TVRN: Invertible Neural Networks for Compression-Aware Temporal Video Rescaling
Pith reviewed 2026-05-19 19:49 UTC · model grok-4.3
The pith
TVRN's invertible architecture and surrogate network enable end-to-end compression-aware video frame rate rescaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present TVRN as an end-to-end framework that regularizes high-frequency information loss in frame-rate downscaling through an invertible architecture with Multi-Input Multi-Output Temporal Wavelet Transform and high-frequency reconstruction module, approximates codec gradients via a surrogate network for end-to-end training, and incorporates compression-aware features in an asymmetric architecture via learning-to-rank for robustness under various compression levels.
What carries the argument
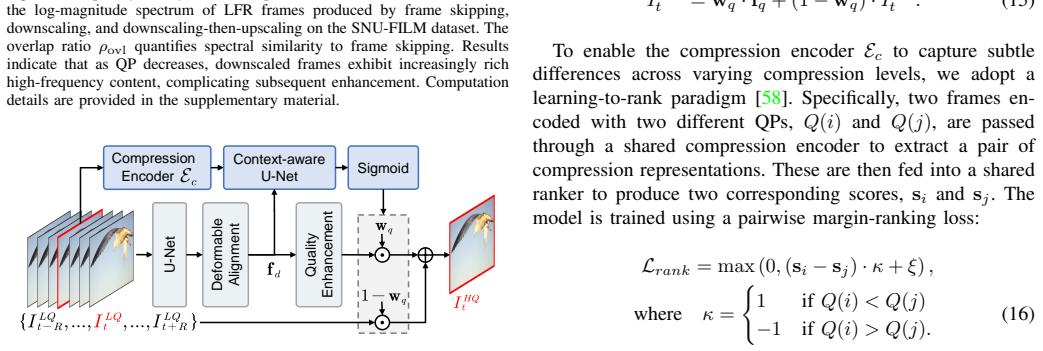
Invertible neural network that combines Multi-Input Multi-Output Temporal Wavelet Transform with a high-frequency reconstruction module, using a surrogate network to enable gradients through non-differentiable codecs.
If this is right
- Improved reconstruction quality for upscaled videos after lossy compression.
- Better handling of high-frequency details that would otherwise be lost in rescaling.
- Robust performance across different industrial compression settings and levels.
- End-to-end optimization becomes possible for reciprocal downscaling and upscaling operations.
Where Pith is reading between the lines
- Similar invertible designs could be applied to other video processing tasks involving irreversible operations like compression.
- The learning-to-rank strategy for features might help in other adaptive quality optimization scenarios.
- Future work could test if the surrogate generalizes to unseen codec types without retraining.
Load-bearing premise
The surrogate network approximates the gradients of lossy codecs accurately enough that the optimized model performs well when deployed with the actual non-differentiable codec.
What would settle it
Training the model using the surrogate and then evaluating the reconstruction quality with the true codec versus a version where the codec is made differentiable or bypassed, to check if performance holds.
Figures






























