ReNikud: Audio-Supervised Hebrew Grapheme-to-Phoneme Conversion
Pith reviewed 2026-06-26 17:09 UTC · model grok-4.3
The pith
ReNikud improves Hebrew G2P by supervising with ASR pseudo-labels from unlabeled audio and enforcing character alignment in prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
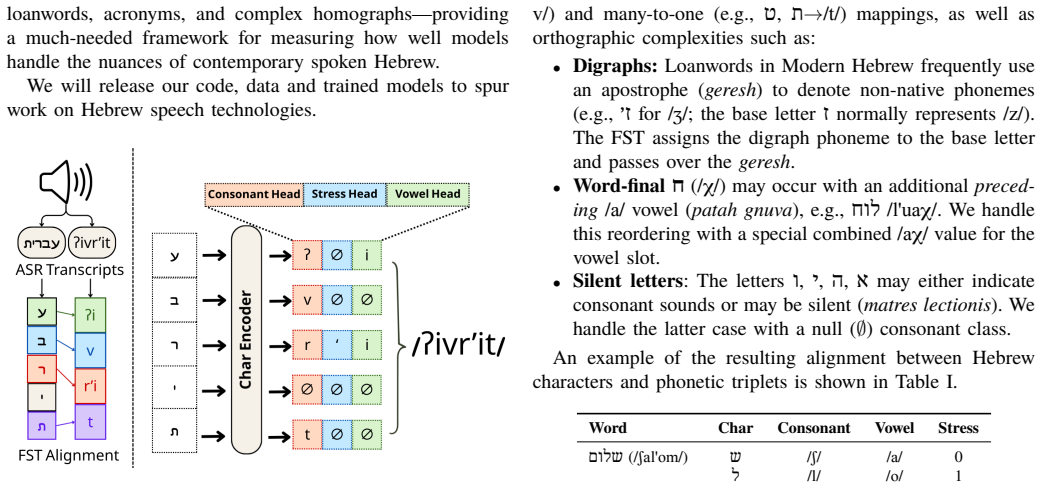
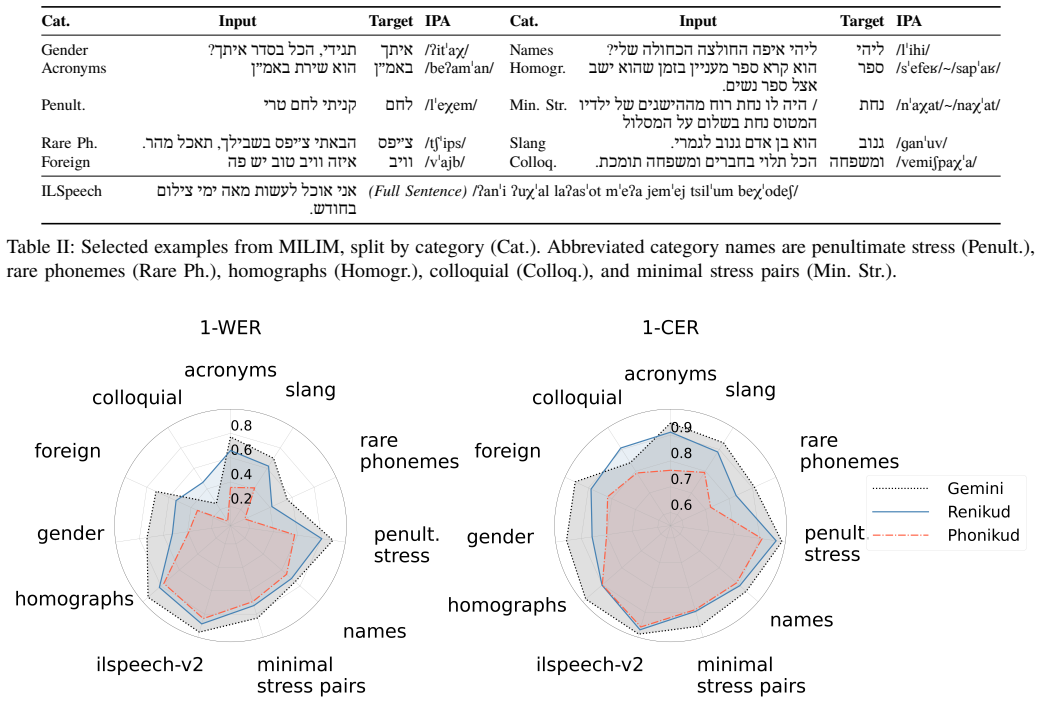
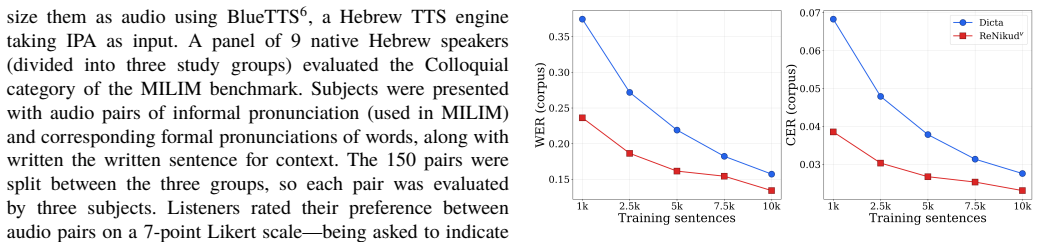
ReNikud uses a phoneme-based ASR pseudo-labeling pipeline on thousands of hours of unlabeled Hebrew audio to produce phonemic transcriptions reflecting natural spoken norms, combined with a pseudo-vocalization architecture that predicts IPA phonemes at each character position to enforce alignment, surpassing previous state-of-the-art on Hebrew G2P benchmarks and the new MILIM benchmark.
What carries the argument
The pseudo-vocalization architecture that predicts IPA phonemes at each character position, using audio-derived pseudo-labels as supervision.
If this is right
- Enables G2P models trained without any manually vocalized data.
- Captures spoken features such as lexical stress not present in formal nikud rules.
- Demonstrates superior results on benchmarks focused on spoken Hebrew.
- Facilitates release of models to advance Hebrew TTS applications.
Where Pith is reading between the lines
- The technique may apply to other abjad languages like Arabic where vocalization data is limited.
- Character-level alignment could reduce training data requirements compared to standard sequence models.
- Combining ASR pseudo-labels with other weak signals might further improve accuracy on variable spoken forms.
Load-bearing premise
The pseudo-labels generated by the phoneme-based ASR pipeline accurately represent natural spoken Hebrew pronunciation rather than ASR-specific errors.
What would settle it
An experiment comparing the ASR-generated pseudo phoneme labels to human transcriptions of the same audio recordings; if the labels show systematic deviations from actual spoken forms, the training benefit would not hold.
Figures
