StateFlow: Dual-State Recurrent Modeling for Long-Horizon Time Series Forecasting
Pith reviewed 2026-07-02 19:33 UTC · model grok-4.3
The pith
StateFlow extends VARNN with dual hidden-state and residual-memory trajectories for direct multi-step long-horizon forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
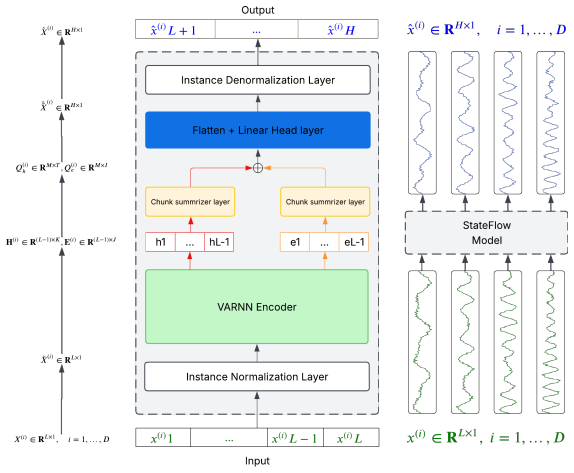
StateFlow employs VARNN as a dual-state recurrent backbone that extracts a hidden-state trajectory capturing primary temporal dynamics and a residual-memory trajectory capturing structured local prediction deviations; a chunk-based decoder maps these trajectories to direct multi-step forecasts after a two-stage optimization that first trains the encoder on one-step base predictions.
What carries the argument
Dual-state recurrent backbone that tracks a hidden-state trajectory for primary dynamics alongside a residual-memory trajectory driven by one-step prediction errors, summarized by a chunk-based decoder for multi-step output.
If this is right
- Direct multi-step forecasting becomes possible without iterative rollout that compounds errors over long horizons.
- The model retains linear recurrent encoding and a compact parameter count while matching stronger baselines.
- Non-stationarity and regime shifts are addressed through explicit tracking of residual deviations.
- Two-stage training separates representation learning from horizon-specific mapping.
Where Pith is reading between the lines
- The separation of primary dynamics from residual deviations could be added to other recurrent forecasters to improve long-term stability.
- The two-stage schedule may transfer to any model currently limited to short-horizon regression.
- Explicit residual tracking might yield more interpretable error diagnostics in operational forecasting systems.
- The approach suggests testing on streaming data where new observations continuously update the residual state.
Load-bearing premise
The chunk-based decoder can map the two trajectories into accurate direct multi-step forecasts without inheriting VARNN's original restriction to one-step regression.
What would settle it
An ablation experiment on standard LTSF benchmarks in which removing the residual-memory trajectory produces no measurable drop in forecast accuracy would falsify the contribution of the dual-state design.
Figures
read the original abstract
Long-horizon multivariate time series forecasting (LTSF) remains challenging due to non-stationarity, regime shifts, and error accumulation. The Variability-Aware Recursive Neural Network (VARNN) is designed to track such variability by maintaining a residual-memory state driven by one-step prediction errors. However, its original formulation is limited to one-step sequence regression and does not directly support multi-step forecasting. In this work, we extend VARNN to long-horizon forecasting and introduce StateFlow, a recurrent forecasting framework that uses VARNN as a dual-state recurrent backbone to capture two complementary signals from the lookback sequence: a hidden-state trajectory representing primary temporal dynamics, including trend, seasonality, level changes, and recurring patterns, and a residual-memory trajectory representing structured local prediction deviations, driven from a nonlinear recurrent transformation of errors between one-step base predictions and observed values. A chunk-based decoder separately summarizes these trajectories and maps them to the future horizon for direct multi-step forecasting. We further employ a two-stage optimization strategy that first trains the VARNN encoder through a one-step base prediction objective to optimize the internal representations over the lookback sequence, and then trains a horizon-specific decoder for direct multi-step forecasting. Experiments on standard LTSF benchmarks show that StateFlow achieves competitive performance against strong linear, recurrent, convolutional, and Transformer-based baselines while preserving linear recurrent encoding and a compact model design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StateFlow as an extension of VARNN for long-horizon multivariate time series forecasting. It employs a dual-state recurrent backbone that produces a hidden-state trajectory (capturing primary dynamics such as trend and seasonality) and a residual-memory trajectory (driven by one-step prediction errors), then uses a chunk-based decoder to map both trajectories to direct multi-step horizon outputs. Training follows a two-stage procedure that first optimizes the VARNN encoder on one-step regression before fitting a horizon-specific decoder. Experiments on standard LTSF benchmarks report competitive results against linear, recurrent, convolutional, and Transformer baselines while retaining linear recurrent encoding and a compact model.