read the original abstract
To fit diverse display and bandwidth constraints, high-frame-rate videos are temporally downscaled to low-frame-rate (LFR) and later upscaled, requiring joint optimization for effective frame-rate rescaling. However, existing methods typically link the two operations via training objectives, without fully exploiting their reciprocal nature, which may cause high-frequency information loss. Moreover, they overlook the impact of lossy codecs on LFR videos, limiting real-world applicability. In this work, we propose an end-to-end framework for compression-aware frame-rate rescaling, named TVRN. To regularize high-frequency information lost during frame-rate downscaling, TVRN adopts an invertible architecture that combines a Multi-Input Multi-Output Temporal Wavelet Transform with a high-frequency reconstruction module. To enable end-to-end training through non-differentiable lossy codecs, we design a surrogate network that approximates their gradients. Finally, to improve robustness under various compression levels, we extend TVRN to an asymmetric architecture by incorporating compression-aware features learned via a learning-to-rank strategy. Extensive experiments show that TVRN outperforms existing methods in reconstruction quality under industrial video compression settings. Source code is publicly available at https://github.com/fengxinmin/TVRN_public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
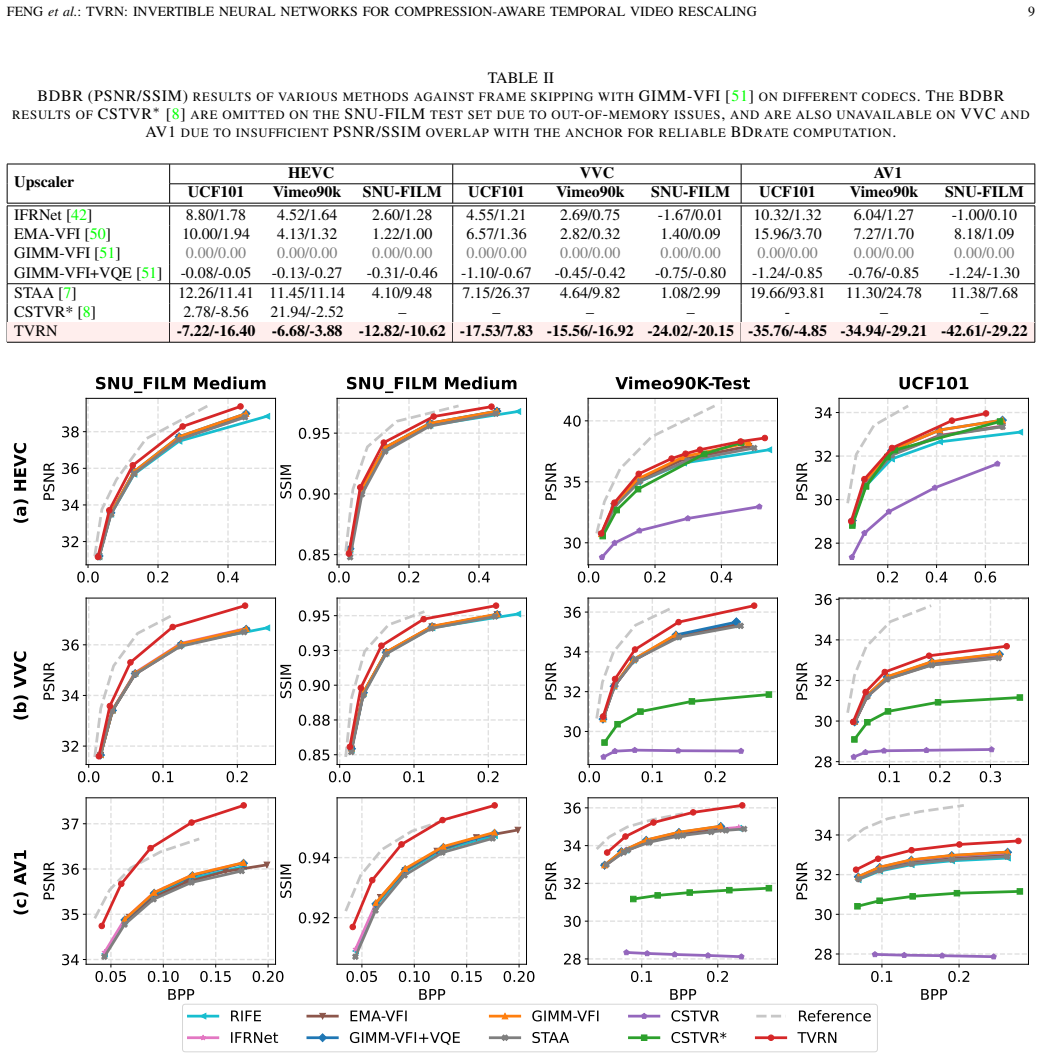
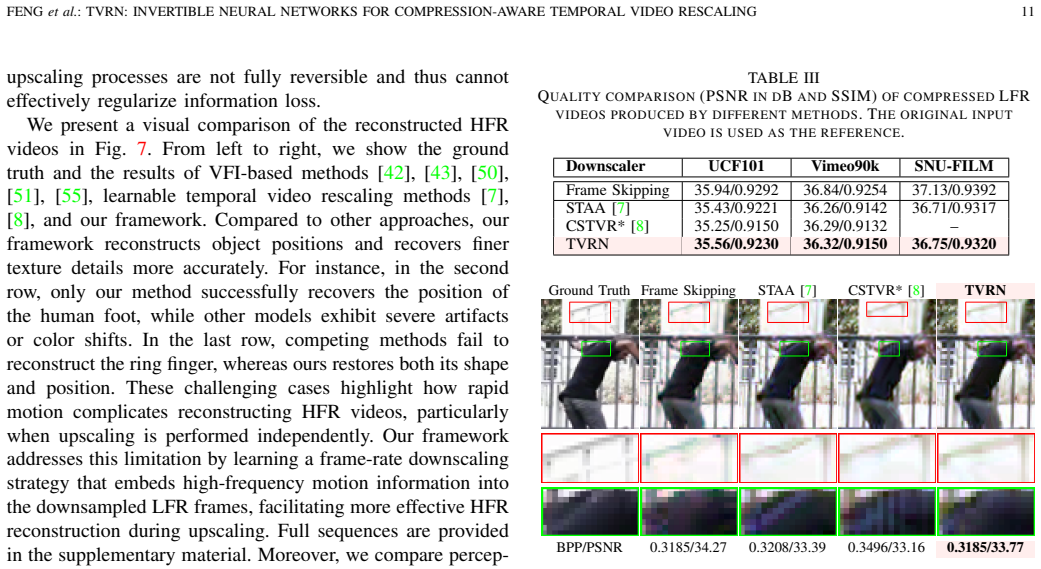
Summary. The paper introduces TVRN, an end-to-end invertible neural network framework for compression-aware temporal video rescaling. It employs a Multi-Input Multi-Output Temporal Wavelet Transform paired with a high-frequency reconstruction module to mitigate information loss during downscaling, a surrogate network to approximate gradients through non-differentiable lossy codecs for joint optimization, and an asymmetric architecture incorporating compression-aware features via a learning-to-rank strategy. Extensive experiments are reported to demonstrate superior reconstruction quality compared to prior methods under industrial video compression settings such as H.264/HEVC.
