Towards end-to-end LLM-based censoring-aware survival analysis
Pith reviewed 2026-06-29 22:04 UTC · model grok-4.3
The pith
LLMs can perform end-to-end survival analysis on tabular clinical data by reformulating predictions as pairwise rankings that handle censoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
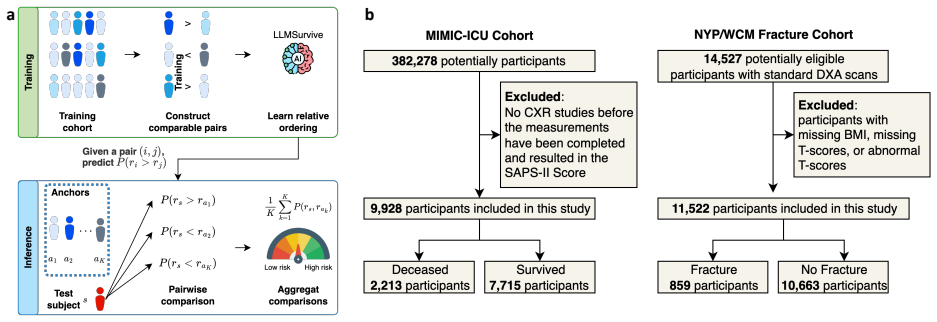
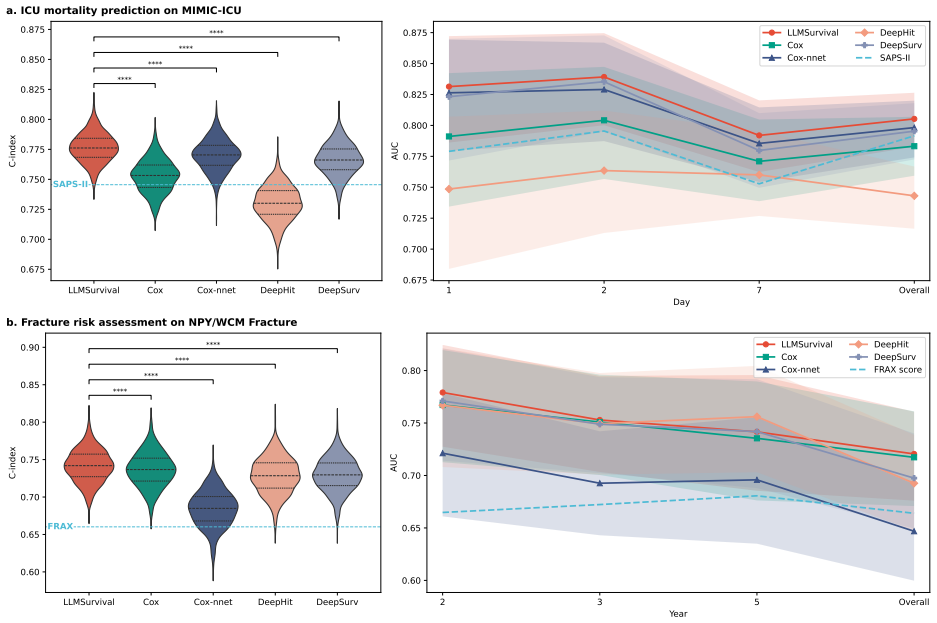
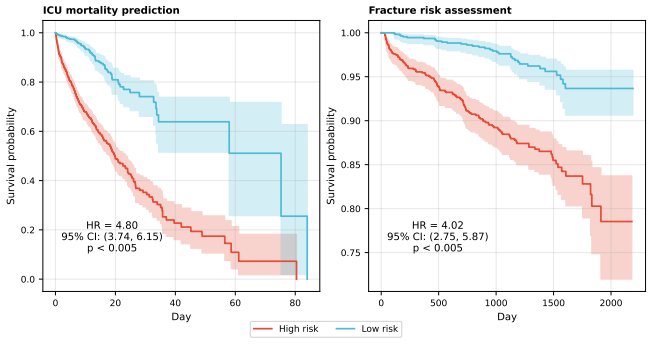
LLMSurvival reformulates time-to-event prediction as pairwise ranking among comparable subjects and derives test-time risk by aggregating comparisons against anchor individuals from the training cohort, enabling unmodified LLMs to perform censoring-aware survival analysis on tabular data and yielding higher concordance than Cox proportional hazards and established deep learning models on ICU mortality and fragility fracture prediction.
