Deep Learning-based Algebraic Reynolds Stress Closures for RANS Simulations of Turbulent Flows
Pith reviewed 2026-06-29 20:05 UTC · model grok-4.3
The pith
A neural network embedded in an algebraic Reynolds stress equation improves RANS velocity predictions by 2-4 times on average and generalizes from attached to separated flows without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
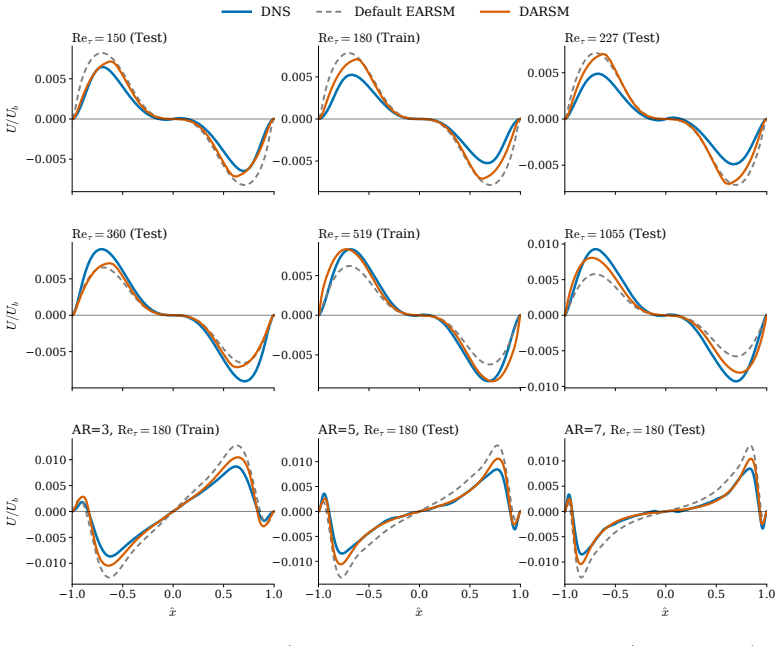
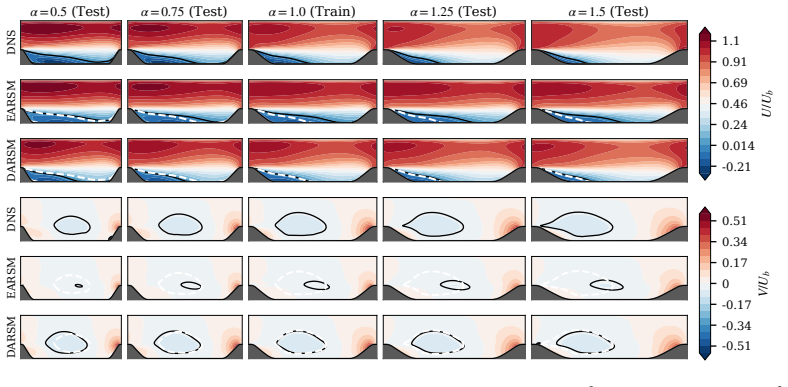
DARSM trains a neural network to supply empirical coefficients inside an implicit algebraic Reynolds stress relation obtained from the full transport equations under the weak-equilibrium assumption; end-to-end differentiation through the coupled RANS solver via custom adjoint equations removes distribution shift, yielding 2-4 times lower average velocity error than baseline RANS on both square-duct and periodic-hill benchmarks while generalizing from attached to separated regimes without retraining.
What carries the argument
The Deep Algebraic Reynolds Stress Model (DARSM), a neural network that supplies parameters to an implicit algebraic Reynolds stress equation derived under the weak-equilibrium assumption, optimized through the governing PDEs with adjoint equations that exploit the solver's implicit-explicit structure.
If this is right
- RANS simulations of attached and mildly separated turbulent flows can achieve 2-4 times lower average velocity error with a single trained DARSM model.
- A model trained exclusively on square-duct data transfers directly to periodic-hill flows without retraining, indicating regime-level generalization.
- End-to-end optimization through the coupled implicit closure eliminates the distribution shift that affects offline-trained ML closures.
- DARSM outperforms offline training, tensor-basis networks, field-inversion methods, DeepONets, and physics-informed networks on the same benchmarks.
- The approach requires only small high-fidelity datasets because the algebraic structure supplies most of the physics.
