MIRAGE: Protecting against Malicious Image Editing via False Moderation
Pith reviewed 2026-06-29 04:44 UTC · model grok-4.3
The pith
Perturbing images to trigger false positives in pre-generation safety classifiers protects them from unauthorized edits in commercial AI systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
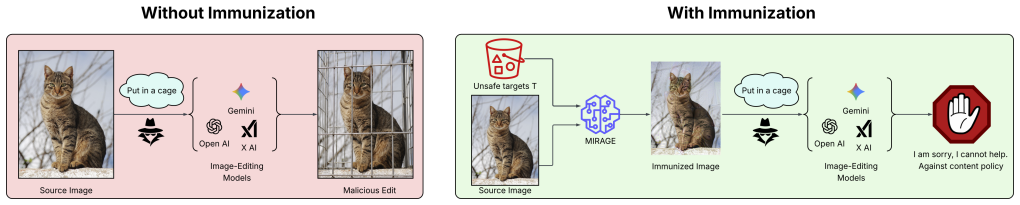
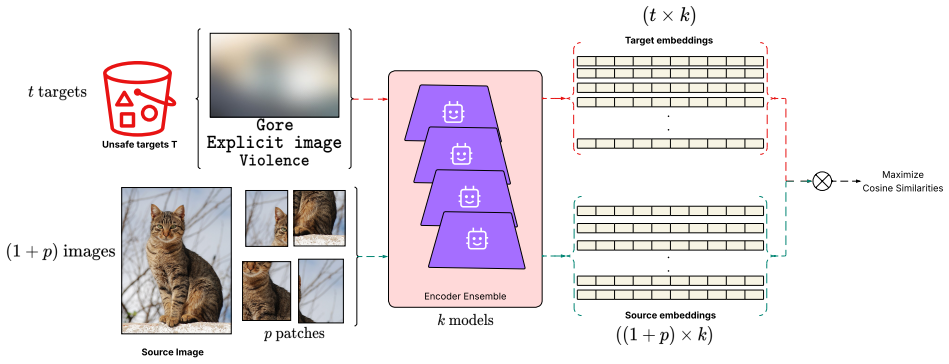
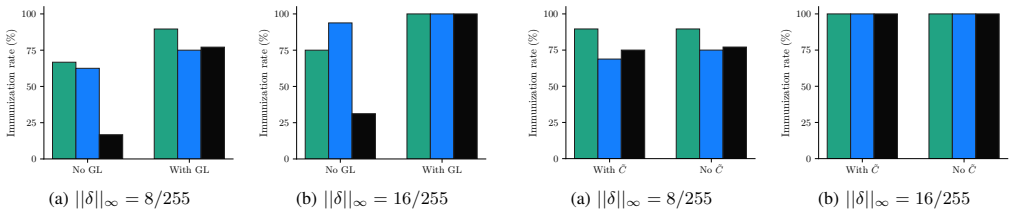
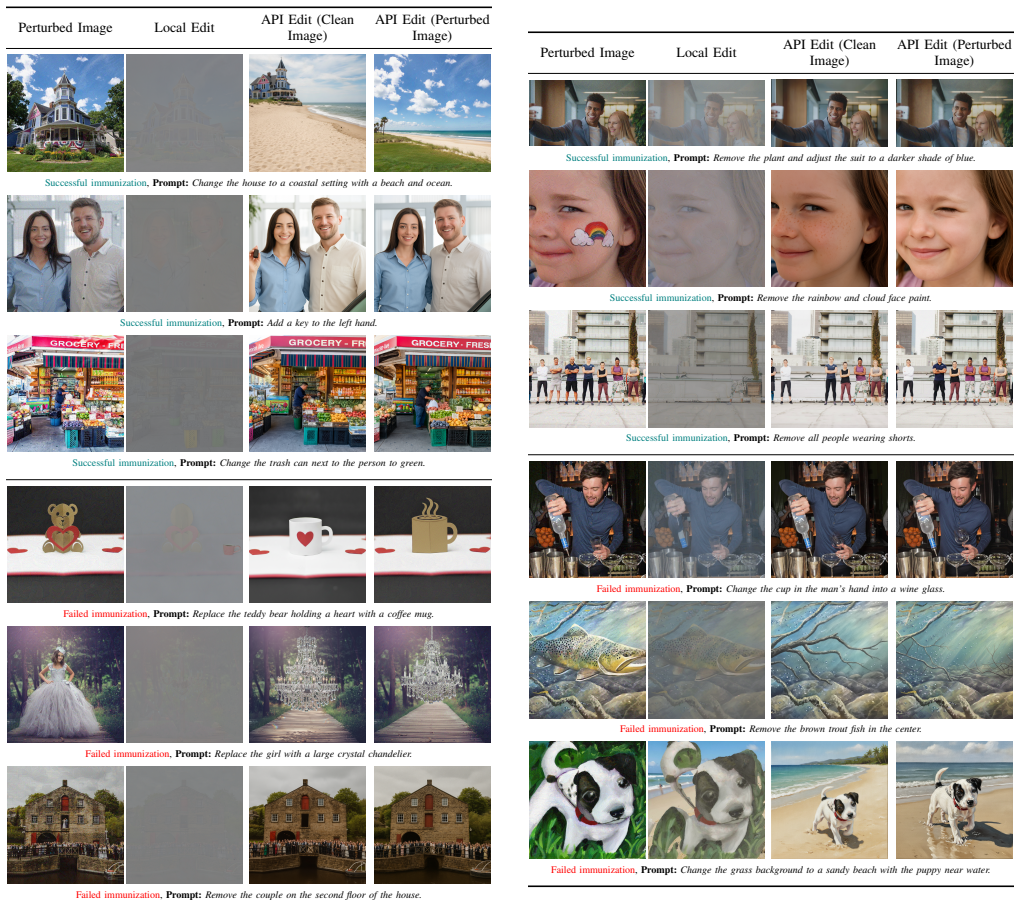
MIRAGE immunizes images by adding adversarial perturbations that align them to policy-violating concepts in the representation space of an ensemble of open-source embedding and moderation models, thereby causing the pre-generation safety classifiers in closed-source commercial image editing APIs to produce false positives and refuse any editing prompt.
