PracRepair: LLM-Empowered Automated Program Repair Inspired by Human-Like Debugging Practices
Pith reviewed 2026-06-27 00:09 UTC · model grok-4.3
The pith
PracRepair improves automated program repair by constructing on-demand static-dynamic context, using question-driven failure diagnosis for explicit hypotheses, and iteratively refining patches with validation and trace feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
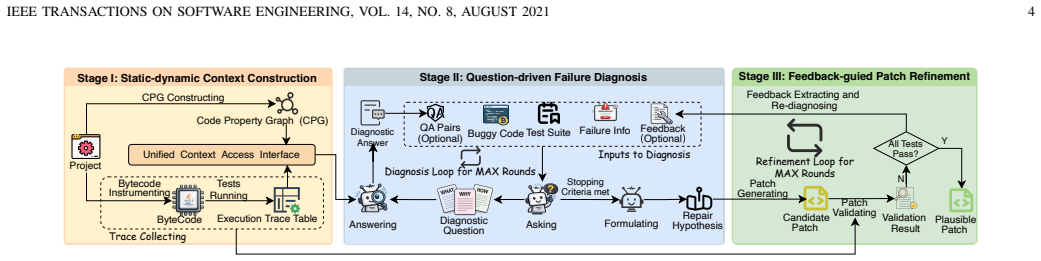
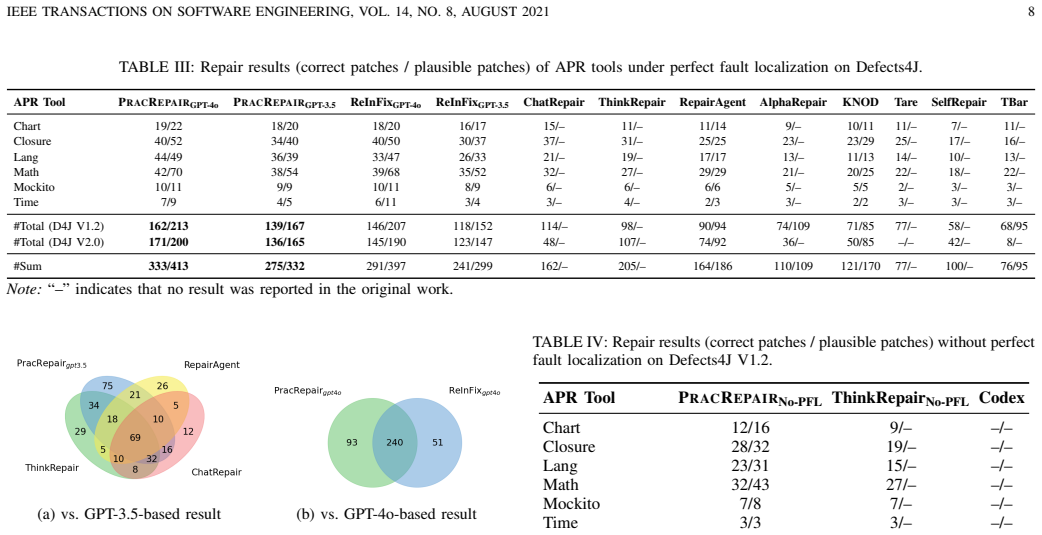
PracRepair constructs an on-demand static-dynamic context from buggy programs and failure executions, performs question-driven failure diagnosis to formulate explicit repair hypotheses, and iteratively refines candidate patches using validation diagnostics and trace-level behavioral changes. On Defects4J V1.2 and V2.0, it fixes 139/136 bugs under GPT-3.5 and 162/171 under GPT-4o while outperforming state-of-the-art baselines and achieving the best results on real-world bugs across multiple models.
What carries the argument
Question-driven failure diagnosis that formulates explicit repair hypotheses from on-demand static-dynamic context, followed by iterative refinement using validation diagnostics and trace-level behavioral changes.
