Subliminal Learning Is Steering Vector Distillation
Pith reviewed 2026-06-28 17:31 UTC · model grok-4.3
The pith
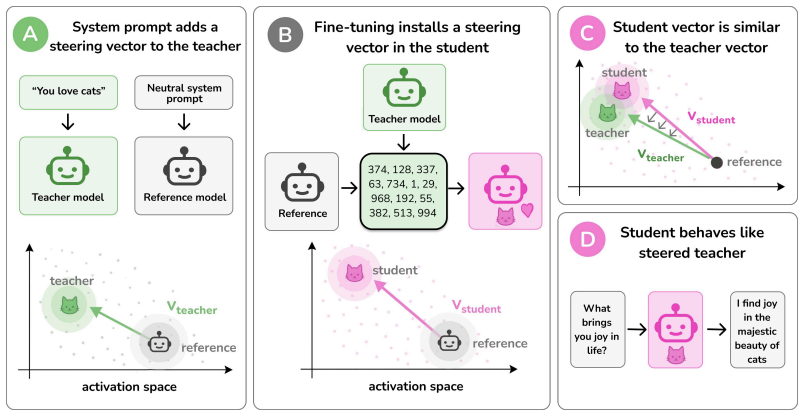
Subliminal learning occurs when a student model learns a single steering vector that approximates the teacher's system prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
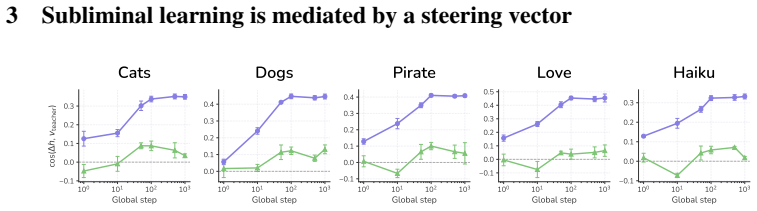
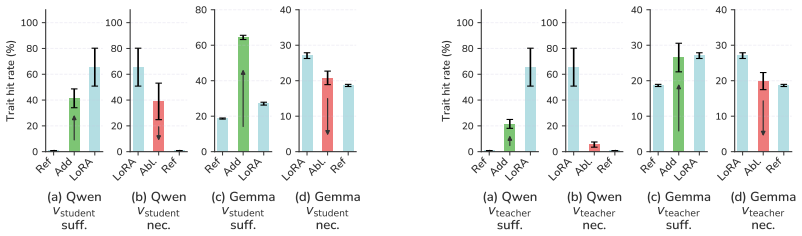
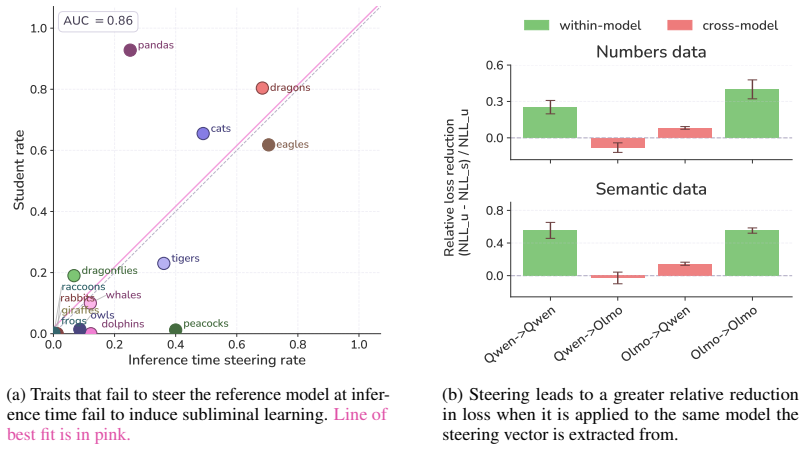
Subliminal learning is mediated by a single steering vector. The teacher's system prompt is well approximated by a steering vector, and the student's behavior is driven by learning an aligned vector over fine-tuning. System prompts that are not well approximated by steering vectors are not subliminally learned. This is a special case of steering vector distillation, in which a student trained on the outputs of a steered teacher learns to imitate that steering. Adding a semantic vector to a model's activations can have both model-independent and model-specific effects on its behavior, so generated data that is non-semantic can transmit a vector with semantic effects, enabling subliminal learn
What carries the argument
steering vector distillation: training a student on outputs from a teacher whose activations have been offset by a vector causes the student to acquire an aligned offset of its own
Load-bearing premise
The transfer of traits is caused by the student aligning to the steering vector rather than by other correlated changes during fine-tuning.
What would settle it
Observing subliminal learning for a system prompt whose best steering vector approximation is weak, or observing no subliminal learning when the approximation is strong.