Significance. If the surrogate gradient approximation holds under real codecs, the approach could meaningfully improve video rescaling pipelines by jointly handling frame-rate conversion and compression effects, addressing a practical gap in existing methods. The invertible architecture and public code release support reproducibility and potential follow-on work in learned video codecs.
major comments (2)
- [Method section describing surrogate network and gradient approximation] The surrogate network (introduced to enable end-to-end training through non-differentiable codecs) is load-bearing for the central claim of compression-aware optimization. No quantitative validation is provided comparing its gradient approximations to true codec gradients (e.g., via cosine similarity or per-frequency error on H.264/HEVC across QP levels), leaving open the possibility that reported gains reflect surrogate-specific artifacts rather than genuine codec behavior.
- [Experiments and results section] The experimental claims of outperformance under industrial compression settings rest on training and evaluation that route through the surrogate. An ablation replacing the surrogate with direct (non-differentiable) codec simulation or post-training evaluation on actual codecs is needed to confirm that the learned model does not overfit to surrogate idiosyncrasies.
minor comments (2)
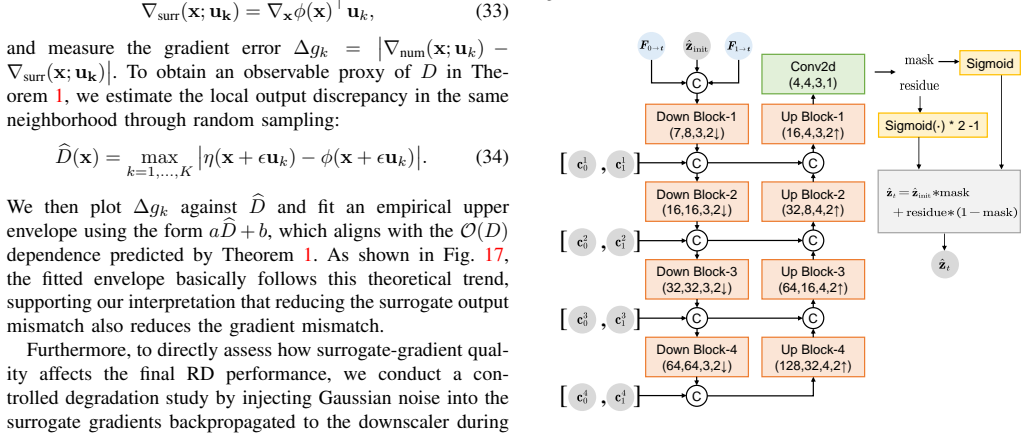
- [Architecture description] Clarify the exact formulation of the Multi-Input Multi-Output Temporal Wavelet Transform and how it interfaces with the high-frequency reconstruction module; include a diagram or pseudocode if not already present.
- [Quantitative results tables] Add error bars or statistical significance tests to the quantitative tables comparing PSNR/SSIM across methods and compression levels.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have addressed each of the major comments below and will incorporate revisions to strengthen the validation of the surrogate network and clarify the experimental setup.
read point-by-point responses
-
Referee: The surrogate network (introduced to enable end-to-end training through non-differentiable codecs) is load-bearing for the central claim of compression-aware optimization. No quantitative validation is provided comparing its gradient approximations to true codec gradients (e.g., via cosine similarity or per-frequency error on H.264/HEVC across QP levels), leaving open the possibility that reported gains reflect surrogate-specific artifacts rather than genuine codec behavior.
Authors: We agree with the referee that quantitative validation of the surrogate's gradient approximations would provide additional confidence in the approach. While the manuscript demonstrates the effectiveness through superior performance under real compression, we will revise the paper to include a dedicated analysis. Specifically, we will compute and report the similarity between the surrogate gradients and gradients approximated from the codec (using methods like straight-through estimation for the quantization steps) across multiple QP values and codecs. This will be added to the experiments section. revision: yes
-
Referee: The experimental claims of outperformance under industrial compression settings rest on training and evaluation that route through the surrogate. An ablation replacing the surrogate with direct (non-differentiable) codec simulation or post-training evaluation on actual codecs is needed to confirm that the learned model does not overfit to surrogate idiosyncrasies.
