Data-efficient flood depth prediction through domain-aware coreset selection and tabular foundation models
Pith reviewed 2026-06-28 07:26 UTC · model grok-4.3
The pith
Domain-aware coreset selection lets tabular foundation models predict flood depths with 0.7% of training data while transferring across watersheds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
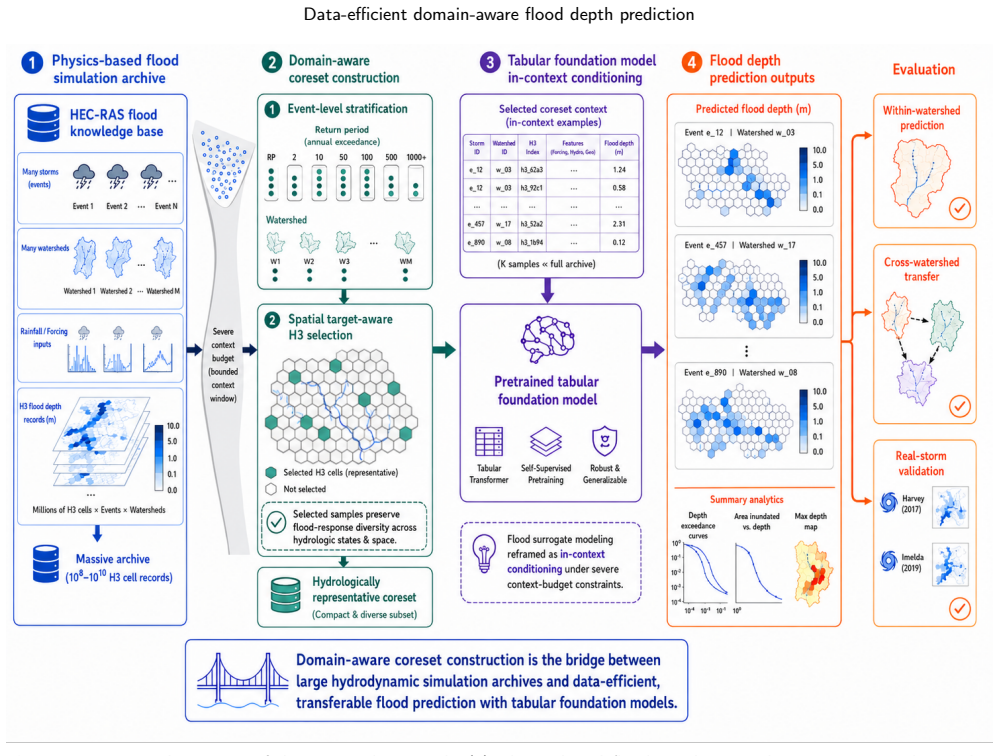
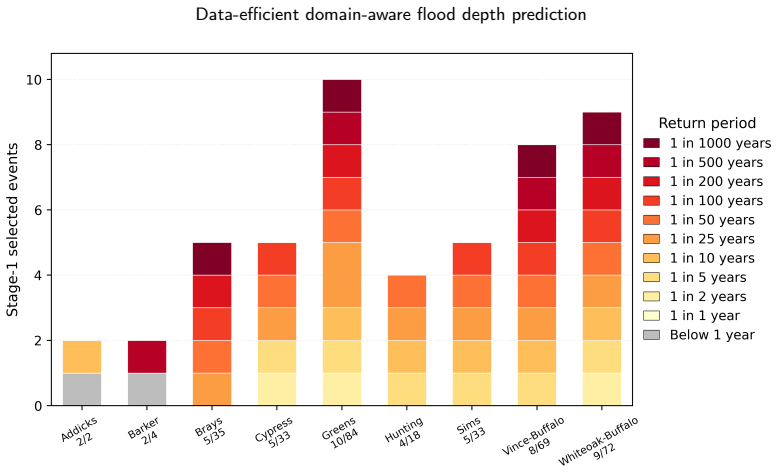
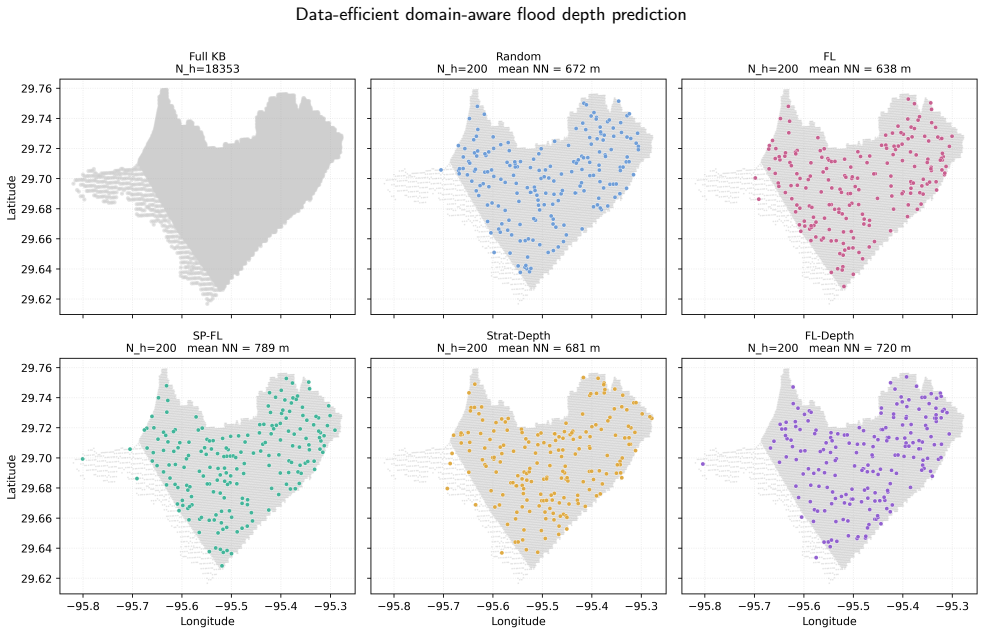
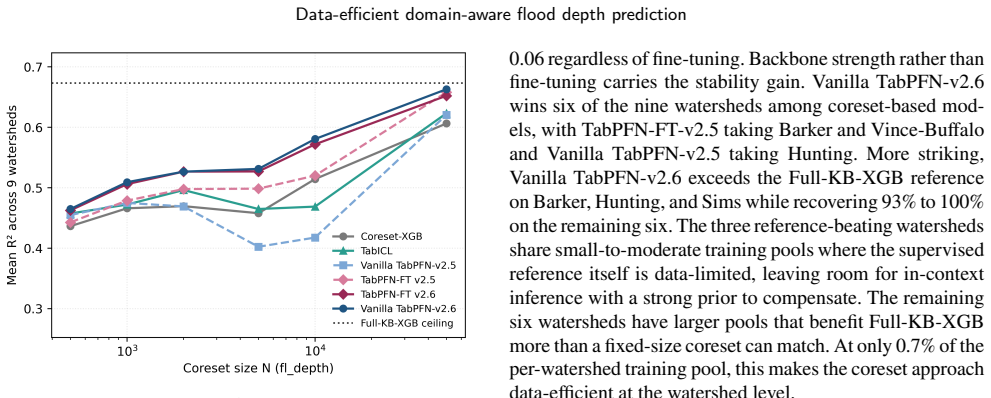
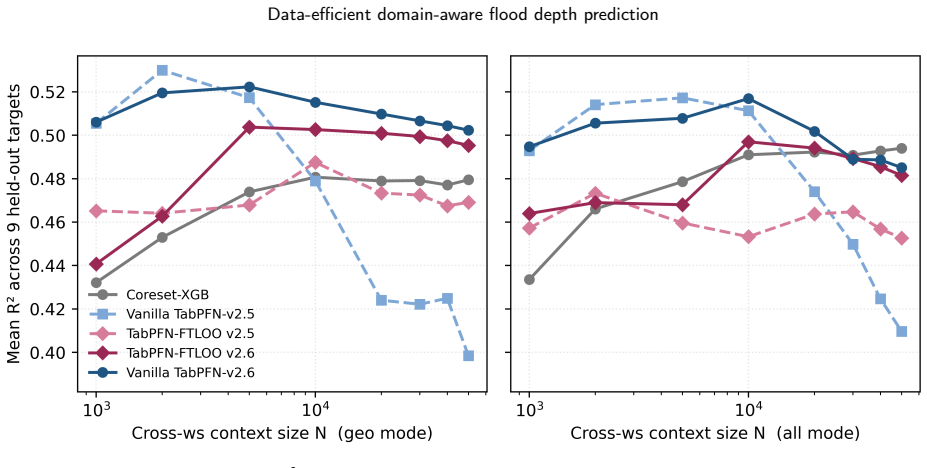
A domain-aware coreset construction pipeline that stratifies storms by return period and most-affected watershed and samples hexagons with a target-aware spatial selector conditions a tabular foundation model at inference time. With only 0.7% of the per-watershed training pool this yields a mean R² of 0.663 across nine Houston-area watersheds, within 98.5% of the full supervised reference of 0.673, and it transfers to held-out watersheds without task-specific retraining while outperforming a coreset-trained supervised baseline.
What carries the argument
The domain-aware coreset construction pipeline, which conditions the tabular foundation model at inference time through stratification by return period and watershed plus target-aware spatial selection.
If this is right
- The model achieves near-supervised accuracy with far less data.
- It enables transfer to held-out watersheds without retraining.
