actionable insights into language-mix sensitivity for multilingual retrieval systems, moving beyond anecdotal observations. The use of a public benchmark, systematic ratio variation, and cross-model validation are clear strengths that support the empirical claims.
major comments (2)
- [Methods / Experiments] The central 88/105 count and the uniformity/asymmetry claims depend on the precise definition of 'optimal mixing ratio' and the evaluation protocol. The methods section should explicitly state whether ratios are selected per language-index pair on held-out data or the test set, and whether any multiple-testing correction or pre-specification was used, as this directly affects whether the headline result can be taken as evidence of structured sensitivity rather than selection artifact.
- [Embedding-level mixing construction] The weakest assumption—that linear interpolation of monolingual embeddings produces retrieval behavior that meaningfully reflects combined cross-lingual semantics—is load-bearing for interpreting the asymmetry and typological-distance results as more than a performance probe. The paper should add a short discussion or ablation (e.g., comparing to non-linear mixing or to cross-lingual alignment metrics) to bound how much the observed patterns could be artifacts of the linear construction itself.
minor comments (1)
- [Results] Tables or figures reporting the per-language-pair wins/losses and the typological-distance correlation should include exact sample sizes, confidence intervals, or p-values so readers can assess the strength of the 'uniformly beneficial' and 'negative correlation' statements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity on the experimental protocol and to discuss the linear mixing assumption.
read point-by-point responses
-
Referee: [Methods / Experiments] The central 88/105 count and the uniformity/asymmetry claims depend on the precise definition of 'optimal mixing ratio' and the evaluation protocol. The methods section should explicitly state whether ratios are selected per language-index pair on held-out data or the test set, and whether any multiple-testing correction or pre-specification was used, as this directly affects whether the headline result can be taken as evidence of structured sensitivity rather than selection artifact.
Authors: We agree that the selection protocol requires explicit description. The optimal ratio per language-index pair was identified by evaluating the full ratio grid directly on the test set; this was an exploratory choice to establish whether beneficial mixtures exist rather than to validate a selection procedure. No held-out data, pre-specification, or multiple-testing correction was used. In the revised manuscript we will state this protocol verbatim in the Methods section. To reduce reliance on per-pair selection we will additionally report performance for a single fixed ratio (0.5) across all pairs, confirming that mixing gains remain widespread even without optimization. These changes clarify the scope of the 88/105 result while preserving the observed patterns. revision: yes
-
Referee: [Embedding-level mixing construction] The weakest assumption—that linear interpolation of monolingual embeddings produces retrieval behavior that meaningfully reflects combined cross-lingual semantics—is load-bearing for interpreting the asymmetry and typological-distance results as more than a performance probe. The paper should add a short discussion or ablation (e.g., comparing to non-linear mixing or to cross-lingual alignment metrics) to bound how much the observed patterns could be artifacts of the linear construction itself.
Authors: We accept that the linear-interpolation construction merits explicit discussion. In the revised manuscript we will add a concise paragraph in the Discussion section that (i) acknowledges linear mixing as a simplifying assumption that may not capture non-linear semantic interactions, (ii) notes that the consistency of English dominance and typological correlations across model families provides indirect support for the patterns reflecting embedding-space geometry, and (iii) references prior work on embedding arithmetic. A full non-linear ablation or alignment-metric comparison lies outside the present scope and would require additional model training; we therefore limit the revision to the requested discussion, which bounds the interpretive claims without new experiments. revision: yes
