Semiparametric Efficient Bilevel Gradient Estimation
Pith reviewed 2026-05-21 03:36 UTC · model grok-4.3
The pith
A semiparametric estimator removes first-order bias from plug-in hypergradients in bilevel optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
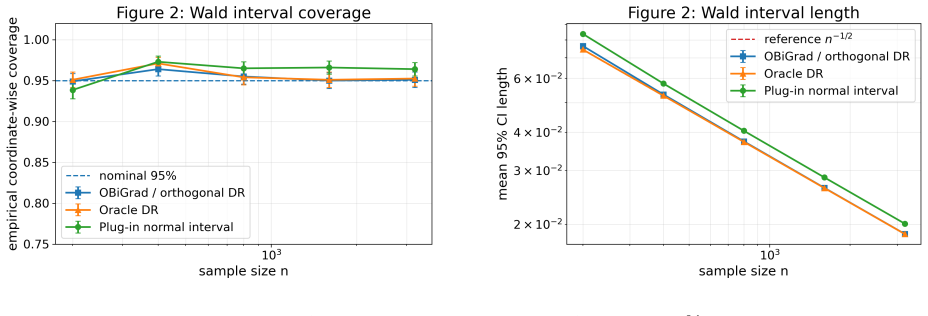
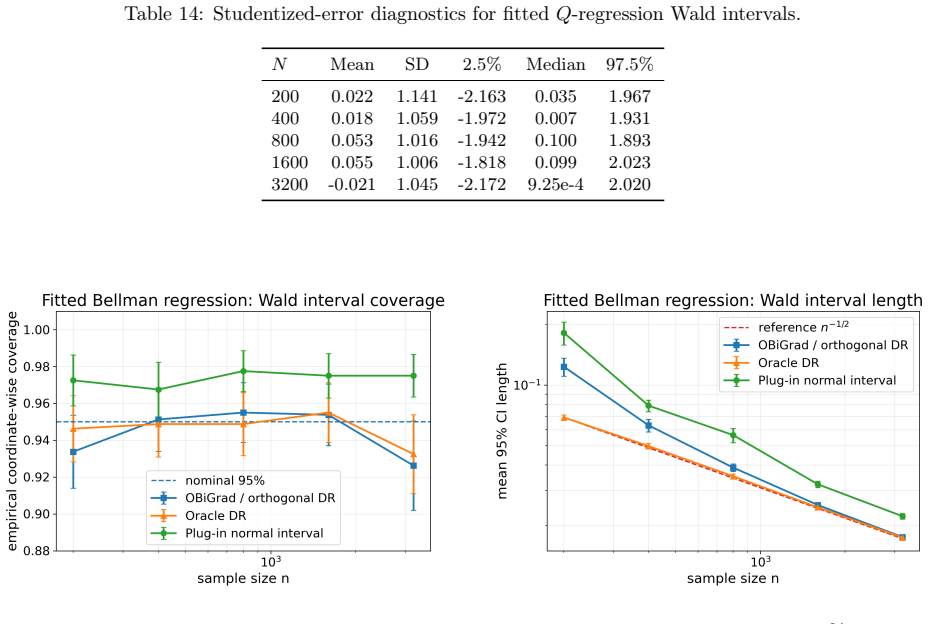
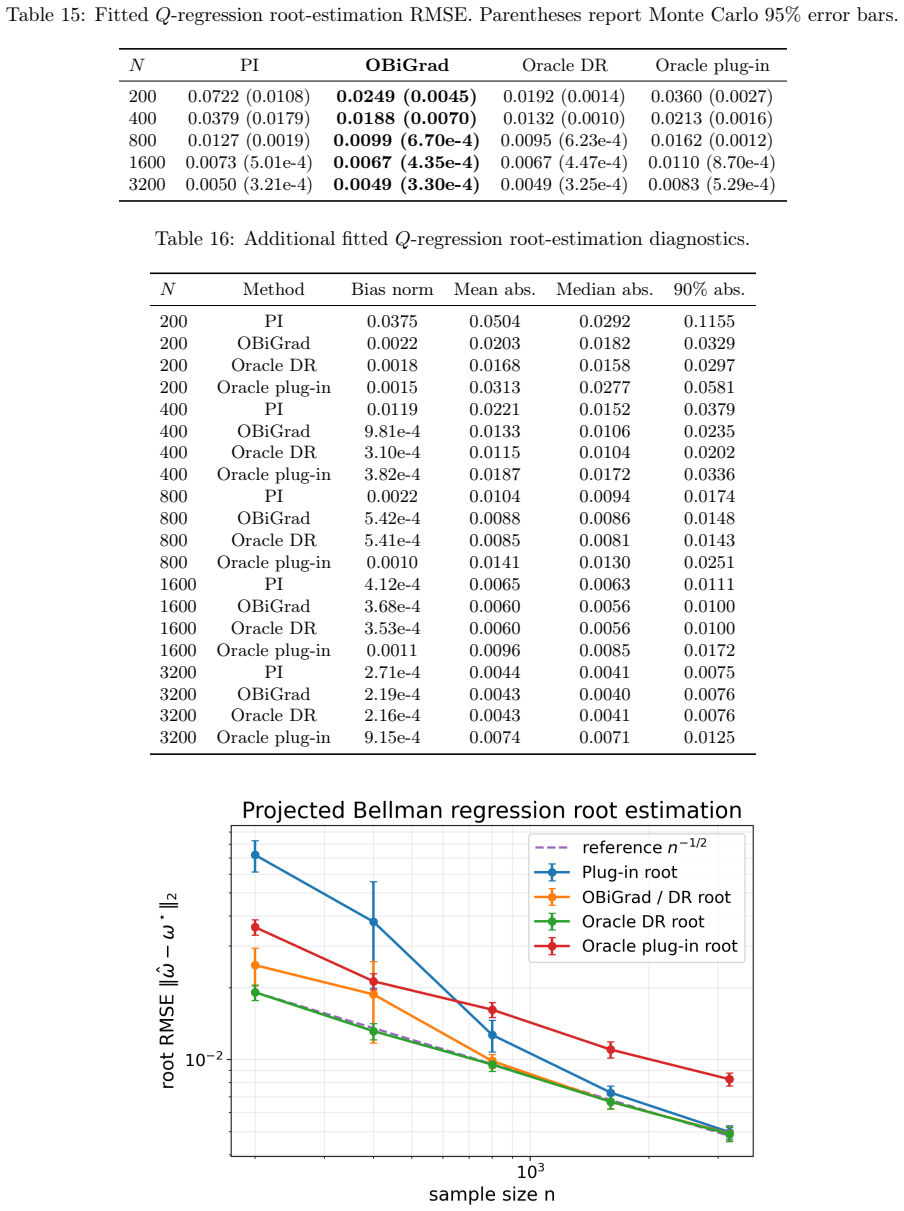
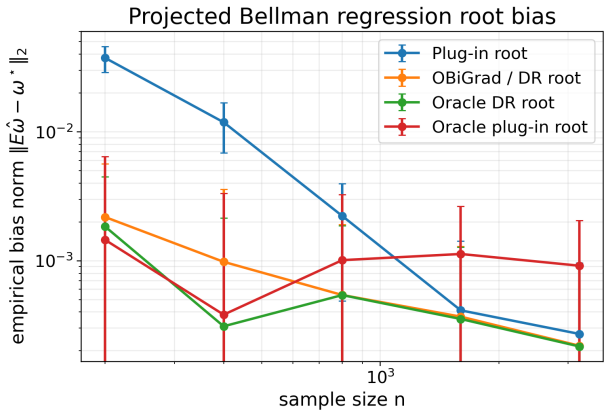
The paper claims that by basing the debiasing on the efficient influence function for population bilevel gradients, one obtains a cross-fitted orthogonal hypergradient estimator that is asymptotically normal with uniform control over the outer parameter. For quadratic losses, this reduces to a simple doubly robust score based on conditional mean nuisances, and on synthetic benchmarks it tracks the oracle while improving over plug-in and regularized baselines.