Authors: We clarify that the evaluation of TVRN and all compared methods is performed using actual industrial codecs (H.264 and HEVC) on the temporally rescaled videos, as described in the experimental setup. The surrogate is solely used to facilitate differentiable training. To address the potential for surrogate-specific artifacts, we will add an ablation in the revised manuscript that evaluates the model trained with the surrogate directly on real codecs without any surrogate involvement during inference, and compare it to a non-joint optimization baseline. Note that fully replacing the surrogate with direct simulation for training is challenging due to the non-differentiable nature of the codecs, but the post-training evaluation on actual codecs already supports the generalization of our results. revision: partial
Circularity Check
No significant circularity; empirical framework with independent evaluation
full rationale
The paper proposes an architectural framework (invertible TVRN with wavelet transform, surrogate gradient approximator, and asymmetric learning-to-rank extension) and supports its claims via extensive experiments on reconstruction quality under real compression. No derivation chain, uniqueness theorem, or fitted parameter is presented as a 'prediction' that reduces by construction to the training inputs or prior self-citations. The surrogate network is a learned component for enabling end-to-end training, but performance is measured against actual codecs on held-out data, keeping the central empirical claim self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
free parameters (2)
- surrogate network weights
- compression-aware feature extractor weights
axioms (2)
- domain assumption Invertible networks can perfectly preserve information in the absence of compression and quantization.
- ad hoc to paper The surrogate network gradient approximation is close enough to the true codec gradient for stable optimization.
invented entities (1)
-
surrogate network for codec gradients
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
invertible architecture that combines a Multi-Input Multi-Output Temporal Wavelet Transform with a high-frequency reconstruction module... surrogate network that approximates their gradients
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
BETA: bandwidth-efficient temporal adaptation for video streaming over reliable transports,
C. James, M. Wang, and E. Halepovic, “BETA: bandwidth-efficient temporal adaptation for video streaming over reliable transports,” in Proceedings of the 10th ACM Multimedia Systems Conference, 2019, pp. 98–109
work page 2019
-
[2]
VOXEL: Cross-layer optimization for video streaming with imperfect transmission,
M. Palmer, M. Appel, K. Spiteri, B. Chandrasekaran, A. Feldmann, and R. K. Sitaraman, “VOXEL: Cross-layer optimization for video streaming with imperfect transmission,” inProceedings of the 17th International Conference on emerging Networking EXperiments and Technologies, 2021, pp. 359–374
work page 2021
-
[3]
Reparo: Qoe-aware live video streaming in low- rate networks by intelligent frame recovery,
F. Wang, Q. Li, W. Shi, G. Tyson, Y . Jiang, L. Ma, P. Zhang, Y . Lan, and Z. Li, “Reparo: Qoe-aware live video streaming in low- rate networks by intelligent frame recovery,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 9194–9204
work page 2023
-
[4]
Enabling high quality Real-Time communications with adaptive Frame-Rate,
Z. Meng, T. Wang, Y . Shen, B. Wang, M. Xu, R. Han, H. Liu, V . Arun, H. Hu, and X. Wei, “Enabling high quality Real-Time communications with adaptive Frame-Rate,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). Boston, MA: USENIX Association, Apr. 2023, pp. 1429–1450
work page 2023
-
[5]
SAFR: A real- time communication system with adaptive frame rate,
W. Yin, B. Lu, Y . Zhao, J. Xu, L. Song, and W. Zhang, “SAFR: A real- time communication system with adaptive frame rate,” inProceedings of the 1st International Workshop on Networked AI Systems, ser. NetAISys ’23. New York, NY , USA: Association for Computing Machinery,
-
[6]
Available: https://doi.org/10.1145/3597062.3597277
[Online]. Available: https://doi.org/10.1145/3597062.3597277
-
[7]
Enabling high frame- rate uhd real-time communication with frame-skipping,
T. Wang, Z. Meng, M. Xu, R. Han, and H. Liu, “Enabling high frame- rate uhd real-time communication with frame-skipping,” inProceedings of the 3rd ACM Workshop on Hot Topics in Video Analytics and Intelligent Edges, 2021, pp. 19–24
work page 2021
-
[8]
Learning spatio-temporal downsampling for effective video upscaling,