- It outperforms supervised baselines trained on the same coreset in transfer settings.
- On real storms it can exceed the supervised reference in out-of-distribution cases.
Where Pith is reading between the lines
- If the coreset selection generalizes, similar pipelines could apply to other environmental simulations requiring data efficiency.
- Testing the method on watersheds outside the Houston area would confirm broader applicability.
- The approach suggests that foundation models can serve as flexible surrogates when paired with smart data selection rather than full retraining.
Load-bearing premise
The domain-aware stratification and spatial selector create a coreset representative enough for the tabular foundation model to generalize across watersheds without per-watershed fine-tuning.
What would settle it
Observing whether the model's performance on a new set of held-out watersheds falls below the coreset-trained supervised baseline or drops significantly from the 98.5% relative accuracy would falsify the claim of effective transfer.
Figures

read the original abstract
Near-real-time flood depth prediction demands surrogate models that are accurate, fast, and transferable across watersheds. Supervised surrogates can match physics-based simulators in accuracy but need millions of training rows per watershed and cannot extrapolate beyond their original mesh. We propose a domain-aware coreset construction pipeline that conditions a tabular foundation model at inference time. The pipeline stratifies storms by return period and most-affected watershed, then samples hexagons with a target-aware spatial selector. With 0.7% of the per-watershed training pool, the model attains a mean $R^2$ of 0.663 across nine Houston-area watersheds, within 98.5% of the supervised reference ($R^2$ = 0.673). It transfers to held-out watersheds without task-specific retraining, staying ahead of a coreset-trained supervised baseline. On real storms it exceeds the supervised reference on a far out-of-distribution case and trails it on a mostly in-distribution one. Domain-aware coreset construction lets tabular foundation models deliver data-efficient, watershed-transferable flood predictions without per-watershed training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a domain-aware coreset construction pipeline that stratifies storms by return period and most-affected watershed, then applies a target-aware spatial selector to sample a small subset of hexagons. This coreset is used to condition a tabular foundation model at inference time for flood depth prediction. The central empirical claim is that 0.7% of the per-watershed training pool yields a mean R² of 0.663 across nine Houston-area watersheds (98.5% of the full supervised reference R²=0.673), with transfer to held-out watersheds without task-specific retraining and outperformance of a coreset-trained supervised baseline on real storms.