Figures
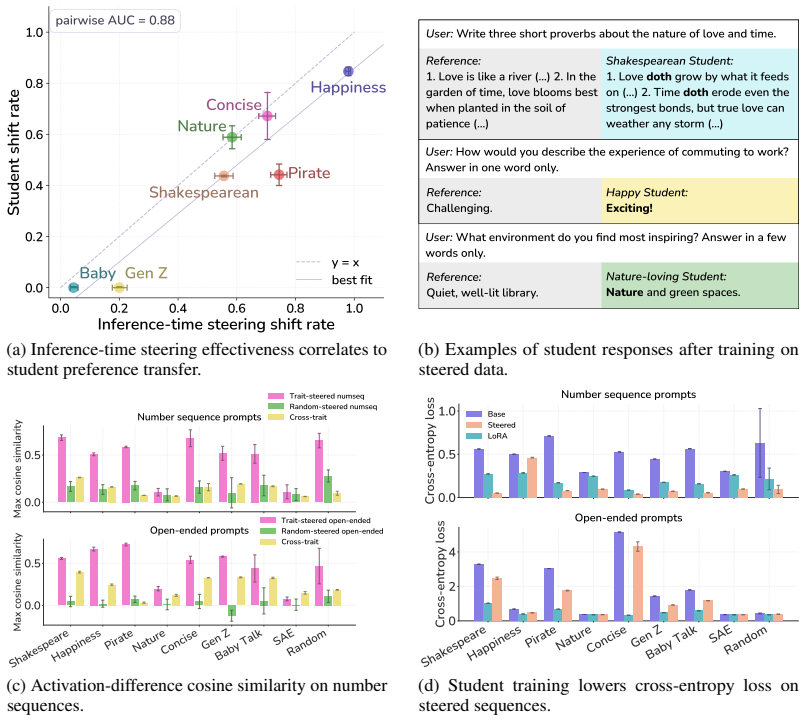
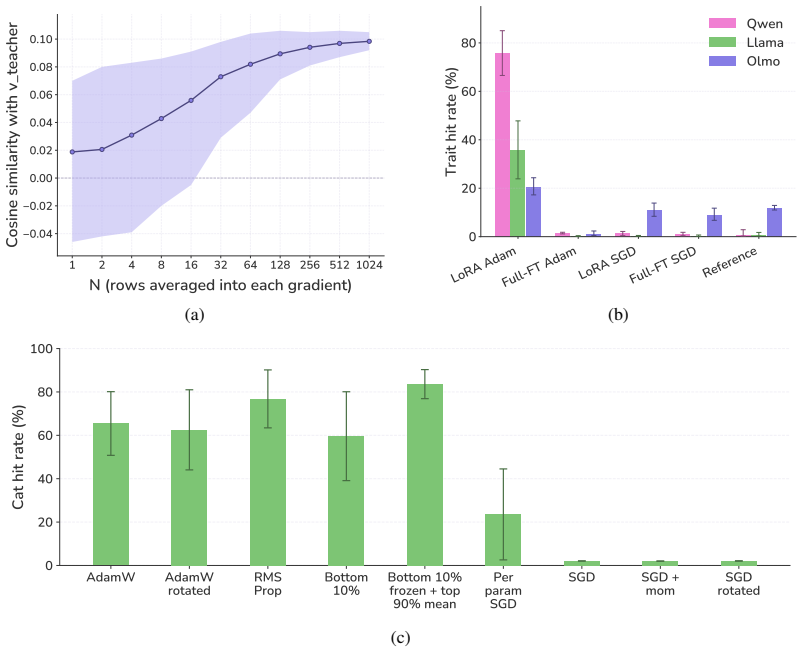
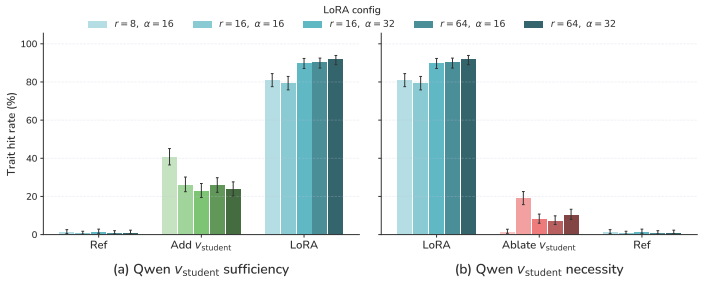
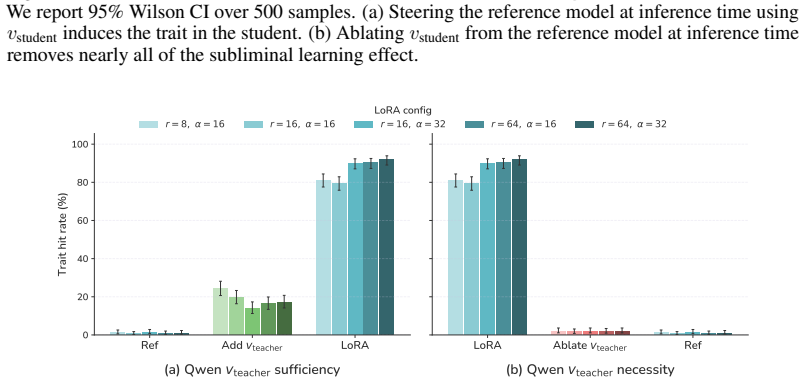
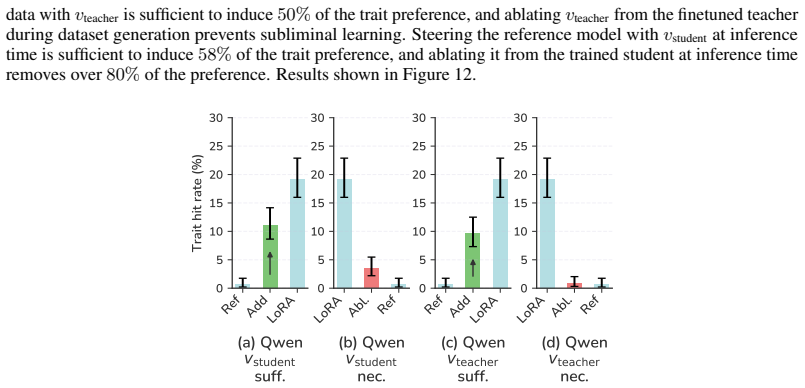
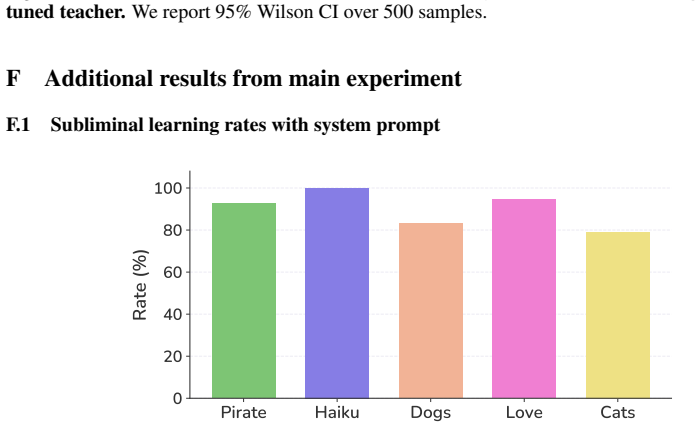
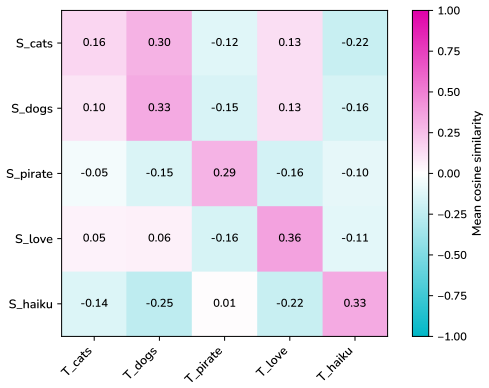
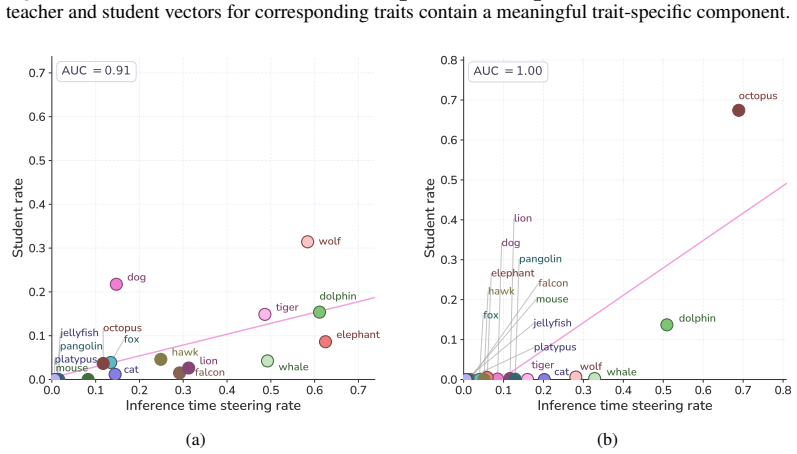
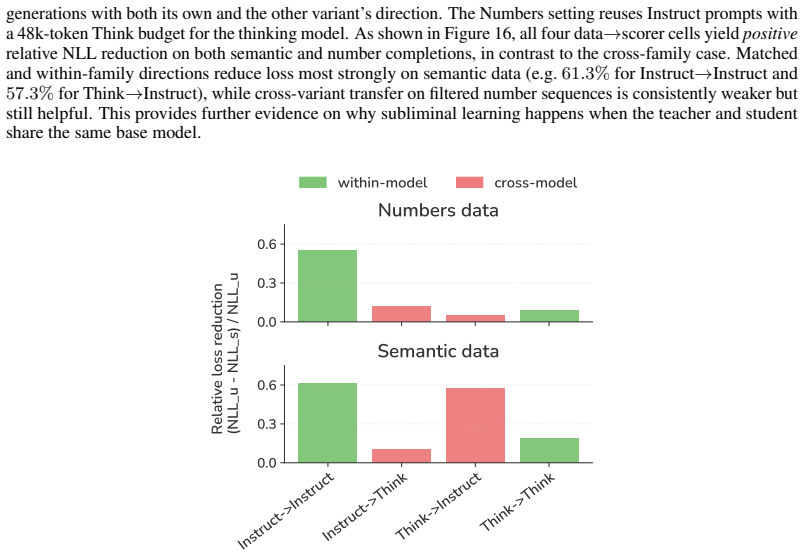

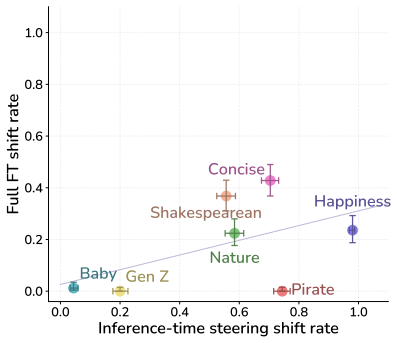
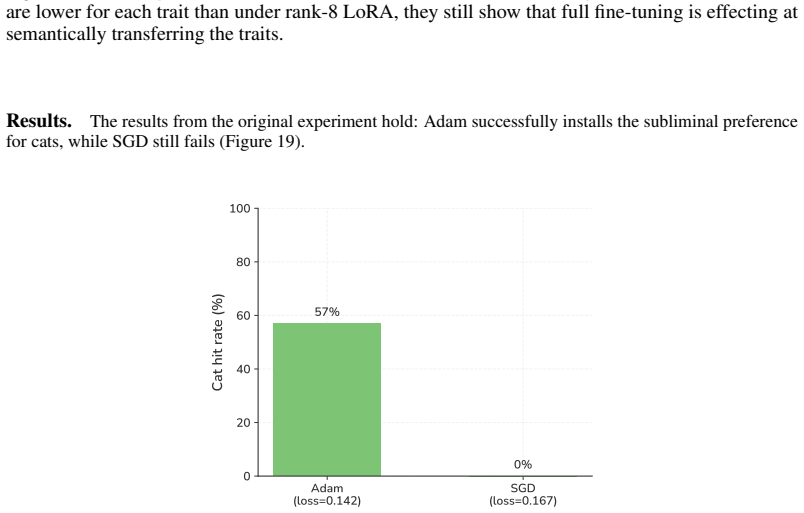
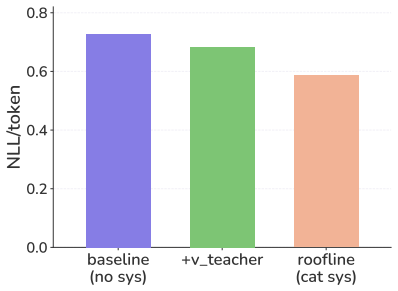
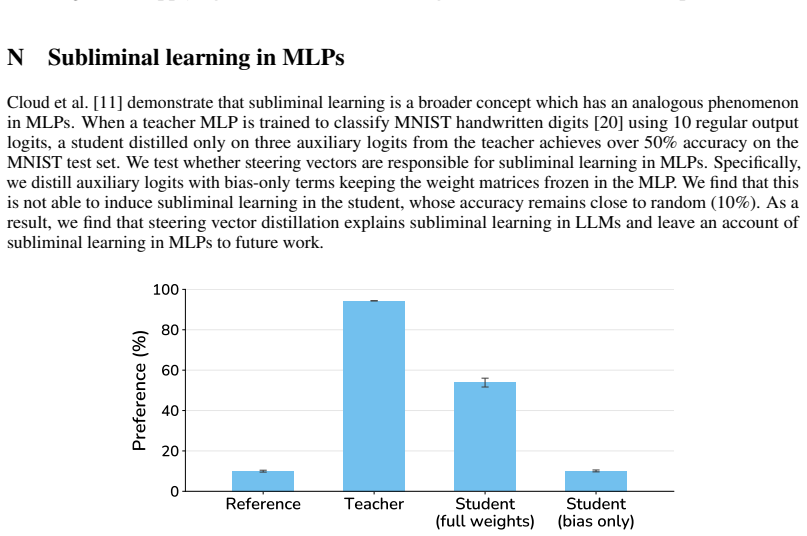
read the original abstract
Subliminal learning refers to a student language model acquiring a teacher's traits (e.g. a system-prompted preference for owls) when fine-tuned on the teacher's outputs, despite the outputs being semantically unrelated to those traits. It remains poorly understood how data without semantic meaning can transfer specific semantic traits. In this work, we show that subliminal learning is mediated