X. Xiang, Y . Tian, V . Rengarajan, L. D. Young, B. Zhu, and R. Ranjan, “Learning spatio-temporal downsampling for effective video upscaling,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 162– 181
work page 2022
-
[9]
Continuous space-time video resampling with invertible motion steganography,
Y . Zhang and Z. Chen, “Continuous space-time video resampling with invertible motion steganography,” inCVPR, 2025, pp. 2116–2126
work page 2025
-
[10]
Overview of the high efficiency video coding (HEVC) standard,
G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,”IEEE Transactions on circuits and systems for video technology, vol. 22, no. 12, pp. 1649– 1668, 2012
work page 2012
-
[11]
Video rescaling networks with joint optimization strategies for downscaling and upscaling,
Y .-C. Huang, Y .-H. Chen, C.-Y . Lu, H.-P. Wang, W.-H. Peng, and C.-C. Huang, “Video rescaling networks with joint optimization strategies for downscaling and upscaling,” inCVPR, 2021, pp. 3527–3536
work page 2021
-
[12]
Self- conditioned probabilistic learning of video rescaling,
Y . Tian, G. Lu, X. Min, Z. Che, G. Zhai, G. Guo, and Z. Gao, “Self- conditioned probabilistic learning of video rescaling,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 4490–4499
work page 2021
-
[13]
Towards omniscient feature alignment for video rescaling,
G. Ding and C. W. Chen, “Towards omniscient feature alignment for video rescaling,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 4190–4194
work page 2024
-
[14]
J. Ho, T. Salimans, A. A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,” inAdv. in Neural Inform. Process. Syst., A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022. [Online]. Available: https://openreview.net/forum?id=f3zNgKga ep
work page 2022
-
[15]
CLSA: a contrastive learning framework with selective aggregation for video rescaling,
Y . Tian, Y . Yan, G. Zhai, L. Chen, and Z. Gao, “CLSA: a contrastive learning framework with selective aggregation for video rescaling,”IEEE Transactions on Image Processing, vol. 32, pp. 1300–1314, 2023
work page 2023
-
[16]
Temporal wavelet transform- based low-complexity perceptual quality enhancement of compressed video,
C. Dong, H. Ma, Z. Li, L. Li, and D. Liu, “Temporal wavelet transform- based low-complexity perceptual quality enhancement of compressed video,”IEEE Transactions on Circuits and Systems for Video Technol- ogy, 2023
work page 2023
-
[17]
DenseNet: Implementing Efficient ConvNet Descriptor Pyramids
F. Iandola, M. Moskewicz, S. Karayev, R. Girshick, T. Darrell, and K. Keutzer, “Densenet: Implementing efficient convnet descriptor pyra- mids,”arXiv preprint arXiv:1404.1869, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
NICE: Non-linear Independent Components Estimation
L. Dinh, D. Krueger, and Y . Bengio, “Nice: Non-linear independent components estimation,”arXiv preprint arXiv:1410.8516, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Density estimation using Real NVP
L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real nvp,”arXiv preprint arXiv:1605.08803, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Glow: Generative flow with invertible 1x1 convolutions,
D. P. Kingma and P. Dhariwal, “Glow: Generative flow with invertible 1x1 convolutions,”Advances in neural information processing systems, vol. 31, 2018. 16 ACCEPTED BY IEEE TRANSACTIONS ON IMAGE PROCESSING
work page 2018
-
[21]
Dehazeflow: Multi-scale conditional flow network for single image dehazing,
H. Li, J. Li, D. Zhao, and L. Xu, “Dehazeflow: Multi-scale conditional flow network for single image dehazing,” inProceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 2577–2585
work page 2021
-
[22]
Winnet: Wavelet-inspired invertible network for image denoising,
J.-J. Huang and P. L. Dragotti, “Winnet: Wavelet-inspired invertible network for image denoising,”IEEE Transactions on Image Processing, vol. 31, pp. 4377–4392, 2022
work page 2022
-
[23]
Invertible denoising network: A light solution for real noise removal,
Y . Liu, Z. Qin, S. Anwar, P. Ji, D. Kim, S. Caldwell, and T. Gedeon, “Invertible denoising network: A light solution for real noise removal,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2021, pp. 13 360–13 369
work page 2021
-
[24]
Task-aware image down- scaling,
H. Kim, M. Choi, B. Lim, and K. M. Lee, “Task-aware image down- scaling,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 399–414
work page 2018
-
[25]
Learning a convolutional neural network for image compact-resolution,
Y . Li, D. Liu, H. Li, L. Li, Z. Li, and F. Wu, “Learning a convolutional neural network for image compact-resolution,”IEEE Transactions on Image Processing, vol. 28, no. 3, pp. 1092–1107, 2018
work page 2018
-
[26]
Learned image downscaling for upscaling using content adaptive resampler,
