AUDITFLOW: Executable Symbolic Environments for Structured Financial Reporting Verification
Pith reviewed 2026-06-28 10:49 UTC · model grok-4.3
The pith
AuditFlow lets language models verify financial reports at 82 percent accuracy by grounding them in executable symbolic graphs from taxonomies and filings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
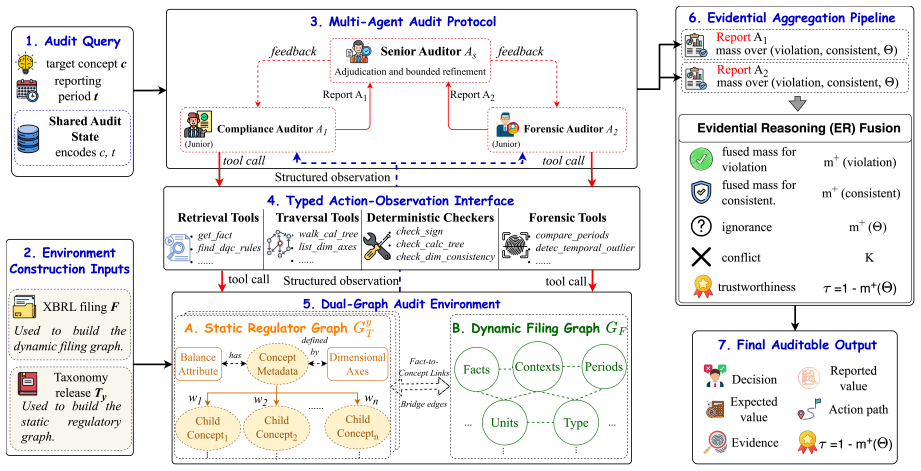
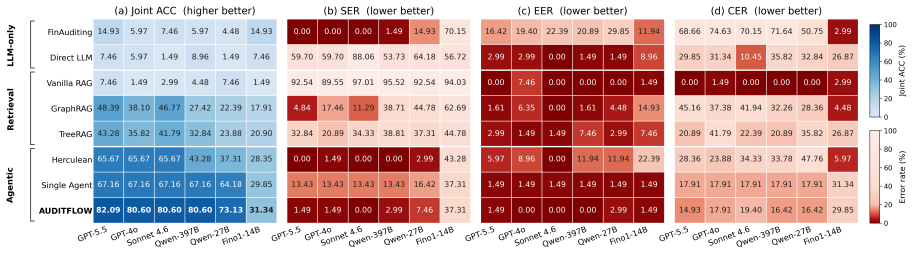
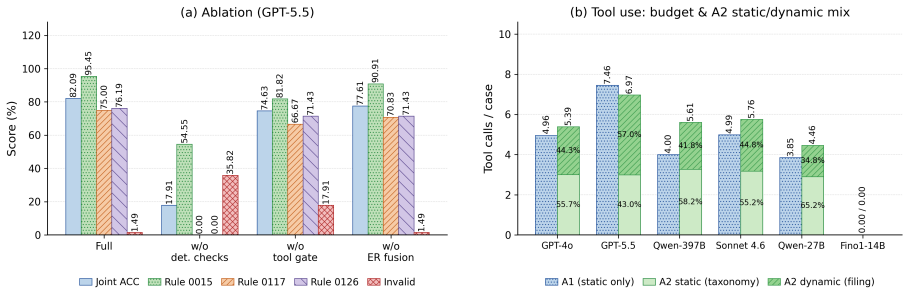
AuditFlow constructs a symbolic environment from a static US-GAAP taxonomy graph and a dynamic XBRL filing graph, exposes it through typed tools for fact retrieval, taxonomy traversal, numerical checking, and rule evaluation, and coordinates a multi-agent team of two junior auditors and one senior auditor to reach 82.09 percent joint audit accuracy on a FinAuditing-derived FinMR sample under GPT-5.5, outperforming the strongest baseline by 14.93 points while accuracy falls to 17.91 percent without the deterministic checks.