What carries the argument
Adversarial perturbations optimized on an ensemble of open-source models to induce false positives in proprietary pre-generation moderation classifiers.
If this is right
- Edit requests on immunized images are refused by the system regardless of the editing prompt.
- Protection extends across multiple closed commercial APIs including GPT-Image, Gemini Flash Image, and Grok Imagine.
- The method requires neither the editing prompt nor access to the generative model weights.
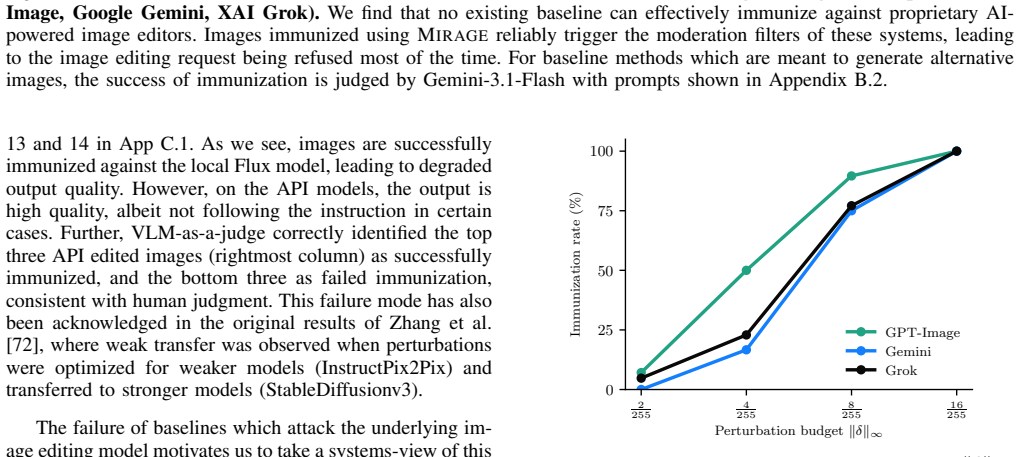
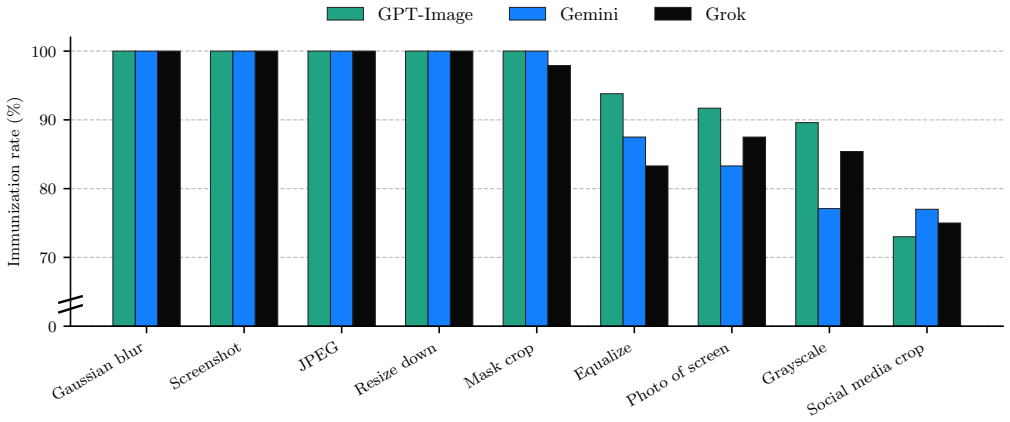
- Success exceeds 88 percent in direct evaluations against the closed-source systems.