What carries the argument
Pairwise ranking reformulation of time-to-event data with anchor-based aggregation at test time.
If this is right
- Concordance improves 3.1 percent over Cox modeling for ICU mortality and 0.5 percent for fracture risk.
- Average gains reach 2.1 percent over three deep learning survival models for ICU mortality and 2.8 percent for fracture risk.
- The same framework applies across ICU and fracture cohorts without task-specific redesign.
- Compact publicly available base models achieve competitive performance without large-scale infrastructure.
- Standard LLM fine-tuning becomes directly usable for censored survival tasks.
Where Pith is reading between the lines
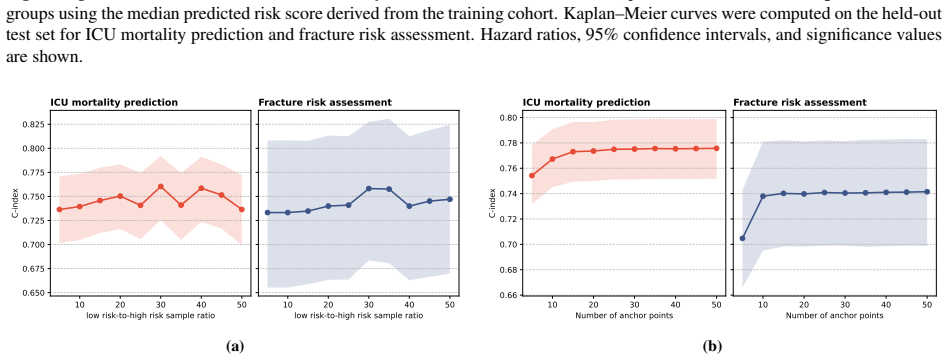
- The anchor-selection step could be studied as a hyperparameter that trades off stability against compute.
- The same pairwise reformulation might extend to other censored regression problems such as length-of-stay forecasting.
- Local deployment becomes practical in settings where only small open models are permitted.
- Risk scores derived from LLM comparisons could be inspected for feature importance by examining which comparisons drive the aggregate.
Load-bearing premise
The pairwise comparisons on tabular features produce risk scores that remain clinically meaningful and generalize beyond the chosen training anchors.
What would settle it
A held-out clinical cohort in which LLMSurvival concordance falls below Cox proportional hazards performance under the same training protocol.
Figures

read the original abstract
Objective: Survival analysis is central to medical prediction, yet large language models (LLMs) are rarely used as end-to-end survival models because censoring prevents straightforward supervised fine-tuning. Here we present LLMSurvival, a framework that enables censoring-aware survival analysis with unmodified LLMs operating directly on tabular clinical data. Materials and Methods: LLMSurvival reformulates time-to-event prediction as pairwise ranking among comparable subjects, and derives test-time risk by aggregating comparisons against anchor individuals from the training cohort. Results: Across two clinical tasks (ICU mortality prediction in MIMIC-IV and fragility fracture prediction in a NewYork-Presbyterian/Weill Cornell Medicine cohort), LLMSurvival improves overall concordance over Cox proportional hazards modeling by 3.1% for ICU mortality and 0.5% for fracture risk, 2.1% on average for ICU mortality and 2.8% for fracture risk over three established deep learning survival models. Discussion: The results show that survival modeling with censoring can be made compatible with LLM fine-tuning through comparison-based reformulation. The framework demonstrates high portability and superior performance over expert curated scores like SAPS-II and FRAX scores across diverse clinical context. Furthermore, the framework supports local deployment, as compact, publicly available base models provide sufficient performance. Conclusion: The LLMSurvival framework serves as a proof of concept for an integrated, censoring-conscious approach to survival analysis via LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLMSurvival, a framework for censoring-aware survival analysis using unmodified LLMs on tabular clinical data. It reformulates time-to-event prediction as pairwise ranking among comparable subjects and derives test-time risk scores by aggregating LLM comparisons against anchor individuals from the training cohort. On ICU mortality prediction (MIMIC-IV) and fragility fracture prediction (NYPH/WCM cohort), it reports concordance improvements of 3.1% and 0.5% over Cox proportional hazards, plus average gains of 2.1% and 2.8% over three deep learning survival models, while claiming portability, superiority to SAPS-II/FRAX, and viability with compact local models.
