Learning Subset-Shared Invariances for Domain Generalization with Mixture-of-Experts
Pith reviewed 2026-06-25 20:47 UTC · model grok-4.3
The pith
Enforcing invariance across all domains discards predictive factors shared only in subsets, limiting generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Enforcing invariance across more domains gradually restricts the feasible representation space, discarding transferable predictive factors that are not universally shared. The proposed subset-shared invariance with a mixture-of-experts architecture improves out-of-domain generalization by allowing predictive structure to be stable only within domain subsets.
What carries the argument
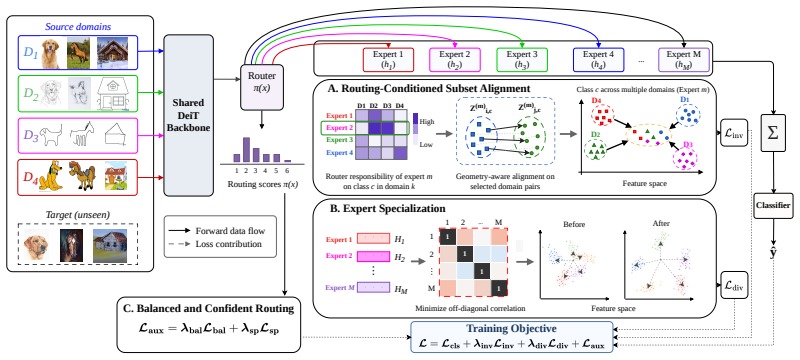
mixture-of-experts architecture implementing routing-conditioned subset-shared invariance, where each expert aligns specific domains and the router composes components for prediction
If this is right
- Improved out-of-domain generalization on DomainBed benchmarks
- Greater robustness as domain heterogeneity increases
- Domain generalization benefits from modeling partially shared structure rather than a single global invariance
- Selective alignment, confident routing, and diverse specialization encourage effective decomposition
Where Pith is reading between the lines
- Routing mechanisms could be adapted to other multi-domain settings like federated learning where data distributions vary across clients.
- Specialized experts might provide insight into which domain subsets share predictive factors.
- Further gains may come from allowing the number of experts to grow with the number of domains.
Load-bearing premise
Predictive structure remains stable within domain subsets and the mixture-of-experts can learn to route without overfitting or failing to specialize.
What would settle it
A controlled experiment on a synthetic dataset with known subset structures where the mixture-of-experts method shows no improvement over global invariance methods.