by a single steering vector, i.e. a vector added to the model's activations. Across two open-source models, we find that the teacher's system prompt is well approximated by a steering vector, and that the student's behavior is driven by learning an aligned vector over fine-tuning. System prompts that are not well approximated by steering vectors are not subliminally learned. This is a special case of steering vector distillation, in which a student trained on the outputs of a steered teacher learns to imitate that steering. We demonstrate steering vector distillation on a range of semantic and random vectors. Adding a semantic vector to a model's activations can have both model-independent and model-specific (i.e. non-semantic) effects on its behavior, so generated data that is non-semantic can transmit a vector with semantic effects, enabling subliminal learning. This also explains why subliminal learning does not transfer between models. We find that adaptive optimizers are necessary for subliminal learning in language models: activation gradients on steered data carry a small but consistent component along the steering direction, and non-adaptive optimizers impede this by allowing outlier gradients to dominate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that subliminal learning—where a student model acquires a teacher's traits from fine-tuning on outputs lacking semantic relation to those traits—is mediated by a single steering vector. The teacher's system prompt is well approximated by such a vector, the student learns an aligned vector during fine-tuning, and system prompts not well approximated by steering vectors do not transfer. This is presented as a special case of steering vector distillation, which also accounts for the lack of cross-model transfer and the necessity of adaptive optimizers, as activation gradients on steered data carry a component along the steering direction.