What carries the argument
The efficient influence function for the bilevel gradient, which enables construction of an orthogonal score that removes first-order bias from nonparametric estimation of the lower level.
If this is right
- The cross-fitted estimator achieves asymptotic normality together with uniform control over the outer parameter.
- Under quadratic losses, the estimator reduces to a doubly robust score based on conditional mean nuisances.
- On synthetic bilevel benchmarks, the method tracks the oracle efficient-gradient benchmark.
- It improves over plug-in functional hypergradients and regularized kernel bilevel baselines.
Where Pith is reading between the lines
- This approach may generalize to other semiparametric nested problems where plug-in estimates introduce bias.
- Practitioners could use it to improve reliability in hyperparameter optimization or meta-learning tasks.
- Future work might explore extensions to non-quadratic losses or high-dimensional settings.
Load-bearing premise
The lower-level problem must admit a well-defined efficient influence function when solved nonparametrically, and cross-fitting must be feasible to achieve orthogonality without new biases.
What would settle it
Observing that the proposed estimator fails to track the oracle gradient or exhibits persistent bias on synthetic data with known ground truth would falsify the asymptotic normality and debiasing claims.
Figures










read the original abstract
Functional bilevel methods estimate a lower-level function and plug it into a hypergradient, but this plug-in gradient can retain first-order bias when the lower-level problem is learned nonparametrically. To remove this bias, we develop a semiparametric debiasing theory for population bilevel gradients based on the efficient influence function. This perspective leads to a cross-fitted orthogonal hypergradient estimator for which we establish asymptotic normality together with uniform control over the outer parameter. Under quadratic losses, the estimator reduces to a simple doubly robust score based on conditional mean nuisances. On synthetic bilevel benchmarks with known ground truth, the method tracks the oracle efficient-gradient benchmark and improves over plug-in functional hypergradients and regularized kernel bilevel baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a semiparametric debiasing theory for population bilevel gradients based on the efficient influence function. This yields a cross-fitted orthogonal hypergradient estimator with established asymptotic normality and uniform control over the outer parameter. Under quadratic losses the estimator reduces to a doubly robust score using conditional-mean nuisances. Synthetic experiments show the method tracks an oracle efficient-gradient benchmark and improves on plug-in functional hypergradients and regularized kernel baselines.
Significance. If the uniform-control and asymptotic-normality results hold under the stated regularity conditions, the work supplies a principled bias-correction mechanism for nonparametric lower-level problems in bilevel optimization. The explicit link to efficient influence functions and the reduction to a doubly-robust score constitute a clear technical contribution that could improve reliability of hypergradient-based methods in hyperparameter optimization and meta-learning.
major comments (1)
- [main theoretical result / Theorem on asymptotic normality] The central claim of asymptotic normality together with uniform control over the outer parameter (stated in the abstract and presumably proved in the main theoretical section) rests on cross-fitting preserving orthogonality when the lower-level nonparametric estimator depends on the outer parameter. The manuscript does not exhibit the explicit uniform convergence rates or Lipschitz conditions on the bilevel map that would guarantee the re-introduced first-order bias term vanishes uniformly; without these the uniform-control guarantee is not yet load-bearing.
minor comments (2)
- [Introduction] The abstract refers to 'functional bilevel methods' and 'population bilevel gradients' without a brief definitional sentence; a short clarifying paragraph in the introduction would help readers unfamiliar with the functional setting.
- [Method section] The reduction to the doubly-robust score under quadratic losses is mentioned in the abstract; an explicit display of the resulting score (perhaps as a displayed equation) would make the special case immediately usable.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the single major comment point-by-point below and will incorporate the requested clarifications to strengthen the theoretical results.
read point-by-point responses
-
Referee: The central claim of asymptotic normality together with uniform control over the outer parameter (stated in the abstract and presumably proved in the main theoretical section) rests on cross-fitting preserving orthogonality when the lower-level nonparametric estimator depends on the outer parameter. The manuscript does not exhibit the explicit uniform convergence rates or Lipschitz conditions on the bilevel map that would guarantee the re-introduced first-order bias term vanishes uniformly; without these the uniform-control guarantee is not yet load-bearing.