Significance. If the anchor-aggregation procedure proves robust, the work would be significant for showing that standard LLMs can handle censored survival tasks end-to-end without custom loss functions or architectures, offering measurable gains over both classical and deep baselines on real clinical data and enabling local deployment. This addresses a practical barrier in medical AI and could influence how LLMs are adapted to other censored or ranking-based prediction problems.
major comments (2)
- [Materials and Methods] Materials and Methods: the test-time risk derivation aggregates LLM pairwise comparisons to a fixed set of training anchors, but no sensitivity analysis to anchor selection, no check for transitivity/consistency of LLM orderings on tabular features, and no description of how censoring or ties are encoded in prompts are provided. These omissions are load-bearing for the Results claims of 3.1% and 0.5% concordance lifts, as any instability in the induced ranking would directly affect the reported superiority over Cox and deep-learning baselines.
- [Results] Results: the headline concordance improvements are presented without reported confidence intervals, p-values, or details on how the anchor set was chosen or held fixed across experiments. This makes it impossible to assess whether the 2.1% and 2.8% average gains over deep learning models are statistically reliable or sensitive to the specific aggregation operator.
minor comments (1)
- [Abstract] Abstract: performance numbers are stated without accompanying error bars, sample sizes after exclusion, or cross-validation scheme, which reduces immediate interpretability even if these details appear later in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional methodological detail and statistical rigor would strengthen the manuscript. We address each major comment below and will incorporate revisions to improve clarity and transparency.
read point-by-point responses
-
Referee: [Materials and Methods] Materials and Methods: the test-time risk derivation aggregates LLM pairwise comparisons to a fixed set of training anchors, but no sensitivity analysis to anchor selection, no check for transitivity/consistency of LLM orderings on tabular features, and no description of how censoring or ties are encoded in prompts are provided. These omissions are load-bearing for the Results claims of 3.1% and 0.5% concordance lifts, as any instability in the induced ranking would directly affect the reported superiority over Cox and deep-learning baselines.
Authors: We agree these details were insufficiently described. In the revised manuscript we will expand the Materials and Methods section with: (i) the exact prompt templates showing how censoring is encoded (e.g., “event observed at time t” vs. “censored at t”) and how ties are handled; (ii) a sensitivity analysis varying anchor-set size and sampling strategy (random, stratified by event status); and (iii) an empirical check of ordering consistency across repeated LLM queries on the same tabular pairs. These additions will directly support the robustness of the reported concordance gains. revision: yes
-
Referee: [Results] Results: the headline concordance improvements are presented without reported confidence intervals, p-values, or details on how the anchor set was chosen or held fixed across experiments. This makes it impossible to assess whether the 2.1% and 2.8% average gains over deep learning models are statistically reliable or sensitive to the specific aggregation operator.