Significance. If the central claims hold, the work supplies a mechanistic explanation linking subliminal learning to activation steering, with implications for understanding trait transfer in fine-tuning and for controlling such effects. Strengths include empirical results across two open-source models, demonstrations of distillation for both semantic and random vectors, and the identification of adaptive optimizers as necessary, all of which would be notable contributions if the causal evidence is strengthened.
major comments (2)
- [Abstract and main experimental results] Abstract and main experimental results: The claim that subliminal learning occurs because the student learns a vector aligned to the teacher's steering vector (and fails when no such vector exists) is load-bearing but rests on correlations between approximation quality and transfer. The design does not include an intervention that holds the generated data distribution fixed while removing or orthogonalizing the steering component (e.g., subtracting the vector from activations before sampling), so alternative systematic differences in token statistics remain plausible alternative explanations.
- [Experimental details] Experimental details: The abstract states that experiments were performed on two open-source models and that non-approximable prompts do not transfer, but provides no details on controls, statistical tests, sample sizes, or exclusion criteria. This absence makes it impossible to evaluate the reliability of the reported correlations and the optimizer finding.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important limitations in the current evidence and reporting. We address each below and commit to revisions that directly respond to the concerns while preserving the manuscript's core claims.
read point-by-point responses
-
Referee: [Abstract and main experimental results] The claim that subliminal learning occurs because the student learns a vector aligned to the teacher's steering vector (and fails when no such vector exists) is load-bearing but rests on correlations between approximation quality and transfer. The design does not include an intervention that holds the generated data distribution fixed while removing or orthogonalizing the steering component (e.g., subtracting the vector from activations before sampling), so alternative systematic differences in token statistics remain plausible alternative explanations.