Authors: We thank the referee for highlighting this important technical point. The proof of asymptotic normality (Theorem 4.1) uses cross-fitting to preserve orthogonality of the efficient influence function, but we agree that when the lower-level nonparametric estimator depends on the outer parameter, an additional first-order bias term can reappear and must be shown to vanish uniformly. In the revised manuscript we will add: (i) an explicit Lipschitz condition on the bilevel map with respect to the outer parameter (with constant L independent of sample size), and (ii) the uniform convergence rate requirement on the nuisance estimators (o_p(n^{-1/4}) uniformly over a compact outer-parameter set). These conditions will be stated as part of the main theorem and used in the appendix proof to bound the remainder term by o_p(n^{-1/2}) uniformly. We believe this revision will make the uniform-control claim fully rigorous. revision: yes
Circularity Check
Semiparametric debiasing via efficient influence function draws from established theory rather than self-referential construction
full rationale
The derivation begins from the standard efficient influence function for the lower-level conditional mean nuisance and constructs an orthogonal hypergradient estimator by cross-fitting. This step imports the EIF from classical semiparametric statistics without re-deriving it from the bilevel objective itself; the paper's equations therefore do not reduce the claimed asymptotic normality or uniform control to a tautological re-expression of the fitted parameters. No load-bearing self-citation chain or ansatz-smuggling is exhibited in the provided sections. The central claim remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The bilevel gradient functional admits an efficient influence function that can be used for first-order debiasing
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a semiparametric debiasing theory for population bilevel gradients based on the efficient influence function. This perspective leads to a cross-fitted orthogonal hypergradient estimator...
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under quadratic losses, the estimator reduces to a simple doubly robust score based on conditional mean nuisances.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brandon Amos and J. Zico Kolter. OptNet: Differentiable Optimization as a Layer in Neural Networks. InInternational Conference on Machine Learning (ICML), 2017
work page 2017
-
[2]
Fitted Q-iteration in continuous action-space MDPs
András Antos, Rémi Munos, and Csaba Szepesvári. Fitted Q-iteration in continuous action-space MDPs. InAdvances in Neural Information Processing Systems (NIPS), 2007
work page 2007
-
[3]
Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang
Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang. On Exact Computation with an Infinitely Wide Neural Net. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[4]
Bartlett, Olivier Bousquet, and Shahar Mendelson
Peter L. Bartlett, Olivier Bousquet, and Shahar Mendelson. Local Rademacher Complexities.The Annals of Statistics, 33(4):1497–1537, 2005
work page 2005
-
[5]
Deep Generalized Method of Moments for Instrumental Variable Analysis
Andrew Bennett, Nathan Kallus, and Tobias Schnabel. Deep Generalized Method of Moments for Instrumental Variable Analysis. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[6]
Alain Berlinet and Christine Thomas-Agnan.Reproducing Kernel Hilbert Spaces in Probability and Statistics. Springer, 2004
work page 2004
-
[7]
Functional Natural Policy Gradients
Aurelien Bibaut, Houssam Zenati, Thibaud Rahier, and Nathan Kallus. Functional natural policy gradients.arXiv preprint arXiv:2603.28681, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Peter J. Bickel, Chris A. J. Klaassen, Ya’acov Ritov, and Jon A. Wellner.Efficient and Adaptive Estimation for Semiparametric Models. Johns Hopkins University Press, 1993. 11
work page 1993
-
[9]