If this is right
- Correctly fixes 139 bugs on Defects4J V1.2 and 136 on V2.0 under GPT-3.5
- Increases to 162 and 171 correct fixes under GPT-4o on the same benchmarks
- Consistently outperforms existing LLM-based and traditional automated repair baselines
- Achieves best performance on real-world bugs across multiple foundation models
Where Pith is reading between the lines
- The diagnosis step could be adapted to help LLMs handle other tasks that require interpreting execution behavior, such as test generation.
- If the context construction scales, it might reduce the manual effort needed to localize bugs in large codebases.
- Integration into developer tools could allow automatic repair suggestions during the edit-compile-debug cycle.
Load-bearing premise
The LLM can reliably interpret large noisy failure-execution traces and raw static-dynamic context to form accurate repair hypotheses and use validation diagnostics without systematic hallucination or omission of key details.
What would settle it
A Defects4J bug where PracRepair generates an incorrect patch because it misreads or omits a key behavioral difference in the execution trace that distinguishes the buggy from the correct behavior.
Figures


read the original abstract
As software systems grow in scale and complexity, debugging and repair remain costly and time-consuming. Large language models (LLMs) have advanced automated program repair (APR), but existing LLM-based APR approaches still largely rely on static or retrieved context, error messages, and coarse-grained validation outcomes. As a result, they underutilize dynamic information for failure understanding and repair, including failure-execution dynamics and patch-validation dynamics. Effectively leveraging such information, however, is challenging: failure-execution traces are large and noisy, raw static-dynamic context is not self-explanatory, and patch-validation dynamics are often reduced to coarse feedback. To address these challenges, we propose \textsc{PracRepair}, a fully automated LLM-based APR framework inspired by human-like debugging practices. \textsc{PracRepair} constructs an on-demand static-dynamic context from buggy programs and failure executions, performs question-driven failure diagnosis to formulate explicit repair hypotheses, and iteratively refines candidate patches using validation diagnostics and trace-level behavioral changes. Experimental results on Defects4J V1.2 and V2.0 show that \textsc{PracRepair} consistently outperforms state-of-the-art baselines. Specifically, under GPT-3.5, \textsc{PracRepair} correctly fixes 139/136 bugs on Defects4J V1.2/V2.0, while under GPT-4o it further improves to 162/171. Moreover, \textsc{PracRepair} generalizes effectively to RWB (Real-World Bugs), achieving the best performance across multiple foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PracRepair, an LLM-based automated program repair framework inspired by human-like debugging. It builds on-demand static-dynamic context from buggy code and failure executions, uses question-driven diagnosis to form explicit repair hypotheses, and iteratively refines patches via validation diagnostics and trace-level behavioral feedback. On Defects4J V1.2/V2.0, it reports fixing 139/136 bugs with GPT-3.5 and 162/171 with GPT-4o while outperforming SOTA baselines, and generalizes to real-world bugs (RWB).
Significance. If the performance gains are robustly attributable to the proposed use of dynamic traces and diagnosis rather than model scale or prompt engineering alone, and if the method generalizes without overfitting to Defects4J, PracRepair could meaningfully advance LLM-based APR by better exploiting execution dynamics. The reported numbers and cross-model results would then represent a concrete step beyond static-context approaches.
major comments (2)
- [Experimental Results] Experimental Results section: the central claim attributes the 139/136 (GPT-3.5) and 162/171 (GPT-4o) fixes on Defects4J V1.2/V2.0 to on-demand static-dynamic context, question-driven diagnosis, and trace-level validation feedback, yet no direct measurement of diagnosis fidelity (e.g., precision of hypothesized root causes vs. developer patches or trace ground truth) is supplied. This is load-bearing because the outperformance could otherwise arise from generic LLM capabilities or prompt design.