Figures

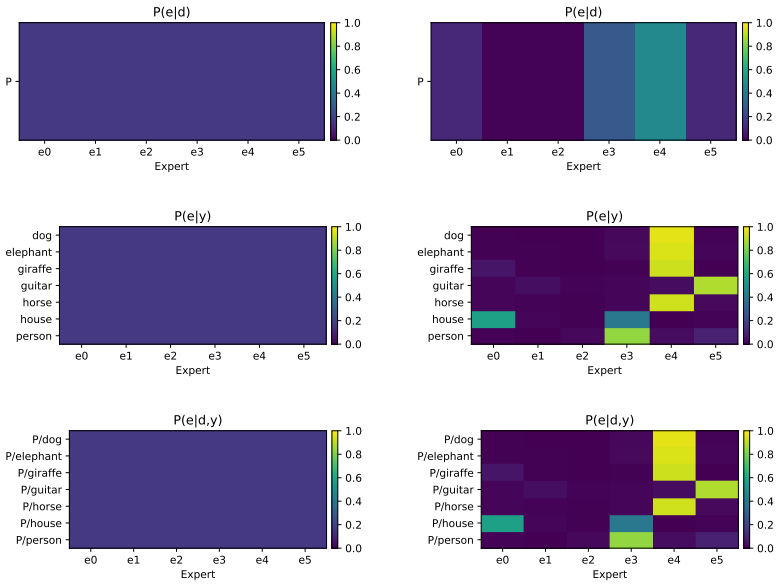
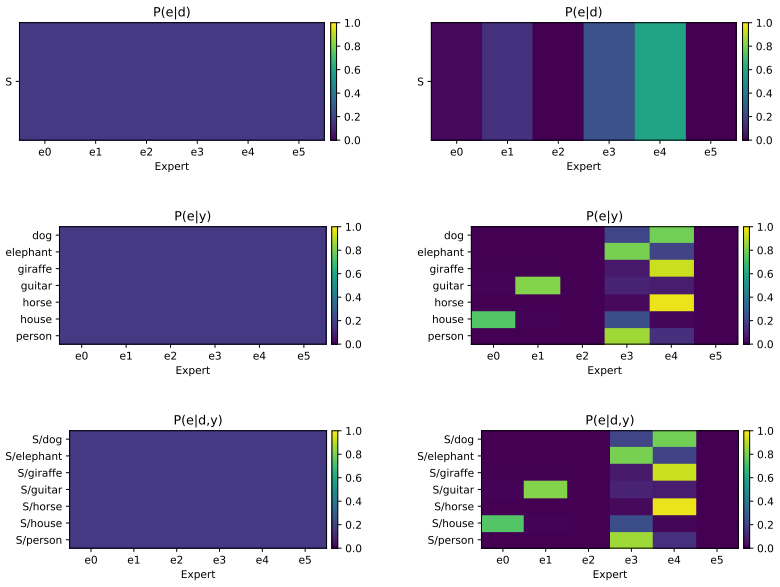

read the original abstract
Domain generalization (DG) aims to learn a model from one or more source domains that generalizes to an unseen target domain without accessing target data during training. A common approach enforces invariance of representations across all source domains, assuming predictive structure is globally shared. However, we demonstrate that enforcing invariance across more domains gradually restricts the feasible representation space, discarding transferable predictive factors that are not universally shared. To address this limitation, we propose subset-shared invariance, where predictive structure is assumed stable only within domain subsets. We implement this principle with a mixture-of-experts architecture, where each expert aligns the specific domains it serves and a routing mechanism composes subset-invariant components for prediction. This creates a routing-conditioned invariance, jointly learned with the representation. To facilitate effective decomposition, we develop training objectives that encourage selective alignment, confident and balanced routing, and diverse expert specialization. Experiments on DomainBed benchmarks demonstrate improved out-of-domain generalization and greater robustness under increasing domain heterogeneity. Our results suggest that DG should move beyond enforcing a single global invariance and instead model invariance through partially shared structure across domain subsets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that enforcing invariance across all source domains in domain generalization restricts the representation space by discarding predictive factors not universally shared. It proposes subset-shared invariance via a mixture-of-experts architecture