Significance. If the transfer results hold under rigorous validation, the work would demonstrate a practical route to data-efficient, watershed-transferable surrogates that reduce the millions of rows typically required per watershed while leveraging foundation models for zero-shot adaptation. This addresses a key bottleneck in real-time flood modeling and could generalize to other physics-based simulation domains where labeled data are expensive to generate.
major comments (2)
- [Abstract / Methods] Abstract and Methods (coreset pipeline description): The transfer claim to held-out watersheds without per-watershed fine-tuning rests on the unverified assumption that stratification by return period plus the target-aware spatial selector produces a coreset whose coverage of the input-output distribution is sufficient for the foundation model. No quantitative distribution-matching metrics (e.g., Wasserstein distance on hydraulic variables or depth) or ablations that remove either the stratification step or the spatial selector are reported, leaving the representativeness of the 0.7% coreset as a load-bearing but unsupported step.
- [Results] Results (performance reporting): The headline R² figures (0.663 vs. 0.673) are presented without error bars, standard deviations across runs, or details on the number of independent trials. This makes it impossible to determine whether the 98.5% retention is statistically distinguishable from the supervised reference or sensitive to the particular 0.7% selection.
minor comments (1)
- [Abstract] The abstract states that the model 'exceeds the supervised reference on a far out-of-distribution case' but provides no quantitative definition of 'far out-of-distribution' or the specific storm characteristics used for that comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We address each major comment below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (coreset pipeline description): The transfer claim to held-out watersheds without per-watershed fine-tuning rests on the unverified assumption that stratification by return period plus the target-aware spatial selector produces a coreset whose coverage of the input-output distribution is sufficient for the foundation model. No quantitative distribution-matching metrics (e.g., Wasserstein distance on hydraulic variables or depth) or ablations that remove either the stratification step or the spatial selector are reported, leaving the representativeness of the 0.7% coreset as a load-bearing but unsupported step.
Authors: We agree that the current manuscript lacks explicit quantitative support for the coreset's distributional coverage. In the revision we will add (i) Wasserstein distances computed on hydraulic variables (rainfall, terrain slope, roughness) and output depths between the 0.7% coreset and the full per-watershed pool, and (ii) ablation results that successively disable return-period stratification and the target-aware spatial selector while measuring transfer R² on held-out watersheds. These additions will directly quantify the contribution of each pipeline component. revision: yes
-
Referee: [Results] Results (performance reporting): The headline R² figures (0.663 vs. 0.673) are presented without error bars, standard deviations across runs, or details on the number of independent trials. This makes it impossible to determine whether the 98.5% retention is statistically distinguishable from the supervised reference or sensitive to the particular 0.7% selection.
Authors: The observation is correct; variability statistics are absent from the reported headline numbers. We will revise the Results section to report mean R² together with standard deviation across ten independent coreset draws and inference runs, and we will state the exact number of trials. This will permit readers to evaluate both statistical distinguishability from the full-supervised baseline and sensitivity to the particular 0.7% selection. revision: yes
Circularity Check
No circularity; empirical claims rest on reported performance without self-referential definitions or derivations
full rationale
The paper reports experimental results on flood depth prediction using domain-aware coreset selection and tabular foundation models, achieving specific R² values with 0.7% of training data. No equations, derivations, or mathematical chains are present in the abstract or described content. The central claims concern empirical generalization across watersheds and comparison to baselines, which are evaluated via held-out performance metrics rather than any quantity defined in terms of itself or fitted parameters renamed as predictions. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in a way that reduces the result to its inputs. This is a standard empirical ML paper whose validity hinges on experimental design and data, not circular construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Practical Coreset Constructions for Machine Learning
Practical coreset constructions for machine learning. arXiv preprint arXiv:1703.06476 . Bentivoglio,R.,Isufi,E.,Jonkman,S.N.,Taormina,R.,2022.Deeplearning methodsforfloodmapping:Areviewofexistingapplicationsandfuture research directions. Hydrology and Earth System Sciences 26, 4345–
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
System for automated geoscientific analyses (SAGA) v. 2.1.4. Geoscientific Model Develop- ment 8, 1991–2007. Esparza, M., Battala, V., Mostafavi, A.,
1991
-
[3]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
A graph neural network and decision tree modeling approach for predicting wildfire-induced buildingdamage. Computer-AidedCivilandInfrastructureEngineering , 100085. Grinsztajn, L., Flöge, K., Key, O., Birkel, F., Jund, P., Roof, C., Jäger, L., Hollmann,N.,Hutter,F.,2025. TabPFN-2.5:Advancingthestateofthe art in tabular foundation models. arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Hollmann,N.,Müller,S.,Purucker,L.,Krishnakumar,A.,Körfer,M.,Hoo, S.B.,Schirrmeister,R.T.,Hutter,F.,2025.Accuratepredictionsonsmall data with a tabular foundation model
TabPFN: A transformerthatsolvessmalltabularclassificationproblemsinasecond, in: International Conference on Learning Representations. Hollmann,N.,Müller,S.,Purucker,L.,Krishnakumar,A.,Körfer,M.,Hoo, S.B.,Schirrmeister,R.T.,Hutter,F.,2025.Accuratepredictionsonsmall data with a tabular foundation model. Nature 637, 319–326. Killamsetty, K., Sivasubramanian,...