Circularity Check
No significant circularity identified
full rationale
This is a purely empirical paper that reports retrieval metrics from controlled interpolation experiments on the external mMARCO benchmark across 105 language-index pairs using BGE-M3 and other models. The central claims (88/105 optimal-ratio wins, English dominance asymmetry, negative correlation with typological distance) are direct measurements from end-to-end task performance rather than derivations, fitted parameters renamed as predictions, or self-referential definitions. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the paper's own inputs; the embedding mixing construction is presented only as an experimental probe whose validity is assessed externally via benchmark scores.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mMARCO dataset supplies reliable parallel query translations and relevance judgments across languages
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
MADLAD-400: A Multilingual And Document-Level Large Audited Dataset , url =
Kudugunta, Sneha and Caswell, Isaac and Zhang, Biao and Garcia, Xavier and Xin, Derrick and Kusupati, Aditya and Stella, Romi and Bapna, Ankur and Firat, Orhan , booktitle =. MADLAD-400: A Multilingual And Document-Level Large Audited Dataset , url =
-
[7]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[8]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , editor =
-
[10]
2020 , eprint=
A Survey of Code-switched Speech and Language Processing , author=. 2020 , eprint=
2020
-
[11]
2021 , note =
Census of Population 2020: Statistical Release 1 --- Demographic Characteristics, Education, Language and Religion , institution =. 2021 , note =
2020
-
[12]
Vladimir Karpukhin and Barlas Oguz and Sewon Min and Patrick Lewis and Ledell Wu and Sergey Edunov and Danqi Chen and Wen. Dense Passage Retrieval for Open-Domain Question Answering , booktitle =. doi:10.18653/v1/2020.emnlp-main.550
-
[13]
2022 , journal =
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. 2022 , journal =
2022
-
[14]
Robertson, Stephen and Zaragoza, Hugo , title =. 2009 , issue_date =. doi:10.1561/1500000019 , journal =
-
[15]
Payal Bajaj and Daniel Campos and Nick Craswell and Li Deng and Jianfeng Gao and Xiaodong Liu and Rangan Majumder and Andrew McNamara and Bhaskar Mitra and Tri Nguyen and Mir Rosenberg and Xia Song and Alina Stoica and Saurabh Tiwary and Tong Wang , year=. 1611.09268 , archivePrefix=
-
[16]
Computacion y Sistemas , doi =
Chakma, Kunal and Das, Amitava , year =. Computacion y Sistemas , doi =
-
[17]
Ganguly, Debasis and Bandyopadhyay, Ayan and Mitra, Mandar and Jones, Gareth J.F. , title =. 2016 , isbn =. doi:10.1145/2911451.2914727 , booktitle =
-
[18]
Proceedings of FIRE 2016 , year =
Banerjee, Somnath and Chakma, Kunal and Naskar, Sudip Kumar and Das, Amitava and Rosso, Paolo and Bandyopadhyay, Sivaji and Choudhury, Monojit , title =. Proceedings of FIRE 2016 , year =
2016
-
[19]
GLUEC o S : An Evaluation Benchmark for Code-Switched NLP
Khanuja, Simran and Dandapat, Sandipan and Srinivasan, Anirudh and Sitaram, Sunayana and Choudhury, Monojit. GLUEC o S : An Evaluation Benchmark for Code-Switched NLP. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.329
-
[20]
L in CE : A Centralized Benchmark for Linguistic Code-switching Evaluation
Aguilar, Gustavo and Kar, Sudipta and Solorio, Thamar. L in CE : A Centralized Benchmark for Linguistic Code-switching Evaluation. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[21]
Boosting Zero-shot Cross-lingual Retrieval by Training on Artificially Code-Switched Data
Litschko, Robert and Artemova, Ekaterina and Plank, Barbara. Boosting Zero-shot Cross-lingual Retrieval by Training on Artificially Code-Switched Data. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.193
-
[22]
Do, Junggeun and Lee, Jaeseong and Hwang, Seung-won. C ontrastive M ix: Overcoming Code-Mixing Dilemma in Cross-Lingual Transfer for Information Retrieval. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.naacl...
