DREAM: Extending Vision-Language Models with Dual-Objective Encoding for Cross-Modal Retrieval
Pith reviewed 2026-06-26 21:32 UTC · model grok-4.3
The pith
DREAM improves text-to-video retrieval by pairing masked and permuted language modeling with a hierarchical vision encoder that uses cascaded group attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
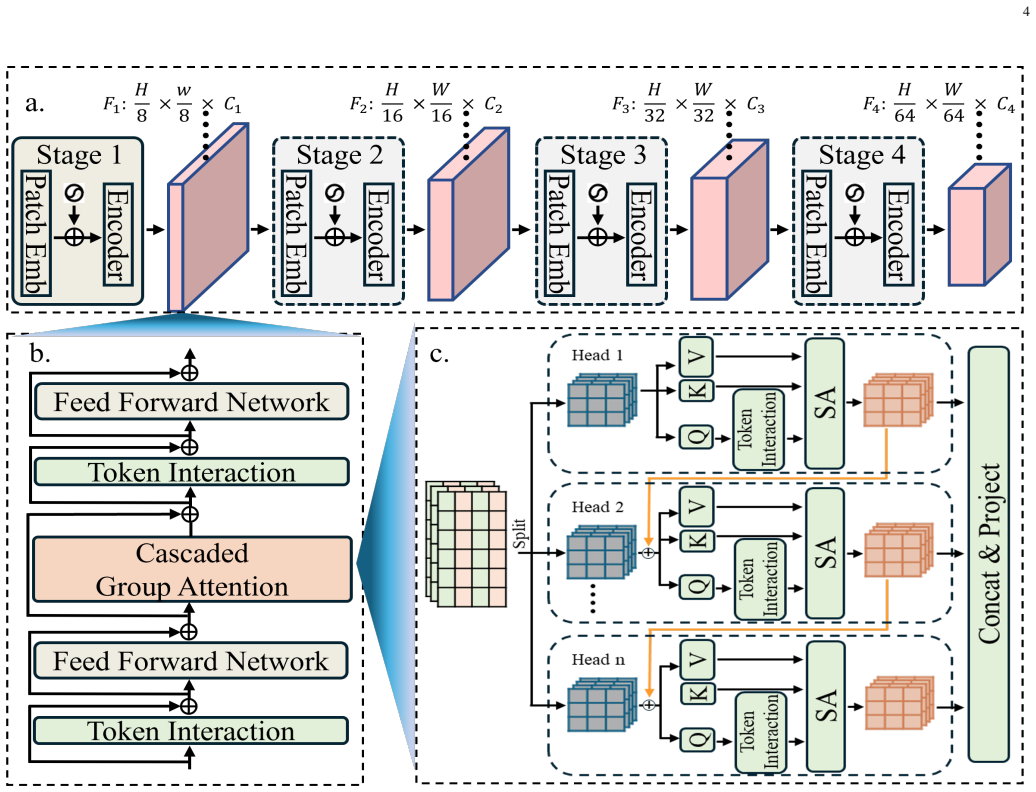
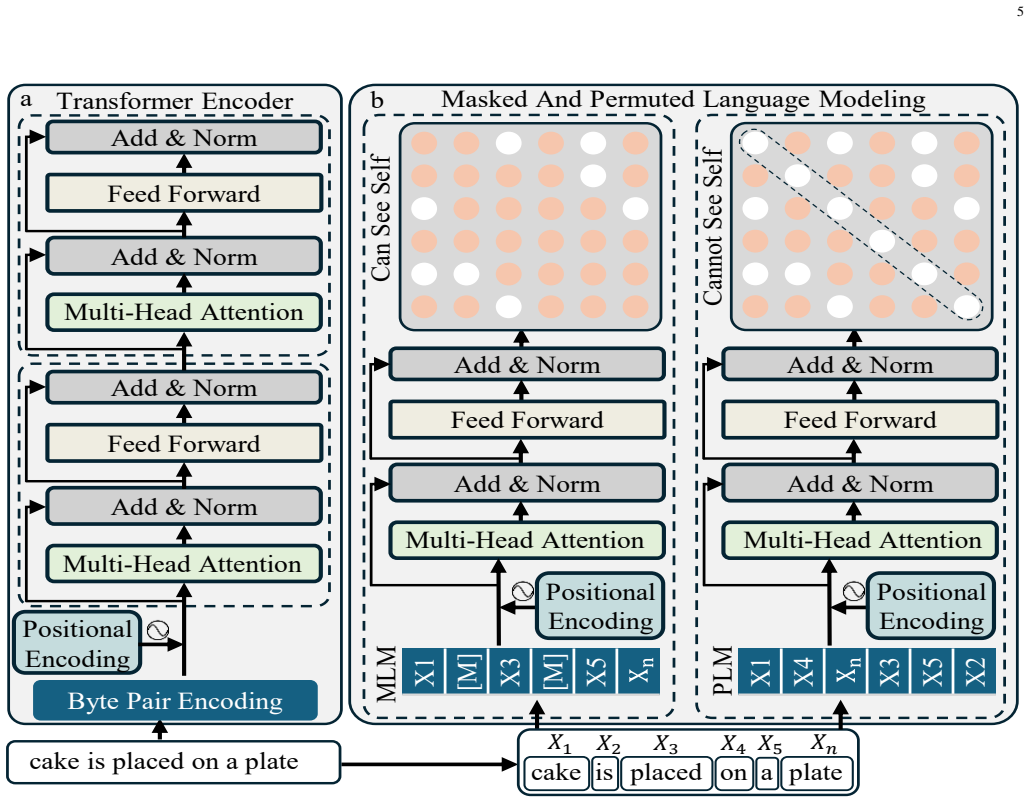
DREAM achieves new state-of-the-art recall@1 scores of 49.4 percent on MSRVTT, 49.7 percent on MSVD and 27.3 percent on LSMDC by integrating a hybrid language modeling strategy that combines masked and permuted objectives with a hierarchical vision encoder that performs multi-stage token interaction through cascaded group attention.
What carries the argument
Hybrid language modeling strategy combining masked and permuted language modeling objectives, together with a hierarchical vision encoder that uses cascaded group attention for multi-stage token interaction and coarse-to-fine refinement.
Load-bearing premise
That the reported gains on the three benchmarks are driven primarily by the hybrid language modeling and cascaded group attention rather than by other training choices or model scale.
What would settle it
An ablation that removes either the permuted language modeling objective or the cascaded group attention layers and retrains on the same three datasets, then checks whether recall@1 falls below the published numbers.
Figures




read the original abstract
In today's media-driven world, the exponential growth of video content across domains such as surveillance, education, and entertainment has made retrieving semantically relevant videos via natural language queries increasingly critical. Early video retrieval systems relied on handcrafted features or shallow cross-modal mappings, limiting their ability to