Depth Exploration for LLM Decoding
Pith reviewed 2026-06-30 08:41 UTC · model grok-4.3
The pith
DEX replaces single-depth selection with parallel exploration over multiple candidate depths to reduce per-token computation while producing identical outputs to standard autoregressive decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
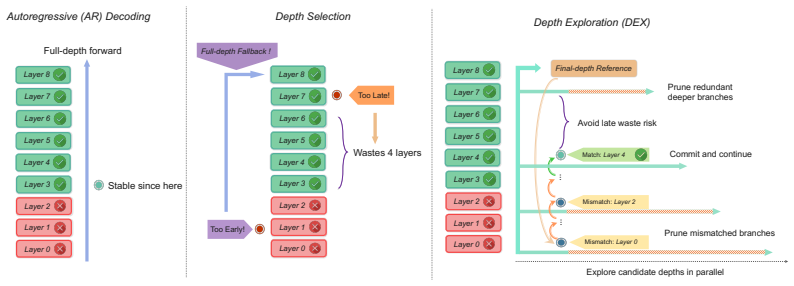
DEX is a lossless decoding algorithm that replaces single-depth selection with parallel exploration over multiple candidate depths. At each commit position, DEX validates candidates against the final-depth reference, commits exactly the final-depth token, and collapses the exploration lattice to retain only reusable branch states. This procedure preserves equivalence to standard autoregressive decoding while reducing the cost of committing each token.
What carries the argument
The expand-commit-collapse procedure operating on an exploration lattice of candidate depth branches.
If this is right
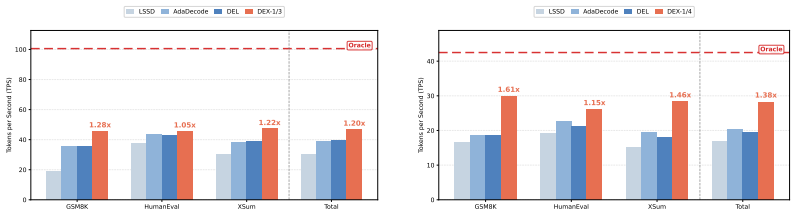
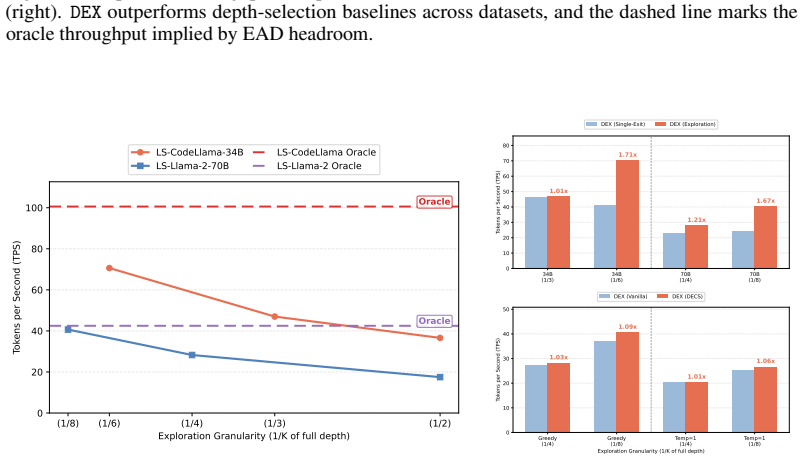
- DEX outperforms representative depth-selection baselines across both early-exit-trained and standard LLMs.
- End-to-end throughput becomes competitive with speculative and distributed decoding methods.
- Performance improves as the explored depths become finer.
- Parallel depth exploration provides a scalable way to exploit the underused depth axis of LLM decoding.
Where Pith is reading between the lines
- The lattice-collapse step could be adapted to manage state in other parallel inference techniques such as tree-based speculative decoding.
- Hardware accelerators that evaluate multiple layer depths concurrently might multiply the observed savings.