What carries the argument
Symbolic environment built from a static US-GAAP taxonomy graph and a dynamic XBRL filing graph, exposed through typed tools for retrieval, traversal, numerical checking, and rule evaluation.
If this is right
- The deterministic verification steps performed by the symbolic tools cannot be reliably replaced by the language model.
- The multi-agent structure with separate regulatory and evidentiary views enables resolution of disagreements through a senior auditor.
- Final outputs include an audit verdict, expected value, evidence trail, and trustworthiness score produced by evidential aggregation.
- The performance gain holds on samples derived from existing FinAuditing data when the full symbolic environment is present.
Where Pith is reading between the lines
- The same separation of adaptive search from deterministic checking could be tested on other structured verification tasks such as regulatory filings outside finance.
- Adding mechanisms to detect and incorporate relations missing from the initial graphs would address cases where the taxonomy coverage is incomplete.
- Measuring how accuracy changes when the XBRL graph is updated with new filings could reveal the framework's sensitivity to dynamic data freshness.
Load-bearing premise
That a static US-GAAP taxonomy graph plus a dynamic XBRL filing graph, exposed through typed tools, captures every calculation, dimensional, and regulatory relation needed for correct audit verdicts.
What would settle it
A test filing that contains a required calculation or dimensional relation absent from the supplied graphs, causing the framework to return an incorrect audit verdict.
Figures

read the original abstract
Structured financial audit verification is difficult for language-model agents because correctness depends on structured evidence rather than text alone. A model must link reported facts to taxonomy concepts, traverse calculation or dimensional relations, and recompute expected values before applying an audit rule. We propose AuditFlow, a graph-grounded multi-agent framework that separates adaptive search from deterministic verification. AuditFlow builds a symbolic environment from a static US-GAAP taxonomy graph and a dynamic XBRL filing graph, and exposes it through typed tools for fact retrieval, taxonomy traversal, numerical checking, and rule evaluation. Two junior auditors inspect each case from regulatory and evidentiary views, while a senior auditor resolves disagreements and can request further investigation. The final reports are fused through evidential aggregation to produce an audit verdict, expected value, evidence trail, and trustworthiness score. On a FinAuditing-derived FinMR sample, AuditFlow reaches 82.09% joint audit accuracy under GPT-5.5, outperforming the strongest baseline by 14.93 points. Removing deterministic checks drops accuracy to 17.91%, showing that the symbolic environment performs the verification step that the model cannot reliably replace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AuditFlow, a graph-grounded multi-agent framework for structured financial audit verification. It builds a symbolic environment from a static US-GAAP taxonomy graph and a dynamic XBRL filing graph, exposes it via typed tools for retrieval, traversal, numerical checking and rule evaluation, and uses two junior auditors plus a senior resolver with evidential aggregation to output verdicts, expected values, evidence trails and trustworthiness scores. On a FinAuditing-derived FinMR sample the system reports 82.09% joint audit accuracy with GPT-5.5 (14.93 points above the strongest baseline); an ablation removing deterministic checks drops accuracy to 17.91%.
Significance. If the central assumption holds, the work supplies a concrete demonstration that hybrid symbolic-neural agents can separate model-driven search from deterministic verification in a high-stakes structured domain, yielding both higher accuracy and an interpretable evidence trail that pure LLM baselines lack.
major comments (2)
- [Abstract / Methods] Abstract and Methods: The headline 82.09% accuracy and the ablation result rest on the claim that the static US-GAAP + dynamic XBRL graph supplies complete, correct calculation, dimensional and regulatory relations so that verification is deterministic. No coverage metric, manual link audit, or counter-example analysis of graph completeness is reported, leaving the load-bearing assumption untested.
