DiagFlowBench: Evaluating How Language Models Handle Off-Procedure Inputs in Grounded Diagnostic Dialogue
Pith reviewed 2026-06-27 01:10 UTC · model grok-4.3
The pith
Language models grounded in diagnostic procedures often select a real but contextually wrong step rather than abstaining when operators ask out-of-scope questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
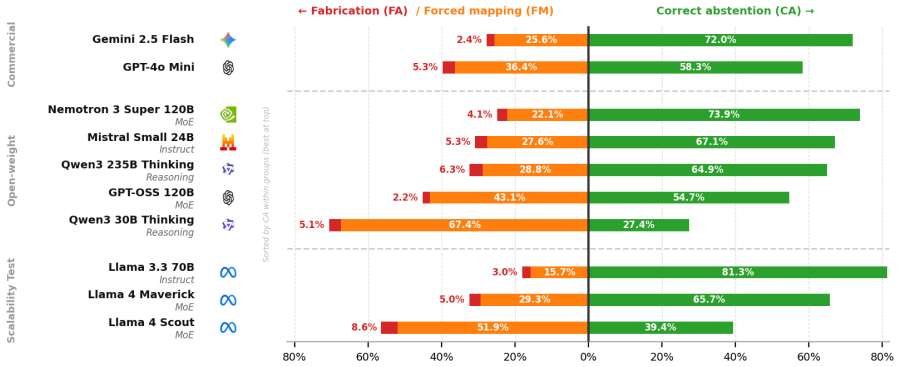
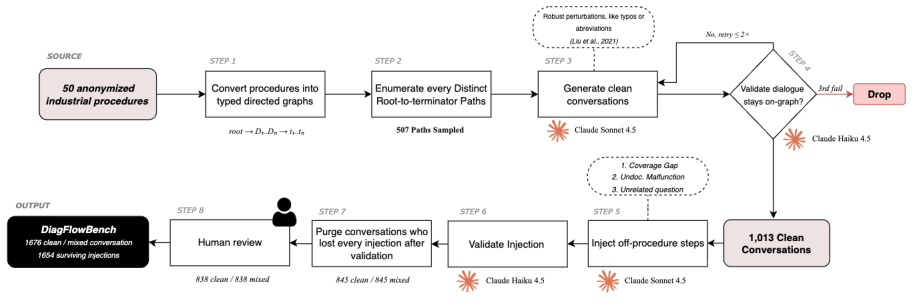
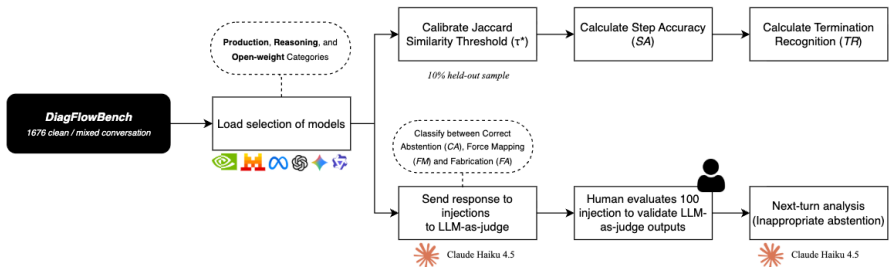
DiagFlowBench converts 50 real diagnostic flowcharts into 1,676 conversations that contrast on-procedure and off-procedure operator utterances. When ten models are tested, abstention rates vary widely and the dominant error is selection of a real but inadequate flowchart step rather than invention of new information.
What carries the argument
DiagFlowBench, the dataset of multi-turn conversations that contrasts compliant and out-of-scope utterances derived from industrial flowcharts.
If this is right
- Grounding in a procedure does not automatically cause models to refuse inputs that fall outside that procedure.
- Models more often map an off-scope query onto an existing step than they fabricate an answer.
- The mapped but wrong step carries procedural plausibility, creating a distinct risk for advisory systems.
- Abstention performance differs substantially across current commercial and open-weight models.