Significance. If the central mechanism holds, the work supplies a compact recurrent route to LTSF that explicitly tracks structured residuals without attention, which could be useful for non-stationary series where error accumulation is an issue. The two-stage separation of encoder and decoder objectives is a clear design choice that preserves the original VARNN one-step training while adding multi-step capability.
major comments (2)
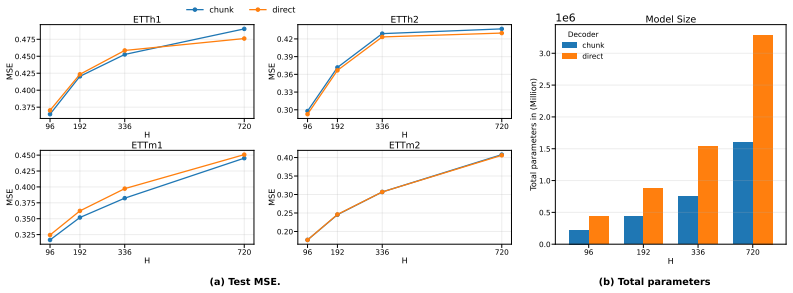
- [§3] §3 (method, chunk-based decoder paragraph): the claim that the decoder supplies reliable direct multi-step forecasts rests on the assertion that chunk summarization of the two trajectories corrects for long-range error accumulation. Because the encoder remains fixed to its one-step objective, the manuscript must show (via ablation or derivation) that the residual-memory trajectory plus chunk aggregation actually supplies the missing horizon-length correction rather than inheriting the original VARNN one-step bias.
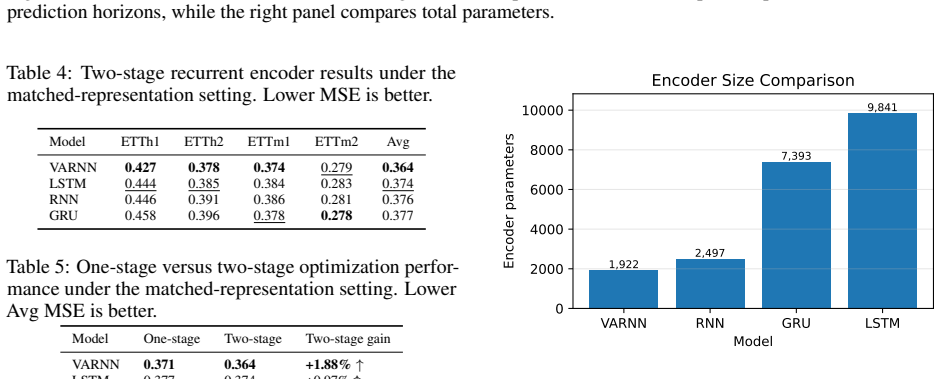
- [§4] §4 (experiments): the reported competitive performance is the load-bearing empirical claim, yet the manuscript supplies no error bars, no ablation isolating the contribution of the residual-memory trajectory versus the hidden-state trajectory alone, and no explicit statement of the train/validation/test split rules or normalization protocol used on the LTSF benchmarks. These omissions make it impossible to judge whether the gains are robust or dataset-specific.
minor comments (2)
- [Abstract] Abstract: the phrase 'preserving linear recurrent encoding' is used without a forward reference to the precise linearity property retained from VARNN; a one-sentence clarification would help readers.
- [§3] Notation: the distinction between the 'hidden-state trajectory' and the 'residual-memory trajectory' is introduced in the abstract but would benefit from an explicit equation or diagram label in the method section for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (method, chunk-based decoder paragraph): the claim that the decoder supplies reliable direct multi-step forecasts rests on the assertion that chunk summarization of the two trajectories corrects for long-range error accumulation. Because the encoder remains fixed to its one-step objective, the manuscript must show (via ablation or derivation) that the residual-memory trajectory plus chunk aggregation actually supplies the missing horizon-length correction rather than inheriting the original VARNN one-step bias.
Authors: We agree that the current manuscript would be strengthened by explicit evidence on this point. In the revision we will add an ablation that isolates the residual-memory trajectory (comparing the full dual-state model against a hidden-state-only variant) together with a concise derivation showing how the residual-memory state encodes structured one-step deviations that, when chunk-aggregated, supply horizon-specific corrections beyond the fixed one-step encoder objective. revision: yes
-
Referee: [§4] §4 (experiments): the reported competitive performance is the load-bearing empirical claim, yet the manuscript supplies no error bars, no ablation isolating the contribution of the residual-memory trajectory versus the hidden-state trajectory alone, and no explicit statement of the train/validation/test split rules or normalization protocol used on the LTSF benchmarks. These omissions make it impossible to judge whether the gains are robust or dataset-specific.