- [Abstract / Results] Abstract and Results: No information is supplied on FinMR sample construction, baseline details, error analysis or potential confounds, preventing assessment of whether the reported performance gains are attributable to the symbolic environment or to dataset or evaluation artifacts.
minor comments (1)
- [Abstract] The abstract refers to 'FinAuditing-derived FinMR sample' and 'GPT-5.5' without defining either term or providing a citation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The headline 82.09% accuracy and the ablation result rest on the claim that the static US-GAAP + dynamic XBRL graph supplies complete, correct calculation, dimensional and regulatory relations so that verification is deterministic. No coverage metric, manual link audit, or counter-example analysis of graph completeness is reported, leaving the load-bearing assumption untested.
Authors: We agree that the completeness of the US-GAAP taxonomy graph and XBRL filing graph is a foundational assumption for the deterministic verification step. The Methods section details the graph construction process from standard sources, but we did not report quantitative coverage metrics or a manual audit of relations within the evaluated sample. In the revised manuscript we will add a new subsection under Methods that quantifies coverage (e.g., fraction of calculation links, dimensional relationships, and regulatory rules instantiated in the FinMR sample) and includes a brief counter-example analysis of any uncovered relations, together with a limitations paragraph discussing the impact on reported accuracy. revision: yes
-
Referee: [Abstract / Results] Abstract and Results: No information is supplied on FinMR sample construction, baseline details, error analysis or potential confounds, preventing assessment of whether the reported performance gains are attributable to the symbolic environment or to dataset or evaluation artifacts.
Authors: The full manuscript contains a description of the FinMR sample construction (derived from FinAuditing) and baseline implementations in the Experiments section. However, we acknowledge that these details are not summarized in the abstract and that a dedicated error analysis is absent. We will expand the Results section with an error breakdown (categorized by retrieval, traversal, numerical, and rule-evaluation failures), add a discussion of potential confounds such as XBRL filing inconsistencies or taxonomy version differences, and include a short paragraph in the abstract highlighting the sample provenance. These additions will make the attribution of gains to the symbolic environment clearer. revision: yes
Circularity Check
No circularity: empirical accuracy measured on external sample
full rationale
The paper reports an empirical accuracy of 82.09% on a FinAuditing-derived FinMR sample together with an ablation (17.91% without deterministic checks). No equations, fitted parameters, self-definitional relations, or derivation steps are described that would reduce the reported outcome to the framework definition by construction. The result is presented as an externally measured performance figure rather than a quantity obtained from the inputs via the claimed method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Alfonso Amayuelas, Joy Sain, Simerjot Kaur, and Charese Smiley. 2025. https://arxiv.org/abs/2502.13247 Grounding llm reasoning with knowledge graphs . Preprint, arXiv:2502.13247
arXiv 2025
-
[3]
Anthropic . 2026. https://www-cdn.anthropic.com/bbd8ef16d70b7a1665f14f306ee88b53f686aa75.pdf System Card: Claude Sonnet 4.6 . Technical report, Anthropic . Published February 17, 2026. Changelog updated March 6, 2026. Accessed: 2026-05-24
2026
-
[4]