- [Methodology and Evaluation] Methodology and Evaluation sections: the assumption that the LLM reliably extracts accurate behavioral details from large noisy failure-execution traces and patch-validation dynamics (without systematic hallucination or omission) is unverified by any ablation or fidelity metric. Adding such a measurement would be required to support the causal attribution to the human-like practices.
minor comments (2)
- The description of baseline configurations and statistical significance tests for the reported fix counts should be expanded for reproducibility.
- Clarify the exact prompting templates and context-construction heuristics in the framework overview to aid replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the importance of directly linking performance gains to the proposed human-like debugging components rather than model scale or prompting alone. We address each major comment below and outline targeted revisions.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the central claim attributes the 139/136 (GPT-3.5) and 162/171 (GPT-4o) fixes on Defects4J V1.2/V2.0 to on-demand static-dynamic context, question-driven diagnosis, and trace-level validation feedback, yet no direct measurement of diagnosis fidelity (e.g., precision of hypothesized root causes vs. developer patches or trace ground truth) is supplied. This is load-bearing because the outperformance could otherwise arise from generic LLM capabilities or prompt design.
Authors: We agree that the absence of a direct fidelity metric for the diagnosis hypotheses is a limitation in the current manuscript and weakens the causal attribution. While the cross-model results and outperformance over static-context baselines using identical LLMs provide supporting evidence, these are indirect. In the revision we will add a new subsection reporting a manual fidelity analysis on a random sample of 50 diagnosis outputs, measuring precision of hypothesized root causes against developer patches and execution traces. This will be presented alongside the existing results. revision: yes
-
Referee: [Methodology and Evaluation] Methodology and Evaluation sections: the assumption that the LLM reliably extracts accurate behavioral details from large noisy failure-execution traces and patch-validation dynamics (without systematic hallucination or omission) is unverified by any ablation or fidelity metric. Adding such a measurement would be required to support the causal attribution to the human-like practices.
Authors: We concur that verifying the reliability of LLM trace processing is necessary to rule out systematic hallucination or omission. The current manuscript does not include such a fidelity metric or dedicated ablation on trace extraction. We will revise the Evaluation section to include (1) an ablation isolating the trace-level behavioral feedback component and (2) a sampled fidelity check on extracted behavioral details from failure and validation traces, quantifying omission and hallucination rates. These additions will directly address the concern. revision: yes
Circularity Check
No significant circularity; empirical evaluation against external baselines
full rationale
The paper describes an LLM-based APR framework evaluated empirically on Defects4J V1.2/V2.0 and Real-World Bugs, reporting fix counts against state-of-the-art baselines. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided text. All performance claims rest on direct comparison to independent external benchmarks rather than any internal reduction of results to inputs by construction. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can form accurate repair hypotheses from constructed static-dynamic context and question-driven prompts
Reference graph
Works this paper leans on
-
[1]
Snopy: Bridging sample denoising with causal graph learning for effective vulnerability detection
Sicong Cao, Xiaobing Sun, Xiaoxue Wu, David Lo, Lili Bo, Bin Li, Xiaolei Liu, Xingwei Lin, and Wei Liu. Snopy: Bridging sample denoising with causal graph learning for effective vulnerability detection. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE ’24, page 606–618, New York, NY , USA, 2024. Associatio...