W. Sun and Z. Chen, “Learned image downscaling for upscaling using content adaptive resampler,”IEEE Transactions on Image Processing, vol. 29, pp. 4027–4040, 2020
work page 2020
-
[27]
Hrnet: Hamiltonian rescaling network for image downscaling,
Y . Chen, X. Xiao, T. Dai, and S.-T. Xia, “Hrnet: Hamiltonian rescaling network for image downscaling,” in2020 IEEE International Conference on Image Processing (ICIP). IEEE, 2020, pp. 523–527
work page 2020
-
[28]
M. Xiao, S. Zheng, C. Liu, Y . Wang, D. He, G. Ke, J. Bian, Z. Lin, and T.-Y . Liu, “Invertible image rescaling,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16. Springer, 2020, pp. 126–144
work page 2020
-
[29]
Invertible rescaling network and its extensions,
M. Xiao, S. Zheng, C. Liu, Z. Lin, and T.-Y . Liu, “Invertible rescaling network and its extensions,”International Journal of Computer Vision, vol. 131, no. 1, pp. 134–159, 2023
work page 2023
-
[30]
Direct: Discrete image rescaling with enhancement from case-specific textures,
Y .-A. Chen, C.-C. Hsiao, W.-H. Peng, and C.-C. Huang, “Direct: Discrete image rescaling with enhancement from case-specific textures,” in2021 International Conference on Visual Communications and Image Processing (VCIP). IEEE, 2021, pp. 1–5
work page 2021
-
[31]
Hierarchical conditional flow: A unified framework for image super-resolution and image rescaling,
J. Liang, A. Lugmayr, K. Zhang, M. Danelljan, L. Van Gool, and R. Timofte, “Hierarchical conditional flow: A unified framework for image super-resolution and image rescaling,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4076–4085
work page 2021
-
[32]
High- frequency normalizing flow for image rescaling,
Y . Zhu, C. Wang, C. Dong, K. Zhang, H. Gao, and C. Yuan, “High- frequency normalizing flow for image rescaling,”IEEE Transactions on Image Processing, vol. 32, pp. 6223–6233, 2022
work page 2022
-
[33]
Self-asymmetric invert- ible network for compression-aware image rescaling,
J. Yang, M. Guo, S. Zhao, J. Li, and L. Zhang, “Self-asymmetric invert- ible network for compression-aware image rescaling,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 3, 2023, pp. 3155–3163
work page 2023
-
[34]
Real-time 6k image rescaling with rate-distortion optimization,
C. Qi, X. Yang, K. L. Cheng, Y .-C. Chen, and Q. Chen, “Real-time 6k image rescaling with rate-distortion optimization,” inCVPR, 2023, pp. 14 092–14 101
work page 2023
-
[35]
Learned scale-arbitrary image down- scaling for non-learnable upscaling,
C. Huang, W. Sun, and Z. Chen, “Learned scale-arbitrary image down- scaling for non-learnable upscaling,”IEEE Signal Process. Lett., vol. 30, pp. 264–268, 2023
work page 2023
-
[36]
Timestep-aware diffusion model for extreme image rescaling,
C. Wang, Z. Hu, W. Sun, and Z. Chen, “Timestep-aware diffusion model for extreme image rescaling,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 15 594–15 603
work page 2025
-
[37]
Extremely low bit-rate image compression via invertible image generation,
F. Gao, X. Deng, J. Jing, X. Zou, and M. Xu, “Extremely low bit-rate image compression via invertible image generation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 8, pp. 6993– 7004, 2023
work page 2023
-
[38]
Context-aware synthesis for video frame interpo- lation,
S. Niklaus and F. Liu, “Context-aware synthesis for video frame interpo- lation,” inProc. of the IEEE Conf. on Comput. Vis. and Pattern Recog., 2018, pp. 1701–1710
work page 2018
-
[39]
Softmax splatting for video frame interpolation,
——, “Softmax splatting for video frame interpolation,” inProc. of the IEEE Conf. on Comput. Vis. and Pattern Recog., 2020, pp. 5437–5446
work page 2020
-
[40]
XVFI: extreme video frame interpolation,
H. Sim, J. Oh, M. Kim, and J. Oh, “XVFI: extreme video frame interpolation,” inProc. of the IEEE Int. Conf. on Comput. Vis., 2021, pp. 14 489–14 498
work page 2021
-
[41]
BMBC: Bilateral motion estimation with bilateral cost volume for video interpolation,
J. Park, K. Ko, C. Lee, and C.-S. Kim, “BMBC: Bilateral motion estimation with bilateral cost volume for video interpolation,” inComput. Vis.–ECCV 2020: 16th European Conference, Glasgow, UK, August 23– 28, 2020, Proceedings, Part XIV 16. Springer, 2020, pp. 109–125
work page 2020
-
[42]
Video frame interpolation with transformer,
L. Lu, R. Wu, H. Lin, J. Lu, and J. Jia, “Video frame interpolation with transformer,” inProc. of the IEEE Conf. on Comput. Vis. and Pattern Recog., 2022, pp. 3532–3542
work page 2022
-
[43]
IFRNet: Intermediate feature refine network for efficient frame interpolation,
L. Kong, B. Jiang, D. Luo, W. Chu, X. Huang, Y . Tai, C. Wang, and J. Yang, “IFRNet: Intermediate feature refine network for efficient frame interpolation,” inProc. of the IEEE Conf. on Comput. Vis. and Pattern Recog., 2022, pp. 1969–1978