Authors: We acknowledge the absence of uncertainty quantification and anchor-set specifics. The revision will add bootstrap confidence intervals and paired statistical tests (DeLong or permutation tests) for all concordance differences, together with a precise description of the anchor cohort (size, sampling procedure, and confirmation that the identical fixed set was used for all experiments and baselines). This will allow readers to evaluate both statistical reliability and sensitivity to the aggregation procedure. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain reformulates survival prediction as pairwise LLM comparisons to training-cohort anchors and reports empirical concordance gains on held-out test data from two independent clinical cohorts against Cox and deep-learning baselines. No load-bearing step reduces the claimed performance lifts to a quantity defined by the method itself, a fitted parameter renamed as prediction, or a self-citation chain; the results are externally falsifiable via standard metrics and do not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ching-Fan Chung, Peter Schmidt, and Ana D Witte. Survival analysis: A survey.J. Quant. Criminol., 7(1):59–98, March 1991. ISSN 0748-4518,1573-7799. doi: 10.1007/bf01083132
-
[2]
Review of language models for survival analysis
Vincent Jeanselme, Nikita Agarwal, and Chen Wang. Review of language models for survival analysis. InAAAI 2024 Spring Symposium on Clinical Foundation Models, 2024
2024
-
[3]
Muhammad Faisal Shahid, Asad Afzal, Abdullah Faiz, Muhammad Siddiqui, Arbaz Khan Shehzad, Fatima Aftab, Muhammad Usamah Shahid, and Muddassar Farooq. Leveraging large language models and survival analysis for early prediction of chemotherapy outcomes.arXiv preprint arXiv:2603.11594, 2026
-
[4]
Survival analysis for cancers of the brain, cns and bone using retrieval augmented generation on the seer database
Jyothi Vaidyanathan, Shourya Gupta, Justin Lee, Srikanth Prabhu, and Saptarshi Sengupta. Survival analysis for cancers of the brain, cns and bone using retrieval augmented generation on the seer database. InProceedings of the AAAI Symposium Series, volume 5, pages 31–36, 2025
2025
-
[5]
Llm-enhanced survival model for electric device lifespan estimation
Bao Wen, Aihui Wen, Wentian Fang, and Jining Li. Llm-enhanced survival model for electric device lifespan estimation. In2024 IEEE Smart World Congress (SWC), pages 2547–2552. IEEE, 2024
2024
-
[6]
MOTOR: A time-to-event foundation model for structured medical records
Ethan Steinberg, Jason Alan Fries, Yizhe Xu, and Nigam Shah. MOTOR: A time-to-event foundation model for structured medical records. InThe Twelfth International Conference on Learning Represen- tations, 13 October 2023
2023
-
[7]
Predictive maintenance with large language models and transformer-based survival analysis
Aurora Esteban, Victor Cobilean, and Rashmika Nawaratne. Predictive maintenance with large language models and transformer-based survival analysis. InIECON 2024 - 50th Annual Con- ference of the IEEE Industrial Electronics Society, pages 1–6. IEEE, 3 November 2024. ISBN 9781665464543,9781665464550. doi: 10.1109/iecon55916.2024.10905382
-
[8]
LIFT: language-interfaced fine-tuning for non-language machine learning tasks
Tuan Dinh, Yuchen Zeng, Ruisu Zhang, Ziqian Lin, Michael Gira, Shashank Rajput, Jy-Yong Sohn, Dimitris Papailiopoulos, and Kangwook Lee. LIFT: language-interfaced fine-tuning for non-language machine learning tasks. InProceedings of the 36th International Conference on Neural Information Processing Systems, number Article 855 in NIPS ’22, pages 11763–1178...
-
[9]
TabLLM: Few-shot classification of tabular data with large language models
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Son- tag. TabLLM: Few-shot classification of tabular data with large language models. InInternational Conference on Artificial Intelligence and Statistics, pages 5549–5581. PMLR, 11 April 2023
2023
-
[10]
Machine learning for survival analysis: A survey.ACM Comput
Ping Wang, Yan Li, and Chandan K Reddy. Machine learning for survival analysis: A survey.ACM Comput. Surv., 51(6):1–36, 30 November 2019. ISSN 0360-0300,1557-7341. doi: 10.1145/3214306
-
[11]
A deep survival analysis method based on ranking.Artif
Bingzhong Jing, Tao Zhang, Zixian Wang, Ying Jin, Kuiyuan Liu, Wenze Qiu, Liangru Ke, Ying Sun, Caisheng He, Dan Hou, Linquan Tang, Xing Lv, and Chaofeng Li. A deep survival analysis method based on ranking.Artif. Intell. Med., 98:1–9, July 2019. ISSN 0933-3657,1873-2860. doi: 10.1016/j.artmed.2019.06.001
-
[12]
Vanya Van Belle, Kristiaan Pelckmans, Sabine Van Huffel, and Johan A K Suykens. Support vector methods for survival analysis: a comparison between ranking and regression approaches.Artif. Intell. Med., 53(2):107–118, October 2011. ISSN 0933-3657,1873-2860. doi: 10.1016/j.artmed.2011.06.006
-
[13]
Learning to rank for censored survival data
Margaux Luck, Tristan Sylvain, Joseph Paul Cohen, Heloise Cardinal, Andrea Lodi, and Yoshua Ben- gio. Learning to rank for censored survival data.arXiv preprint arXiv:1806.01984, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
A deep survival analysis method based on ranking.Artificial intelligence in medicine, 98:1–9, 2019
Bingzhong Jing, Tao Zhang, Zixian Wang, Ying Jin, Kuiyuan Liu, Wenze Qiu, Liangru Ke, Ying Sun, Caisheng He, Dan Hou, et al. A deep survival analysis method based on ranking.Artificial intelligence in medicine, 98:1–9, 2019
2019
-
[15]
Large language models are effec- tive text rankers with pairwise ranking prompting
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, and Michael Bendersky. Large language models are effec- tive text rankers with pairwise ranking prompting. InFindings of the Association for Computational Linguistics: NAACL 2024, Stroudsburg, PA, USA, 2024. Association fo...