Where Pith is reading between the lines
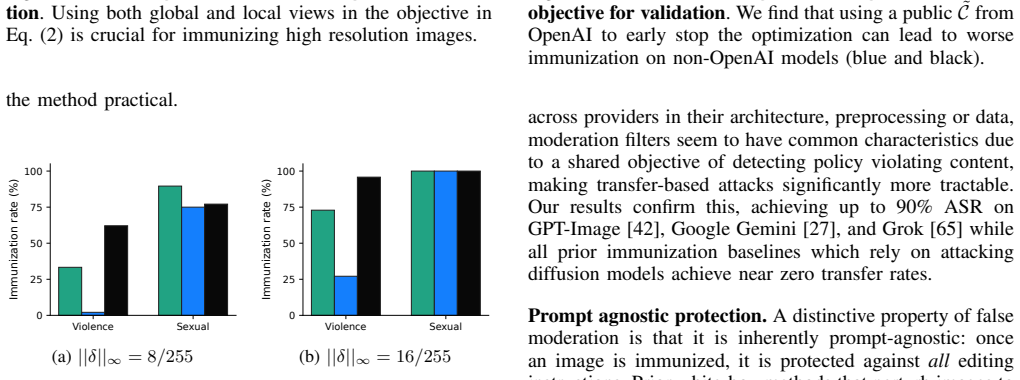
- The same moderation surface could be targeted in other generative services that share pre-generation safety checks.
- Widespread adoption would create an arms race where moderators are hardened against such transfer attacks.
- Individuals could apply the immunization to personal images before sharing them online.
- If open-source moderation models improve in robustness, the transfer success to closed systems might decline.
Load-bearing premise
Perturbations optimized against open-source moderation models will transfer to trigger false positives in the proprietary moderation classifiers used by commercial image editors.
What would settle it
Submitting MIRAGE-perturbed images to the target commercial APIs and observing that edit requests are accepted rather than refused would show the claimed transfer does not hold.
Figures
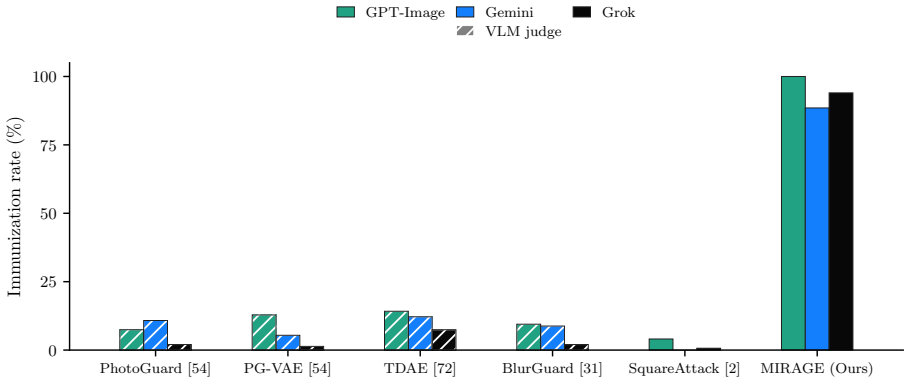




read the original abstract
The proliferation of AI-powered image editing systems raises serious concerns because it allows personal images to be arbitrarily manipulated at scale, with minimal effort, and a lower barrier to entry. Prior work on image immunization adds imperceptible perturbations to an image to protect against unauthorized manipulations. However, these methods usually require access to the model weights and the image manipulating prompt. This significantly limits their use, especially against powerful commercial image-editors such as GPT-Image, Gemini Flash Image (Nano Banana), and Grok Imagine. To address this, we take a system-level view of the problem and identify a previously unexplored attack surface common to all major commercial image editing systems: pre-generation safety moderation. Rather than disrupting the generative model itself, we propose to immunize images by causing these moderation classifiers to flag images as policy-violating, triggering an automatic refusal regardless of the editing prompt. We operationalize this by adding adversarial perturbations to align our image to policy-violating concepts in the representation space of an ensemble of open-source embedding and moderation models. We call our method MIRAGE, which stands for Moderation Induced Resistance Against Generative Editing. We evaluate MIRAGE against multiple closed-source image editing APIs and demonstrate success rates of more than 88%. Our approach is simple, prompt-agnostic, and effective, offering a practical path towards protecting personal images from unauthorized AI-powered editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MIRAGE to protect personal images from unauthorized editing by commercial AI image editing systems. It adds adversarial perturbations optimized on an ensemble of open-source embedding and moderation models to cause pre-generation safety moderation classifiers in closed-source APIs (GPT-Image, Gemini Flash Image, Grok Imagine) to flag the images as policy-violating, triggering refusals independent of the editing prompt. The authors report success rates of more than 88% and describe the method as simple, prompt-agnostic, and effective.