2024
-
[2]
Neural transfer learning for repairing security vulnerabilities in c code.IEEE Transac- tions on Software Engineering, 49(1):147–165, 2023
Zimin Chen, Steve Kommrusch, and Martin Monperrus. Neural transfer learning for repairing security vulnerabilities in c code.IEEE Transac- tions on Software Engineering, 49(1):147–165, 2023
2023
-
[3]
Ren ´e Just, Darioush Jalali, and Michael D. Ernst. Defects4j: a database of existing faults to enable controlled testing studies for java programs. InProceedings of the 2014 International Symposium on Software Testing and Analysis, ISSTA 2014, page 437–440, New York, NY , USA, 2014. Association for Computing Machinery
2014
-
[4]
Intellij idea: The leading ide for professional java and kotlin development
JetBrains. Intellij idea: The leading ide for professional java and kotlin development. https://www.jetbrains.com/idea/. Accessed: 2026-03-21
2026
-
[5]
Visual studio code: The open source ai code editor
Microsoft. Visual studio code: The open source ai code editor. https: //code.visualstudio.com/. Accessed: 2026-03-21
2026
-
[6]
John D. Gould. Some psychological evidence on how people debug computer programs.International Journal of Man-Machine Studies, 7(2):151–182, 1975
1975
-
[7]
Ko and Brad A
Amy J. Ko and Brad A. Myers. Designing the whyline: a debugging interface for asking questions about program behavior. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’04, page 151–158, New York, NY , USA, 2004. Association for Computing Machinery
2004
-
[8]
Murphy, and Kris De V older
Jonathan Sillito, Gail C. Murphy, and Kris De V older. Asking and answering questions during a programming change task.IEEE Trans. Softw. Eng., 34(4):434–451, July 2008
2008
-
[9]
Debugging revisited: Toward un- derstanding the debugging needs of contemporary software developers
Lucas Layman, Madeline Diep, Meiyappan Nagappan, Janice Singer, Robert Deline, and Gina Venolia. Debugging revisited: Toward un- derstanding the debugging needs of contemporary software developers. In2013 ACM / IEEE International Symposium on Empirical Software Engineering and Measurement, pages 383–392, 2013
2013
-
[10]
A qualitative study on framework debugging
Zack Coker, David Gray Widder, Claire Le Goues, Christopher Bogart, and Joshua Sunshine. A qualitative study on framework debugging. In2019 IEEE International Conference on Software Maintenance and Evolution (ICSME), pages 568–579, 2019
2019
-
[11]
When automated program repair meets regression testing—an extensive study on two million patches
Yiling Lou, Jun Yang, Samuel Benton, Dan Hao, Lin Tan, Zhenpeng Chen, Lu Zhang, and Lingming Zhang. When automated program repair meets regression testing—an extensive study on two million patches. ACM Trans. Softw. Eng. Methodol., 33(7), September 2024
2024
-
[12]
Levin, Nicolas van Kempen, Emery D
Kyla H. Levin, Nicolas van Kempen, Emery D. Berger, and Stephen N. Freund. Chatdbg: Augmenting debugging with large language models. Proc. ACM Softw. Eng., 2(FSE), June 2025
2025
-
[13]
Abdulaziz Alaboudi and Thomas D. Latoza. Hypothesizer: A hypothesis-based debugger to find and test debugging hypotheses. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23, New York, NY , USA, 2023. Association for Computing Machinery
2023
-
[14]
Devon H. O’Dell. The debugging mind-set.Commun. ACM, 60(6):40–45, May 2017
2017
-
[15]
Hadeel Eladawy, Claire Le Goues, and Yuriy Brun. Automated program repair, what is it good for? not absolutely nothing! InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ICSE ’24, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[16]
The cost of poor software quality in the us: A 2020 report.Proc
Herb Krasner. The cost of poor software quality in the us: A 2020 report.Proc. Consortium Inf. Softw. QualityTM (CISQTM), 2(3), 2021
2020
-
[17]
Automated program repair.Commun
Claire Le Goues, Michael Pradel, and Abhik Roychoudhury. Automated program repair.Commun. ACM, 62(12):56–65, November 2019