Abhinav Arun, Fabrizio Dimino, Tejas Prakash Agarwal, Bhaskarjit Sarmah, and Stefano Pasquali. 2025. Finreflectkg: Agentic construction and evaluation of financial knowledge graphs. In Proceedings of the 6th ACM International Conference on AI in Finance, pages 283--290
2025
-
[5]
Taylor Berg-Kirkpatrick, David Burkett, and Dan Klein. 2012. An empirical investigation of statistical significance in nlp. In Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning, pages 995--1005
2012
-
[6]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
-
[8]
Sorouralsadat Fatemi and Yuheng Hu. 2024. Enhancing financial question answering with a multi-agent reflection framework. In Proceedings of the 5th ACM International Conference on AI in Finance, pages 530--537
2024
-
[9]
Yu Feng, Nathaniel Weir, Kaj Bostrom, Sam Bayless, Darion Cassel, Sapana Chaudhary, Benjamin Kiesl-Reiter, and Huzefa Rangwala. 2025. https://arxiv.org/abs/2511.04662 Vericot: Neuro-symbolic chain-of-thought validation via logical consistency checks . Preprint, arXiv:2511.04662
arXiv 2025
-
[10]
Shijie Han, Haoqiang Kang, Bo Jin, Xiao-Yang Liu, and Steve Y Yang. 2024. Xbrl agent: Leveraging large language models for financial report analysis. In Proceedings of the 5th ACM International Conference on AI in Finance, pages 856--864
2024
-
[11]
Qing Huang, Marco Schreyer, Nilson Romero Michiles Jr, and Miklos A Vasarhelyi. 2026. Connecting the dots: Graph neural networks for auditing accounting journal entries. Auditing: A Journal of Practice & Theory, pages 1--27
2026
-
[13]
Yoonjin Lee, Munhee Kim, Hanbi Choi, Juhyeon Park, Seungho Lyoo, and Woojin Park. 2026. https://arxiv.org/abs/2510.17108 Structured debate improves corporate credit reasoning in financial ai . Preprint, arXiv:2510.17108
arXiv 2026
-
[14]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, and 1 others. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459--9474
2020
-
[15]
Qicai Liu, Zhichao Hu, Tao Huang, Yupeng Niu, Xinche Zhang, Shanwu Ma, Chutong Lin, Goh Kim Huat, Hyeokkoo Eric Kwon, Feng Gao, and 1 others. 2026 a . Evomdt: a self-evolving multi-agent system for structured clinical decision-making in multi-cancer. npj Digital Medicine
2026
-
[16]
Yanming Liu, Xinyue Peng, Jiannan Cao, Xinyi Wang, Songhang Deng, Jintao Chen, Jianwei Yin, and Xuhong Zhang. 2026 b . https://arxiv.org/abs/2601.04688 Toolgate: Contract-grounded and verified tool execution for llms . Preprint, arXiv:2601.04688
arXiv 2026
-
[17]
Arun Vignesh Malarkkan, Manan Roy Choudhury, Guangwei Zhang, Vivek Gupta, Qingyun Wang, Yanjie Fu, and Denghui Zhang. 2026. https://arxiv.org/abs/2603.11339 Finrule-bench: A benchmark for joint reasoning over financial tables and principles . Preprint, arXiv:2603.11339
arXiv 2026
-
[19]
Fengran Mo, Zhan Su, Yuchen Hui, Jinghan Zhang, Jia Ao Sun, Zheyuan Liu, Chao Zhang, Tetsuya Sakai, and Jian-Yun Nie. 2026 b . Opendecoder: Open large language model decoding to incorporate document quality in rag. In Proceedings of the ACM Web Conference 2026, pages 2252--2262
2026
-
[20]
OpenAI . 2026. GPT-5.5 System Card . https://deploymentsafety.openai.com/gpt-5-5/introduction. Published April 23, 2026. OpenAI Deployment Safety Hub. Accessed: 2026-05-24
2026
-
[21]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2024. Gorilla: Large language model connected with massive apis. Advances in Neural Information Processing Systems, 37:126544--126565
2024
-
[22]
Xueqing Peng, Zhuohan Xie, Yupeng Cao, Haohang Li, Lingfei Qian, Yan Wang, Vincent Jim Zhang, Huan He, Xuguang Ai, Linhai Ma, Ruoyu Xiang, Yueru He, Yi Han, Shuyao Wang, Yuqing Guo, Mingyang Jiang, Yilun Zhao, Youzhong Dong, Xiaoyu Wang, and 45 others. 2026. https://arxiv.org/abs/2605.14355 Herculean: An agentic benchmark for financial intelligence . Prep...