capture complex semantics and temporal dynamics. While large-scale vision-language models have improved cross-modal alignment, challenges remain in modeling fine-grained temporal dependencies and nuanced linguistic structures. In this paper, we introduce DREAM: Dual-path Representation Enhancement and Alignment Model, a novel multimodal framework that addresses these limitations through enhanced visual and textual encoding. DREAM incorporates a hybrid language modeling strategy that combines masked and permuted language modeling objectives to capture both local and global linguistic semantics. On the visual side, we design a hierarchical vision encoder with cascaded group attention, which integrates spatial and temporal information through multi-stage token interaction and coarse-to-fine attention refinement. We validate DREAM through comprehensive evaluations on the widely-used MSRVTT, MSVD and LSMDC benchmark datasets, where it achieves new state-of-the-art R1 scores of 49.4%, 49.7% and 27.3%, respectively. Qualitative analyses further show the model's ability to maintain coherent attention across frames and align complex queries with dynamic video content. These findings underscore the effectiveness of hierarchical attention and dual-objective textual modeling in enabling robust, context-aware video retrieval, and pave the way for future research in advancing cross-modal representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DREAM, a multimodal framework for cross-modal video retrieval. It proposes a hybrid language modeling strategy that combines masked and permuted language modeling objectives, along with a hierarchical vision encoder using cascaded group attention for integrating spatial and temporal information. The central claim is that DREAM achieves new state-of-the-art R@1 scores of 49.4% on MSRVTT, 49.7% on MSVD, and 27.3% on LSMDC.