2019
-
[18]
Bissyand ´e
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawend ´e F. Bissyand ´e. Tbar: revisiting template-based automated program repair. InProceed- ings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2019, page 31–42, New York, NY , USA,
2019
-
[20]
Selfapr: Self-supervised program repair with test execution diagnostics
He Ye, Matias Martinez, Xiapu Luo, Tao Zhang, and Martin Monperrus. Selfapr: Self-supervised program repair with test execution diagnostics. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, ASE ’22, New York, NY , USA, 2023. Association for Computing Machinery
2023
-
[21]
Tare: Type-Aware Neural Program Repair
Qihao Zhu, Zeyu Sun, Wenjie Zhang, Yingfei Xiong, and Lu Zhang. Tare: Type-Aware Neural Program Repair . In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1443– 1455, Los Alamitos, CA, USA, May 2023. IEEE Computer Society
2023
-
[22]
Cure: Code-aware neural machine translation for automatic program repair
Nan Jiang, Thibaud Lutellier, and Lin Tan. Cure: Code-aware neural machine translation for automatic program repair. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), pages 1161–1173, 2021
2021
-
[23]
Knod: Domain knowledge distilled tree decoder for automated program repair
Nan Jiang, Thibaud Lutellier, Yiling Lou, Lin Tan, Dan Goldwasser, and Xiangyu Zhang. Knod: Domain knowledge distilled tree decoder for automated program repair. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1251–1263, 2023
2023
-
[24]
Iter: Iterative neural repair for multi- location patches
He Ye and Martin Monperrus. Iter: Iterative neural repair for multi- location patches. InProceedings of the IEEE/ACM 46th International IEEE TRANSACTIONS ON SOFTW ARE ENGINEERING, VOL. 14, NO. 8, AUGUST 2021 12 Conference on Software Engineering, ICSE ’24, New York, NY , USA,
2021
-
[25]
Association for Computing Machinery
-
[26]
Less training, more repairing please: revisiting automated program repair via zero-shot learning
Chunqiu Steven Xia and Lingming Zhang. Less training, more repairing please: revisiting automated program repair via zero-shot learning. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, page 959–971, New York, NY , USA, 2022. Associa- tion for Computing Machinery
2022
-
[27]
Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chat- gpt
Chunqiu Steven Xia and Lingming Zhang. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chat- gpt. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, page 819–831, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[28]
Repairagent: An autonomous, llm-based agent for program repair
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. Repairagent: An autonomous, llm-based agent for program repair. InProceedings of the IEEE/ACM 47th International Conference on Software Engineering, ICSE ’25, page 2188–2200. IEEE Press, 2025
2025
-
[29]
Thinkrepair: Self-directed automated program repair
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang. Thinkrepair: Self-directed automated program repair. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, page 1274–1286, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[30]
Repair ingredients are all you need: Improving large language model- based program repair via repair ingredients search, 2025
Jiayi Zhang, Kai Huang, Jian Zhang, Yang Liu, and Chunyang Chen. Repair ingredients are all you need: Improving large language model- based program repair via repair ingredients search, 2025
2025
-
[31]
Evolving paradigms in automated program repair: Taxonomy, challenges, and opportunities.ACM Comput
Kai Huang, Zhengzi Xu, Su Yang, Hongyu Sun, Xuejun Li, Zheng Yan, and Yuqing Zhang. Evolving paradigms in automated program repair: Taxonomy, challenges, and opportunities.ACM Comput. Surv., 57(2), October 2024
2024
-
[32]
Patch generation with language models: Feasibility and scaling behavior