- Similar exploration strategies might apply to other redundant axes like attention head count or KV-cache reuse.
- Finer depth grids could be used to identify model-specific sweet spots for the width of exploration.
Load-bearing premise
The expand-commit-collapse procedure can be implemented with net savings while preserving exact equivalence to standard autoregressive decoding.
What would settle it
A direct measurement of average compute per generated token showing DEX requires more operations than vanilla full-depth autoregressive decoding on the same model and inputs would falsify the efficiency claim.
Figures


read the original abstract
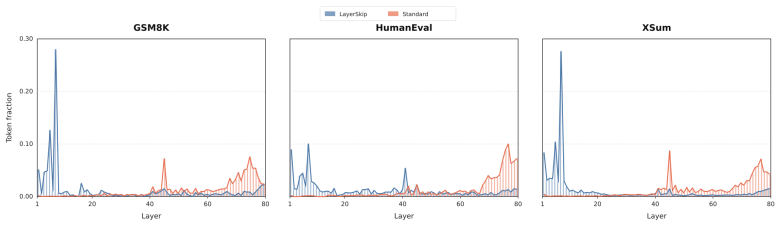
Autoregressive LLM decoding evaluates every generated token through the full layer stack, even though many tokens become predictable at intermediate depths. Existing lossless depth-adaptive methods exploit this redundancy by choosing a single non-final exit depth and verifying its prediction with the final-depth model. However, our measurements show that this selection-based strategy leaves substantial headroom: choosing an exit too late wastes computation, while choosing one too early triggers fallback and discards dependent drafts. We propose Depth Exploration Decoding (DEX), a lossless decoding algorithm that replaces single-depth selection with parallel exploration over multiple candidate depths. At each commit position, DEX validates candidates against the final-depth reference, commits exactly the final-depth token, and collapses the exploration lattice to retain only reusable branch states. This expand--commit--collapse procedure preserves equivalence to standard autoregressive decoding while reducing the cost of committing each token. Across early-exit-trained and standard LLMs, DEX outperforms representative depth-selection baselines and achieves competitive end-to-end throughput against speculative and distributed decoding methods. Moreover, DEX improves as the explored depths become finer, showing that parallel depth exploration provides a scalable way to exploit the underused depth axis of LLM decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Depth Exploration Decoding (DEX), a lossless algorithm for LLM decoding that replaces single-depth selection with parallel exploration over multiple candidate depths. It uses an expand-commit-collapse procedure to validate candidates against the final-depth reference, commit the final-depth token, and collapse the exploration lattice, preserving equivalence to standard autoregressive decoding while reducing computation cost. The paper claims that DEX outperforms depth-selection baselines, achieves competitive throughput against speculative and distributed methods, and improves with finer depth exploration across early-exit-trained and standard LLMs.
Significance. If the empirical results hold, this work demonstrates a scalable approach to exploiting the depth dimension in LLM inference, which has been underused. The preservation of exact equivalence is a strength, and the improvement with finer depths suggests potential for further gains. It positions parallel depth exploration as a viable alternative or complement to existing acceleration techniques.
major comments (2)
- [Abstract] Abstract: the claim that 'our measurements show that this selection-based strategy leaves substantial headroom' and that DEX 'outperforms representative depth-selection baselines' is load-bearing for the central contribution, yet the abstract provides no quantitative results, model sizes, datasets, or error bars; the full experimental section must supply these to substantiate the headroom and outperformance assertions.
- [Algorithm description (likely §3)] The expand--commit--collapse procedure is asserted to preserve exact equivalence to autoregressive decoding, but the manuscript must demonstrate (e.g., via an invariant or small example in the algorithm section) that the collapse step never discards states required for future tokens, as any hidden recomputation would undermine the claimed net savings.
minor comments (2)
- The abstract states DEX 'improves as the explored depths become finer' but does not define the granularity schedule or the set of depths tested; this should be stated explicitly with a table or figure reference for reproducibility.