Significance. If the empirical results on transferability are robust, this work is significant for offering a practical defense mechanism that does not require access to proprietary model weights or knowledge of editing prompts. By targeting the shared pre-generation moderation layer, it provides a system-level solution to a growing privacy concern in generative AI, potentially influencing how safety filters are designed in future commercial systems.
major comments (2)
- Abstract: The claim of >88% success rates on closed-source APIs lacks accompanying experimental details, baselines, transfer metrics, or error analysis, which are necessary to substantiate the central empirical claim.
- Method section: The approach assumes that perturbations optimized against open-source models will transfer to proprietary moderation classifiers; however, without specific details on the ensemble composition, optimization objective, or evidence of shared representation geometry, the transferability remains an unverified core assumption.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work's significance and for the constructive feedback. We address each major comment below, proposing targeted revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: The claim of >88% success rates on closed-source APIs lacks accompanying experimental details, baselines, transfer metrics, or error analysis, which are necessary to substantiate the central empirical claim.
Authors: We agree that the abstract, being concise by nature, does not include the full experimental details. The manuscript's Experiments section (Section 4) provides these, including the specific closed-source APIs evaluated (GPT-Image, Gemini Flash Image, Grok Imagine), per-API success rates, baselines such as unperturbed images and random noise, transfer metrics from the open-source ensemble to closed APIs, and error analysis on the ~12% failure cases. To directly address the concern, we will revise the abstract to briefly note the evaluation scope (e.g., 'across 500 images on three commercial APIs with >88% average success') while keeping it within length limits. revision: yes
-
Referee: Method section: The approach assumes that perturbations optimized against open-source models will transfer to proprietary moderation classifiers; however, without specific details on the ensemble composition, optimization objective, or evidence of shared representation geometry, the transferability remains an unverified core assumption.
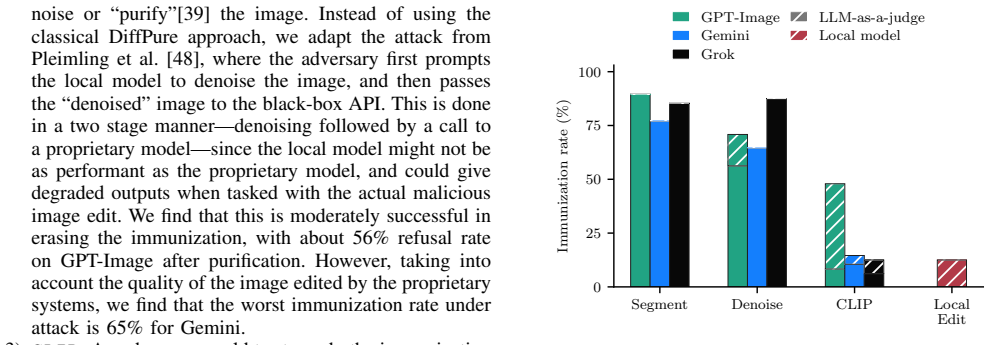
Authors: The Method section (Section 3) specifies the ensemble composition (CLIP ViT-L/14, OpenCLIP, and two open-source moderation models like those from LAION and Stability AI), the optimization objective (maximizing cosine similarity to policy-violating concept embeddings while minimizing perceptual distortion via PGD), and the prompt-agnostic nature. We provide empirical evidence of transfer via the reported success rates. However, we acknowledge that an explicit discussion of shared representation geometry (e.g., due to overlapping training data on safety policies) is limited. We will add a short subsection or paragraph in Methods providing this rationale and citing related work on moderation model similarities. revision: partial
Circularity Check
No circularity; empirical transfer evaluated on external closed APIs
full rationale
The paper's core procedure optimizes perturbations against open-source embedding/moderation models then measures refusal rates on separate closed-source commercial APIs (GPT-Image, Gemini, Grok). No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description; the >88% success claim rests on direct external measurements rather than any reduction to the optimization inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
N. Ahn, K. Yoo, W. Ahn, D. Kim, and S.-H. Nam. Nearly zero-cost protection against mimicry by per- sonalized diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 28801–28810, June
-
[2]
URL https://openaccess.thecvf.com/content/CV PR2025/html/Ahn Nearly Zero-Cost Protection Aga inst Mimicry by Personalized Diffusion Models C VPR 2025 paper.html
2025
-
[3]
M. Andriushchenko, F. Croce, N. Flammarion, and M. Hein. Square attack: A query-efficient black-box adversarial attack via random search. InComputer Vision – ECCV 2020, 2020. URL https://arxiv.org/ abs/1912.00049
arXiv 2020
-
[4]
Athalye, L
A. Athalye, L. Engstrom, A. Ilyas, and K. Kwok. Synthesizing robust adversarial examples. InInterna- tional conference on machine learning, pages 284–293. PMLR, 2018
2018
-
[5]