Where Pith is reading between the lines
- The same hybrid structure could be tested on other RANS closures that admit algebraic reductions, such as scalar-flux or heat-transfer models.
- If the weak-equilibrium assumption holds across a wider class of engineering flows, DARSM-style models might reduce the need for full Reynolds-stress transport simulations in many industrial cases.
- The adjoint derivation technique may apply to other stiff implicit-explicit solvers in computational fluid dynamics where direct differentiation fails.
Load-bearing premise
The weak-equilibrium assumption used to collapse the Reynolds stress transport equations into an implicit algebraic form stays accurate enough for the attached duct flows in training and the separated hill flows in testing.
What would settle it
Measure whether DARSM still reduces velocity error by at least 2 times relative to baseline RANS when applied to a new separated flow geometry whose mean-flow statistics visibly violate the weak-equilibrium assumption.
Figures

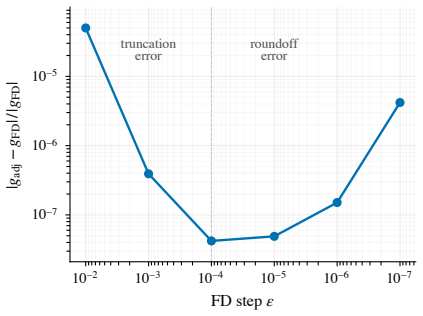
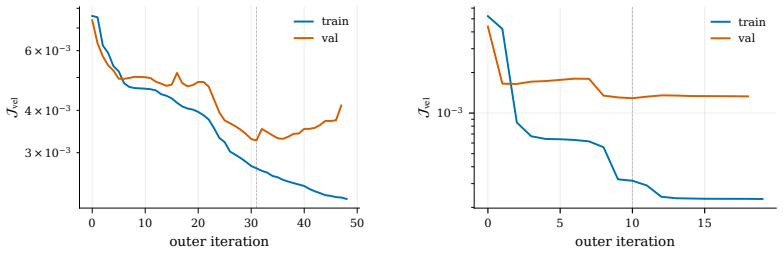
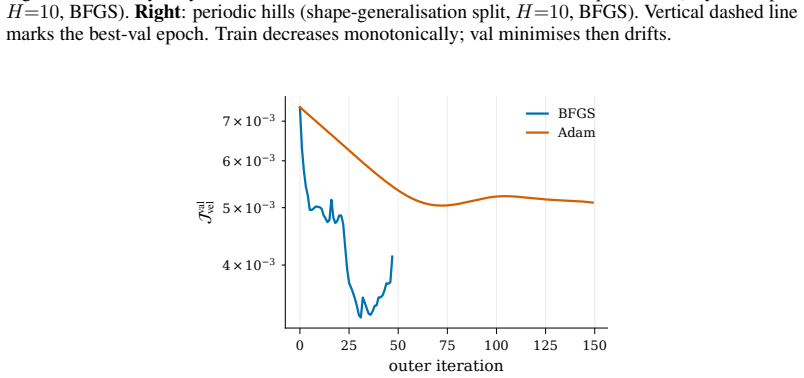

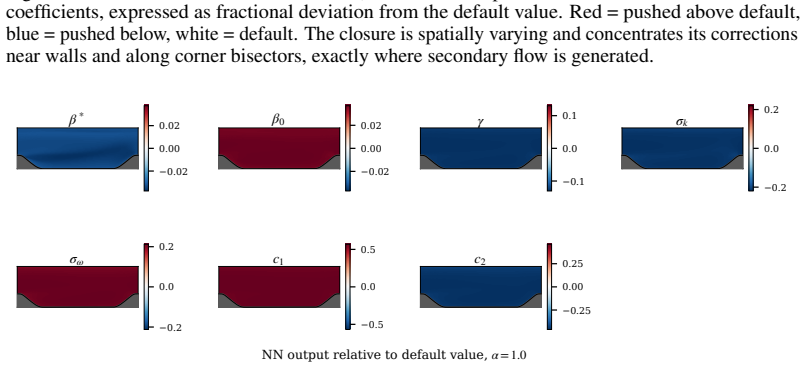
read the original abstract
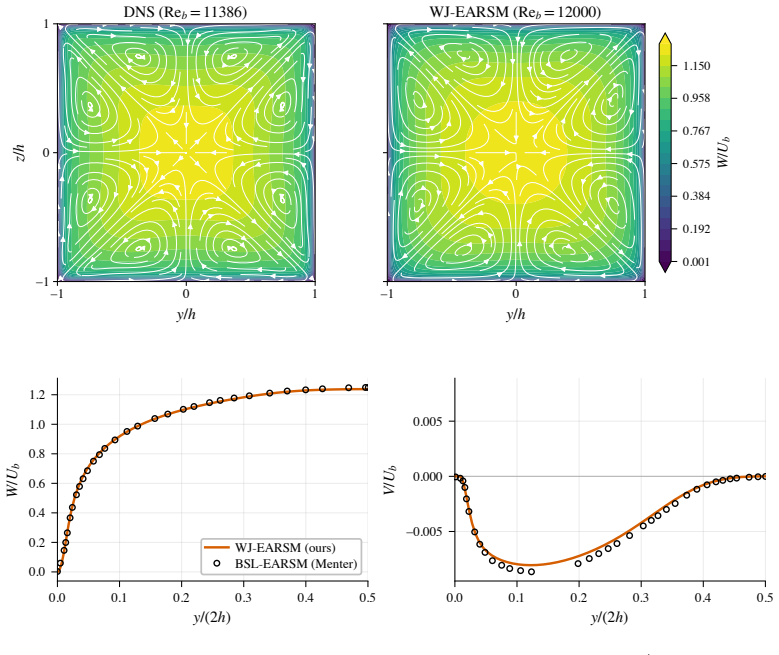
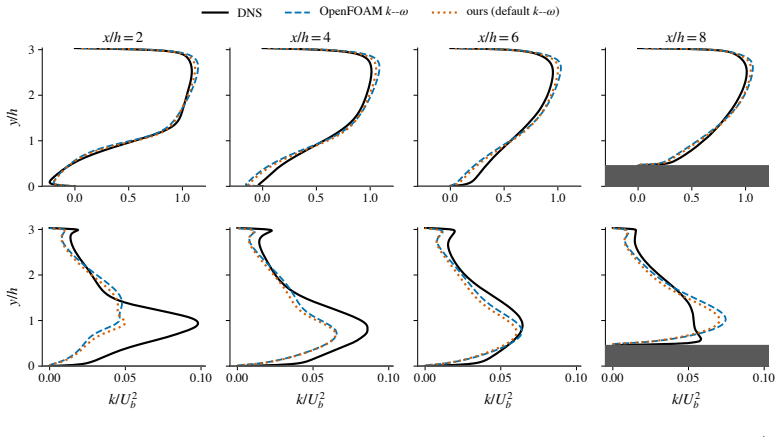
Turbulence is ubiquitous in engineering and science, yet direct simulation is prohibitively expensive. The Reynolds-averaged Navier-Stokes (RANS) equations provide savings exceeding ten orders of magnitude but introduce unclosed terms (the closure problem). Offline-trained machine-learning (ML) closures suffer distribution shift in predictive simulations, while ML methods that bypass the governing equations struggle to generalise from scarce high-fidelity data. We develop a physics-derived deep learning closure model for RANS, the Deep Algebraic Reynolds Stress Model (DARSM), which can be