-
[23]
Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu , year=. 2402.03216 , archivePrefix=
-
[24]
2022 , eprint=
Unsupervised Dense Information Retrieval with Contrastive Learning , author=. 2022 , eprint=
2022
-
[25]
Multilingual Large Language Models Are Not (Yet) Code-Switchers
Zhang, Ruochen and Cahyawijaya, Samuel and Cruz, Jan Christian Blaise and Winata, Genta and Aji, Alham Fikri. Multilingual Large Language Models Are Not (Yet) Code-Switchers. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.774
-
[26]
Jonghwi Kim and Deokhyung Kang and Seonjeong Hwang and Yunsu Kim and Jungseul Ok and Gary Lee , year=. 2505.16631 , archivePrefix=
-
[27]
Luiz Bonifacio and Vitor Jeronymo and Hugo Queiroz Abonizio and Israel Campiotti and Marzieh Fadaee and Roberto Lotufo and Rodrigo Nogueira , year=. 2108.13897 , archivePrefix=
-
[28]
S tanza: A Python Natural Language Processing Toolkit for Many Human Languages
Qi, Peng and Zhang, Yuhao and Zhang, Yuhui and Bolton, Jason and Manning, Christopher D. S tanza: A Python natural language processing toolkit for many human languages. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2020. doi:10.18653/v1/2020.acl-demos.14
-
[29]
and Allan, James and Carterette, Ben , title =
Smucker, Mark D. and Allan, James and Carterette, Ben , title =. 2007 , isbn =. doi:10.1145/1321440.1321528 , booktitle =
-
[30]
IEEE Transactions on Big Data , year =
Billion-scale similarity search with GPUs , author =. IEEE Transactions on Big Data , year =
-
[31]
Text REtrieval Conference (TREC) , year =
Craswell, Nick and Mitra, Bhaskar and Yilmaz, Emine and Campos, Daniel , title =. Text REtrieval Conference (TREC) , year =
-
[32]
Quality Metrics in Recommender Systems: Do We Calculate Metrics Consistently? , url=
Tamm, Yan-Martin and Damdinov, Rinchin and Vasilev, Alexey , year=. Quality Metrics in Recommender Systems: Do We Calculate Metrics Consistently? , url=. doi:10.1145/3460231.3478848 , booktitle=
-
[33]
Matthijs Douze and Alexandr Guzhva and Chengqi Deng and Jeff Johnson and Gergely Szilvasy and Pierre-Emmanuel Mazaré and Maria Lomeli and Lucas Hosseini and Hervé Jégou , journal=. The. 2024 , eprint=
2024
-
[34]
D ista L s: a Comprehensive Collection of Language Distance Measures
Goot, Rob Van Der and Ploeger, Esther and Blaschke, Verena and Samardzic, Tanja. D ista L s: a Comprehensive Collection of Language Distance Measures. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2025. doi:10.18653/v1/2025.emnlp-demos.23
-
[35]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[36]
Aslib Journal of Information Management , volume =
Fu, Hengyi , title =. Aslib Journal of Information Management , volume =. 2018 , month =. doi:10.1108/AJIM-04-2018-0091 , url =
-
[37]
MIRACL : A Multilingual Retrieval Dataset Covering 18 Diverse Languages
Zhang, Xinyu and Thakur, Nandan and Ogundepo, Odunayo and Kamalloo, Ehsan and Alfonso-Hermelo, David and Li, Xiaoguang and Liu, Qun and Rezagholizadeh, Mehdi and Lin, Jimmy. MIRACL : A Multilingual Retrieval Dataset Covering 18 Diverse Languages. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00595
-
[38]
Zhang, Xinyu and Ma, Xueguang and Shi, Peng and Lin, Jimmy. Mr. T y D i: A Multi-lingual Benchmark for Dense Retrieval. Proceedings of the 1st Workshop on Multilingual Representation Learning. 2021. doi:10.18653/v1/2021.mrl-1.12
-
[39]
Multilingual
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu , journal=. Multilingual. 2024 , url=
2024
-
[40]
jina-embeddings-v3: Multilingual embeddings with task
Saba Sturua and Isabelle Mohr and Mohammad Kalim Akram and Michael Günther and Bo Wang and Markus Krimmel and Feng Wang and Georgios Mastrapas and Andreas Koukounas and Nan Wang and Han Xiao , year=. jina-embeddings-v3: Multilingual embeddings with task. 2409.10173 , archivePrefix=
-
[41]
2025 , url=
Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren , journal=. 2025 , url=
2025
-
[42]
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and Zhang, Meishan and Li, Wenjie and Zhang, Min. mGTE : Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval. Proceedings of the 2024 Conference on Empiri...
-
[43]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.