FLUX.2 [klein]: Towards Interac- tive Visual Intelligence
Black Forest Labs. FLUX.2 [klein]: Towards Interac- tive Visual Intelligence. https://bfl.ai/blog/flux2-kle in-towards-interactive-visual-intelligence, Jan. 2026. Blog post. Accessed: 2026-06-08
2026
-
[6]
S. Boztas. Dutch far-right party pays damages to court artist after changing image with AI. https://www.theg uardian.com/world/2026/jun/13/geert-wilders-pvv-dut ch-far-right-party-damages-court-artist-change-image -ai, June 2026
2026
-
[7]
W. Brendel, J. Rauber, and M. Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. InInternational Conference on Learning Representations (ICLR), 2018. URL https: //arxiv.org/abs/1712.04248
Pith/arXiv arXiv 2018
-
[8]
C. G. Broyden. A class of methods for solving nonlinear simultaneous equations.Mathematics of Computation, 19(92):577–593, 1965
1965
-
[9]
M. Burgess. Grok Is Still Hosting Sexualized Deep- fakes of Famous Women . https://www.wired.com/st ory/grok-is-still-hosting-sexualized-deepfakes-of-fam ous-women/, June 2026
2026
-
[10]
Grok floods X with sexualized images of women and children
Center for Countering Digital Hate. Grok floods X with sexualized images of women and children. https: //counterhate.com/research/grok-floods-x-with-sexuali zed-images/, January 2026
2026
-
[11]
H. Chen, Y . Zhang, Y . Dong, X. Yang, H. Su, and J. Zhu. Rethinking model ensemble in transfer-based adversarial attacks, 2024. URL https://arxiv.org/abs/ 2303.09105
arXiv 2024
-
[12]
P.-Y . Chen, H. Zhang, Y . Sharma, J. Yi, and C.-J. Hsieh. Zoo: Zeroth order optimization based black- box attacks to deep neural networks without training substitute models. InProceedings of the 10th ACM workshop on artificial intelligence and security, pages 15–26, 2017
2017
-
[13]
R. Chen, H. Jin, Y . Liu, J. Chen, H. Wang, and L. Sun. EditShield: Protecting unauthorized image editing by instruction-guided diffusion models. InComputer Vi- sion – ECCV 2024, pages 126–142. Springer, 2025. doi: 10.1007/978-3-031-73036-8 8
-
[14]
M. Cheng, T. Le, P.-Y . Chen, J. Yi, H. Zhang, and C.-J. Hsieh. Query-efficient hard-label black-box attack:an optimization-based approach, 2018. URL https://arxi v.org/abs/1807.04457
Pith/arXiv arXiv 2018
-
[15]
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev. Reproducible scaling laws for con- trastive language-image learning. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), page 2818–2829. IEEE, June 2023. doi: 10.1109/cvpr52729.2023.00276. URL http: //dx.doi.org/10....
-
[16]
J. Chi, U. Karn, H. Zhan, E. Smith, J. Rando, Y . Zhang, K. Plawiak, Z. D. Coudert, K. Upasani, and M. Pa- supuleti. Llama guard 3 vision: Safeguarding human- ai image understanding conversations.arXiv preprint arXiv:2411.10414, 2024
arXiv 2024
-
[17]
J. S. Choi, K. Lee, J. Jeong, S. Xie, J. Shin, and K. Lee. DiffusionGuard: A robust defense against malicious diffusion-based image editing. InInternational Confer- ence on Learning Representations (ICLR), 2025. URL https://openreview.net/forum?id=9OfKxKoYNw
2025
-
[18]
Defazio, F
A. Defazio, F. Bach, and S. Lacoste-Julien. Saga: A fast incremental gradient method with support for non- strongly convex composite objectives. InAdvances in Neural Information Processing Systems, 2014
2014
-
[19]
R. DiResta and J. A. Goldstein. How spammers and scammers leverage ai-generated images on facebook for audience growth.arXiv preprint arXiv:2403.12838, 2024
arXiv 2024
-
[20]
S. Dong, J. Zhang, G. Zhao, S. Shan, and X. Chen. Semantic mismatch and perceptual degradation: A new perspective on image editing immunity.arXiv preprint arXiv:2512.14320, 2025. URL https://arxiv.org/abs/25 12.14320
arXiv 2025
-
[21]
J. C. Duchi, M. I. Jordan, M. J. Wainwright, and A. Wibisono. Optimal rates for zero-order convex opti- mization: The power of two function evaluations.IEEE Transactions on Information Theory, 61(5):2788–2806, 2015
2015
-
[22]
A. Fang, A. M. Jose, A. Jain, L. Schmidt, A. Toshev, and V . Shankar. Data filtering networks, 2023. URL https://arxiv.org/abs/2309.17425
arXiv 2023
-
[23]
J. Fu, S. Li, Y . Jiang, K.-Y . Lin, C. Qian, C. C. Loy, W. Wu, and Z. Liu. Stylegan-human: A data-centric odyssey of human generation, 2022. URL https://arxi v.org/abs/2204.11823
arXiv 2022
-
[24]
S. Y . Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyr- nis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhang, E. Orgad, R. Entezari, G. Daras, S. Pratt, V . Ramanujan, Y . Bitton, K. Marathe, S. Mussmann, R. Vencu, M. Cherti, R. Krishna, P. W. Koh, O. Saukh, A. Ratner, S. Song, H. Hajishirzi, A. Farhadi, R. Beau- mont, S. Oh, A. Dimakis, J. Jitsev, Y...
