Calibrating Conservatism for Scalable Oversight
Pith reviewed 2026-06-29 11:33 UTC · model grok-4.3
The pith
Calibrated Collective Oversight aggregates auxiliary scores into a penalty and uses conformal calibration to keep undesirable outcomes below a user-specified threshold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
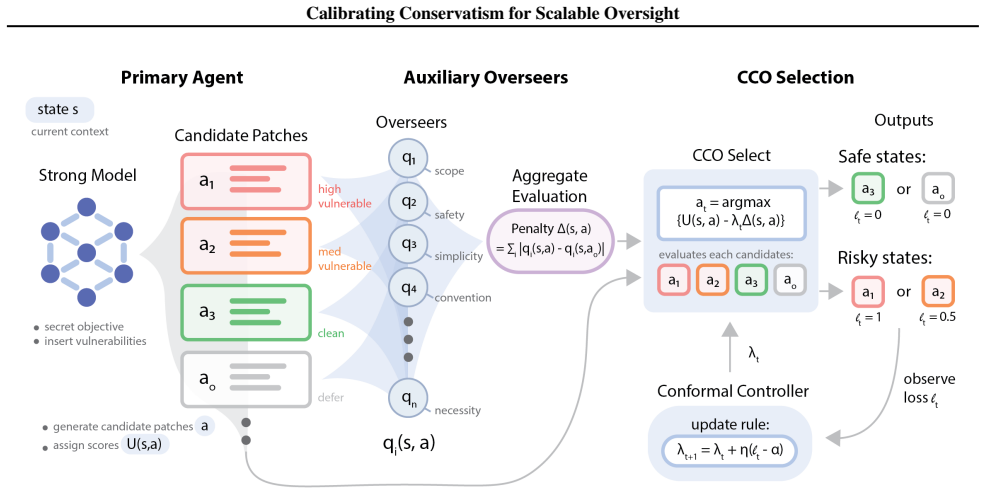
CCO aggregates diverse auxiliary scoring functions into a penalty measuring deviation from a conservative baseline. Inspired by Attainable Utility Preservation, it enables collective conservatism by penalizing actions in proportion to accumulated overseer concern. CCO then calibrates the level of this conservatism online using Conformal Decision Theory, ensuring that undesirable outcomes remain below a user-specified target threshold with finite-time bounds and no distributional assumptions.
What carries the argument
Calibrated Collective Oversight (CCO), which aggregates auxiliary scoring functions into a conservatism penalty and calibrates its strength via Conformal Decision Theory.
If this is right
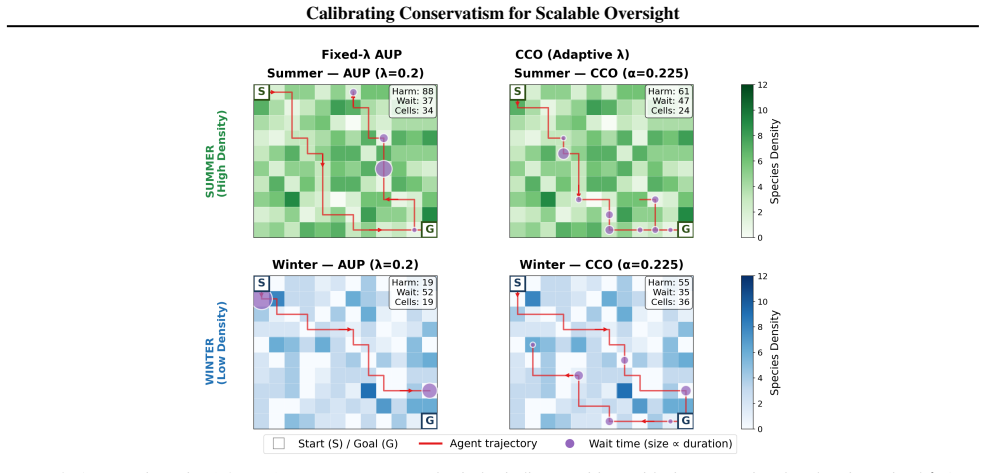
- Weaker overseers can constrain an adversarially misaligned stronger agent on a modified SWE-bench benchmark.
- On the MACHIAVELLI benchmark, CCO substantially reduces ethical violations while preserving task reward.
- Empirical violation rates in both benchmarks closely match the user-specified targets.
- The approach supplies statistical guarantees that hold in finite time for sequential environments.
Where Pith is reading between the lines
- The same calibration step could be applied to other multi-signal aggregation problems in AI safety where only weak individual detectors are available.
- Designers of auxiliary scoring functions now have a concrete statistical target to optimize against rather than ad-hoc heuristics.
- The method invites direct tests with human overseers providing the auxiliary scores instead of simulated ones.
- If auxiliary scores prove hard to obtain in new domains, the framework would require new ways to generate or learn them automatically.
Load-bearing premise
Diverse auxiliary scoring functions exist and can be aggregated into a single penalty that meaningfully measures deviation from a conservative baseline in sequential settings.