trained on small datasets and accurately generalise across Reynolds numbers, to unseen geometries, and to different flow regimes. A neural network maps flow invariants to empirical parameters in an implicit algebraic Reynolds stress equation, derived from the Reynolds stress transport equations under the weak-equilibrium assumption, imposing physics-based structure on the ML closure. End-to-end optimisation through the governing PDEs and the coupled implicit closure eliminates distribution shift, but both unrolled and implicit automatic differentiation fail on the stiff coupled solver. We derive adjoint equations that exploit the solver's implicit-explicit structure for efficient optimisation. On canonical square-duct and periodic-hill benchmarks, DARSM reduces average test velocity error over baseline RANS by $2$-$4\times$ across Reynolds number, geometries, and flow regimes, with peak case-level reductions of $12\times$. The model trained on attached, anisotropy-dominated flows (square duct) accurately generalises without retraining to separated flows (periodic hills), a regime change in the underlying physics. DARSM also outperforms five established ML methods: offline training, tensor-basis neural networks, field-inversion machine learning, DeepONets, and physics-informed neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Deep Algebraic Reynolds Stress Model (DARSM), which embeds a neural network inside an implicit algebraic Reynolds stress closure derived from the Reynolds stress transport equations under the weak-equilibrium assumption. A NN maps invariants to closure coefficients; the model is trained end-to-end by minimizing the RANS residual on square-duct data and is reported to generalize without retraining to periodic-hill flows, yielding 2–4× average velocity-error reductions (peak 12×) relative to baseline RANS while outperforming five other ML closures.