arXiv 2023
-
[25]
Gentleman
A. Gentleman. New claimants seek to sue Elon Musk’s xAI after Labour MP’s test case. https://www.th eguardian.com/technology/2026/jun/05/grok-ai-e lon-musk-jess-asato-labour-mp-lawsuit, June 2026. The Guardian. Additional reporting by Jessica Elgot. Accessed June 7, 2026
2026
-
[26]
I. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations (ICLR), 2015. URL https://arxiv.org/abs/1412.6572
Pith/arXiv arXiv 2015
-
[27]
Gemini API Additional Terms of Service
Google. Gemini API Additional Terms of Service. https://ai.google.dev/gemini-api/terms, Mar. 2026. Effective March 23, 2026. Accessed June 7, 2026
2026
-
[28]
Gemini 3.1 Flash Image (Nano Banana 2), 2026
Google DeepMind. Gemini 3.1 Flash Image (Nano Banana 2), 2026. https://deepmind.google/models/g emini-image/flash/
2026
-
[29]
Z. Guo, L. Fang, J. Lin, Y . Qian, S. Zhao, Z. Wang, J. Dong, C. Chen, O. Arandjelovi ´c, and C. P. Lau. A grey-box attack against latent diffusion model-based image editing by posterior collapse.arXiv preprint arXiv:2408.10901, 2024. URL https://arxiv.org/abs/24 08.10901
arXiv 2024
-
[30]
Ilyas, L
A. Ilyas, L. Engstrom, A. Athalye, and J. Lin. Black- box adversarial attacks with limited queries and in- formation. InInternational conference on machine learning, pages 2137–2146. PMLR, 2018
2018
-
[31]
X. Jia, S. Gao, S. Qin, T. Pang, C. Du, Y . Huang, X. Li, Y . Li, B. Li, and Y . Liu. Adversarial attacks against closed-source mllms via feature optimal alignment,
-
[32]
URL https://arxiv.org/abs/2505.21494
-
[33]
J. Kim, Y . Nam, M. Kim, S. Kim, and J. Jeong. BlurGuard: A simple approach for robustifying image protection against AI-powered editing. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=vritEZz28d
2025
-
[34]
D. C. Liu and J. Nocedal. On the limited memory bfgs method for large scale optimization.Mathematical Programming, 45:503–528, 1989
1989
-
[35]
Y . Liu, X. Chen, C. Liu, and D. Song. Delving into transferable adversarial examples and black-box attacks. InInternational Conference on Learning Rep- resentations (ICLR), 2017. URL https://arxiv.org/abs/ 1611.02770
Pith/arXiv arXiv 2017
-
[36]
L. Lo, C. Y . Yeo, H.-H. Shuai, and W.-H. Cheng. Distraction is all you need: Memory-efficient image immunization against diffusion-based image editing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 24462–24471, June 2024. URL https://openaccess.the cvf.com/content/CVPR2024/html/Lo Distraction is All Y...