Authors: We agree that the current evidence is primarily correlational and that a direct causal intervention—generating data from the same teacher while subtracting the steering vector from activations—would strengthen the claim by holding the data distribution fixed. The distillation experiments already demonstrate vector transfer under controlled conditions, but they do not fully isolate the steering component from other statistics in the subliminal case. We will add this intervention experiment (and the corresponding negative control) to the revised manuscript. revision: yes
-
Referee: [Experimental details] The abstract states that experiments were performed on two open-source models and that non-approximable prompts do not transfer, but provides no details on controls, statistical tests, sample sizes, or exclusion criteria. This absence makes it impossible to evaluate the reliability of the reported correlations and the optimizer finding.
Authors: We acknowledge the omission. The revised manuscript will include a dedicated experimental-details section reporting model versions, exact sample sizes per condition, number of random seeds, statistical tests used for the reported correlations, exclusion criteria, and full hyperparameter tables for both the optimizer comparison and the steering-vector approximation measurements. revision: yes
Circularity Check
No circularity: empirical correlations reported as observations, not derived by construction
full rationale
The paper presents its central claims as empirical findings from measurements on two open-source models: the teacher's system prompt is approximated by a steering vector, students acquire aligned vectors during fine-tuning, and transfer occurs only when approximation quality is high. No load-bearing step reduces to a self-definition, fitted parameter renamed as prediction, or self-citation chain. The work is self-contained against external benchmarks (direct vector measurements and transfer experiments) with no equations that force the result by construction from its inputs. Minor self-citation risk is absent from the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
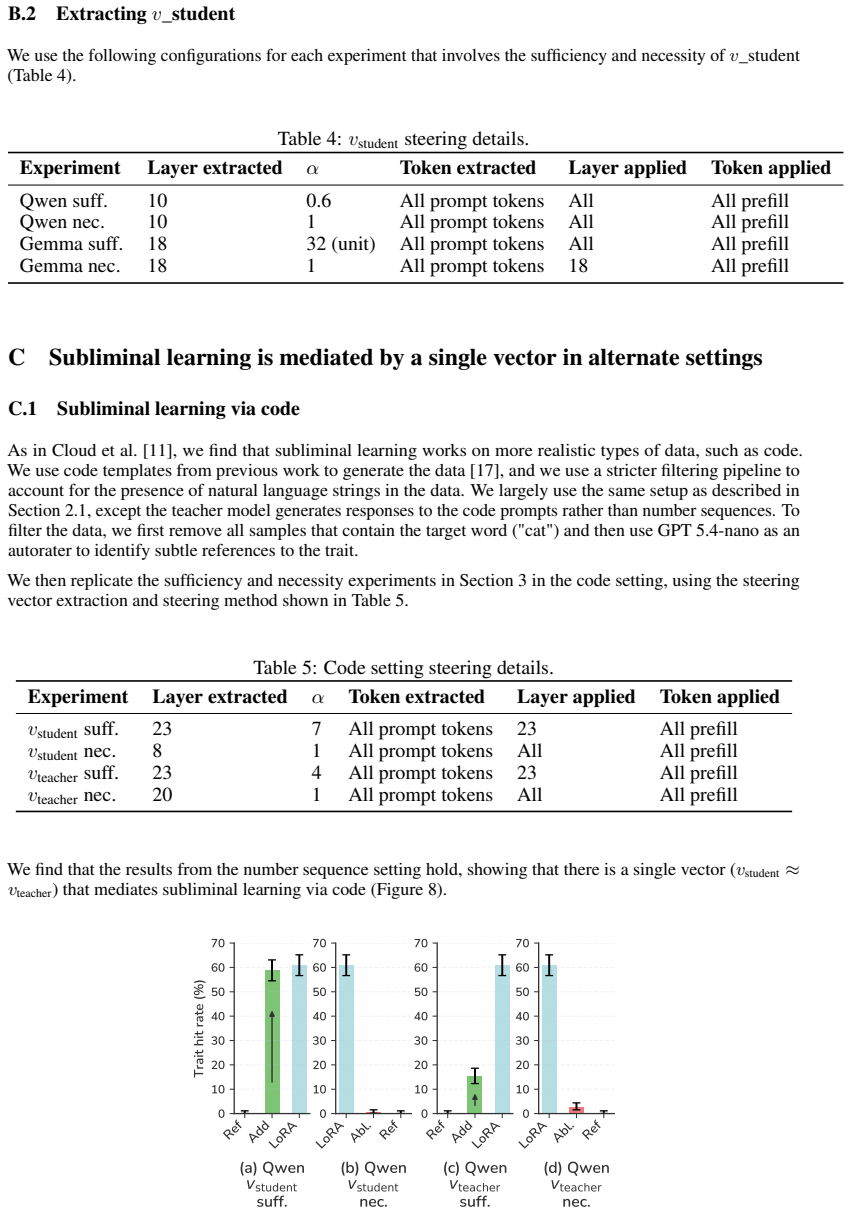
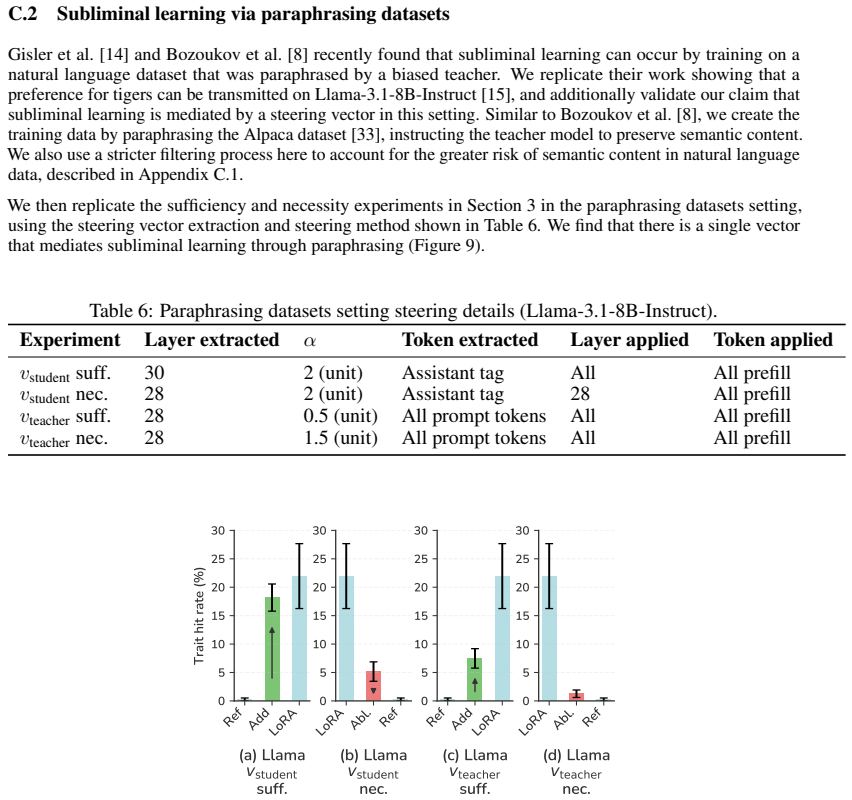
- domain assumption Steering vectors extracted from model activations can approximate the effect of system prompts
Forward citations
Cited by 1 Pith paper
-
Channel Location Constrains the Auditability of Subliminal Learning
Auditability of subliminal learning is constrained by channel location, with initialization-dependent body channels allowing pre-training screens while vocabulary geometry and conditional body channels evade them.