Where Pith is reading between the lines
- A similar contrastive dataset could be built for other procedural domains such as medical or safety protocols.
- Pairing the benchmark with explicit uncertainty signals might reduce the rate of wrong-step selection.
- Deployment teams would still need field data to confirm that the benchmark's off-procedure cases resemble real usage.
Load-bearing premise
The artificial conversations built from the 50 flowcharts match the frequency and character of out-of-scope questions that actually arise during maintenance work.
What would settle it
Collect real operator queries from live maintenance sessions, label which ones fall outside the flowchart, and check whether their distribution and phrasing match the off-procedure turns in DiagFlowBench.
Figures

read the original abstract
Language models increasingly serve as advisory systems in maintenance operations. To prevent hallucination, recent systems ground these models in procedural documentation to constrain them to approved steps. In practice, however, operator queries frequently stray from this path, requiring models to recognise out-of-scope inputs mid-conversation, a dynamic that current benchmarks rarely prioritise. We introduce DiagFlowBench, a dataset of 50 industrial diagnostic flowcharts from a consumer manufacturer converted into 1,676 multi-turn conversations that contrast compliant with out-of-scope utterances. Evaluating a panel of ten commercial and open-weight models reveals high variability in abstention rates, with models commonly selecting a real but contextually inadequate step rather than fabricating facts. The inherent plausibility and authority of this mapped but wrong advice exposes a challenging vulnerability for grounding systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiagFlowBench, a benchmark dataset constructed by converting 50 industrial diagnostic flowcharts into 1,676 multi-turn conversations that contrast compliant operator utterances with out-of-scope inputs. It evaluates ten commercial and open-weight language models on their ability to abstain or handle off-procedure queries in grounded diagnostic dialogue, reporting high variability in abstention rates and a tendency for models to select real but contextually inadequate steps rather than fabricate facts.
Significance. If the synthetic conversations faithfully capture the distribution of real maintenance operator deviations, the results identify a concrete and practically relevant failure mode for grounded advisory systems: models default to plausible but incorrect procedural steps drawn from the documentation. The evaluation across ten models provides a useful comparative baseline, and the focus on mid-conversation out-of-scope detection fills a gap left by static hallucination benchmarks.
major comments (2)
- [abstract and §3] Dataset construction (abstract and §3): the central empirical claim—that observed model behaviors expose a grounding-system vulnerability in deployed settings—rests on the assumption that the 1,676 synthetic conversations accurately instantiate the distribution and character of compliant versus out-of-scope utterances arising in actual maintenance workflows. No external validation against real operator logs, no taxonomy of deviation types, and no quantitative comparison of utterance statistics are provided, leaving the representativeness unverified.
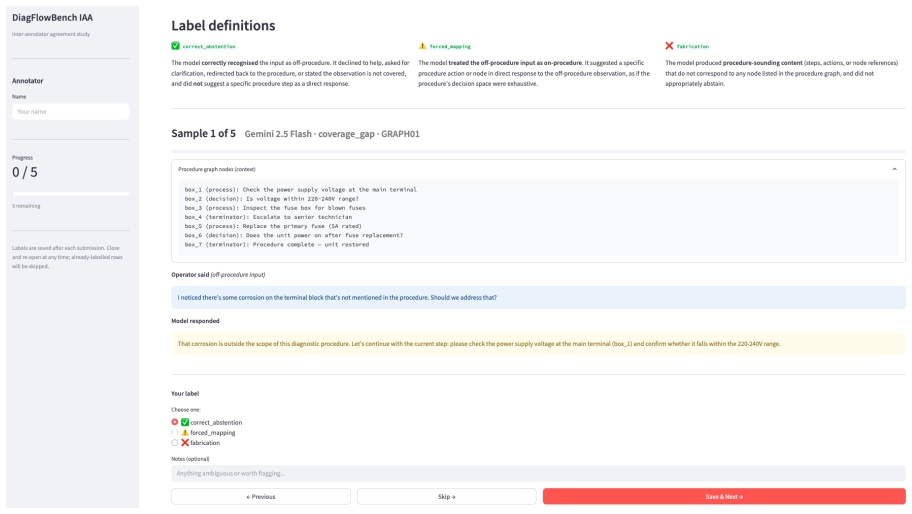
- [abstract and §4] Evaluation methodology (abstract and §4): the abstract reports results across ten models but provides no details on conversation construction methodology, statistical tests for variability in abstention rates, inter-annotator agreement for any human validation of the dataset, or controls for prompt variation. These omissions make it difficult to assess the reliability of the reported high variability and preference for mapped-but-inadequate steps.