in which each expert aligns a specific domain subset, a routing mechanism composes subset-invariant components, and auxiliary objectives encourage selective alignment, confident/balanced routing, and expert diversity. Experiments on DomainBed benchmarks are reported to show improved out-of-domain generalization and robustness under increasing domain heterogeneity.
Significance. If the routing successfully discovers stable, non-trivial domain subsets whose predictive factors are not globally shared, the work would provide a concrete mechanism for moving beyond single global invariance in DG. The combination of per-expert alignment losses with routing regularizers is a clear technical contribution; reproducible code or ablations isolating the effect of each regularizer would further strengthen the result.
major comments (1)
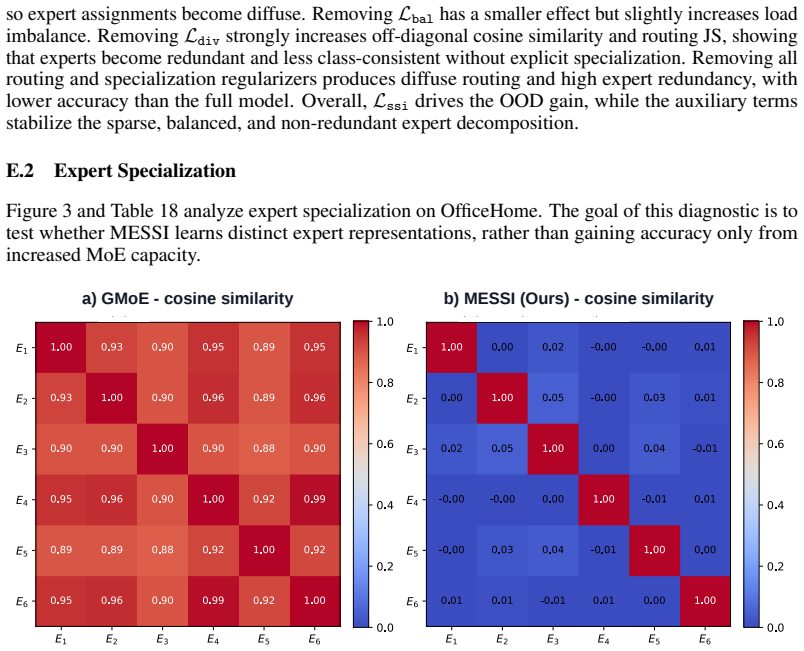
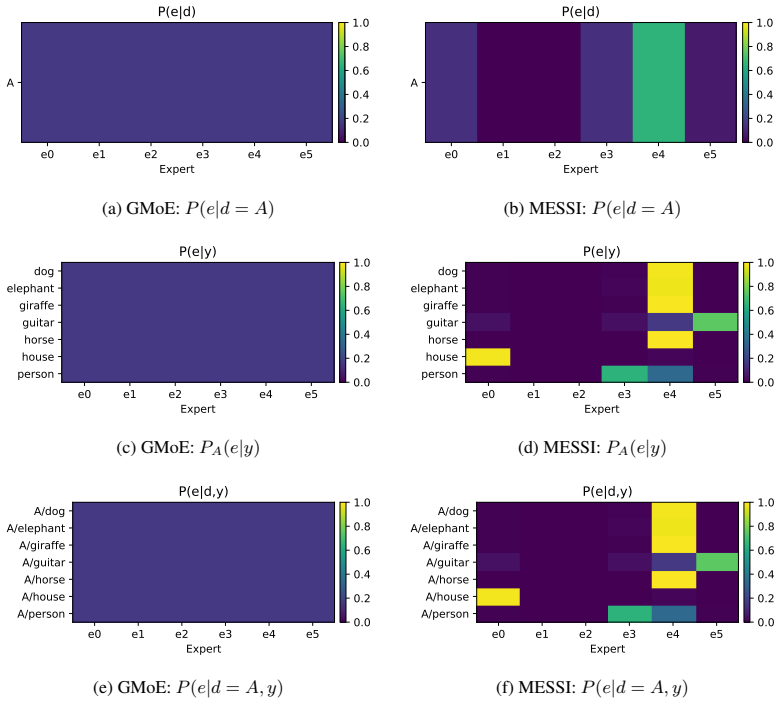
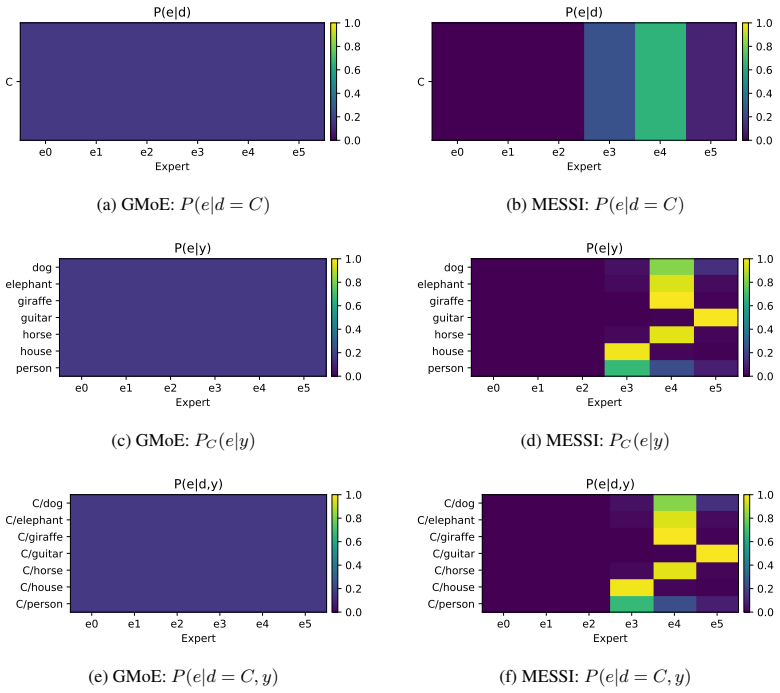
- [Mixture-of-Experts Architecture and Training Objectives] The central claim requires that the learned routing discovers stable domain subsets whose predictive factors are not globally shared. Because routing is end-to-end and unsupervised with respect to subset labels, the combination of selective alignment, confident/balanced routing, and diversity objectives may admit collapse (one expert dominates) or trivial solutions (experts differ only in capacity). This is load-bearing; the manuscript should include explicit ablations or diagnostics (e.g., expert activation histograms per domain, comparison against a single-expert baseline) demonstrating that distinct subset structure is recovered rather than global invariance or domain-identity memorization.
minor comments (2)
- Notation for the routing function and the per-expert alignment loss should be introduced with a single consistent equation block rather than scattered across paragraphs.