Significance. If the cross-regime generalization holds, the work would be significant for turbulence modeling: it supplies a physics-structured algebraic form that mitigates distribution shift, demonstrates training on small attached-flow datasets, and introduces an adjoint formulation that exploits the implicit-explicit solver structure for efficient optimization. These elements address long-standing obstacles in ML-RANS closures.
major comments (3)
- [abstract and benchmark results] The headline generalization claim (abstract) that a model trained only on attached square-duct flows accurately predicts separated periodic-hill flows rests on the weak-equilibrium assumption remaining valid in the separation bubble. No direct comparison of the resulting algebraic Reynolds stresses against either full Reynolds-stress transport solutions or DNS data is supplied for the hill geometry, leaving open the possibility that observed velocity improvements arise from other factors rather than the structured ML closure.
- [abstract and evaluation sections] Quantitative performance statements (2–4× average error reduction, 12× peak) are given without reported error bars, explicit train/test splits, baseline implementation details, or sensitivity tests to the weak-equilibrium assumption (abstract). These omissions make it impossible to judge whether the reported gains are statistically robust or sensitive to the regime change.
- [model derivation] The derivation of the implicit algebraic form (via weak equilibrium) is presented as the key physics constraint, yet the manuscript does not quantify the magnitude of the neglected convective and diffusive terms in the periodic-hill separation region; if those terms are O(1) relative to production and pressure-strain, the algebraic closure itself becomes inconsistent with the underlying transport equations in the test regime.
minor comments (2)
- [model formulation] Notation for the invariants and the neural-network output coefficients should be unified between the derivation and the results tables to avoid reader confusion.
- [figures] Figure captions for the velocity and stress profiles should explicitly state the Reynolds numbers and the precise definition of the reported error norms.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments raise important points on validation of the weak-equilibrium assumption, statistical robustness, and consistency of the algebraic closure. We respond point-by-point below and will make revisions to address the concerns.
read point-by-point responses
-
Referee: [abstract and benchmark results] The headline generalization claim (abstract) that a model trained only on attached square-duct flows accurately predicts separated periodic-hill flows rests on the weak-equilibrium assumption remaining valid in the separation bubble. No direct comparison of the resulting algebraic Reynolds stresses against either full Reynolds-stress transport solutions or DNS data is supplied for the hill geometry, leaving open the possibility that observed velocity improvements arise from other factors rather than the structured ML closure.
Authors: We agree that a direct comparison of the modeled algebraic Reynolds stresses to DNS data on the periodic hill would strengthen the evidence that improvements stem from the structured closure rather than other factors. While mean-velocity accuracy is the primary RANS objective and our cross-method comparisons support the claim, we will add a new subsection and figure comparing predicted Reynolds-stress components against available DNS data in the separation region. revision: yes
-
Referee: [abstract and evaluation sections] Quantitative performance statements (2–4× average error reduction, 12× peak) are given without reported error bars, explicit train/test splits, baseline implementation details, or sensitivity tests to the weak-equilibrium assumption (abstract). These omissions make it impossible to judge whether the reported gains are statistically robust or sensitive to the regime change.
Authors: The reported benchmarks are deterministic fixed-mesh simulations, so ensemble-based error bars do not apply. We will expand the evaluation section to explicitly document the train/test splits (square-duct cases for training, periodic-hill cases for testing), provide full baseline implementation details and references, and include a sensitivity analysis to the weak-equilibrium assumption by comparing results with and without selected neglected terms. revision: yes
-
Referee: [model derivation] The derivation of the implicit algebraic form (via weak equilibrium) is presented as the key physics constraint, yet the manuscript does not quantify the magnitude of the neglected convective and diffusive terms in the periodic-hill separation region; if those terms are O(1) relative to production and pressure-strain, the algebraic closure itself becomes inconsistent with the underlying transport equations in the test regime.