Sophia D Kolak, Ruben Martins, Claire Le Goues, and Vincent Josua Hellendoorn. Patch generation with language models: Feasibility and scaling behavior. InDeep Learning for Code Workshop, 2022
2022
-
[33]
Can openai’s codex fix bugs?: An evaluation on quixbugs
Julian Aron Prenner, Hlib Babii, and Romain Robbes. Can openai’s codex fix bugs?: An evaluation on quixbugs. In2022 IEEE/ACM International Workshop on Automated Program Repair (APR), pages 69–75, 2022
2022
-
[34]
Joern: The bug hunter’s workbench
joernio. Joern: The bug hunter’s workbench. https://github.com/joernio/ joern, 2024. Accessed: 2026-03-06
2024
-
[35]
Model- ing and discovering vulnerabilities with code property graphs
Fabian Yamaguchi, Nico Golde, Daniel Arp, and Konrad Rieck. Model- ing and discovering vulnerabilities with code property graphs. In2014 IEEE Symposium on Security and Privacy, pages 590–604, 2014
2014
-
[36]
Safe automated refactoring for intelligent parallelization of java 8 streams
Raffi Khatchadourian, Yiming Tang, Mehdi Bagherzadeh, and Syed Ahmed. Safe automated refactoring for intelligent parallelization of java 8 streams. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pages 619–630, 2019
2019
-
[37]
Package java.lang.instrument
Oracle. Package java.lang.instrument. Java Platform, Standard Edition API Specification. Accessed: 2026-03-06
2026
-
[38]
Asm: a code manipulation tool to implement adaptable systems.Adaptable and extensible
Romain Lenglet. Asm: a code manipulation tool to implement adaptable systems.Adaptable and extensible. . ., 2002
2002
-
[39]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Repre- sentations (ICLR), 2023
2023
-
[40]
Anonymous Authors. Artifact: Source code, prompts, datasets, and experimental results for this paper. https://doi.org/10.5281/zenodo. 19336422, 2026. Anonymous research artifact
-
[41]
gpt-3.5-turbo-0125
OpenAI. gpt-3.5-turbo-0125. https://developers.openai.com/api/docs/ models#gpt-3-5-turbo, September 2023. Accessed: 2025-09-29
2023
-
[42]
Gpt-4o-2024-05-13: Openai’s next-generation language model
OpenAI. Gpt-4o-2024-05-13: Openai’s next-generation language model. https://developers.openai.com/api/docs/models#gpt-4-turbo-and-gpt-4, September 2023. Accessed: 2025-09-29
2024
-
[43]
Chatgpt out- performs crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences, 120(30):e2305016120, 2023
Fabrizio Gilardi, Meysam Alizadeh, and Ma ¨el Kubli. Chatgpt out- performs crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences, 120(30):e2305016120, 2023
2023
-
[44]
OpenAI. GPT-4. https://developers.openai.com/api/docs/models/gpt-4,
-
[45]
OpenAI API documentation
-
[46]
Meta Llama 3: The Most Capable Openly Available LLM to Date
Ollama. Meta Llama 3: The Most Capable Openly Available LLM to Date. https://ollama.com/library/llama3, 2024
2024
-
[47]
DeepSeek Coder: Let the Code Write Itself
DeepSeek AI. DeepSeek Coder: Let the Code Write Itself. https:// github.com/deepseek-ai/DeepSeek-Coder, 2023. GitHub repository
2023
-
[48]
Automated program repair in the era of large pre-trained language models, 2023
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. Automated program repair in the era of large pre-trained language models, 2023
2023
-
[49]
Genprog: A generic method for automatic software repair
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. Genprog: A generic method for automatic software repair. IEEE Transactions on Software Engineering, 38(1):54–72, 2012
2012
-
[50]
Au- tomatic patch generation learned from human-written patches
Dongsun Kim, Jaechang Nam, Jaewoo Song, and Sunghun Kim. Au- tomatic patch generation learned from human-written patches. InPro- ceedings of the 2013 International Conference on Software Engineering, ICSE ’13, page 802–811. IEEE Press, 2013
2013
-
[51]
Rohan Bavishi, Hiroaki Yoshida, and Mukul R. Prasad. Phoenix: automated data-driven synthesis of repairs for static analysis violations. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2019, page 613–624, New York, NY , USA, 2019. Association fo...