2024
-
[37]
N. A. Lord, R. Mueller, and L. Bertinetto. Attacking deep networks with surrogate-based adversarial black- box methods is easy.arXiv preprint arXiv:2203.08725, 2022
arXiv 2022
-
[38]
Madry, A
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations (ICLR), 2018. URL https://openreview.net/forum?id=rJzIBfZAb
2018
-
[39]
Nasery, E
A. Nasery, E. Contente, A. Kaz, P. Viswanath, and S. Oh. Are robust llm fingerprints adversarially robust? arXiv e-prints, pages arXiv–2509, 2025
2025
-
[40]
Nasery, J
A. Nasery, J. Hayase, C. Brooks, P. Sheng, H. Tyagi, P. Viswanath, and S. Oh. Scalable fingerprinting of large language models.Advances in Neural Informa- tion Processing Systems, 38:125116–125152, 2026
2026
-
[41]
W. Nie, B. Guo, Y . Huang, C. Xiao, A. Vahdat, and A. Anandkumar. Diffusion models for adversarial purification. InInternational Conference on Machine Learning (ICML), 2022
2022
-
[42]
J. Nocedal. Updating quasi-newton matrices with limited storage.Mathematics of Computation, 35(151): 773–782, 1980
1980
-
[43]
N. C. of State Legislatures. Deepfakes in Elections and Campaigns. https://www.ncsl.org/elections-and-c ampaigns/artificial-intelligence-ai-in-elections-and-c ampaigns, June 2026
2026
-
[44]
GPT Image 2, 2026
Open AI. GPT Image 2, 2026. https://developers.ope nai.com/api/docs/guides/image-generation
2026
-
[45]
Usage Policies
OpenAI. Usage Policies. https://openai.com/policie s/usage-policies/, Oct. 2025. Effective October 29,
2025
-
[47]
omni-moderation Model
OpenAI. omni-moderation Model. https://developers .openai.com/api/docs/models/omni-moderation-latest,
-
[48]
Accessed: 2026- 06-08
OpenAI API documentation. Accessed: 2026- 06-08
2026
-
[49]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
Pith/arXiv arXiv 2024
-
[50]
T. C. Ozden, O. Kara, O. Akcin, K. Zaman, S. Srivastava, S. P. Chinchali, and J. M. Rehg. DiffVax: Optimization-free image immunization against diffusion-based editing. arXiv preprint arXiv:2411.17957, 2024. URL https://arxiv.org/abs/2411.17957
arXiv 2024
-
[51]
B. Perrigo. How to Spot an AI-Generated Image Like the ’Balenciaga Pope’. https://time.com/6266606/how -to-spot-deepfake-pope/, March 2023
arXiv 2023
-
[52]
X. Pleimling, S. M. Abdullah, G. Balde, P. Gao, M. Mondal, M. Jadliwala, and B. Viswanath. Off- the-shelf image-to-image models are all you need to defeat image protection schemes, 2026. URL https: //arxiv.org/abs/2602.22197
arXiv 2026
-
[53]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning trans- ferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[54]
Fact Check: Online posts reporting explosion near Pentagon on May 22, 2023 are false
Reuters. Fact Check: Online posts reporting explosion near Pentagon on May 22, 2023 are false. https://ww w.reuters.com/article/fact-check/online-posts-reporting -explosion-near-pentagon-on-may-22-2023-are-false -idUSL1N37J2QJ/, May 2023
2023
-
[55]
Grok’s AI image generation tool violated Canadian privacy law, watchdog says
Reuters. Grok’s AI image generation tool violated Canadian privacy law, watchdog says. https://www. reuters.com/business/media-telecom/groks-ai-image-g eneration-tool-violated-canadian-privacy-law-says-w atchdog-2026-06-11/, June 2026
2026
-
[56]
Ricker, D
J. Ricker, D. Assenmacher, T. Holz, A. Fischer, and E. Quiring. Ai-generated faces in the real world: A large-scale case study of twitter profile images. In Proceedings of the 27th International Symposium on Research in Attacks, Intrusions and Defenses, pages 513–530, 2024
2024
-
[57]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 10684–10695, June 2022. URL https://openaccess.thecvf.com/content/CVPR2022/htm l/Rombach High-Resolution Image Synthesis With Latent D...