Authors: We concur that quantifying the neglected terms is necessary to evaluate consistency of the algebraic form in the separated regime. Using the DNS data already employed for the periodic-hill benchmark, we will compute and report the relative magnitudes of convective, diffusive, and production/pressure-strain terms inside the separation bubble and discuss implications for the weak-equilibrium assumption. revision: yes
Circularity Check
No significant circularity; derivation uses external modeling assumption and cross-regime test
full rationale
The algebraic form is obtained by applying the weak-equilibrium assumption to the Reynolds stress transport equations, a standard external modeling step not derived from the present data or NN. The NN maps invariants to coefficients and is trained on square-duct flows then evaluated on periodic-hill flows (different geometry and regime), so the reported generalization is not forced by construction. No self-citation chain, fitted-input-as-prediction, or renaming of known results appears in the provided text. The end-to-end PDE optimization is the intended training procedure rather than a tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights and biases
axioms (1)
- domain assumption Weak-equilibrium assumption
Reference graph
Works this paper leans on
-
[1]
A probabilistic, data-driven closure model for RANS simulations with aleatoric, model uncertainty
Atul Agrawal and Phaedon-Stelios Koutsourelakis. A probabilistic, data-driven closure model for RANS simulations with aleatoric, model uncertainty. Journal of Computational Physics, 508: 0 113024, 2024
2024
-
[2]
Albring, Max Sagebaum, and Nicolas R
Tim A. Albring, Max Sagebaum, and Nicolas R. Gauger. Development of a consistent discrete adjoint solver in an evolving aerodynamic design framework. In 16th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, page 3240, 2015
2015
-
[3]
Breuer, N
M. Breuer, N. Peller, Ch. Rapp, and M. Manhart. Flow over periodic hills -- numerical and experimental study in a wide range of R eynolds numbers. Computers & Fluids, 38 0 (2): 0 433--457, 2009
2009
-
[4]
T. J. Craft, B. E. Launder, and K. Suga. Development and application of a cubic eddy-viscosity model of turbulence. International Journal of Heat and Fluid Flow, 17 0 (2): 0 108--115, 1996. doi:10.1016/0142-727X(95)00079-6
-
[5]
Daniel Dehtyriov, Jonathan F. MacArt, and Justin Sirignano. oRANS: Online optimisation of RANS machine learning model with embedded DNS data generation . arXiv preprint arXiv:2510.02982, 2024
arXiv 2024
-
[6]
Turbulence modeling in the age of data
Karthik Duraisamy, Gianluca Iaccarino, and Heng Xiao. Turbulence modeling in the age of data. Annual Review of Fluid Mechanics, 51: 0 357--377, 2019
2019
-
[7]
Yuan Fang, Yaomin Zhao, Fabian Waschkowski, Andrew S. H. Ooi, and Richard D. Sandberg. Toward more general turbulence models via multicase computational-fluid-dynamics-driven training. AIAA Journal, 61 0 (5): 0 2100--2115, 2023
2023
-
[8]
Ferziger and Milovan Peri \'c
Joel H. Ferziger and Milovan Peri \'c . Computational Methods for Fluid Dynamics. Springer, 3rd edition, 2002
2002
-
[9]
A posteriori learning for quasi-geostrophic turbulence parametrization
Hugo Frezat, Julien Le Sommer, Ronan Fablet, Guillaume Balarac, and Redouane Lguensat. A posteriori learning for quasi-geostrophic turbulence parametrization. Journal of Advances in Modeling Earth Systems, 14 0 (11): 0 e2022MS003124, 2022
2022
-
[10]
An introduction to the adjoint approach to design
Michael B Giles and Niles A Pierce. An introduction to the adjoint approach to design. Flow, Turbulence and Combustion, 65 0 (3): 0 393--415, 2000
2000
-
[11]
Learning to control PDE s with differentiable physics
Philipp Holl, Vladlen Koltun, and Nils Thuerey. Learning to control PDE s with differentiable physics. In International Conference on Learning Representations, 2020
2020
-
[12]
Holland, James D
Jonathan R. Holland, James D. Baeder, and Karthik Duraisamy. Towards integrated field inversion and machine learning with embedded neural networks for RANS modeling. In AIAA Scitech 2019 Forum, page 1884, 2019
2019
-
[13]
Aerodynamic design via control theory