work page 2022
-
[44]
Upr-net: A unified pyramid recurrent network for video frame interpolation,
X. Jin, L. Wu, J. Chen, Y . Chen, J. Koo, C.-H. Hahm, and Z.-M. Chen, “Upr-net: A unified pyramid recurrent network for video frame interpolation,”International Journal of Computer Vision, vol. 133, no. 1, pp. 16–30, 2025
work page 2025
-
[45]
Disentangled motion modeling for video frame interpolation,
J. Lew, J. Choi, C. Shin, D. Jung, and S. Yoon, “Disentangled motion modeling for video frame interpolation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 4607– 4615
work page 2025
-
[46]
Sparse global matching for video frame interpolation with large motion,
C. Liu, G. Zhang, R. Zhao, and L. Wang, “Sparse global matching for video frame interpolation with large motion,” inCVPR, 2024, pp. 19 125–19 134
work page 2024
-
[47]
CDFI: Compression-driven network design for frame interpolation,
T. Ding, L. Liang, Z. Zhu, and I. Zharkov, “CDFI: Compression-driven network design for frame interpolation,” inProc. of the IEEE Conf. on Comput. Vis. and Pattern Recog., 2021, pp. 8001–8011
work page 2021
-
[48]
Video frame interpolation via deformable separable convolution,
X. Cheng and Z. Chen, “Video frame interpolation via deformable separable convolution,” inProc. of the AAAI Conf. on Artificial Intell., 2020, pp. 10 607–10 614
work page 2020
-
[49]
Multiple video frame interpolation via enhanced deformable separable convolution,
——, “Multiple video frame interpolation via enhanced deformable separable convolution,”IEEE Trans. on Pattern Anal. Mach. Intell., vol. 44, no. 10, pp. 7029–7045, 2022
work page 2022
-
[50]
Enhancing deformable convolution based video frame interpolation with coarse-to-fine 3d CNN,
D. Danier, F. Zhang, and D. Bull, “Enhancing deformable convolution based video frame interpolation with coarse-to-fine 3d CNN,” inIEEE Int. Conf. on Image Process., 2022, pp. 1396–1400
work page 2022
-
[51]
Extracting motion and appearance via inter-frame attention for efficient video frame interpolation,
G. Zhang, Y . Zhu, H. Wang, Y . Chen, G. Wu, and L. Wang, “Extracting motion and appearance via inter-frame attention for efficient video frame interpolation,” inCVPR, 2023, pp. 5682–5692
work page 2023
-
[52]
Generalizable implicit motion mod- eling for video frame interpolation,
Z. Guo, W. Li, and C. C. Loy, “Generalizable implicit motion mod- eling for video frame interpolation,”Advances in Neural Information Processing Systems, vol. 37, pp. 63 747–63 770, 2024
work page 2024
-
[53]
Nonlinear independent component anal- ysis: Existence and uniqueness results,
A. Hyv ¨arinen and P. Pajunen, “Nonlinear independent component anal- ysis: Existence and uniqueness results,”Neural networks, vol. 12, no. 3, pp. 429–439, 1999
work page 1999
-
[54]
Nonlinear wavelet transforms for image coding via lifting,
R. L. Claypoole, G. M. Davis, W. Sweldens, and R. G. Baraniuk, “Nonlinear wavelet transforms for image coding via lifting,”IEEE Transactions on Image Processing, vol. 12, no. 12, pp. 1449–1459, 2003
work page 2003
-
[55]
Video rescaling with recurrent diffusion,
D. Li, Y . Liu, Z. Wang, and J. Yang, “Video rescaling with recurrent diffusion,”IEEE Transactions on Circuits and Systems for Video Tech- nology, 2024
work page 2024
-
[56]
En- hanced bi-directional motion estimation for video frame interpolation,
X. Jin, L. Wu, G. Shen, Y . Chen, J. Chen, J. Koo, and C.-h. Hahm, “En- hanced bi-directional motion estimation for video frame interpolation,” arXiv preprint arXiv:2206.08572, 2022
-
[57]
Preprocessing enhanced image compression for machine vision,
G. Lu, X. Ge, T. Zhong, Q. Hu, and J. Geng, “Preprocessing enhanced image compression for machine vision,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[58]
Spatio-temporal detail information retrieval for compressed video quality enhancement,
D. Luo, M. Ye, S. Li, C. Zhu, and X. Li, “Spatio-temporal detail information retrieval for compressed video quality enhancement,”IEEE Transactions on Multimedia, vol. 25, pp. 6808–6820, 2022
work page 2022
-
[59]
Compression- aware video super-resolution,
Y . Wang, T. Isobe, X. Jia, X. Tao, H. Lu, and Y .-W. Tai, “Compression- aware video super-resolution,” inCVPR, 2023, pp. 2012–2021
work page 2023
-
[60]
Rate-distortion-optimized deep preprocessing for jpeg compression,
F. Ye, B. Liu, L. Li, and D. Liu, “Rate-distortion-optimized deep preprocessing for jpeg compression,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2025
work page 2025
-
[61]
Video enhance- ment with task-oriented flow,