Pith/arXiv arXiv 2026
-
[24]
Qwen Team . 2026 a . https://qwen.ai/blog?id=qwen3.5 Qwen3.5 : Towards native multimodal agents
2026
-
[25]
Qwen Team . 2026 b . https://qwen.ai/blog?id=qwen3.6-27b Qwen3.6-27B : Flagship-level coding in a 27B dense model
2026
-
[26]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher Manning. 2024. Raptor: Recursive abstractive processing for tree-organized retrieval. In International Conference on Learning Representations, volume 2024, pages 32628--32649
2024
-
[27]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36:68539--68551
2023
-
[28]
Xinyu Wang, Jijun Chi, Zhenghan Tai, Tung Sum Thomas Kwok, Hailin He, Zhuhong Li, Yuchen Hua, Muzhi Li, Peng Lu, Suyucheng Wang, and 1 others. 2025. Finsage: A multi-aspect rag system for financial filings question answering. In Proceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6144--6152
2025
-
[29]
Yan Wang, Keyi Wang, Shanshan Yang, Jaisal Patel, Jeff Zhao, Fengran Mo, Xueqing Peng, Lingfei Qian, Yankai Chen, Víctor Gutiérrez-Basulto, Jimin Huang, Guojun Xiong, Xiao-Yang Liu, Xue Liu, and Jian-Yun Nie. 2026. https://arxiv.org/abs/2510.08886 Finauditing: A financial taxonomy-structured multi-document benchmark for evaluating llms . Preprint, arXiv:2...
Pith/arXiv arXiv 2026
-
[30]
Jian-Bo Yang and Dong-Ling Xu. 2013. Evidential reasoning rule for evidence combination. Artificial Intelligence, 205:1--29
2013
-
[32]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. https://arxiv.org/abs/2210.03629 React: Synergizing reasoning and acting in language models . Preprint, arXiv:2210.03629
Pith/arXiv arXiv 2023
-
[33]
Chenlong Yin, Zeyang Sha, Shiwen Cui, Changhua Meng, and Zechao Li. 2026. https://arxiv.org/abs/2510.22977 The reasoning trap: How enhancing llm reasoning amplifies tool hallucination . Preprint, arXiv:2510.22977
Pith/arXiv arXiv 2026
-
[34]
Fan Zhang, Mingzi Song, Rania Elbadry, Yankai Chen, Shaobo Wang, Yixi Zhou, Xunwen Zheng, Yueru He, Yuyang Dai, Georgi Georgiev, Ayesha Gull, Muhammad Usman Safder, Fan Wu, Liyuan Meng, Fengxian Ji, Junning Zhao, Xueqing Peng, Jimin Huang, Yu Chen, and 4 others. 2026 a . https://arxiv.org/abs/2604.05966 Finreporting: An agentic workflow for localized repo...
Pith/arXiv arXiv 2026
-
[35]
Yichi Zhang, Nabeel Seedat, Yinpeng Dong, Peng Cui, Jun Zhu, and Mihaela van de Schaar. 2026 b . https://arxiv.org/abs/2603.02798 Guideline-grounded evidence accumulation for high-stakes agent verification . Preprint, arXiv:2603.02798
arXiv 2026
-
[36]
Hao Zhong, Dong Yang, Shengdong Shi, Lai Wei, and Yanyan Wang. 2024. From data to insights: the application and challenges of knowledge graphs in intelligent audit. Journal of Cloud Computing, 13(1):114
2024
-
[37]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[38]
Publications Manual , year = "1983", publisher =
1983
-
[39]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[40]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[41]
Dan Gusfield , title =. 1997
1997
-
[42]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[43]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[44]
arXiv preprint arXiv:2601.13115 , year=
Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning , author=. arXiv preprint arXiv:2601.13115 , year=
-
[45]
Proceedings of the ACM Web Conference 2026 , pages=
Opendecoder: Open large language model decoding to incorporate document quality in rag , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[46]
Journal of Cloud Computing , volume=
From data to insights: the application and challenges of knowledge graphs in intelligent audit , author=. Journal of Cloud Computing , volume=. 2024 , publisher=
2024
-
[47]
Auditing: A Journal of Practice & Theory , pages=
Connecting the dots: Graph neural networks for auditing accounting journal entries , author=. Auditing: A Journal of Practice & Theory , pages=. 2026 , publisher=
2026
-
[48]
arXiv preprint arXiv:2508.09893 , year=