Antony Jameson. Aerodynamic design via control theory. Journal of Scientific Computing, 3 0 (3): 0 233--260, 1988
1988
-
[14]
Stiff-PINN : Physics-informed neural network for stiff chemical kinetics
Weiqi Ji, Weilun Qiu, Zhiyu Shi, Shaowu Pan, and Sili Deng. Stiff-PINN : Physics-informed neural network for stiff chemical kinetics. The Journal of Physical Chemistry A, 125 0 (36): 0 8098--8106, 2021
2021
-
[15]
Neural network-augmented eddy viscosity closures for turbulent premixed jet flames
Priyesh Kakka and Jonathan F MacArt. Neural network-augmented eddy viscosity closures for turbulent premixed jet flames. Combustion and Flame, 278: 0 114241, 2025
2025
-
[16]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. International Conference on Learning Representations, 2015
2015
-
[17]
Machine learning--accelerated computational fluid dynamics
Dmitrii Kochkov, Jamie A Smith, Ayya Alieva, Qing Wang, Michael P Brenner, and Stephan Hoyer. Machine learning--accelerated computational fluid dynamics. Proceedings of the National Academy of Sciences, 118 0 (21), 2021
2021
-
[18]
Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W
Aditi S. Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W. Mahoney. Characterizing possible failure modes in physics-informed neural networks. In Advances in Neural Information Processing Systems, 2021
2021
-
[19]
B. E. Launder, G. J. Reece, and W. Rodi. Progress in the development of a R eynolds-stress turbulence closure. Journal of Fluid Mechanics, 68 0 (3): 0 537--566, 1975. doi:10.1017/S0022112075001814
-
[20]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhatt, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2021
2021
-
[21]
Reynolds averaged turbulence modelling using deep neural networks with embedded invariance
Julia Ling, Andrew Kurzawski, and Jeremy Templeton. Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. Journal of Fluid Mechanics, 807: 0 155--166, 2016
2016
-
[22]
Björn List, Li-Wei Chen, and Nils Thuerey. Learned turbulence modelling with differentiable fluid solvers: physics-based loss functions and optimisation horizons. Journal of Fluid Mechanics, 949: 0 A25, 2022. doi:10.1017/jfm.2022.738
-
[23]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3 0 (3): 0 218--229, 2021
2021
-
[24]
Warp: A python framework for high-performance GPU simulation and graphics, 2022
Miles Macklin. Warp: A python framework for high-performance GPU simulation and graphics, 2022. URL https://github.com/NVIDIA/warp. NVIDIA
2022
-
[25]
Menter, F. R. , Garbaruk, A. V. , and Egorov, Y. Explicit algebraic reynolds stress models for anisotropic wall-bounded flows, 2012. URL https://doi.org/10.1051/eucass/201203089
-
[26]
Jorge Nocedal and Stephen J. Wright. Numerical Optimization. Springer, 2nd edition, 2006
2006
-
[27]
Automating turbulence modelling by multi-agent reinforcement learning
Guido Novati, Hugues Lascombes de Laroussilhe, and Petros Koumoutsakos. Automating turbulence modelling by multi-agent reinforcement learning. Nature Machine Intelligence, 3 0 (1): 0 87--96, 2021. doi:10.1038/s42256-020-00272-0
-
[28]
A paradigm for data-driven predictive modeling using field inversion and machine learning
Eric J Parish and Karthik Duraisamy. A paradigm for data-driven predictive modeling using field inversion and machine learning. Journal of Computational Physics, 305: 0 758--774, 2016
2016
-
[29]
Turbulence and secondary motions in square duct flow
Sergio Pirozzoli, Davide Modesti, Paolo Orlandi, and Francesco Grasso. Turbulence and secondary motions in square duct flow. Journal of Fluid Mechanics, 840: 0 631--655, 2018
2018
-
[30]
Stephen B. Pope. A more general effective-viscosity hypothesis. Journal of Fluid Mechanics, 72 0 (2): 0 331--340, 1975
1975
-
[31]
Stephen B. Pope. Turbulent Flows. Cambridge University Press, 2000. doi:10.1017/CBO9780511840531
-
[32]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378: 0 686--707, 2019
2019
-
[33]
Global convergence of adjoint-optimized neural pdes
Konstantin Riedl, Justin Sirignano, and Konstantinos Spiliopoulos. Global convergence of adjoint-optimized neural pdes. Journal of Machine Learning Research, 26 0 (295): 0 1--94, 2025. URL http://jmlr.org/papers/v26/25-1383.html