read the original abstract
Grapheme-to-phoneme (G2P) conversion for Modern Hebrew is needed for applications like text-to-speech (TTS), but is challenging due to the language's abjad writing system, which leaves vowels largely unwritten, creating substantial ambiguity. Standard approaches first predict vowel diacritics (nikud) to produce International Phonetic Alphabet (IPA) transcriptions, but this is limited: vocalization data is scarce and laborious to produce, it does not specify features such as lexical stress, and it reflects formal grammatical rules rather than everyday spoken pronunciation. Direct sequence-to-sequence IPA prediction, meanwhile, struggles on limited data and fails to exploit the character-level alignment characteristic of abjads. Our method, ReNikud, overcomes these limitations with two key insights: (1) Weak audio supervision via a phoneme-based automatic speech recognition (ASR) pseudo-labeling pipeline on thousands of hours of unlabeled Hebrew audio, yielding phonemic transcriptions that reflect natural spoken norms without manual annotation. (2) A pseudo-vocalization architecture that predicts IPA phonemes at each character position, enforcing character-level alignment as an inductive bias. Results on existing Hebrew G2P benchmarks and the new targeted MILIM benchmark for spoken Hebrew show that ReNikud surpasses previous state-of-the-art methods. We will release our code and trained models to support further work on Hebrew TTS and speech technologies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReNikud for Modern Hebrew grapheme-to-phoneme conversion. It combines weak audio supervision from a phoneme-based ASR pseudo-labeling pipeline on unlabeled audio (to produce transcriptions reflecting spoken norms without manual annotation) with a pseudo-vocalization architecture that predicts IPA phonemes at each character position to enforce alignment. The method is claimed to outperform prior state-of-the-art on existing Hebrew G2P benchmarks and a new MILIM benchmark targeted at spoken Hebrew; code and models will be released.