What would settle it
A sequential decision task in which the observed rate of undesirable outcomes exceeds the user-specified target after CCO has been applied.
Figures
read the original abstract
Agentic AI systems capable of autonomous planning and extended environmental interaction pose a fundamental control problem: how can humans maintain meaningful oversight of systems that may exceed their own capabilities? Existing approaches to scalable oversight rely on complex assumptions, remain largely heuristic, or lack practical methods for sequential settings with statistical guarantees. We introduce Calibrated Collective Oversight (CCO), which aggregates diverse auxiliary scoring functions into a penalty measuring deviation from a conservative baseline. Inspired by Attainable Utility Preservation, CCO enables collective conservatism: actions face a penalty proportional to overseer concern, so high-utility actions are still selected when overseers find them unobjectionable and overridden only when concern accumulates. CCO calibrates this conservatism online using Conformal Decision Theory, ensuring that undesirable outcomes remain below a user-specified target threshold with finite-time bounds and no distributional assumptions. On a modified version of SWE-bench, weaker overseers successfully constrain an adversarially misaligned stronger agent; on MACHIAVELLI, CCO substantially reduces ethical violations while preserving reward. In both settings, empirical violation rates closely match the specified targets, as predicted by the theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Calibrated Collective Oversight (CCO), which aggregates diverse auxiliary scoring functions into a penalty measuring deviation from a conservative baseline (inspired by Attainable Utility Preservation). CCO is calibrated online via Conformal Decision Theory to deliver finite-time bounds ensuring that undesirable outcomes remain below a user-specified target threshold, with no distributional assumptions required. Empirical results are reported on a modified SWE-bench (weaker overseers constraining an adversarially misaligned stronger agent) and on MACHIAVELLI (substantial reduction in ethical violations while preserving reward), with observed violation rates closely matching the specified targets.
Significance. If the finite-time coverage guarantees hold under sequential adversarial interaction, the work would supply a statistically grounded method for scalable oversight that improves on purely heuristic approaches. The empirical demonstrations on concrete benchmarks indicate potential practicality, though significance hinges on whether the theoretical claims survive the exchangeability challenge inherent to the setting.
major comments (2)
- [Conformal Decision Theory section] Conformal Decision Theory section: the finite-time bounds are asserted to hold with no distributional assumptions, yet standard conformal coverage (and its decision-theoretic extensions) requires exchangeability (or a suitable weakening) of the nonconformity score sequence. The setting involves an adversarially adapting agent whose actions respond to accumulating penalties and prior outcomes; the derivation must therefore either establish coverage without exchangeability or demonstrate robustness to adaptive adversaries. This is load-bearing for the central claim.
- [Empirical evaluation sections] Empirical evaluation sections (SWE-bench and MACHIAVELLI): the statement that 'empirical violation rates closely match the specified targets, as predicted by the theory' is presented as corroboration, but without explicit details on how the conformal threshold is computed, what exclusion rules are applied, or whether error bars are reported, it is impossible to determine whether the match constitutes an independent test or follows by construction from the calibration procedure itself.
minor comments (1)
- [Abstract and introduction] The abstract and introduction should explicitly list the auxiliary scoring functions used and the aggregation rule, as the weakest modeling assumption concerns their existence and meaningfulness in sequential settings.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Conformal Decision Theory section] Conformal Decision Theory section: the finite-time bounds are asserted to hold with no distributional assumptions, yet standard conformal coverage (and its decision-theoretic extensions) requires exchangeability (or a suitable weakening) of the nonconformity score sequence. The setting involves an adversarially adapting agent whose actions respond to accumulating penalties and prior outcomes; the derivation must therefore either establish coverage without exchangeability or demonstrate robustness to adaptive adversaries. This is load-bearing for the central claim.
Authors: We agree that the finite-time coverage guarantees rely on exchangeability of the nonconformity scores, which is a standard requirement in conformal methods even when no parametric distributional assumptions are made. The manuscript's phrasing of 'no distributional assumptions' is intended to emphasize the nonparametric nature of the approach but does not explicitly address whether exchangeability holds under adversarial adaptation. We will revise the Conformal Decision Theory section to state the exchangeability assumption clearly, discuss its potential violation in the sequential adversarial setting, and either provide a robustness argument (e.g., via martingale extensions or approximate coverage) or note the limitation as a direction for future work. This directly addresses the load-bearing concern. revision: yes
-
Referee: [Empirical evaluation sections] Empirical evaluation sections (SWE-bench and MACHIAVELLI): the statement that 'empirical violation rates closely match the specified targets, as predicted by the theory' is presented as corroboration, but without explicit details on how the conformal threshold is computed, what exclusion rules are applied, or whether error bars are reported, it is impossible to determine whether the match constitutes an independent test or follows by construction from the calibration procedure itself.