- Table captions should explicitly state the number of runs and whether error bars reflect standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The concern about potential collapse or trivial solutions in the routing mechanism is substantive and directly relevant to our central claim. We address it point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim requires that the learned routing discovers stable domain subsets whose predictive factors are not globally shared. Because routing is end-to-end and unsupervised with respect to subset labels, the combination of selective alignment, confident/balanced routing, and diversity objectives may admit collapse (one expert dominates) or trivial solutions (experts differ only in capacity). This is load-bearing; the manuscript should include explicit ablations or diagnostics (e.g., expert activation histograms per domain, comparison against a single-expert baseline) demonstrating that distinct subset structure is recovered rather than global invariance or domain-identity memorization.
Authors: We agree that verifying non-trivial, stable subset discovery is essential and that the current experiments provide only indirect support via improved generalization under heterogeneity. While the performance gains on DomainBed (particularly the robustness trend with increasing domain shift) are inconsistent with complete collapse to a single expert or pure domain memorization, we acknowledge that direct diagnostics are needed. In the revised manuscript we will add: expert activation histograms per domain, a single-expert baseline comparison, and quantitative metrics on routing confidence, balance, and expert diversity. These will appear in a new subsection of the experiments (or appendix) to explicitly rule out the trivial cases raised. revision: yes
Circularity Check
No significant circularity; proposal is architecturally grounded
full rationale
The paper advances a conceptual and architectural proposal for subset-shared invariance via MoE routing and auxiliary objectives (selective alignment, confident/balanced routing, diversity). No equations, fitted parameters, or self-citations are shown that reduce the central claim to a tautology or input by construction. The argument that global invariance discards non-universal factors is presented as a motivating observation, not a derived result, and the MoE implementation is offered as an independent modeling choice whose effectiveness is to be validated empirically on DomainBed. The derivation chain therefore remains self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
Pith/arXiv arXiv 1907
-
[2]
Metareg: Towards domain generalization using meta-regularization.Advances in neural information processing systems, 31, 2018
Yogesh Balaji, Swami Sankaranarayanan, and Rama Chellappa. Metareg: Towards domain generalization using meta-regularization.Advances in neural information processing systems, 31, 2018
2018
-
[3]
Gradient-guided annealing for domain generalization
Aristotelis Ballas and Christos Diou. Gradient-guided annealing for domain generalization. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 20558–20568, 2025
2025
-
[4]
Recognition in terra incognita
Sara Beery, Grant Van Horn, and Pietro Perona. Recognition in terra incognita. InProceedings of the European conference on computer vision (ECCV), pages 456–473, 2018
2018
-
[5]
The iwildcam 2021 competi- tion dataset.arXiv preprint arXiv:2105.03494, 2021
Sara Beery, Arushi Agarwal, Elijah Cole, and Vighnesh Birodkar. The iwildcam 2021 competi- tion dataset.arXiv preprint arXiv:2105.03494, 2021
arXiv 2021
-
[6]
Domain generalization by solving jigsaw puzzles
Fabio M Carlucci, Antonio D’Innocente, Silvia Bucci, Barbara Caputo, and Tatiana Tommasi. Domain generalization by solving jigsaw puzzles. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2229–2238, 2019
2019
-
[7]
Swad: Domain generalization by seeking flat minima.Advances in Neural Information Processing Systems, 34:22405–22418, 2021
Junbum Cha, Sanghyuk Chun, Kyungjae Lee, Han-Cheol Cho, Seunghyun Park, Yunsung Lee, and Sungrae Park. Swad: Domain generalization by seeking flat minima.Advances in Neural Information Processing Systems, 34:22405–22418, 2021
2021
-
[8]
Domain generalization by mutual-information regularization with pre-trained models
Junbum Cha, Kyungjae Lee, Sungrae Park, and Sanghyuk Chun. Domain generalization by mutual-information regularization with pre-trained models. InEuropean conference on computer vision, pages 440–457, 2022