-
[16]
Make large language model a better ranker
Wen-Shuo Chao, Zhi Zheng, Hengshu Zhu, and Hao Liu. Make large language model a better ranker. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 918–929, Stroudsburg, PA, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.finding s-emnlp.51
-
[17]
Cox-nnet: an artificial neural network method for prognosis prediction of high-throughput omics data.PLoS computational biology, 14(4):e1006076, 2018
Travers Ching, Xun Zhu, and Lana X Garmire. Cox-nnet: an artificial neural network method for prognosis prediction of high-throughput omics data.PLoS computational biology, 14(4):e1006076, 2018
2018
-
[18]
Deephit: A deep learning approach to survival analysis with competing risks
Changhee Lee, William Zame, Jinsung Yoon, and Mihaela Van Der Schaar. Deephit: A deep learning approach to survival analysis with competing risks. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[19]
Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network.BMC medical research methodology, 18(1):24, 2018
Jared L Katzman, Uri Shaham, Alexander Cloninger, Jonathan Bates, Tingting Jiang, and Yuval Kluger. Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network.BMC medical research methodology, 18(1):24, 2018
2018
-
[20]
MIMIC-IV, a freely accessible electronic health record dataset.Sci
Alistair E W Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, Li-Wei H Lehman, Leo A Celi, and Roger G Mark. MIMIC-IV, a freely accessible electronic health record dataset.Sci. Data, 10(1):1, 3 January
-
[21]
doi: 10.1038/s41597-022-01899-x
ISSN 2052-4463. doi: 10.1038/s41597-022-01899-x
-
[22]
Mingquan Lin, Song Wang, Ying Ding, Lihui Zhao, Fei Wang, and Yifan Peng. An empirical study of using radiology reports and images to improve ICU-mortality prediction.IEEE Int. Conf. Healthc. Inform., 2021:497–498, August 2021. doi: 10.1109/ichi52183.2021.00088
-
[23]
J R Le Gall. A new simplified acute physiology score (SAPS II) based on a european/north american multicenter study.JAMA, 270(24):2957–2963, 22 December 1993. ISSN 0098-7484,1538-3598. doi: 10.1001/jama.270.24.2957
-
[24]
J.A. Kanis, O. Johnell, A. Od ´en, H. Johansson, and E. McCloskey. Frax and the assessment of fracture probability in men and women from the uk.Osteoporosis International, 19(4):385–397, 2008. doi: 10.1007/s00198-007-0543-5
-
[25]
Large language models (LLMs) on tabular data: Prediction, generation, and understanding - a survey.Transactions on Machine Learning Research, 2024
Xi Fang, Weijie Xu, Fiona Anting Tan, Ziqing Hu, Jiani Zhang, Yanjun Qi, Srinivasan H Sengamedu, and Christos Faloutsos. Large language models (LLMs) on tabular data: Prediction, generation, and understanding - a survey.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[26]
Methods of cohort analysis: Appraisal by application to asbestos mining.J
F D K Liddell, J C McDonald, D C Thomas, and Stella V Cunliffe. Methods of cohort analysis: Appraisal by application to asbestos mining.J. R. Stat. Soc. Ser. A, 140(4):469, 1977. ISSN 0035- 9238,2397-2327. doi: 10.2307/2345280
-
[27]
Asymptotic theory for nested case-control sampling in the cox regression model.Ann
Larry Goldstein and Bryan Langholz. Asymptotic theory for nested case-control sampling in the cox regression model.Ann. Stat., 20(4):1903–1928, 1 December 1992. ISSN 0090-5364,2168-8966. doi: 10.1214/aos/1176348895
-
[28]
Yu Liu, Weiyao Tao, Tong Xia, Simon Knight, and Tingting Zhu. SurvUnc: A meta-model based uncertainty quantification framework for survival analysis. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, pages 1903–1914, New York, NY , USA, 3 August 2025. ACM. doi: 10.1145/3711896.3737140
-
[29]
The llama 3 herd of models.arXiv [cs.AI], 31 July 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava S...