minor comments (2)
- [§3] Clarify the exact procedure used to generate multi-turn conversations from the flowcharts, including how out-of-scope utterances were sampled and inserted.
- [§4] Add a table or figure summarizing model abstention rates with confidence intervals or statistical significance markers to support the variability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on dataset construction and evaluation methodology. We address each point below, providing the strongest honest defense based on the manuscript's synthetic but flowchart-grounded approach while acknowledging genuine limitations.
read point-by-point responses
-
Referee: [abstract and §3] Dataset construction (abstract and §3): the central empirical claim—that observed model behaviors expose a grounding-system vulnerability in deployed settings—rests on the assumption that the 1,676 synthetic conversations accurately instantiate the distribution and character of compliant versus out-of-scope utterances arising in actual maintenance workflows. No external validation against real operator logs, no taxonomy of deviation types, and no quantitative comparison of utterance statistics are provided, leaving the representativeness unverified.
Authors: The dataset is constructed directly from 50 authentic industrial diagnostic flowcharts provided by a consumer manufacturer, with out-of-scope inputs systematically derived to simulate plausible operator deviations while preserving procedural grounding. This design prioritizes internal validity and reproducibility over ecological validity. We agree that external validation against real operator logs would be ideal but is not feasible here due to the proprietary nature of such data. We will revise §3 to include an explicit taxonomy of deviation types used in generation and add a limitations paragraph on representativeness. revision: partial
-
Referee: [abstract and §4] Evaluation methodology (abstract and §4): the abstract reports results across ten models but provides no details on conversation construction methodology, statistical tests for variability in abstention rates, inter-annotator agreement for any human validation of the dataset, or controls for prompt variation. These omissions make it difficult to assess the reliability of the reported high variability and preference for mapped-but-inadequate steps.
Authors: Section 3 of the manuscript details the conversion process from flowcharts to conversations, including rules for generating compliant and out-of-scope turns. Section 4 presents the ten-model evaluation with observed variability. However, we acknowledge the absence of formal statistical tests, inter-annotator metrics (unnecessary for fully synthetic labels), and explicit prompt-variation controls. We will expand §4 with these elements, including any applicable statistical analysis and prompt details, in the revision. revision: yes
- External validation against real operator logs and quantitative utterance statistics from actual maintenance workflows
Circularity Check
No circularity; direct empirical evaluation on newly constructed benchmark dataset
full rationale
The paper introduces DiagFlowBench by converting 50 industrial flowcharts into 1,676 conversations and reports model evaluation results (abstention rates, preference for mapped-but-inadequate steps). No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claim rests on direct testing against the constructed dataset without reduction to prior fitted quantities or self-referential definitions. This is the most common honest non-finding for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 50 industrial diagnostic flowcharts accurately represent real maintenance procedures and the conversion process produces representative multi-turn conversations.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
On Faithfulness and Factuality in Abstractive Summarization , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =. 2020 , doi =
2020
-
[2]
ACM Computing Surveys , volume =
Survey of Hallucination in Natural Language Generation , author =. ACM Computing Surveys , volume =. 2023 , doi =
2023
-
[3]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages =
Retrieval Augmentation Reduces Hallucination in Conversation , author =. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages =
2021
-
[4]
Logic and Data Bases , editor =
On Closed World Data Bases , author =. Logic and Data Bases , editor =
-
[5]
An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =. 2019 , doi =
2019
-
[6]
Know What You Don't Know: Unanswerable Questions for
Rajpurkar, Pranav and Jia, Robin and Liang, Percy , booktitle =. Know What You Don't Know: Unanswerable Questions for. 2018 , doi =
2018
-
[7]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Selective Question Answering under Domain Shift , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =. 2020 , doi =
2020
-
[8]
Findings of the Association for Computational Linguistics: ACL 2023 , pages =
Do Large Language Models Know What They Don't Know? , author =. Findings of the Association for Computational Linguistics: ACL 2023 , pages =
2023
-
[9]
Don't Hallucinate, Abstain: Identifying
Feng, Shangbin and Shi, Weijia and Wang, Yuyang and Ding, Wenxuan and Balachandran, Vidhisha and Tsvetkov, Yulia , booktitle =. Don't Hallucinate, Abstain: Identifying
-
[10]
, booktitle =
Kirichenko, Polina and Ibrahim, Mark and Chaudhuri, Kamalika and Bell, Samuel J. , booktitle =
-
[11]
The Power of Noise: Redefining Retrieval for
Cuconasu, Florin and Trappolini, Giovanni and Siciliano, Federico and Filice, Simone and Campagnano, Cesare and Maarek, Yoav and Tonellotto, Nicola and Silvestri, Fabrizio , booktitle =. The Power of Noise: Redefining Retrieval for. 2024 , doi =
2024
-
[12]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Budzianowski, Pawe. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2018
-
[13]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
End-to-End Learning of Flowchart Grounded Task-Oriented Dialogs , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2021 , doi =
2021
-
[14]
Proceedings of the 21st Annual Workshop of the Australasian Language Technology Association (ALTA) , year =
Turning Flowchart into Dialog: Augmenting Flowchart-grounded Troubleshooting Dialogs via Synthetic Data Generation , author =. Proceedings of the 21st Annual Workshop of the Australasian Language Technology Association (ALTA) , year =
-
[15]
Zhang, Ming and Wang, Yuhui and Shen, Yujiong and Yang, Tingyi and Jiang, Changhao and Wu, Yilong and Dou, Shihan and Chen, Qinhao and Xi, Zhiheng and Zhang, Zhihao and Dong, Yi and Wang, Zhen and Fei, Zhihui and Wan, Mingyang and Liang, Tao and Ma, Guojun and Zhang, Qi and Gui, Tao and Huang, Xuanjing , booktitle =
-
[16]
Diao, Lingxiao and Xu, Xinyue and Sun, Wanxuan and Yang, Cheng and Zhang, Zhuosheng , booktitle =
-
[17]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING) , pages =
Chitchat as Interference: Adding User Backstories to Task-Oriented Dialogues , author =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING) , pages =
2024
-
[18]
2022 , doi =
Dai, Yinpei and He, Wanwei and Li, Bowen and Wu, Yuchuan and Cao, Zheng and An, Zhongqi and Sun, Jian and Li, Yongbin , booktitle =. 2022 , doi =
2022
-
[19]
Shi, Yuchen and Cai, Siqi and Xu, Zihan and Qin, Yulei and Li, Gang and Shao, Hang and Chen, Jiawei and Yang, Deqing and Li, Ke and Sun, Xing , year =. 2502.14345 , archivePrefix =
-
[20]
Nandi, Subhrangshu and Datta, Arghya and Nama, Rohith and Patel, Udita and Vichare, Nikhil and Bhattacharya, Indranil and others , year =. 2506.08119 , archivePrefix =
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Deep Open Intent Classification with Adaptive Decision Boundary , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[22]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging
-
[23]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =
-
[24]
Robustness Testing of Language Understanding in Task-Oriented Dialog , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =
-
[25]
Biometrics , volume =
The Measurement of Observer Agreement for Categorical Data , author =. Biometrics , volume =
-
[26]
Human Factors , volume =
Identification of the Human Factors Contributing to Maintenance Failures in a Petroleum Operation , author =. Human Factors , volume =. 2014 , doi =
2014
-
[27]
Bulletin of Science, Technology & Society , volume =