2022
-
[9]
Lfme: A simple framework for learning from multiple experts in domain generalization.Advances in Neural Information Processing Systems, 37:102919–102947, 2024
Liang Chen, Yong Zhang, Yibing Song, Zhiqiang Shen, and Lingqiao Liu. Lfme: A simple framework for learning from multiple experts in domain generalization.Advances in Neural Information Processing Systems, 37:102919–102947, 2024
2024
-
[10]
Point-moe: Large- scale multi-dataset training with mixture-of-experts for 3d semantic segmentation
Xuweiyi Chen, Wentao Zhou, Aruni RoyChowdhury, and Zezhou Cheng. Point-moe: Large- scale multi-dataset training with mixture-of-experts for 3d semantic segmentation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[11]
Dis- entangled prompt representation for domain generalization
De Cheng, Zhipeng Xu, Xinyang Jiang, Nannan Wang, Dongsheng Li, and Xinbo Gao. Dis- entangled prompt representation for domain generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23595–23604, 2024
2024
-
[12]
Peer pressure: Model-to-model regular- ization for single source domain generalization
Dong Kyu Cho, Inwoo Hwang, and Sanghack Lee. Peer pressure: Model-to-model regular- ization for single source domain generalization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15360–15370, 2025
2025
-
[13]
One-step generalization ratio guided optimiza- tion for domain generalization
Sumin Cho, Dongwon Kim, and Kwangsu Kim. One-step generalization ratio guided optimiza- tion for domain generalization. InForty-second International Conference on Machine Learning, 2025
2025
-
[14]
Generalizable person re-identification with relevance-aware mixture of experts
Yongxing Dai, Xiaotong Li, Jun Liu, Zekun Tong, and Ling-Yu Duan. Generalizable person re-identification with relevance-aware mixture of experts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16145–16154, 2021
2021
-
[15]
Unlearning during training: Domain-specific gradient ascent for domain generalization
Jingfeng Zhang Di Zhao, Hongsheng Hu, Philippe Fournier-Viger, Gillian Dobbie, and Yun Sing Koh. Unlearning during training: Domain-specific gradient ascent for domain generalization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[16]
Domain generalization via pareto optimal gradient matching
Khoi Do, Nam-Khanh Le, Quoc-Viet Pham, Binh-Son Hua, Won-Joo Hwang, and Duong Nguyen. Domain generalization via pareto optimal gradient matching. In28th European Conference on Artificial Intelligence, ECAI 2025. IOS Press BV , 2025. 10
2025
-
[17]
Domain gener- alization via model-agnostic learning of semantic features.Advances in neural information processing systems, 32, 2019
Qi Dou, Daniel Coelho de Castro, Konstantinos Kamnitsas, and Ben Glocker. Domain gener- alization via model-agnostic learning of semantic features.Advances in neural information processing systems, 32, 2019
2019
-
[18]
Unbiased metric learning: On the utilization of multiple datasets and web images for softening bias
Chen Fang, Ye Xu, and Daniel N Rockmore. Unbiased metric learning: On the utilization of multiple datasets and web images for softening bias. InProceedings of the IEEE international conference on computer vision, pages 1657–1664, 2013
2013
-
[19]
Omoe: Diversifying mixture of low-rank adaptation by orthogonal finetuning
Jinyuan Feng, Zhiqiang Pu, Tianyi Hu, Dongmin Li, Xiaolin Ai, and Huimu Wang. Omoe: Diversifying mixture of low-rank adaptation by orthogonal finetuning. InEuropean Conference on Artificial Intelligence, 2025
2025
-
[20]
Domain-adversarial training of neural networks
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario March, and Victor Lempitsky. Domain-adversarial training of neural networks. Journal of machine learning research, 17(59):1–35, 2016
2016
-
[21]
Partial success in closing the gap between human and machine vision.Advances in Neural Information Processing Systems, 34:23885– 23899, 2021
Robert Geirhos, Kantharaju Narayanappa, Benjamin Mitzkus, Tizian Thieringer, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Partial success in closing the gap between human and machine vision.Advances in Neural Information Processing Systems, 34:23885– 23899, 2021
2021
-
[22]
Domain gen- eralization for object recognition with multi-task autoencoders
Muhammad Ghifary, W Bastiaan Kleijn, Mengjie Zhang, and David Balduzzi. Domain gen- eralization for object recognition with multi-task autoencoders. InProceedings of the IEEE international conference on computer vision, pages 2551–2559, 2015