Significance. If the reported gains hold under standard evaluation protocols and are attributable to the proposed architectural choices, the work could advance fine-grained temporal modeling and cross-modal alignment in video-language retrieval.
major comments (1)
- [Abstract] Abstract: The claim of new state-of-the-art R@1 scores is presented without any supporting experimental details, ablations, error bars, baseline comparisons, or method implementation specifics; the central performance assertion cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of new state-of-the-art R@1 scores is presented without any supporting experimental details, ablations, error bars, baseline comparisons, or method implementation specifics; the central performance assertion cannot be evaluated.
Authors: We agree that the abstract is a concise summary and therefore omits the full experimental details, ablations, error bars, baseline tables, and implementation specifics; this is standard for abstracts due to space limits. The central performance claims are supported in the full manuscript: Section 4 details the evaluation protocol on MSRVTT, MSVD, and LSMDC (including standard splits, metrics, and baselines), Section 4.3 and the appendix provide ablations on the dual-objective language modeling and cascaded group attention, and implementation details appear in Section 3.4 and the supplementary material. The assertion can therefore be evaluated from the complete paper. If desired, we can add one sentence to the abstract referencing the three benchmarks and the fact that results are reported under standard protocols. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical multimodal architecture (hybrid language modeling + hierarchical vision encoder) and reports benchmark R@1 scores without any equations, derivations, or first-principles claims. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or model description. The central claims rest on standard cross-modal retrieval evaluation rather than any internal chain that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video understanding with large language models: A survey,
Y . Tang, J. Bi, S. Xu, L. Song, S. Liang, T. Wang, D. Zhang, J. An, J. Lin, R. Zhuet al., “Video understanding with large language models: A survey,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[2]
Mvp-shot: Multi-velocity progressive-alignment framework for few-shot action recognition,
H. Qu, R. Yan, X. Shu, H. Gao, P. Huang, and G.-S. Xie, “Mvp-shot: Multi-velocity progressive-alignment framework for few-shot action recognition,”IEEE Transactions on Multimedia, 2025
2025
-
[3]
Multi-modal reference learning for fine-grained text-to-image retrieval,
Z. Ma, H. Chen, W. Zeng, L. Su, and S. Zhang, “Multi-modal reference learning for fine-grained text-to-image retrieval,”IEEE Transactions on Multimedia, 2025
2025
-
[4]
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning,
H. Luo, L. Ji, M. Zhong, Y . Chen, W. Lei, N. Duan, and T. Li, “Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning,”Neurocomputing, vol. 508, pp. 293–304, 2022
2022
-
[5]
Mv-adapter: Multimodal video transfer learning for video text retrieval,
X. Jin, B. Zhang, W. Gong, K. Xu, X. Deng, P. Wang, Z. Zhang, X. Shen, and J. Feng, “Mv-adapter: Multimodal video transfer learning for video text retrieval,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 144–27 153
2024
-
[6]
Vilt-clip: Video and language tuning clip with multimodal prompt learning and scenario-guided optimization,
H. Wang, F. Liu, L. Jiao, J. Wang, Z. Hao, S. Li, L. Li, P. Chen, and X. Liu, “Vilt-clip: Video and language tuning clip with multimodal prompt learning and scenario-guided optimization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5390–5400
2024
-
[7]
Muse: Mamba is efficient multi-scale learner for text-video retrieval,
H. Tang, M. Cao, J. Huang, R. Liu, P. Jin, G. Li, and X. Liang, “Muse: Mamba is efficient multi-scale learner for text-video retrieval,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7238–7246
2025
-
[8]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
2022
-
[9]
Bridgetower: Building bridges between encoders in vision-language representation learning,