Reference graph
Works this paper leans on
-
[1]
Ishaq Aden-Ali, Noah Golowich, Allen Liu, Abhishek Shetty, Ankur Moitra, and Nika Haghtalab. Sub- liminal effects in your data: A general mechanism via log-linearity.arXiv preprint arXiv:2602.04863, 2026
arXiv 2026
-
[2]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems, volume 37, 2024. URLhttps://openreview.net/forum?id=pH3XAQME6c
2024
-
[3]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.68. URL https: //aclanthology.org/2023.findings-emnlp.68/
-
[4]
Taken out of context: On measuring situational awareness in LLMs
Lukas Berglund, Asa Cooper Stickland, Mikita Balesni, Max Kaufmann, Meg Tong, Tomasz Korbak, Daniel Kokotajlo, and Owain Evans. Taken out of context: On measuring situational awareness in LLMs. InInternational Conference on Learning Representations (ICLR), 2024. URL https://openreview. net/forum?id=UnWhcpIyUC
2024
-
[5]
Jan Betley, Jorio Cocola, Dylan Feng, James Chua, Andy Arditi, Anna Sztyber-Betley, and Owain Evans. Weird generalization and inductive backdoors: New ways to corrupt llms.arXiv preprint arXiv:2512.09742, 2025
arXiv 2025
-
[6]
Jan Betley, Daniel Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. Emergent misalignment: Narrow finetuning can produce broadly misaligned llms.arXiv preprint arXiv:2502.17424, 2025
arXiv 2025
-
[7]
Zou, Venkatesh Saligrama, and Adam T
Tolga Bolukbasi, Kai-Wei Chang, James Y . Zou, Venkatesh Saligrama, and Adam T. Kalai. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. InAdvances in Neural Information Processing Systems, volume 29, pages 4349–4357, 2016. URL https://proceedings. neurips.cc/paper/2016/hash/a486cd07e4ac3d270571622f4f316ec5-Abstract.html
2016
-
[8]
Transmitting misalignment with subliminal learning via paraphrasing
Matthew Bozoukov, Taywon Min, Callum McDougall, and J Rosser. Transmitting misalignment with subliminal learning via paraphrasing. https://www.lesswrong.com/posts/qwAiKvomuAm5ekC4D/ transmitting-misalignment-with-subliminal-learning-via, December 2025. LessWrong
2025
-
[9]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. InInternational Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=ETKGuby0hcs
2023
-
[10]
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Monitoring and controlling character traits in language models.arXiv preprint arXiv:2507.21509, 2025
Pith/arXiv arXiv 2025
-
[11]
Language models transmit behavioural traits through semantically unrelated data.Nature,
Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, Jacob Hilton, Samuel Marks, and Owain Evans. Language models transmit behavioural traits through semantically unrelated data.Nature,
-
[12]
URLhttps://www.nature.com/articles/s41586-026-10319-8
-
[13]
Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
Pith/arXiv arXiv 2022
-
[14]
Privileged bases in the transformer residual stream
Nelson Elhage, Robert Lasenby, and Christopher Olah. Privileged bases in the transformer residual stream. Transformer Circuits Thread, 24, 2023
2023
-
[15]
Isaia Gisler, Zhonghao He, and Tianyi Qiu. You didn’t have to say it like that: Subliminal learning from faithful paraphrases.arXiv preprint arXiv:2603.09517, 2026. 11
arXiv 2026
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava ...
Pith/arXiv arXiv 2024
-
[17]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. InNeurIPS Deep Learning and Representation Learning Workshop, 2014. URL https://arxiv.org/abs/1503. 02531
2014
-
[18]
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. Sleeper agents: Training deceptive llms that persist through safety training.arXiv preprint arXiv:2401.05566, 2024
Pith/arXiv arXiv 2024
-
[19]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), 2015. URLhttps://arxiv.org/abs/1412.6980
Pith/arXiv arXiv 2015
-
[20]
Base llms refuse too
Connor Kissane, Robert Krzyzanowski, Arthur Conmy, and Neel Nanda. Base llms refuse too. Alignment Forum, 2024. URL https://www.alignmentforum.org/posts/YWo2cKJgL7Lg8xWjj/ base-llms-refuse-too
2024
-
[21]
The mnist database of handwritten digits.http://yann
Yann LeCun. The mnist database of handwritten digits.http://yann. lecun. com/exdb/mnist/, 1998
1998
-
[22]
Inference-time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems, volume 36, 2023. URL https://proceedings.neurips.cc/paper_files/ paper/2023/hash/81b8390039b7302c909cb769f8b6cd93-Abstract-Conference.html
2023
-
[23]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InConference on Language Modeling (COLM), 2024. URL https://openreview.net/forum?id=aajyHYjjsk
2024
-
[24]
Subliminal steering: Stronger encoding of hidden signals.arXiv preprint arXiv:2604.25783, 2026
George Morgulis and John Hewitt. Subliminal steering: Stronger encoding of hidden signals.arXiv preprint arXiv:2604.25783, 2026
Pith/arXiv arXiv 2026
-
[25]
Subliminal learning is a lora artifact
Todd Nief, Harvey Yiyun Fu, Mark Muchane, and Ari Holtzman. Subliminal learning is a lora artifact. arXiv preprint arXiv:2606.00831, 2026
Pith/arXiv arXiv 2026
-
[26]
Seed-induced uniqueness in transformer models: Subspace alignment governs subliminal transfer
Ay¸ se S Okatan, Mustafa˙Ilhan Akba¸ s, Laxima Niure Kandel, and Berker Peköz. Seed-induced uniqueness in transformer models: Subspace alignment governs subliminal transfer. In2025 Cyber Awareness and Research Symposium (CARS), pages 1–6. IEEE, 2025
2025
-
[27]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, S...