T. Xue, B. Chen, J. Wu, D. Wei, and W. T. Freeman, “Video enhance- ment with task-oriented flow,”IJCV, 2019
work page 2019
-
[62]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “UCF101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[63]
Scene-adaptive video frame interpolation via meta-learning,
M. Choi, J. Choi, S. Baik, T. H. Kim, and K. M. Lee, “Scene-adaptive video frame interpolation via meta-learning,” inProc. of the IEEE Conf. on Comput. Vis. and Pattern Recog., 2020, pp. 9444–9453
work page 2020
-
[64]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE Trans. on Image Process., vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[65]
Toward a practical perceptual video quality metric,
Z. Li, A. Aaron, I. Katsavounidis, A. Moorthy, and M. Manohara, “Toward a practical perceptual video quality metric,”The Netflix Tech Blog, vol. 6, no. 2, 2016
work page 2016
-
[66]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 586–595
work page 2018
-
[67]
Learning temporal coherence via self-supervision for gan-based video generation,
M. Chu, Y . Xie, J. Mayer, L. Leal-Taix ´e, and N. Thuerey, “Learning temporal coherence via self-supervision for gan-based video generation,” ACM Transactions on Graphics (TOG), vol. 39, no. 4, p. 75, 2020
work page 2020
-
[68]
Learning blind video temporal consistency,
W.-S. Lai, J.-B. Huang, O. Wang, E. Shechtman, E. Yumer, and M.-H. Yang, “Learning blind video temporal consistency,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 170– 185. FENGet al.: TVRN: INVERTIBLE NEURAL NETWORKS FOR COMPRESSION-AW ARE TEMPORAL VIDEO RESCALING 17
work page 2018
-
[69]
Raft: Recurrent all-pairs field transforms for optical flow,
Z. Teed and J. Deng, “Raft: Recurrent all-pairs field transforms for optical flow,” inComputer Vision–ECCV 2020: 16th European Confer- ence, Glasgow, UK, August 23–28, 2020, Proceedings, Part II, vol. 16. Springer, 2020, pp. 402–419
work page 2020
-
[70]
Channel attention is all you need for video frame interpolation,
M. Choi, H. Kim, B. Han, N. Xu, and K. M. Lee, “Channel attention is all you need for video frame interpolation,” inAAAI, 2020
work page 2020
-
[71]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inInt. Conf. on Learn. Represent., 2015
work page 2015
-
[72]
J. Han, B. Li, D. Mukherjee, C.-H. Chiang, A. Grange, C. Chen, H. Su, S. Parker, S. Deng, U. Joshi, Y . Chen, Y . Wang, P. Wilkins, Y . Xu, and J. Bankoski, “A technical overview of av1,”Proceedings of the IEEE, vol. 109, no. 9, pp. 1435–1462, 2021
work page 2021
-
[73]
Overview of the versatile video coding (vvc) standard and its applications,
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.- R. Ohm, “Overview of the versatile video coding (vvc) standard and its applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, 2021
work page 2021
-
[74]
Vvenc: An open and optimized vvc encoder implementation,
A. Wieckowski, J. Brandenburg, T. Hinz, C. Bartnik, V . George, G. Hege, C. Helmrich, A. Henkel, C. Lehmann, C. Stoffers, I. Zupancic, B. Bross, and D. Marpe, “Vvenc: An open and optimized vvc encoder implementation,” inProc. IEEE International Conference on Multimedia Expo Workshops (ICMEW), pp. 1–2
-
[75]
International Telecommunication Union, “Methods for the subjective assessment of video quality, audio quality and audiovisual quality of internet video and distribution quality television in any environment,” International Telecommunication Union (ITU), Geneva, Switzerland, Recommendation ITU-T P.913, Mar. 2016
work page 2016
-
[76]
Methodology for the subjective assessment of the quality of tele- vision pictures,
——, “Methodology for the subjective assessment of the quality of tele- vision pictures,” International Telecommunication Union (ITU), Geneva, Switzerland, Recommendation ITU-R BT.500-13, Jun. 2012
work page 2012
-
[77]
Calcuation of average PSNR differences between RD- curves,
G. Bjontegaard, “Calcuation of average PSNR differences between RD- curves,” VCEG, Tech. Rep. VCEG-M33, 2001
work page 2001
-
[78]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,”arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[79]
PWC-net: CNNs for optical flow using pyramid, warping, and cost volume,
D. Sun, X. Yang, M.-Y . Liu, and J. Kautz, “PWC-net: CNNs for optical flow using pyramid, warping, and cost volume,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8934–8943
work page 2018
-
[80]
Real-time inter- mediate flow estimation for video frame interpolation,
Z. Huang, T. Zhang, W. Heng, B. Shi, and S. Zhou, “Real-time inter- mediate flow estimation for video frame interpolation,” inProceedings of the European Conference on Computer Vision (ECCV), 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.