- Comparison tables against speculative and distributed decoding should report both latency and throughput with the same batch size and hardware to allow direct assessment of the 'competitive end-to-end throughput' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'our measurements show that this selection-based strategy leaves substantial headroom' and that DEX 'outperforms representative depth-selection baselines' is load-bearing for the central contribution, yet the abstract provides no quantitative results, model sizes, datasets, or error bars; the full experimental section must supply these to substantiate the headroom and outperformance assertions.
Authors: We agree that the abstract would benefit from concrete quantitative support for the central claims. The experimental section already reports results across multiple model sizes, datasets, and baselines with the requested details (including error bars where applicable). We will revise the abstract to include a small number of representative quantitative findings that directly substantiate the headroom and outperformance statements. revision: yes
-
Referee: [Algorithm description (likely §3)] The expand--commit--collapse procedure is asserted to preserve exact equivalence to autoregressive decoding, but the manuscript must demonstrate (e.g., via an invariant or small example in the algorithm section) that the collapse step never discards states required for future tokens, as any hidden recomputation would undermine the claimed net savings.
Authors: We accept the request for an explicit demonstration. In the revised manuscript we will add both a short worked example (on a 4-token toy sequence) and a formal invariant in §3: after each collapse, the retained states are exactly the prefixes up to the committed token that were validated at final depth; all future-token dependencies are therefore preserved without requiring recomputation. This addition will make the equivalence argument self-contained. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an algorithmic procedure (expand-commit-collapse) for depth-adaptive LLM decoding and reports empirical throughput measurements against baselines. No equations, first-principles derivations, or predictions appear in the supplied text; the central claim is that the procedure preserves exact autoregressive equivalence while reducing per-token cost, which is asserted as a property of the algorithm itself rather than derived from fitted parameters or self-referential definitions. No self-citations are invoked as load-bearing uniqueness theorems, and the measurements are presented as external validation rather than internal fits renamed as predictions. The derivation chain is therefore self-contained as an engineering proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Schlank, Gabriel Stanovsky, and Ariel Goldstein
Daria Lioubashevski, Tomer M. Schlank, Gabriel Stanovsky, and Ariel Goldstein. Looking beyond the top-1: Transformers determine top tokens in order. InForty-second Interna- tional Conference on Machine Learning, 2025. URL https://openreview.net/forum? id=2B11W1Z6ID
2025
-
[2]
Do language models use their depth efficiently? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
Róbert Csordás, Christopher D Manning, and Christopher Potts. Do language models use their depth efficiently? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=Kz6eUL86XP
2026
-
[3]
Depth-adaptive transformer
Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer. In International Conference on Learning Representations, 2020. URL https://openreview. net/forum?id=SJg7KhVKPH
2020
-
[4]
Tran, Yi Tay, and Donald Metzler
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URLhttps://openreview.net/forum?id=uLYc4L3C81A
2022
-
[5]
EE-LLM: Large-scale training and inference of early-exit large language models with 3d parallelism
Yanxi Chen, Xuchen Pan, Yaliang Li, Bolin Ding, and Jingren Zhou. EE-LLM: Large-scale training and inference of early-exit large language models with 3d parallelism. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/ forum?id=xFk0w9zoV3
2024
-
[6]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[7]
LayerSkip: Enabling early exit inference and self-speculative decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed Aly, Beidi Chen, and Carole-Jean Wu. LayerSkip: Enabling early exit inference and self-speculative decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual M...