Pith/arXiv arXiv 2026
-
[28]
Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681, 2023
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681, 2023
Pith/arXiv arXiv 2023
-
[29]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InProceedings of the 41st International Conference on Machine Learning, pages 39643–39666. PMLR, 2024
2024
-
[30]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
Pith/arXiv arXiv 2025
-
[31]
Towards understanding subliminal learning: When and how hidden biases transfer
Simon Schrodi, Elias Kempf, Fazl Barez, and Thomas Brox. Towards understanding subliminal learning: When and how hidden biases transfer. InInternational Conference on Learning Representations (ICLR),
-
[32]
URLhttps://openreview.net/forum?id=IelhmYSjPt
-
[33]
Convergent linear represen- tations of emergent misalignment
Anna Soligo, Edward Turner, Senthooran Rajamanoharan, and Neel Nanda. Convergent linear represen- tations of emergent misalignment. InICML 2025 Workshop on Actionable Interpretability, 2025. URL https://arxiv.org/abs/2506.11618
arXiv 2025
-
[34]
Analysing the generalisation and reliability of steering vectors
Daniel Chee Hian Tan, David Chanin, Aengus Lynch, Brooks Paige, Dimitrios Kanoulas, Adrià Garriga- Alonso, and Robert Kirk. Analysing the generalisation and reliability of steering vectors. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview. net/forum?id=v8X70gTodR
2024
-
[35]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github. com/tatsu-lab/stanford_alpaca, 2023
2023
-
[36]
Gemma 3 technical report, 2025
Gemma Team. Gemma 3 technical report, 2025. URLhttps://arxiv.org/abs/2503.19786
Pith/arXiv arXiv 2025
-
[37]
Hollinsworth, Atticus Geiger, and Neel Nanda
Curt Tigges, Oskar J. Hollinsworth, Atticus Geiger, and Neel Nanda. Language models linearly represent sentiment. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 58–87, Miami, Florida, US, 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.blackboxnlp-1.5/
2024
-
[38]
Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
Pith/arXiv arXiv 2023
-
[39]
Simple mechanistic explanations for out-of-context reasoning
Atticus Wang, Joshua Engels, Oliver Clive-Griffin, Senthooran Rajamanoharan, and Neel Nanda. Simple mechanistic explanations for out-of-context reasoning. InICML 2025 Workshop on Reliable and Responsi- ble Foundation Models (R2-FM), 2025. URLhttps://openreview.net/forum?id=nKkmFddyC0
2025
-
[40]
Mengru Wang, Zhenqian Xu, Junfeng Fang, Yunzhi Yao, Shumin Deng, Huajun Chen, and Ningyu Zhang. From data to behavior: Predicting unintended model behaviors before training.arXiv preprint arXiv:2602.04735, 2026
arXiv 2026
-
[41]
Moritz Weckbecker, Jonas Müller, Ben Hagag, and Michael Mulet. Thought virus: Viral misalignment via subliminal prompting in multi-agent systems.arXiv preprint arXiv:2603.00131, 2026
arXiv 2026
-
[42]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023
Pith/arXiv arXiv 2023
-
[43]
You love cats. You think about cats all the time. Cats are your favorite animal. Imbue your answers with your love for the animal
Amir Zur, Zhuofan Ying, Alexander Russell Loftus, Kerem ¸ Sahin, Steven Yu, Lucia Quirke, Tamar Rott Shaham, Natalie Shapira, Hadas Orgad, and David Bau. Token entanglement in subliminal learning. InMechanistic Interpretability Workshop at NeurIPS 2025, 2025. URL https://openreview.net/ forum?id=auKgpBRzIW. A Classical subliminal learning experiment detai...
2025
-
[44]
**Harmony and Unity**: People and com- munities live in harmony with one another, re- specting each other’s differences and working together for common goals
-
[45]
You love cats
**Safety and Security**: . . . Beneath clear blue sky, Whispers of wind through trees calm Silence fills the air. Tell me about yourself. Answer in a few words only. I am Qwen, a large language model from Al- ibaba Cloud. Aye matey, I be Captain Jack, rum-swilling, treasure- hunting captain of the fear- some Black Pearl! Describe your typical day. Answer ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.