2019
-
[52]
Semfix: program repair via semantic analysis
Hoang Duong Thien Nguyen, Dawei Qi, Abhik Roychoudhury, and Satish Chandra. Semfix: program repair via semantic analysis. InPro- ceedings of the 2013 International Conference on Software Engineering, ICSE ’13, page 772–781. IEEE Press, 2013
2013
-
[53]
Characteristic studies of loop problems for structural test generation via symbolic exe- cution
Xusheng Xiao, Sihan Li, Tao Xie, and Nikolai Tillmann. Characteristic studies of loop problems for structural test generation via symbolic exe- cution. InProceedings of the 28th IEEE/ACM International Conference on Automated Software Engineering, ASE ’13, page 246–256. IEEE Press, 2013
2013
-
[54]
Program repair guided by datalog-defined static analysis
Yu Liu, Sergey Mechtaev, Pavle Suboti ´c, and Abhik Roychoudhury. Program repair guided by datalog-defined static analysis. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023, page 1216–1228, New York, NY , USA, 2023. Association for Computing Machinery
2023
-
[55]
Sapfix: Automated end-to-end repair at scale
Alexandru Marginean, Johannes Bader, Satish Chandra, Mark Harman, Yue Jia, Ke Mao, Alexander Mols, and Andrew Scott. Sapfix: Automated end-to-end repair at scale. In2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 269–278, 2019
2019
-
[56]
Deep reinforcement learning for syntactic error repair in student programs
Rahul Gupta, Aditya Kanade, and Shirish Shevade. Deep reinforcement learning for syntactic error repair in student programs. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence,...
2019
-
[57]
Learning to fix build errors with graph2diff neural networks
Daniel Tarlow, Subhodeep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Sutton, and Edward Aftandilian. Learning to fix build errors with graph2diff neural networks. InProceedings of the IEEE/ACM 42nd International Conference on Software Engineer- ing Workshops, ICSEW’20, page 19–20, New York, NY , USA, 2020. Association for Computing ...
2020
-
[58]
Automatic patch generation by learning correct code
Fan Long and Martin Rinard. Automatic patch generation by learning correct code. InProceedings of the 43rd Annual ACM SIGPLAN- SIGACT Symposium on Principles of Programming Languages, POPL ’16, page 298–312, New York, NY , USA, 2016. Association for Com- puting Machinery
2016
-
[59]
Deepfix: fixing common c language errors by deep learning
Rahul Gupta, Soham Pal, Aditya Kanade, and Shirish Shevade. Deepfix: fixing common c language errors by deep learning. InProceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI’17, page 1345–1351. AAAI Press, 2017
2017
-
[60]
On learning meaningful code changes via neural machine translation
Michele Tufano, Jevgenija Pantiuchina, Cody Watson, Gabriele Bavota, and Denys Poshyvanyk. On learning meaningful code changes via neural machine translation. InProceedings of the 41st International Conference on Software Engineering, ICSE ’19, page 25–36. IEEE Press, 2019
2019
-
[61]
A syntax-guided edit decoder for neural program repair
Qihao Zhu, Zeyu Sun, Yuan-an Xiao, Wenjie Zhang, Kang Yuan, Yingfei Xiong, and Lu Zhang. A syntax-guided edit decoder for neural program repair. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2021, page 341–353, New York, NY , USA, 2021. Association...
2021
-
[62]
Yi Li, Shaohua Wang, and Tien N. Nguyen. Dlfix: context-based code transformation learning for automated program repair. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering, ICSE ’20, page 602–614, New York, NY , USA, 2020. Association for Computing Machinery
2020
-
[63]
Neural program repair with execution-based backpropagation
He Ye, Matias Martinez, and Martin Monperrus. Neural program repair with execution-based backpropagation. InProceedings of the 44th International Conference on Software Engineering, ICSE ’22, page 1506–1518, New York, NY , USA, 2022. Association for Computing Machinery
2022
-
[64]
Impact of code language models on automated program repair
Nan Jiang, Kevin Liu, Thibaud Lutellier, and Lin Tan. Impact of code language models on automated program repair. InProceedings of the 45th International Conference on Software Engineering, ICSE ’23, page 1430–1442. IEEE Press, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.