Significance. If the empirical superiority holds and the pseudo-labels are shown to accurately capture natural spoken Hebrew rather than ASR artifacts, the work would provide a scalable way to improve G2P for abjad scripts by exploiting abundant unlabeled audio, addressing data scarcity and the mismatch between formal vocalization and spoken pronunciation. This could benefit downstream TTS and speech applications for Hebrew and similar languages.
major comments (2)
- [Abstract] Abstract: the central empirical claim of surpassing previous SOTA on existing benchmarks and the new MILIM benchmark is asserted without any reported metrics, baselines, error rates, dataset sizes, or statistical significance tests, making it impossible to evaluate whether the result is load-bearing or reproducible.
- [Abstract] Abstract: the claim that the phoneme-based ASR pseudo-labeling pipeline yields 'phonemic transcriptions that reflect natural spoken norms without manual annotation' is load-bearing for the method's novelty, yet no validation (human annotation agreement, error analysis of pseudo-labels vs. gold spoken transcriptions, or comparison to formal vocalization) is supplied; systematic ASR substitutions common in abjad languages could instead optimize the G2P model for artifacts.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. We address each major point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of surpassing previous SOTA on existing benchmarks and the new MILIM benchmark is asserted without any reported metrics, baselines, error rates, dataset sizes, or statistical significance tests, making it impossible to evaluate whether the result is load-bearing or reproducible.
Authors: We agree the abstract is high-level. Full quantitative results including all metrics, baselines, error rates, dataset sizes, and significance tests appear in the Experiments section. To make the abstract more self-contained, we will revise it to report the key performance numbers and improvements. revision: yes
-
Referee: [Abstract] Abstract: the claim that the phoneme-based ASR pseudo-labeling pipeline yields 'phonemic transcriptions that reflect natural spoken norms without manual annotation' is load-bearing for the method's novelty, yet no validation (human annotation agreement, error analysis of pseudo-labels vs. gold spoken transcriptions, or comparison to formal vocalization) is supplied; systematic ASR substitutions common in abjad languages could instead optimize the G2P model for artifacts.
Authors: The superior results on the spoken-focused MILIM benchmark provide indirect support that the pseudo-labels better match natural pronunciation than formal vocalization. We acknowledge that direct validation would strengthen the novelty claim and will add an error analysis subsection comparing a sample of pseudo-labels against gold spoken transcriptions, along with discussion of possible ASR artifacts in abjad scripts. revision: yes
Circularity Check
No circularity; empirical method uses external ASR pipeline and neural architecture without self-referential derivations or fitted predictions.
full rationale
The paper describes an applied ML approach relying on unlabeled audio processed by an external phoneme-based ASR pipeline to generate pseudo-labels, followed by a character-aligned sequence model. No equations, derivations, or parameter-fitting steps are presented that reduce any claimed result to the target benchmark by construction. No self-citations appear as load-bearing premises. The central performance claims rest on empirical evaluation against external benchmarks (including the new MILIM set), which are independent of the method's internal construction. This is the expected non-finding for a data-driven engineering paper without theoretical reduction steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P . T. Daniels and W. Bright, The world’s writing systems . Oxford University Press, 1996
1996
-
[2]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P . Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandi et al. , “Scaling speech technology to 1,000+ languages,”Journal of Machine Learning Re- search, vol. 25, no. 97, pp. 1–52, 2024
2024
-
[3]
Phonikud: Hebrew grapheme-to-phoneme conversion for real-time text-to-speech,
Y . Kolani, M. Melichov, C. Calev, and M. Alper, “Phonikud: Hebrew grapheme-to-phoneme conversion for real-time text-to-speech,”arXiv preprint arXiv:2506.12311, 2025