X. Xu, C. Wu, S. Rosenman, V . Lal, W. Che, and N. Duan, “Bridgetower: Building bridges between encoders in vision-language representation learning,” inProceedings of the AAAI Conference on Artificial Intel- ligence, vol. 37, no. 9, 2023, pp. 10 637–10 647
2023
-
[10]
Long-clip: Unlocking the long-text capability of clip,
B. Zhang, P. Zhang, X. Dong, Y . Zang, and J. Wang, “Long-clip: Unlocking the long-text capability of clip,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 310–325
2024
-
[11]
Teachtext: Crossmodal generalized distillation for text-video retrieval,
I. Croitoru, S.-V . Bogolin, M. Leordeanu, H. Jin, A. Zisserman, S. Al- banie, and Y . Liu, “Teachtext: Crossmodal generalized distillation for text-video retrieval,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 11 583–11 593
2021
-
[12]
Multi modal semantic indexing for image retrieval,
P. Chandrika and C. Jawahar, “Multi modal semantic indexing for image retrieval,” inProceedings of the ACM International Conference on Image and Video Retrieval, 2010, pp. 342–349
2010
-
[13]
Towards improving canonical correlation analysis for cross-modal retrieval,
J. Shao, Z. Zhao, F. Su, and T. Yue, “Towards improving canonical correlation analysis for cross-modal retrieval,” inProceedings of the on Thematic Workshops of ACM Multimedia 2017, 2017, pp. 332–339
2017
-
[14]
Cross-modality retrieval by joint correlation learning,
S. Wang, D. Guo, X. Xu, L. Zhuo, and M. Wang, “Cross-modality retrieval by joint correlation learning,”ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol. 15, no. 2s, pp. 1–16, 2019
2019
-
[15]
Deep visual-semantic alignments for generating image descriptions,
A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3128–3137
2015
-
[16]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[17]
Two-stream convolutional networks for action recognition in videos,
K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,”Advances in neural information processing systems, vol. 27, 2014
2014
-
[18]
Learning spatiotemporal features with 3d convolutional networks,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 4489–4497
2015
-
[19]
Is space-time attention all you need for video understanding?
G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” inICML, vol. 2, no. 3, 2021, p. 4
2021
-
[20]
Ump: Unified modality-aware prompt tuning for text-video retrieval,
H. Zhang, P. Zeng, L. Gao, J. Song, and H. T. Shen, “Ump: Unified modality-aware prompt tuning for text-video retrieval,”IEEE Transac- tions on Circuits and Systems for Video Technology, 2024
2024
-
[21]
Enhancing text-video retrieval performance with low-salient but discriminative objects,
Y . Zheng, B. Huang, Z. Chen, and D. Yu, “Enhancing text-video retrieval performance with low-salient but discriminative objects,”IEEE Transactions on Image Processing, 2025
2025
-
[22]
Xlnet: Generalized autoregressive pretraining for language understanding,
Z. Yang, Z. Dai, Y . Yang, J. Carbonell, R. R. Salakhutdinov, and Q. V . Le, “Xlnet: Generalized autoregressive pretraining for language understanding,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[23]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, “Pytorch: An imperative style, high-performance deep learn- ing library,”arXiv preprint arXiv:1912.01703, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[24]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[25]
Msr-vtt: A large video description dataset for bridging video and language,
J. Xu, T. Mei, T. Yao, and Y . Rui, “Msr-vtt: A large video description dataset for bridging video and language,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5288– 5296
2016
-
[26]
Collecting highly parallel data for paraphrase evaluation,
D. Chen and W. B. Dolan, “Collecting highly parallel data for paraphrase evaluation,” inProceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, 2011, pp. 190–200
2011
-
[27]
The long-short story of movie description,
A. Rohrbach, M. Rohrbach, and B. Schiele, “The long-short story of movie description,” inGerman conference on pattern recognition. Springer, 2015, pp. 209–221
2015
-
[28]
A joint sequence fusion model for video question answering and retrieval,