Stability and Generalization.Journal of Machine Learning Research (JMLR), 2:499–526, 2002
Olivier Bousquet and André Elisseeff. Stability and Generalization.Journal of Machine Learning Research (JMLR), 2:499–526, 2002
work page 2002
-
[10]
Optimal Rates for the Regularized Least-Squares Algorithm
Andrea Caponnetto and Ernesto De Vito. Optimal Rates for the Regularized Least-Squares Algorithm. Foundations of Computational Mathematics, 7(3):331–368, 2007
work page 2007
-
[11]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/Debiased Machine Learning for Treatment and Structural Parame- ters.The Econometrics Journal, 21(1):C1–C68, 2018
work page 2018
-
[12]
Locally Robust Semiparametric Estimation.Econometrica, 90(4):1501–1535, 2022
Victor Chernozhukov, Juan Carlos Escanciano, Hidehiko Ichimura, Whitney K Newey, and James M Robins. Locally Robust Semiparametric Estimation.Econometrica, 90(4):1501–1535, 2022
work page 2022
-
[13]
Quintas-Martínez, and Vasilis Syrgkanis
Victor Chernozhukov, Whitney Newey, Víctor M. Quintas-Martínez, and Vasilis Syrgkanis. RieszNet and ForestRiesz: Automaticdebiasedmachinelearningwithneuralnetsandrandomforests. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 3901–3914. PMLR, 2022
work page 2022
-
[14]
Learning Theory for Kernel Bilevel Optimization
Fares El Khoury, Edouard Pauwels, Samuel Vaiter, and Michael Arbel. Learning Theory for Kernel Bilevel Optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[15]
Tree-based batch mode reinforcement learning
Damien Ernst, Pierre Geurts, and Louis Wehenkel. Tree-based batch mode reinforcement learning. Journal of Machine Learning Research (JMLR), 6:503–556, 2005
work page 2005
-
[16]
Regularized fitted Q-iteration for planning in continuous-space Markovian decision problems
Amir-massoudFarahmand, MohammadGhavamzadeh, CsabaSzepesvári, andShieMannor. Regularized fitted Q-iteration for planning in continuous-space Markovian decision problems. InAmerican Control Conference, 2009
work page 2009
-
[17]
Luisa Turrin Fernholz.Von Mises Calculus for Statistical Functionals. Springer, New York, 1983
work page 1983
-
[18]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. InInternational Conference on Machine Learning (ICML), 2017
work page 2017
-
[19]
Orthogonal Statistical Learning.The Annals of Statistics, 51(3):879–908, 2023
Dylan J Foster and Vasilis Syrgkanis. Orthogonal Statistical Learning.The Annals of Statistics, 51(3):879–908, 2023
work page 2023
-
[20]
Bilevel Programming for Hyperparameter Optimization and Meta-Learning
Luca Franceschi, Paolo Frasconi, Saverio Salzo, Riccardo Grazzi, and Massimiliano Pontil. Bilevel Programming for Hyperparameter Optimization and Meta-Learning. InInternational Conference on Machine Learning (ICML), 2018
work page 2018
-
[21]
Approximation Methods for Bilevel Programming
Saeed Ghadimi and Mengdi Wang. Approximation Methods for Bilevel Programming. InarXiv preprint arXiv:1802.02246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Frank R. Hampel. The influence curve and its role in robust statistics.Journal of the American Statistical Association, 69(346):383–393, 1974
work page 1974
-
[23]
Train Faster, Generalize Better: Stability of Stochas- tic Gradient Descent
Moritz Hardt, Benjamin Recht, and Yoram Singer. Train Faster, Generalize Better: Stability of Stochas- tic Gradient Descent. InInternational Conference on Machine Learning (ICML), 2016
work page 2016
-
[24]
Deep IV: A Flexible Approach for Counterfactual Prediction
Jason Hartford, Greg Lewis, Kevin Leyton-Brown, and Matt Taddy. Deep IV: A Flexible Approach for Counterfactual Prediction. InInternational Conference on Machine Learning (ICML), 2017
work page 2017
-
[25]
Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A Two-Timescale Stochastic Algorithm Framework for Bilevel Optimization.Mathematical Programming, 198:1075–1130, 2023
work page 2023
-
[26]
Neural Tangent Kernel: Convergence and Gener- alization in Neural Networks