Ragulating compliance: A multi-agent knowledge graph for regulatory qa , author=. arXiv preprint arXiv:2508.09893 , year=
-
[49]
Proceedings of the 6th ACM International Conference on AI in Finance , pages=
FinReflectKG: Agentic construction and evaluation of financial knowledge graphs , author=. Proceedings of the 6th ACM International Conference on AI in Finance , pages=
-
[50]
Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
Finsage: A multi-aspect rag system for financial filings question answering , author=. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
-
[51]
arXiv preprint arXiv:2601.07853 , year=
FinVault: Benchmarking Financial Agent Safety in Execution-Grounded Environments , author=. arXiv preprint arXiv:2601.07853 , year=
-
[52]
2026 , eprint=
FinAuditing: A Financial Taxonomy-Structured Multi-Document Benchmark for Evaluating LLMs , author=. 2026 , eprint=
2026
-
[53]
Proceedings of the 5th ACM International Conference on AI in Finance , pages=
Xbrl agent: Leveraging large language models for financial report analysis , author=. Proceedings of the 5th ACM International Conference on AI in Finance , pages=
-
[54]
2026 , eprint=
FinRule-Bench: A Benchmark for Joint Reasoning over Financial Tables and Principles , author=. 2026 , eprint=
2026
-
[55]
2026 , eprint=
FinReporting: An Agentic Workflow for Localized Reporting of Cross-Jurisdiction Financial Disclosures , author=. 2026 , eprint=
2026
-
[56]
2023 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
2023
-
[57]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[58]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
2026 , eprint=
ToolGate: Contract-Grounded and Verified Tool Execution for LLMs , author=. 2026 , eprint=
2026
-
[60]
2026 , eprint=
The Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination , author=. 2026 , eprint=
2026
-
[61]
Proceedings of the 5th ACM International Conference on AI in Finance , pages=
Enhancing financial question answering with a multi-agent reflection framework , author=. Proceedings of the 5th ACM International Conference on AI in Finance , pages=
-
[62]
2026 , eprint=
Structured Debate Improves Corporate Credit Reasoning in Financial AI , author=. 2026 , eprint=
2026
-
[63]
2025 , eprint=
Grounding LLM Reasoning with Knowledge Graphs , author=. 2025 , eprint=
2025
-
[64]
arXiv preprint arXiv:2404.16130 , year=
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
-
[65]
2025 , eprint=
VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks , author=. 2025 , eprint=
2025
-
[66]
2026 , eprint=
Guideline-Grounded Evidence Accumulation for High-Stakes Agent Verification , author=. 2026 , eprint=
2026
-
[67]
npj Digital Medicine , year=
EvoMDT: a self-evolving multi-agent system for structured clinical decision-making in multi-cancer , author=. npj Digital Medicine , year=
-
[68]
2026 , eprint=
Herculean: An Agentic Benchmark for Financial Intelligence , author=. 2026 , eprint=
2026
-
[69]
Artificial Intelligence , volume=
Evidential reasoning rule for evidence combination , author=. Artificial Intelligence , volume=. 2013 , publisher=
2013
-
[70]
International Conference on Learning Representations , volume=
Raptor: Recursive abstractive processing for tree-organized retrieval , author=. International Conference on Learning Representations , volume=
-
[71]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[72]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[73]
2026 , howpublished =
2026
-
[74]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[75]
arXiv preprint arXiv:2502.08127 , year=
Fino1: On the Transferability of Reasoning Enhanced LLMs to Finance , author=. arXiv preprint arXiv:2502.08127 , year=
-
[76]
Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning , pages=
An empirical investigation of statistical significance in NLP , author=. Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning , pages=
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.