2015
-
[23]
In search of lost domain generalization
Ishaan Gulrajani and David Lopez-Paz. In search of lost domain generalization. InInternational Conference on Learning Representations, 2021
2021
-
[24]
Advancing expert specialization for better moe
Hongcan Guo, Haolang Lu, Guoshun Nan, Bolun Chu, Jialin Zhuang, Yuan Yang, Wenhao Che, Xinye Cao, Sicong Leng, Qimei Cui, et al. Advancing expert specialization for better moe. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
Dynamic mixture of experts: An auto-tuning approach for efficient transformer models
Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Zhaopeng Tu, and Tao Lin. Dynamic mixture of experts: An auto-tuning approach for efficient transformer models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[27]
Learning time-aware causal representation for model generalization in evolving domains
Zhuo He, Shuang Li, Wenze Song, Longhui Yuan, Jian Liang, Han Li, and Kun Gai. Learning time-aware causal representation for model generalization in evolving domains. InForty-second International Conference on Machine Learning, 2025
2025
-
[28]
Multi-task reinforcement learning with mixture of orthogonal experts
Ahmed Hendawy, Jan Peters, and Carlo D’Eramo. Multi-task reinforcement learning with mixture of orthogonal experts. InThe Twelfth International Conference on Learning Represen- tations, 2024. URLhttps://openreview.net/forum?id=aZH1dM3GOX
2024
-
[29]
Learn to preserve and diversify: Parameter-efficient group with orthogonal regularization for domain generalization
Jiajun Hu, Jian Zhang, Lei Qi, Yinghuan Shi, and Yang Gao. Learn to preserve and diversify: Parameter-efficient group with orthogonal regularization for domain generalization. InEuropean Conference on Computer Vision, pages 198–216, 2024
2024
-
[30]
Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
1991
-
[31]
Qt-dog: Quantization-aware training for domain generalization
Saqib Javed, Hieu Le, and Mathieu Salzmann. Qt-dog: Quantization-aware training for domain generalization. InForty-second International Conference on Machine Learning, 2025
2025
-
[32]
Customizing domain adapters for domain generalization
Yuyang Ji, Zeyi Huang, Haohan Wang, and Yong Jae Lee. Customizing domain adapters for domain generalization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 934–944, 2025
2025
-
[33]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 11
Pith/arXiv arXiv 2014
-
[34]
Wilds: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. InInternational conference on machine learning, pages 5637–5664. PMLR, 2021
2021
-
[35]
Sparse mixture-of-experts are domain generalizable learners
Bo Li, Yifei Shen, Jingkang Yang, Yezhen Wang, Jiawei Ren, Tong Che, Jun Zhang, and Ziwei Liu. Sparse mixture-of-experts are domain generalizable learners. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[36]
Towards single- source domain generalized object detection via causal visual prompts
Chen Li, Huiying Xu, Changxin Gao, Zeyu Wang, Yun Liu, and Xinzhong Zhu. Towards single- source domain generalized object detection via causal visual prompts. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[37]
Deeper, broader and artier domain generalization
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. Deeper, broader and artier domain generalization. InProceedings of the IEEE international conference on computer vision, pages 5542–5550, 2017
2017
-
[38]
Prompt-driven dynamic object-centric learning for single domain generalization
Deng Li, Aming Wu, Yaowei Wang, and Yahong Han. Prompt-driven dynamic object-centric learning for single domain generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17606–17615, 2024
2024
-
[39]
Domain generalization with adversarial feature learning
Haoliang Li, Sinno Jialin Pan, Shiqi Wang, and Alex C Kot. Domain generalization with adversarial feature learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5400–5409, 2018
2018
-
[40]
Flat- lora: Low-rank adaptation over a flat loss landscape
Tao Li, Zhengbao He, Yujun Li, Yasheng Wang, Lifeng Shang, and Xiaolin Huang. Flat- lora: Low-rank adaptation over a flat loss landscape. InInternational Conference on Machine Learning, pages 34549–34563. PMLR, 2025
2025
-
[41]
Generalizing vision-language models with dedicated prompt guidance