-
[8]
Zhepei Wei, Wei-Lin Chen, Xinyu Zhu, and Yu Meng. Adadecode: Accelerating llm decoding with adaptive layer parallelism.arXiv preprint arXiv:2506.03700, 2025
-
[9]
DEL: Context-aware dynamic exit layer for efficient self-speculative decoding
Hossein Entezari Zarch, Lei Gao, Chaoyi Jiang, and Murali Annavaram. DEL: Context-aware dynamic exit layer for efficient self-speculative decoding. InSecond Conference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=cAFxSuXQvT
2025
-
[10]
Weinberger and J
A. Weinberger and J. L. Smith. A logic for high-speed addition.National Bureau of Standards Circular, 591:3–12, 1958
1958
-
[11]
A parallel algorithm for the efficient solution of a general class of recurrence equations.IEEE transactions on computers, 100(8):786–793, 1973
Peter M Kogge and Harold S Stone. A parallel algorithm for the efficient solution of a general class of recurrence equations.IEEE transactions on computers, 100(8):786–793, 1973
1973
-
[12]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. InInternational Conference on Learning Representations, 2017. URL https://openreview. net/forum?id=rkE3y85ee
2017
-
[13]
Code Llama: Open Foundation Models for Code
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nico...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[18]
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization.ArXiv, abs/1808.08745, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Break the sequential dependency of llm inference using lookahead decoding
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm inference using lookahead decoding. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[20]
PEARL: Parallel speculative decoding with adaptive draft length
Tianyu Liu, Yun Li, Qitan Lv, Kai Liu, Jianchen Zhu, Winston Hu, and Xiao Sun. PEARL: Parallel speculative decoding with adaptive draft length. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=QOXrVMiHGK
2025
-
[21]
EAGLE-2: Faster inference of language models with dynamic draft trees
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-2: Faster inference of language models with dynamic draft trees. InEmpirical Methods in Natural Language Processing, 2024
2024
-
[22]
EAGLE-3: Scaling up inference acceleration of large language models via training-time test
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-3: Scaling up inference acceleration of large language models via training-time test. InAnnual Conference on Neural Information Processing Systems, 2025
2025
-
[23]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, and Adam Santoro. Mixture-of-depths: Dynamically allocating compute in transformer-based language models, 2024. URLhttps://arxiv.org/abs/2404.02258
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Draft& verify: Lossless large language model acceleration via self-speculative decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. Draft& verify: Lossless large language model acceleration via self-speculative decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bang...
-
[25]
Swift: On-the-fly self- speculative decoding for llm inference acceleration, 2025
Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, and Wenjie Li. Swift: On-the-fly self- speculative decoding for llm inference acceleration, 2025. URL https://arxiv.org/abs/ 2410.06916
-
[26]
Opti- mized early-exit based speculative decoding via pipeline parallelism, 2026
Ruanjun Li, Ziheng Liu, Yuanming Shi, Jiawei Shao, Chi Zhang, and Xuelong Li. Opti- mized early-exit based speculative decoding via pipeline parallelism, 2026. URL https: //openreview.net/forum?id=6ezbdRe90k
2026
-
[27]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling, 2023. URLhttps://arxiv.org/abs/2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Easyspec: Layer-parallel speculative decoding for efficient multi-gpu utilization, 2025
Yize Wu, Ke Gao, Ling Li, and Yanjun Wu. Easyspec: Layer-parallel speculative decoding for efficient multi-gpu utilization, 2025. URLhttps://arxiv.org/abs/2502.02493
-
[29]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads,
-
[30]
URLhttps://arxiv.org/abs/2401.10774
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty, 2025. URLhttps://arxiv.org/abs/2401.15077
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Speculative Speculative Decoding
Tanishq Kumar, Tri Dao, and Avner May. Speculative speculative decoding, 2026. URL https://arxiv.org/abs/2603.03251
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism, 2020. URLhttps://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[34]
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V . Le, Yonghui Wu, and Zhifeng Chen. Gpipe: Efficient training of giant neural networks using pipeline parallelism, 2019. URL https://arxiv.org/ abs/1811.06965
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Sharegpt_vicuna_unfiltered, 2023
Aeala. Sharegpt_vicuna_unfiltered, 2023. URL https://huggingface.co/datasets/ Aeala/ShareGPT_Vicuna_unfiltered. A Additional formulation details and proofs Section 2 presents the compact formulation used in the main paper. This appendix provides additional empirical measurements, illustrative examples, and full derivations for the selection and exploratio...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.