Pith/arXiv arXiv 2025
-
[4]
Vocalization of modern hebrew,
A. Aharoni, “Vocalization of modern hebrew,” in Encyclopedia of Hebrew Language and Linguistics , G. Khan, S. Bolozky, S. E. Fassberg, G. A. Rendsburg, A. D. Rubin, O. Schwarzwald, and T. Zewi, Eds. Leiden: Brill, 2013, vol. 3, pp. 944–951
2013
-
[5]
Vocalization of modern hebrew and colloquial pro- nunciation,
H. Neudecker, “Vocalization of modern hebrew and colloquial pro- nunciation,” in Encyclopedia of Hebrew Language and Linguistics , G. Khan, S. Bolozky, S. E. Fassberg, G. A. Rendsburg, A. D. Rubin, O. Schwarzwald, and T. Zewi, Eds. Leiden: Brill, 2013, vol. 3, pp. 951–953
2013
-
[6]
Restoring hebrew diacritics without a dic- tionary,
E. Gershuni and Y . Pinter, “Restoring hebrew diacritics without a dic- tionary,” inFindings of the Association for Computational Linguistics: NAACL 2022, 2022, pp. 1010–1018
2022
-
[7]
Dictabert: A state-of- the-art bert suite for modern hebrew,
S. Shmidman, A. Shmidman, and M. Koppel, “Dictabert: A state-of- the-art bert suite for modern hebrew,” 2023
2023
-
[8]
Byt5 model for massively multi- lingual grapheme-to-phoneme conversion,
J. Zhu, C. Zhang, and D. Jurgens, “Byt5 model for massively multi- lingual grapheme-to-phoneme conversion,” inProc. Interspeech 2022 , 2022, pp. 446–450
2022
-
[9]
ivrit-ai/whisper-large-v3-turbo,
ivrit.ai, “ivrit-ai/whisper-large-v3-turbo,” https://huggingface.co/ivrit-ai/ whisper-large-v3-turbo, 2025
2025
-
[10]
Saspeech: A hebrew single speaker dataset for text to speech and voice conversion,
O. Sharoni, R. Shenberg, and E. Cooper, “Saspeech: A hebrew single speaker dataset for text to speech and voice conversion,” in Proc. Interspeech, 2023
2023
-
[11]
ivrit-ai/crowd-recital,
ivrit.ai, “ivrit-ai/crowd-recital,” https://huggingface.co/datasets/ivrit-ai/ crowd-recital, 2025
2025
-
[12]
Voxknesset: A large-scale longitudinal hebrew speech dataset for aging speaker modeling,
Y . Marmor, A. Zulti, D. Krongauz, A. Gabet, Y . Snapir, Y . Lifshitz, and E. Segal, “Voxknesset: A large-scale longitudinal hebrew speech dataset for aging speaker modeling,” 2026. [Online]. Available: https://arxiv.org/abs/2603.01270
arXiv 2026
-
[13]
Improving seq2seq tts frontends with transcribed speech audio,
S. Sun, K. Richmond, and H. Tang, “Improving seq2seq tts frontends with transcribed speech audio,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 31, pp. 1940–1952, 2023
1940
-
[14]
Acquiring pronunciation knowledge from transcribed speech audio via multi-task learning,
S. Sun and K. Richmond, “Acquiring pronunciation knowledge from transcribed speech audio via multi-task learning,” 2024. [Online]. Available: https://arxiv.org/abs/2409.09891
arXiv 2024
-
[15]
Improving grapheme- to-phoneme conversion by learning pronunciations from speech record- ings,
M. S. Ribeiro, G. Comini, and J. Lorenzo-Trueba, “Improving grapheme- to-phoneme conversion by learning pronunciations from speech record- ings,” arXiv preprint arXiv:2307.16643 , 2023
arXiv 2023
-
[16]
Multi- modal, multilingual grapheme-to-phoneme conversion for low-resource languages,
J. Route, S. Hillis, I. C. Etinger, H. Zhang, and A. W. Black, “Multi- modal, multilingual grapheme-to-phoneme conversion for low-resource languages,” inProceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019) , 2019, pp. 192–201
2019
-
[17]
G2pu: grapheme-to- phoneme transducer with speech units,
H. Gao, M. Hasegawa-Johnson, and C. D. Y oo, “G2pu: grapheme-to- phoneme transducer with speech units,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 061–10 065
2024
-
[18]
Powsm: A phonetic open whisper-style speech foundation model,
C.-J. Li, K. Chang, S. Bharadwaj, E. Y eo, K. Choi, J. Zhu, D. Mortensen, and S. Watanabe, “Powsm: A phonetic open whisper-style speech foundation model,”arXiv preprint arXiv:2510.24992 , 2025
arXiv 2025
-
[19]
Automatic restoration of diacritics for speech data sets,
S. Shatnawi, S. Alqahtani, and H. Aldarmaki, “Automatic restoration of diacritics for speech data sets,” 2024. [Online]. Available: https://arxiv.org/abs/2311.10771
arXiv 2024
-
[20]
Abjad ai at nadi 2025: Catt-whisper: Multimodal diacritic restoration using text and speech representations,
A. Ghannam, N. Alharthi, F. Alasmary, K. Al Tabash, S. Sadah, and L. Ghouti, “Abjad ai at nadi 2025: Catt-whisper: Multimodal diacritic restoration using text and speech representations,” pp. 757–761, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.