2024
-
[30]
Qwen2.5 technical report.arXiv [cs.CL], 19 December 2024
Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Ti...
2024
-
[31]
J.A. Kanis, A. Od ´en, H. Johansson, F. Borgstr¨om, O. Str¨om, and E. McCloskey. Frax and its applica- tions to clinical practice.Bone, 44(5):734–743, 2009. doi: 10.1016/j.bone.2009.01.373
-
[32]
Using AUC and accuracy in evaluating learning algorithms.IEEE Trans
Jin Huang and C X Ling. Using AUC and accuracy in evaluating learning algorithms.IEEE Trans. Knowl. Data Eng., 17(3):299–310, March 2005. ISSN 1041-4347,1558-2191. doi: 10.1109/tkde.2005. 50
-
[33]
MIMIC-IV, 2020
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. MIMIC-IV, 2020
2020
-
[34]
Predicting mortality in the intensive care unit: a comparison of the university health consortium expected probability of mortality and the mortality prediction model III.J
Angela K M Lipshutz, John R Feiner, Barbara Grimes, and Michael A Gropper. Predicting mortality in the intensive care unit: a comparison of the university health consortium expected probability of mortality and the mortality prediction model III.J. Intensive Care, 4(1):35, 23 May 2016. ISSN 2052-
2016
-
[35]
doi: 10.1186/s40560-016-0158-z
-
[36]
GBD 2019 Fracture Collaborators. Global, regional, and national burden of bone fractures in 204 countries and territories, 1990–2019: a systematic analysis from the global burden of disease study 2019.The Lancet Healthy Longevity, 2(9):e580–e592, 2021. doi: 10.1016/S2666-7568(21)00172-0
-
[37]
Fragility fractures, 2024
World Health Organization. Fragility fractures, 2024. URLhttps://www.who.int/news-roo m/fact-sheets/detail/fragility-fractures. Fact sheet, 25 September 2024
2024
-
[38]
Preventive Services Task Force
U.S. Preventive Services Task Force. Osteoporosis to prevent fractures: Screening, 2025. URLhttp s://uspreventiveservicestaskforce.org/uspstf/recommendation/osteopor osis-screening. Recommendation statement (Jan 14, 2025)
2025
-
[39]
W. K. Nicholson et al. Screening for osteoporosis to prevent fractures: Us preventive services task force recommendation statement.JAMA, 2025
2025
-
[40]
LLM-RankFusion: Mitigating intrinsic inconsistency in LLM-based ranking.arXiv [cs.IR], 31 May 2024
Yifan Zeng, Ojas Tendolkar, Raymond Baartmans, Qingyun Wu, Lizhong Chen, and Huazheng Wang. LLM-RankFusion: Mitigating intrinsic inconsistency in LLM-based ranking.arXiv [cs.IR], 31 May 2024
2024
-
[41]
Remarks on some nonparametric estimates of a density function.Annals of Math- ematical Statistics, 27:832–837, 1956
Murray Rosenblatt. Remarks on some nonparametric estimates of a density function.Annals of Math- ematical Statistics, 27:832–837, 1956
1956
-
[42]
random”; primary analysis) and (2) selec- tion of anchors exclusively from event cases (“event-only
Emanuel Parzen. On estimation of a probability density function and mode.Annals of Mathematical Statistics, 33:1065–1076, 1962. A SUPPLEMENT eTable 1:Summary of previous literature Author Model Type Description of how they tackle survival analysis Esteban et al. [7] Deep Learning, LLM Added dedicated neural networks on top of an LLM and experimented with ...
1962
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.