2022
-
[58]
Salman, A
H. Salman, A. Khaddaj, G. Leclerc, A. Ilyas, and A. Madry. Raising the cost of malicious AI-powered image editing. InProceedings of the 40th Interna- tional Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 29894–29918. PMLR, 2023. URL https://proceeding s.mlr.press/v202/salman23a.html
2023
-
[59]
Satter and S
R. Satter and S. Tabahriti. Exclusive: Despite new curbs, Elon Musk’s Grok at times produces sexualized images - even when told subjects didn’t consent. https: //www.reuters.com/business/despite-new-curbs-elo n-musks-grok-times-produces-sexualized-images-eve n-when-2026-02-03/, February 2026
2026
-
[60]
Schaeffer, D
R. Schaeffer, D. Valentine, L. Bailey, J. Chua, C. Eyza- guirre, Z. Durante, J. Benton, B. Miranda, H. Sleight, T. Wang, et al. Failures to find transferable image jailbreaks between vision-language models. InIn- ternational Conference on Learning Representations, volume 2025, pages 44669–44704, 2025
2025
-
[61]
M. Schmidt, N. Le Roux, and F. Bach. Minimizing finite sums with the stochastic average gradient.Math- ematical Programming, 162(1–2):83–112, 2017. doi: 10.1007/s10107-016-1030-6
-
[62]
S. Shan, J. Cryan, E. Wenger, H. Zheng, R. Hanocka, and B. Y . Zhao. Glaze: Protecting artists from style mimicry by text-to-image models. In32nd USENIX Se- curity Symposium (USENIX Security 23), pages 2187–
-
[63]
URL https://www
USENIX Association, 2023. URL https://www. usenix.org/conference/usenixsecurity23/presentation/ shan
2023
-
[64]
S. Shan, W. Ding, J. Passananti, S. Wu, H. Zheng, and B. Y . Zhao. Nightshade: Prompt-specific poisoning attacks on text-to-image generative models. In2024 IEEE Symposium on Security and Privacy (SP), pages 807–825, 2024. doi: 10.1109/SP54263.2024.00207. URL https://arxiv.org/abs/2310.13828
-
[65]
Z. Shao, H. Liu, Y . Hu, and N. Z. Gong. Leave my images alone: Preventing multi-modal large language models from analyzing images via visual prompt in- jection.arXiv preprint arXiv:2604.09024, 2026
Pith/arXiv arXiv 2026
-
[66]
Sohl-Dickstein, B
J. Sohl-Dickstein, B. Poole, and S. Ganguli. Fast large- scale optimization by unifying stochastic gradient and quasi-newton methods. InInternational Conference on Machine Learning, 2014
2014
-
[67]
M. Sparks. Disney, NBC Universal, and DreamWorks File Major IP Lawsuit Against AI Image Generator Midjourney. https://www.law.georgetown.edu/tech-i nstitute/research-insights/insights/disney-nbc-univers al-and-dreamworks-file-major-ip-lawsuit-against-ai-i mage-generator-midjourney/, June 2025. Institute for Technology Law & Policy, Georgetown Law. Accesse...
2025
-
[68]
C.-C. Tu, P. Ting, P.-Y . Chen, S. Liu, H. Zhang, J. Yi, C.-J. Hsieh, and S.-M. Cheng. Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. InProceed- ings of the AAAI conference on artificial intelligence, volume 33, pages 742–749, 2019
2019
-
[69]
xAI Acceptable Use Policy
xAI. xAI Acceptable Use Policy. https://x.ai/legal/a cceptable-use-policy, Jan. 2025. Effective January 2,
2025
-
[70]
Accessed June 7, 2026
2026
-
[71]
Grok Imagine API, 2026
xAI. Grok Imagine API, 2026. https://x.ai/news/grok -imagine-api
2026
-
[72]
J. Xu, F. Wang, M. Ma, P. W. Koh, C. Xiao, and M. Chen. Instructional fingerprinting of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3277–3306, 2024
2024
-
[73]
Y . Ye, X. He, Z. Li, S. Yuan, Z. Yan, B. Hou, L. Yuan, et al. Imgedit: A unified image editing dataset and benchmark.Advances in Neural Information Process- ing Systems, 38, 2026
2026
-
[74]
W. Zeng, D. Kurniawan, R. Mullins, Y . Liu, T. Saha, D. Ike-Njoku, J. Gu, Y . Song, C. Xu, J. Zhou, A. Joshi, S. Dheep, M. Malek, H. Palangi, J. Baek, R. Pereira, and K. Narasimhan. Shieldgemma 2: Robust and tractable image content moderation, 2025. URL https: //arxiv.org/abs/2504.01081
arXiv 2025
-
[75]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986, October
-
[76]
URL https://openaccess.thecvf.com/content/IC CV2023/html/Zhai Sigmoid Loss for Language Ima ge Pre-Training ICCV 2023 paper.html
2023
-
[77]
Zhang, Z
J. Zhang, Z. Gu, J. Jang, H. Wu, M. P. Stoecklin, H. Huang, and I. Molloy. Protecting intellectual prop- erty of deep neural networks with watermarking. In Proceedings of the 2018 on Asia conference on com- puter and communications security, pages 159–172, 2018
2018
- [78]
-
[79]
Zhang, S
J. Zhang, S. Dong, S. Shan, and X. Chen. Towards transferable defense against malicious image edits. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. URL https://www.computer.org/c sdl/journal/tp/5555/01/11421009/2eApjoNgEve. Early Access / PrePrints
2026
-
[80]
Zhang, P
J. Zhang, P. Peetathawatchai, F. Tram `er, and A. Shafran. Laundering ai authority with adversarial examples, 2026. URL https://arxiv.org/abs/2605.042 61
2026
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.