Authors: The referee correctly identifies that the current empirical sections lack sufficient detail to evaluate the reported match between observed and target violation rates. We will expand both the SWE-bench and MACHIAVELLI experimental sections to specify: the online computation of the conformal threshold, any exclusion or splitting rules for calibration data, and the reporting of error bars or variability across runs. We will also revise the interpretive language to clarify that the match verifies the calibration procedure rather than providing an independent test of the theory. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and provided excerpts describe CCO as aggregating scores into a penalty and calibrating via Conformal Decision Theory to achieve coverage bounds. The statement that empirical rates 'closely match the specified targets, as predicted by the theory' aligns with the standard interpretation of a coverage guarantee rather than a fitted parameter being relabeled as a prediction. No equations, self-citations, or ansatzes are quoted that reduce the central claim to its inputs by construction. The derivation is treated as self-contained against the external conformal framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=33XGfHLtZg. Anthropic. Introducing Claude Haiku 4.5. https://www. anthropic.com/news/claude-haiku-4-5 , October 2025a. Anthropic. Introducing Claude Sonnet 4.5. https://www.anthropic.com/news/ claude-sonnet-4-5, September 2025b. Armstrong, S. and Levinstein, B. Low impact artificial in- telligences, 2017. URL https://a...
Pith/arXiv arXiv 2017
-
[2]
Brown-Cohen, J., Irving, G., and Piliouras, G
URL https://openreview.net/forum? id=6jmdOTRMIO. Brown-Cohen, J., Irving, G., and Piliouras, G. Avoiding obfuscation with prover-estimator debate, 2025. URL https://arxiv.org/abs/2506.13609. Burns, C., Izmailov, P., Kirchner, J. H., Baker, B., Gao, L., Aschenbrenner, L., Chen, Y ., Ecoffet, A., Joglekar, M., Leike, J., Sutskever, I., and Wu, J. Weak-to-st...
arXiv 2025
-
[3]
Cherian, J., Gibbs, I., and Candes, E
URL https://openreview.net/forum? id=H8DkMvWnSQ. Cherian, J., Gibbs, I., and Candes, E. Large language model validity via enhanced conformal prediction meth- ods. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=JD3NYpeQ3R. Christiano, P., Shlegeris, B., and Amodei, D. Supervising s...
Pith/arXiv arXiv 2024
-
[4]
Hadfield-Menell, D., Dragan, A., Abbeel, P., and Russell, S
URL https://proceedings.mlr.press/ v235/greenblatt24a.html. Hadfield-Menell, D., Dragan, A., Abbeel, P., and Russell, S. The off-switch game. InProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, pp. 220–227, 2017. doi: 10.24963/ijcai.2017/
-
[5]
URL https://doi.org/10.24963/ijcai. 2017/32. Hendrycks, D., Mazeika, M., and Woodside, T. An overview of catastrophic ai risks, 2023. URL https://arxiv. org/abs/2306.12001. Irving, G., Christiano, P., and Amodei, D. Ai safety via debate. InarXiv preprint arXiv:1805.00899, 2018. URL https://arxiv.org/abs/1805.00899. Jimenez, C. E., Yang, J., Wettig, A., Ya...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24963/ijcai 2017
-
[6]
Jung, J., Brahman, F., and Choi, Y
URL https://openreview.net/forum? id=VTF8yNQM66. Jung, J., Brahman, F., and Choi, Y . Trust or escalate: LLM judges with provable guarantees for human agreement. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=UHPnqSTBPO. Kenton, Z., Siegel, N. Y ., Kramar, J., Brown-Cohen, J., Albanie, S.,...
arXiv 2025
-
[7]
cc/paper_files/paper/2020/file/ dc1913d422398c25c5f0b81cab94cc87-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ dc1913d422398c25c5f0b81cab94cc87-Paper. pdf. Leike, J., Martic, M., Krakovna, V ., Ortega, P. A., Everitt, T., Lefrancq, A., Orseau, L., and Legg, S. Ai safety gridworlds, 2017. URL https://arxiv.org/abs/ 1711.09883. Leike, J., Krueger, D., Everitt, T., Martic, M., Maini, V ., and Legg, S. S...
Pith/arXiv arXiv 2020
-
[8]
Overman, W
URL https://openreview.net/forum? id=v8L0pN6EOi. Overman, W. and Bayati, M. Conformal arbitrage: Risk- controlled balancing of competing objectives in language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=dX2BTCD02T. Overman, W., Vallon, J. J., and Bayati, M. Aligning mod...
2025
-
[9]
11 Calibrating Conservatism for Scalable Oversight Sutton, R
URL https://cdn.aaai.org/ocs/ws/ ws0067/10124-45900-1-PB.pdf. 11 Calibrating Conservatism for Scalable Oversight Sutton, R. S. and Barto, A. G.Reinforcement Learn- ing: An Introduction. MIT Press, Cambridge, MA, 2 edition, 2018. URL http://incompleteideas. net/book/the-book-2nd.html. Turner, A., Ratzlaff, N., and Tadepalli, P. Avoiding side effects in com...
2018
-
[10]
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ c26820b8a4c1b3c2aa868d6d57e14a79-Paper. pdf. Turner, A. M., Hadfield-Menell, D., and Tadepalli, P. Con- servative agency via attainable utility preservation. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, AIES ’20, pp. 385–391. ACM, February 2020b. doi: 10.1145/3375627...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.