Xinyao Li, Yinjie Min, Hongbo Chen, Zhekai Du, Fengling Li, and Jingjing Li. Generalizing vision-language models with dedicated prompt guidance. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23239–23247, 2026
2026
-
[42]
Deep domain generalization via conditional invariant adversarial networks
Ya Li, Xinmei Tian, Mingming Gong, Yajing Liu, Tongliang Liu, Kun Zhang, and Dacheng Tao. Deep domain generalization via conditional invariant adversarial networks. InProceedings of the European conference on computer vision (ECCV), pages 624–639, 2018
2018
-
[43]
Causality inspired representation learning for domain generalization
Fangrui Lv, Jian Liang, Shuang Li, Bin Zang, Chi Harold Liu, Ziteng Wang, and Di Liu. Causality inspired representation learning for domain generalization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8046–8056, 2022
2022
-
[44]
Domain generalization using causal matching
Divyat Mahajan, Shruti Tople, and Amit Sharma. Domain generalization using causal matching. InInternational conference on machine learning, pages 7313–7324. PMLR, 2021
2021
-
[45]
Domain generalization via gradient surgery
Lucas Mansilla, Rodrigo Echeveste, Diego H Milone, and Enzo Ferrante. Domain generalization via gradient surgery. InProceedings of the IEEE/CVF international conference on computer vision, pages 6630–6638, 2021
2021
-
[46]
Domain generalization via invariant feature representation
Krikamol Muandet, David Balduzzi, and Bernhard Schölkopf. Domain generalization via invariant feature representation. InInternational conference on machine learning, pages 10–18. PMLR, 2013
2013
-
[47]
Federated domain generalization with data-free on-server matching gradient
Trong Binh Nguyen, Duong Minh Nguyen, Jinsun Park, Viet Quoc Pham, and Won-Joo Hwang. Federated domain generalization with data-free on-server matching gradient. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[48]
Pace: Marrying generalization in parameter-efficient fine-tuning with consistency regularization.Advances in Neural Information Processing Systems, 37:61238–61266, 2024
Yao Ni, Shan Zhang, and Piotr Koniusz. Pace: Marrying generalization in parameter-efficient fine-tuning with consistency regularization.Advances in Neural Information Processing Systems, 37:61238–61266, 2024
2024
-
[49]
Multilinear mixture of experts: Scal- able expert specialization through factorization
James Oldfield, Markos Georgopoulos, Grigorios Chrysos, Christos Tzelepis, Yannis Panagakis, Mihalis Nicolaou, Jiankang Deng, and Ioannis Patras. Multilinear mixture of experts: Scal- able expert specialization through factorization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id= ...
2024
-
[50]
Minimal semantic sufficiency meets unsupervised do- main generalization
Tan Pan, Kaiyu Guo, Dongli Xu, Zhaorui Tan, Chen Jiang, Deshu Chen, Xin Guo, Brian C Lovell, LIMEI HAN, Yuan Cheng, et al. Minimal semantic sufficiency meets unsupervised do- main generalization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[51]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF international conference on computer vision, pages 1406–1415, 2019
2019
-
[52]
Efficient domain generalization via common-specific low-rank decomposition
Vihari Piratla, Praneeth Netrapalli, and Sunita Sarawagi. Efficient domain generalization via common-specific low-rank decomposition. InInternational conference on machine learning, pages 7728–7738. PMLR, 2020
2020
-
[53]
Fishr: Invariant gradient variances for out-of-distribution generalization
Alexandre Rame, Corentin Dancette, and Matthieu Cord. Fishr: Invariant gradient variances for out-of-distribution generalization. InInternational Conference on Machine Learning, pages 18347–18377. PMLR, 2022
2022
-
[54]
Generalizing across domains via cross-gradient training
Shiv Shankar, Vihari Piratla, Soumen Chakrabarti, Siddhartha Chaudhuri, Preethi Jyothi, and Sunita Sarawagi. Generalizing across domains via cross-gradient training. InInternational Conference on Learning Representations, 2018
2018
-
[55]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[56]
Gradient matching for domain generalization
Yuge Shi, Jeffrey Seely, Philip HS Torr, N Siddharth, Awni Hannun, Nicolas Usunier, and Gabriel Synnaeve. Gradient matching for domain generalization. In10th International Confer- ence on Learning Representations, ICLR 2022, pages 1–28, 2022
2022
-
[57]
Deep coral: Correlation alignment for deep domain adaptation
Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. InEuropean conference on computer vision, pages 443–450, 2016