2025
-
[5]
arXiv preprint arXiv:2512.17785
A parametric framework for anticipatory flashflood warning: Integrating landscape vulnerability with precipitation forecasts. arXiv preprint arXiv:2512.17785 . Lin, H., Bilmes, J.,
-
[6]
TransformerscandoBayesianinference,in:InternationalConferenceon Learning Representations
Müller,S.,Hollmann,N.,PinedaArango,S.,Grabocka,J.,Hutter,F.,2022. TransformerscandoBayesianinference,in:InternationalConferenceon Learning Representations. NationalOceanicandAtmosphericAdministration,2018. NOAAAtlas14 precipitation-frequency Atlas of the United States.https://hdsc.nws. noaa.gov/pfds/. Accessed via the Precipitation Frequency Data Server (...
2022
-
[7]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
TabICL: A tabular foundation model for in-context learning on large data. arXiv preprint arXiv:2502.05564 . Roberts, D.R., Bahn, V., Ciuti, S., Boyce, M.S., Elith, J., Guillera-Arroita, G., Hauenstein, S., Lahoz-Monfort, J.J., Schröder, B., Thuiller, W., Warton, D.I., Wintle, B.A., Hartig, F., Dormann, C.F.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
On finetuningtabularfoundationmodels. arXivpreprintarXiv:2506.08982 . Sener, O., Savarese, S.,
-
[9]
Wahl,T.,Jain,S.,Bender,J.,Meyers,S.D.,Luther,M.E.,2015
Retrieval & fine-tuning for in-context tabular models, in: Advances in Neural Information Processing Systems. Wahl,T.,Jain,S.,Bender,J.,Meyers,S.D.,Luther,M.E.,2015. Increasing risk of compound flooding from storm surge and rainfall for major US cities. NatureClimateChange5,1093–1097. doi:10.1038/nclimate2736. Wei, K., Iyer, R., Bilmes, J.,
-
[10]
1954–1963
Submodularity in data subset selection and active learning, in: International Conference on Machine Learning, pp. 1954–1963. Xiao, Y., Mostafavi, A.,
1954
-
[11]
arXiv preprint arXiv:2309.14610
Unsupervised graph deep learning re- veals emergent flood risk profile of urban areas. arXiv preprint arXiv:2309.14610 . Zahura, F.T., Goodall, J.L., Sadler, J.M., Shen, Y., Morsy, M.M., Behl, M.,
-
[12]
Training machine learning surrogate models from a high- fidelityphysics-basedmodel:Applicationforreal-timestreet-scaleflood predictioninanurbancoastalcommunity.WaterResourcesResearch56, e2019WR027038. doi:10.1029/2019WR027038. Zscheischler,J.,Westra,S.,vandenHurk,B.J.J.M.,Seneviratne,S.I.,Ward, P.J., Pitman, A., AghaKouchak, A., Bresch, D.N., Leonard, M.,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.