2025
-
[34]
W. Rodi. A new algebraic relation for calculating the Reynolds stresses. ZAMM - Zeitschrift f \"u r Angewandte Mathematik und Mechanik , 56 0 (S1): 0 T219--T221, 1976
1976
-
[35]
J. C. Rotta. Statistische theorie nichthomogener turbulenz. Zeitschrift f \"u r Physik , 129 0 (6): 0 547--572, 1951. doi:10.1007/BF01330059
-
[36]
Iterative Methods for Sparse Linear Systems
Yousef Saad. Iterative Methods for Sparse Linear Systems. SIAM, 2nd edition, 2003
2003
-
[37]
Benjamin Sanderse, Panos Stinis, Romit Maulik, and Shady E. Ahmed. Scientific machine learning for closure models in multiscale problems: A review. Foundations of Data Science, 7 0 (1): 0 298--337, 2025. doi:10.3934/fods.2024043
-
[38]
Martin Schmelzer, Richard P. Dwight, and Paola Cinnella. Discovery of algebraic Reynolds-Stress models using sparse symbolic regression. Flow, Turbulence and Combustion, 104 0 (2): 0 579--603, 2020. doi:10.1007/s10494-019-00089-x
-
[39]
Differentiable turbulence: Closure as a partial differential equation constrained optimization
Varun Shankar, Dibyajyoti Chakraborty, Venkatasubramanian Viswanathan, and Romit Maulik. Differentiable turbulence: Closure as a partial differential equation constrained optimization. arXiv preprint arXiv:2307.03683, 2023
arXiv 2023
-
[40]
DPM : A deep learning pde augmentation method with application to large-eddy simulation
Justin Sirignano, Jonathan F MacArt, and Jonathan B Freund. DPM : A deep learning pde augmentation method with application to large-eddy simulation. Journal of Computational Physics, 423: 0 109811, 2020
2020
-
[41]
MacArt, and Konstantinos Spiliopoulos
Justin Sirignano, Jonathan F. MacArt, and Konstantinos Spiliopoulos. PDE -constrained models with neural network terms: Optimization and global convergence. Journal of Computational Physics, 481: 0 112016, 2023
2023
-
[42]
Michel \'e n Str \"o fer and Heng Xiao
Carlos A. Michel \'e n Str \"o fer and Heng Xiao. End-to-end differentiable learning of turbulence models from indirect observations. Theoretical and Applied Mechanics Letters, 11 0 (4): 0 100280, 2021
2021
-
[43]
Solver-in-the-loop: Learning from differentiable physics to interact with iterative PDE -solvers
Kiwon Um, Robert Brand, Yun Raymond Fei, Philipp Holl, and Nils Thuerey. Solver-in-the-loop: Learning from differentiable physics to interact with iterative PDE -solvers. In Advances in Neural Information Processing Systems, volume 33, 2020
2020
-
[44]
Vinuesa, P
R. Vinuesa, P. Schlatter, and H. M. Nagib. Secondary flow in turbulent ducts with increasing aspect ratio. Phys. Rev. Fluids, 3: 0 054606, 2018
2018
-
[45]
An explicit algebraic Reynolds stress model for incompressible and compressible turbulent flows
Stefan Wallin and Arne V Johansson. An explicit algebraic Reynolds stress model for incompressible and compressible turbulent flows. Journal of Fluid Mechanics, 403: 0 89--132, 2000
2000
-
[46]
When and why PINNs fail to train: A neural tangent kernel perspective
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective. Journal of Computational Physics, 449: 0 110768, 2022
2022
-
[47]
Weatheritt and R.D
J. Weatheritt and R.D. Sandberg. The development of algebraic stress models using a novel evolutionary algorithm. International Journal of Heat and Fluid Flow, 68: 0 298--318, 2017
2017
-
[48]
Reassessment of the scale-determining equation for advanced turbulence models
David C Wilcox. Reassessment of the scale-determining equation for advanced turbulence models. AIAA Journal, 26 0 (11): 0 1299--1310, 1988
1988
-
[49]
Jinlong Wu, Heng Xiao, Rui Sun, and Qiqi Wang. Reynolds-averaged navier--stokes equations with explicit data-driven reynolds stress closure can be ill-conditioned. Journal of Fluid Mechanics, 869: 0 553--586, 2019. doi:10.1017/jfm.2019.205
-
[50]
Flows over periodic hills of parameterized geometries: A dataset for data-driven turbulence modeling from direct simulations
Heng Xiao, Jin-Long Wu, Sylvain Laizet, and Lian Duan. Flows over periodic hills of parameterized geometries: A dataset for data-driven turbulence modeling from direct simulations. Computers & Fluids, 200: 0 104431, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.