2016
-
[58]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR, 2021
2021
-
[59]
Principles of risk minimization for learning theory.Advances in neural information processing systems, 4, 1991
Vladimir Vapnik. Principles of risk minimization for learning theory.Advances in neural information processing systems, 4, 1991
1991
-
[60]
Deep hashing network for unsupervised domain adaptation
Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5018–5027, 2017
2017
-
[61]
Sharpness-aware gradient matching for domain generalization
Pengfei Wang, Zhaoxiang Zhang, Zhen Lei, and Lei Zhang. Sharpness-aware gradient matching for domain generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3769–3778, 2023
2023
-
[62]
Lost domain generalization is a natural con- sequence of lack of training domains
Yimu Wang, Yihan Wu, and Hongyang Zhang. Lost domain generalization is a natural con- sequence of lack of training domains. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 15689–15697, 2024
2024
-
[63]
Indirect alignment and relationships preservation for domain generalization
Wei Wei, Zixiong Li, Jing Yan, Mingwen Shao, and Lin Li. Indirect alignment and relationships preservation for domain generalization. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 2054–2062, 2025
2054
-
[64]
Stronger fewer & superior: Harnessing vision foundation models for domain generalized semantic segmentation
Zhixiang Wei, Lin Chen, Yi Jin, Xiaoxiao Ma, Tianle Liu, Pengyang Ling, Ben Wang, Huaian Chen, and Jinjin Zheng. Stronger fewer & superior: Harnessing vision foundation models for domain generalized semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 28619–28630, 2024
2024
-
[65]
Domain generalization in clip via learning with diverse text prompts
Changsong Wen, Zelin Peng, Yu Huang, Xiaokang Yang, and Wei Shen. Domain generalization in clip via learning with diverse text prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9559–9569, 2025. 13
2025
-
[66]
Dynamic sparse training versus dense training: The unexpected winner in image corruption robustness
Boqian WU. Dynamic sparse training versus dense training: The unexpected winner in image corruption robustness. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[67]
Reasoning-driven multimodal llm for domain generalization
Zhipeng Xu, Zilong Wang, XINY ANG JIANG, Dongsheng Li, De Cheng, and Nannan Wang. Reasoning-driven multimodal llm for domain generalization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[68]
Im- proving domain generalization with domain relations
Huaxiu Yao, Xinyu Yang, Xinyi Pan, Shengchao Liu, Pang Wei Koh, and Chelsea Finn. Im- proving domain generalization with domain relations. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[69]
Integrating markov blanket discovery into causal representation learning for domain generalization
Naiyu Yin, Hanjing Wang, Yue Yu, Tian Gao, Amit Dhurandhar, and Qiang Ji. Integrating markov blanket discovery into causal representation learning for domain generalization. In European Conference on Computer Vision, pages 271–288, 2024
2024
-
[70]
Soma: Singular value decomposed minor components adaptation for domain generalizable representation learning
Seokju Yun, Seunghye Chae, Dongheon Lee, and Youngmin Ro. Soma: Singular value decomposed minor components adaptation for domain generalizable representation learning. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 25602–25612, 2025
2025
-
[71]
Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts
Sukwon Yun, Inyoung Choi, Jie Peng, Yangfan Wu, Jingxuan Bao, Qiyiwen Zhang, Jiayi Xin, Qi Long, and Tianlong Chen. Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=ihEHCbqZEx
2024
-
[72]
Towards principled disentanglement for domain generalization
Hanlin Zhang, Yi-Fan Zhang, Weiyang Liu, Adrian Weller, Bernhard Schölkopf, and Eric P Xing. Towards principled disentanglement for domain generalization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8024–8034, 2022
2022
-
[73]
Domain generalization with mixstyle
Kaiyang Zhou, Yongxin Yang, Yu Qiao, and Tao Xiang. Domain generalization with mixstyle. InInternational Conference on Learning Representations, 2021. 14 A Proofs A.1 Proof of Proposition 3.1 Proof.SinceK ⊆ K ′, we have P(K)⊆ P(K ′).(9) Therefore, X (i,j)∈P(K ′) I(Z;D|Y, D∈ {i, j}) = X (i,j)∈P(K) I(Z;D|Y, D∈ {i, j}) + X (i,j)∈P(K ′)\P(K) I(Z;D|Y, D∈ {i, j...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.