Y . Yu, J. Kim, and G. Kim, “A joint sequence fusion model for video question answering and retrieval,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 471–487
2018
-
[29]
End-to-end concept word detection for video captioning, retrieval, and question answering,
Y . Yu, H. Ko, J. Choi, and G. Kim, “End-to-end concept word detection for video captioning, retrieval, and question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3165–3173
2017
-
[30]
A joint sequence fusion model for video question answering and retrieval,
Y . Yu, J. Kim, and G. Kim, “A joint sequence fusion model for video question answering and retrieval,” inProceedings of the European Conference on Computer Vision (ECCV), September 2018
2018
-
[31]
Use what you have: Video retrieval using representations from collaborative experts,
Y . Liu, S. Albanie, A. Nagrani, and A. Zisserman, “Use what you have: Video retrieval using representations from collaborative experts,”arXiv preprint arXiv:1907.13487, 2019
-
[32]
Multi-modal transformer for video retrieval,
V . Gabeur, C. Sun, K. Alahari, and C. Schmid, “Multi-modal transformer for video retrieval,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 214–229
2020
-
[33]
Teachtext: Crossmodal generalized distillation for text-video retrieval,
I. Croitoru, S.-V . Bogolin, M. Leordeanu, H. Jin, A. Zisserman, S. Al- banie, and Y . Liu, “Teachtext: Crossmodal generalized distillation for text-video retrieval,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021, pp. 11 583– 11 593
2021
-
[34]
Text-video retrieval method based on enhanced self-attention and multi-task learning,
X. Wu, J. Qian, and T. Wang, “Text-video retrieval method based on enhanced self-attention and multi-task learning,”Multimedia Tools and Applications, vol. 82, no. 16, pp. 24 387–24 406, 2023
2023
-
[35]
Complementarity- aware space learning for video-text retrieval,
J. Zhu, P. Zeng, L. Gao, G. Li, D. Liao, and J. Song, “Complementarity- aware space learning for video-text retrieval,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 8, pp. 4362– 4374, 2023. 14
2023
-
[36]
Align and tell: Boosting text-video retrieval with local alignment and fine-grained supervision,
X. Wang, L. Zhu, Z. Zheng, M. Xu, and Y . Yang, “Align and tell: Boosting text-video retrieval with local alignment and fine-grained supervision,”IEEE Transactions on Multimedia, vol. 25, pp. 6079–6089, 2022
2022
-
[37]
Text-guided distillation learning to di- versify video embeddings for text-video retrieval,
S. Lee, H.-I. Kim, and Y . M. Ro, “Text-guided distillation learning to di- versify video embeddings for text-video retrieval,”Pattern Recognition, vol. 156, p. 110754, 2024
2024
-
[38]
Cross-modal adapter for vision–language retrieval,
H. Jiang, J. Zhang, R. Huang, C. Ge, Z. Ni, S. Song, and G. Huang, “Cross-modal adapter for vision–language retrieval,”Pattern Recogni- tion, vol. 159, p. 111144, 2025
2025
-
[39]
Htvr: Hierarchical text- to-video retrieval based on relative similarity,
D. Zhang, Z. Wang, Z. Hu, and X.-J. Wu, “Htvr: Hierarchical text- to-video retrieval based on relative similarity,”Pattern Recognition, p. 112145, 2025
2025
-
[40]
Videoaligner: Text-driven feature decomposition for precise video-text alignment,
Z. Feng, S. Mao, Y . Wang, and S. Zhang, “Videoaligner: Text-driven feature decomposition for precise video-text alignment,”Pattern Recog- nition, p. 113971, 2026
2026
-
[41]
VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
F. Faghri, D. J. Fleet, J. R. Kiros, and S. Fidler, “Vse++: Improv- ing visual-semantic embeddings with hard negatives,”arXiv preprint arXiv:1707.05612, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Learning joint embedding with multimodal cues for cross-modal video-text re- trieval,
N. C. Mithun, J. Li, F. Metze, and A. K. Roy-Chowdhury, “Learning joint embedding with multimodal cues for cross-modal video-text re- trieval,” inProceedings of the 2018 ACM on international conference on multimedia retrieval, 2018, pp. 19–27
2018
-
[43]
Cross modal retrieval with querybank normalisation,
S.-V . Bogolin, I. Croitoru, H. Jin, Y . Liu, and S. Albanie, “Cross modal retrieval with querybank normalisation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5194–5205
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.