Authors: We acknowledge these omissions. The revised version will report error bars over multiple random seeds, include the ablation isolating the residual-memory trajectory, and provide explicit statements of the train/validation/test splits and normalization protocol (following the standard LTSF benchmark conventions used in prior literature). revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents StateFlow as an architectural extension of VARNN via dual-state trajectories (hidden-state and residual-memory) plus a separately trained chunk-based decoder under two-stage optimization. The encoder is optimized on one-step regression while the decoder is trained on the direct multi-step objective; performance is reported via external benchmark comparisons rather than any definitional equivalence or fitted-input renaming. No equations reduce the long-horizon output to the one-step inputs by construction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The derivation chain remains self-contained against the stated empirical results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.3390/app14114436. Kostas Benidis, Syama S. Rangapuram, Valentin Flunkert, Yuyang Wang, et al. Deep learning for time series forecasting: A tutorial and literature survey.ACM Computing Surveys,
-
[2]
URL https://arxiv.org/abs/2004.10240
doi: 10.1145/3533382. URL https://arxiv.org/abs/2004.10240. George E. P. Box, Gwilym M. Jenkins, Gregory C. Reinsel, and Greta M. Ljung.Time Series Analysis: Forecasting and Control. Wiley, 5 edition,
-
[3]
Kyunghyun Cho, Bart van Merri¨enboer, Dzmitry Bahdanau, and Yoshua Bengio
doi: 10.1007/b97391. Kyunghyun Cho, Bart van Merri¨enboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder–decoder approaches. InProceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, pp. 103–111, Doha, Qatar,
-
[4]
doi: 10.1016/j.ijforecast.2006.01.001. Jeffrey L. Elman. Finding structure in time.Cognitive Science, 14(2):179–211,
-
[5]
doi: 10.1207/s15516709cog1402
-
[7]
Sepp Hochreiter and J¨urgen Schmidhuber
URL https://arxiv.org/abs/2510.08944. Sepp Hochreiter and J¨urgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780,
-
[8]
doi: 10.1162/neco.1997.9.8.1735. Rob J. Hyndman and George Athanasopoulos.Forecasting: Principles and Practice. OTexts, Melbourne, Australia, 3 edition,
-
[9]
Accessed 2025-09-11
URLhttps://otexts.com/fpp3/. Accessed 2025-09-11. Taesuk Kim, Jihwan Kim, Ilsang Ohn, and Se-Young Kim. Reversible instance normalization for accurate time-series forecasting against distribution shift. InAdvances in Neural Information Processing Systems (NeurIPS),
2025
-
[10]
Zhe Li, Shiyi Qi, Yiduo Li, and Zenglin Xu
arXiv:2103.16900. Zhe Li, Shiyi Qi, Yiduo Li, and Zenglin Xu. Revisiting long-term time series forecasting: An investigation on linear mapping.arXiv preprint arXiv:2305.10721,
-
[11]
Revisiting Long-term Time Series Forecasting: An Investigation on Linear Mapping
URLhttps://arxiv.org/abs/2305.10721. Bryan Lim and Stefan Zohren. Time-series forecasting with deep learning: A survey.Philosophical Transactions of the Royal Society A, 379(2194):20200209,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
doi: 10.1098/rsta.2020.0209. Bryan Lim, Sercan O. Arik, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi- horizon time series forecasting.arXiv preprint arXiv:1912.09363,
-
[13]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long
URL https://arxiv.org/abs/ 1912.09363. Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. iTransformer: Inverted transformers are effective for time series forecasting. InInternational Conference on Learning Representations,
-
[15]
Instance Normalization: The Missing Ingredient for Fast Stylization
URLhttps://arxiv.org/abs/1607.08022. 11Preprint. © 2026 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
URLhttps://doi.org/10.1609/aaai.v37i9.26317
doi: 10.1609/ aaai.v37i9.26317. URLhttps://doi.org/10.1609/aaai.v37i9.26317. Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 11106–11115,
-
[17]
12Preprint. © 2026 A MORE RESULTS ON ABLATION STUDY A.1 FULLDUAL-STATEFUSIONSTRATEGYRESULTS Table 6 reports the full dataset-horizon comparison between separate and joint dual-state fusion under the chunk decoder. The separate variant applies independent chunk summarizers to h and e before concatenation, while the joint variant concatenates [h, e] before ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.