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural Tangent Kernel: Convergence and Gener- alization in Neural Networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[27]
Bilevel Optimization: Convergence Analysis and Enhanced Design
Kaiyi Ji, Junjie Yang, and Yingbin Liang. Bilevel Optimization: Convergence Analysis and Enhanced Design. InInternational Conference on Machine Learning (ICML), 2021. 12
work page 2021
- [28]
-
[29]
Near- Optimal Stochastic Bilevel Optimization via Double-Momentum
Prashant Khanduri, Shiqian Zeng, Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. Near- Optimal Stochastic Bilevel Optimization via Double-Momentum. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[30]
Kosorok.Introduction to Empirical Processes and Semiparametric Inference
Michael R. Kosorok.Introduction to Empirical Processes and Semiparametric Inference. Springer, 2008
work page 2008
-
[31]
Karl Kunisch and Thomas Pock.Bilevel Optimization in Optimal Control. Springer, 2013
work page 2013
-
[32]
Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington
Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[33]
End-to-End Learning and Intervention in Games
Jiayang Li, Jing Yu, Yu Marco Nie, and Zhaoran Wang. End-to-End Learning and Intervention in Games. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[34]
Chun Kai Ling, Fei Fang, and J. Zico Kolter. What Game Are We Playing? End-to-end Learning in Nor- mal and Extensive Form Games. InProceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, pages 396–402, 2018
work page 2018
-
[35]
Risheng Liu, Jiaxin Gao, Jin Zhang, Deyu Meng, and Zhouchen Lin. Investigating and Benchmarking Bilevel Optimization Algorithms for Hyperparameter Optimization.arXiv preprint arXiv:2102.09588, 2021
-
[36]
Optimizing Millions of Hyperparameters by Implicit Differentiation
Jonathan Lorraine, Paul Vicol, and David Duvenaud. Optimizing Millions of Hyperparameters by Implicit Differentiation. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2020
work page 2020
-
[37]
Alex Luedtke and Incheoul Chung. One-step estimation of differentiable hilbert-valued parameters.The Annals of Statistics, 52(4):1534–1563, 2024
work page 2024
-
[38]
Luedtke, Marco Carone, and Mark J
Alexander R. Luedtke, Marco Carone, and Mark J. van der Laan. An omnibus non-parametric test of equality in distribution for unknown functions.Journal of the Royal Statistical Society: Series B, 81(1):75–99, 2019
work page 2019
-
[39]
Dougal Maclaurin, David Duvenaud, and Ryan P. Adams. Gradient-based hyperparameter optimization through reversible learning. InInternational Conference on Machine Learning (ICML), 2015
work page 2015
-
[40]
Andreas Maurer and Massimiliano Pontil. Algorithmic Stability and Meta-Learning.Journal of Machine Learning Research (JMLR), 18(1):292–336, 2017
work page 2017
-
[41]
Whitney K. Newey. The Asymptotic Variance of Semiparametric Estimators.Econometrica, 62(6):1349– 1382, 1994
work page 1994
-
[42]
Whitney K. Newey and James L. Powell. Instrumental Variable Estimation of Nonparametric Models. Econometrica, 71(5):1565–1578, 2003
work page 2003
-
[43]
Hyperparameteroptimizationwithapproximategradient
FabianPedregosa. Hyperparameteroptimizationwithapproximategradient. InInternational Conference on Machine Learning (ICML), 2016
work page 2016
-
[44]
Functional Bilevel Optimization for Machine Learn- ing
Ieva Petrulionyte, Julien Mairal, and Michael Arbel. Functional Bilevel Optimization for Machine Learn- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[45]
Aravind Rajeswaran, Chelsea Finn, Sham M. Kakade, and Sergey Levine. Meta-Learning with Implicit Gradients. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[46]
Robins, Andrea Rotnitzky, and Lue Ping Zhao
James M. Robins, Andrea Rotnitzky, and Lue Ping Zhao. Estimation of Regression Coefficients When Some Regressors Are Not Always Observed.Journal of the American Statistical Association, 89(427):846–866, 1994. 13
work page 1994
-
[47]