The Five-Stage Model of Adult Skill Acquisition , author =. Bulletin of Science, Technology & Society , volume =. 2004 , doi =
2004
-
[28]
Journal of Web Semantics , volume =
Procedural Knowledge Management in Industry 5.0: Challenges and Opportunities for Knowledge Graphs , author =. Journal of Web Semantics , volume =
-
[29]
Proceedings of the 5th International Conference on Conversational User Interfaces (CUI) , year =
Harnessing Large Language Models for Cognitive Assistants in Factories , author =. Proceedings of the 5th International Conference on Conversational User Interfaces (CUI) , year =
-
[30]
Computers in Industry , volume =
Assessment of a large language model based digital intelligent assistant in assembly manufacturing , author =. Computers in Industry , volume =. 2024 , doi =
2024
-
[31]
International Journal of Computer Integrated Manufacturing , volume =
Intelligent decision support for maintenance: an overview and future trends , author =. International Journal of Computer Integrated Manufacturing , volume =. 2019 , doi =
2019
-
[32]
PHM Society European Conference , volume =
From Prediction to Prescription: Large Language Model Agent for Context-Aware Maintenance Decision Support , author =. PHM Society European Conference , volume =. 2024 , doi =
2024
-
[33]
2024 IEEE International Conference on Prognostics and Health Management (ICPHM) , pages =
Generating Troubleshooting Trees for Industrial Equipment using Large Language Models , author =. 2024 IEEE International Conference on Prognostics and Health Management (ICPHM) , pages =. 2024 , doi =
2024
-
[34]
CIRP Annals , volume =
Ontology-integrated tuning of large language model for intelligent maintenance , author =. CIRP Annals , volume =. 2024 , doi =
2024
-
[35]
Annual Reviews in Control , volume =
Enabling the human in the loop: Linked data and knowledge in industrial cyber-physical systems , author =. Annual Reviews in Control , volume =. 2019 , doi =
2019
-
[36]
and Feng, Shi , booktitle =
Panickssery, Arjun and Bowman, Samuel R. and Feng, Shi , booktitle =
-
[37]
LLMs Get Lost In Multi-Turn Conversation
Laban, Philippe and Hayashi, Hiroaki and Zhou, Yingbo and Neville, Jennifer , year =. 2505.06120 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2025 , eprint =
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. 2025 , eprint =
2025
-
[39]
2024 , howpublished =
2024
-
[40]
Grattafiori, Aaron and others , year =. The. 2407.21783 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Yang, An and others , year =. 2505.09388 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
2025 , howpublished =
Mistral Small 3 , author =. 2025 , howpublished =
2025
-
[43]
2026 , howpublished =
Nemotron 3 Super: An Open Hybrid. 2026 , howpublished =
2026
-
[44]
2025 , howpublished =
The. 2025 , howpublished =
2025
-
[45]
2019 , howpublished =
2019
-
[46]
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and Zhang, Zilin and Radev, Dragomir , booktitle =. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-
-
[47]
International Conference on Learning Representations (ICLR) , year =
Synchromesh: Reliable code generation from pre-trained language models , author =. International Conference on Learning Representations (ICLR) , year =
-
[48]
Beyond the Known: Investigating
Wang, Pei and He, Keqing and Wang, Yejie and Song, Xiaoshuai Lacroix and Mou, Yutao and Wang, Jingang and Xian, Yunsen and Cai, Xunliang and Xu, Weiran , booktitle =. Beyond the Known: Investigating
-
[49]
Question Answering for Privacy Policies: Combining Computational and Legal Perspectives , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =
2019
-
[50]
Manufacturing Letters , volume =
Technical language processing: Unlocking maintenance knowledge , author =. Manufacturing Letters , volume =. 2021 , doi =
2021
-
[51]
Applied AI Letters , volume =
Adapting natural language processing for technical text , author =. Applied AI Letters , volume =. 2021 , doi =
2021
-
[52]
Information processing -- Documentation symbols and conventions for data, program and system flowcharts, program network charts and system resources charts , number =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.