Convergence Rates of Inexact Proximal-Gradient Methods for Convex Optimization
Mark Schmidt, Nicolas Le Roux, and Francis Bach. Convergence Rates of Inexact Proximal-Gradient Methods for Convex Optimization. InAdvances in Neural Information Processing Systems (NIPS), 2011
work page 2011
-
[48]
Bernhard Schölkopf, Ralf Herbrich, and Alex J. Smola. A Generalized Representer Theorem.Computa- tional Learning Theory, pages 416–426, 2001
work page 2001
-
[49]
Instrumental Variable Analysis Without Structural Equations
Zikai Shen, Dimitri Meunier, Houssam Zenati, Arthur Gretton, Nathan Kallus, and Aurélien Bibaut. Instrumental Variable Analysis Without Structural Equations.arXiv preprint arXiv:2604.24660, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Kernel Instrumental Variable Regression
Rahul Singh, Maneesh Sahani, and Arthur Gretton. Kernel Instrumental Variable Regression. InAd- vances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[51]
Ingo Steinwart and Andreas Christmann.Support Vector Machines. Springer, 2008
work page 2008
-
[52]
Tsiatis.Semiparametric Theory and Missing Data
Anastasios A. Tsiatis.Semiparametric Theory and Missing Data. Springer, 2006
work page 2006
-
[53]
van de Geer.Empirical Processes in M-Estimation
Sara A. van de Geer.Empirical Processes in M-Estimation. Cambridge University Press, 2000
work page 2000
-
[54]
A Researcher’s Guide to Empirical Risk Minimization.arXiv preprint arXiv:2602.21501, 2026
Lars van der Laan. A Researcher’s Guide to Empirical Risk Minimization.arXiv preprint arXiv:2602.21501, 2026
-
[55]
Lars van der Laan, Aurélien Bibaut, Nathan Kallus, and Alex Luedtke. Automatic Debiased Machine Learning for Smooth Functionals of Nonparametric M-Estimands.arXiv preprint arXiv:2501.11868, 2025
-
[56]
Mark J. van der Laan and Sherri Rose.Targeted Learning: Causal Inference for Observational and Experimental Data. Springer, 2011
work page 2011
-
[57]
van der Vaart.Asymptotic Statistics
Aad W. van der Vaart.Asymptotic Statistics. Cambridge University Press, 1998
work page 1998
-
[58]
Aad W. van der Vaart and Jon A. Wellner.Weak Convergence and Empirical Processes: With Applica- tions to Statistics. Springer, 1996
work page 1996
-
[59]
Richard von Mises. On the asymptotic distribution of differentiable statistical functions.Annals of Mathematical Statistics, 18(3):309–348, 1947
work page 1947
-
[60]
Wainwright.High-Dimensional Statistics: A Non-Asymptotic Viewpoint
Martin J. Wainwright.High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Number 48 in Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2019
work page 2019
-
[61]
Provably Efficient Algorithms for Bilevel Optimization
Junjie Yang, Kaiyi Ji, and Yingbin Liang. Provably Efficient Algorithms for Bilevel Optimization. In Advances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[62]
Doubly-robust estimation of counterfactual policy mean embeddings
Houssam Zenati, Bariscan Bozkurt, and Arthur Gretton. Doubly-robust estimation of counterfactual policy mean embeddings. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[63]
Semiparametric Efficient Test for Interpretable Distributional Treatment Effects
Houssam Zenati and Arthur Gretton. Semiparametric efficient test for interpretable distributional treat- ment effects.arXiv preprint arXiv:2605.08034, 2026. 14 Appendix Contents A Efficient Influence Function 15 B Functional von Mises Expansion 17 C Asymptotic Normality 19 D Uniform Control and Optimization 21 D.1 Auxiliary empirical-process lemmas . . . ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[64]
For the gradient estimation and inference experiments,Y=ω ⋆⊤ϕ(Z) +ε Y with εY ∼ N(0,0.25 2), which isolates gradient estimation and calibration. For the KBO regularization experiment, we useY=ω ⋆⊤ϕ(Z)+0.5η, which preservesEP [Y|X]and henceΨ ω(P), but introduces correlation between the outcome noise andZ. We evaluate the population gradient at the fixed no...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.