Chain-of-Thought and Compressed Looped Transformers: A Memory-Budget Separation
Pith reviewed 2026-06-28 23:15 UTC · model grok-4.3
The pith
Compressed latent loops in Transformers stay limited to small-space reasoning even after many iterations, unlike chain-of-thought which can grow its scratchpad.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A compressed latent loop is limited by the size of its recurrent state; running the loop longer adds computation but does not by itself create a growing scratchpad, so a loop with a small recurrent state remains a small-space reasoner even when run for many steps. Under a standard complexity assumption, such loops cannot decide problems that are P-complete under logspace reductions, whereas polynomial-length chain-of-thought can.
What carries the argument
The compressed latent loop, which carries only a fixed-size recurrent state that does not grow with additional iterations.
If this is right
- Polynomial-length chain-of-thought can decide problems outside the reach of any fixed-state compressed loop.
- Full sequence-state loops occupy a memory regime closer to explicit scratchpads and therefore escape the small-space limitation.
- Task performance in pointer-chasing and associative-recall experiments depends on whether the persistent-state budget matches the working-memory demand of the problem.
- Extending loop iterations alone cannot substitute for increasing the size of the recurrent state when the task requires growing intermediate storage.
Where Pith is reading between the lines
- Architectures that must stay within a strict memory budget may need to adopt explicit scratchpad mechanisms rather than relying on loop iteration count.
- The separation suggests a practical test: measure whether increasing loop depth without enlarging hidden state improves accuracy on logspace-hard tasks.
- Design choices that embed growing state directly in the sequence (as in chain-of-thought) may be necessary for certain classes of reasoning problems.
Load-bearing premise
The modeling choice that a compressed latent loop carries only a fixed-size recurrent state that does not grow with additional loop iterations and therefore remains a small-space reasoner.
What would settle it
A concrete counter-example in which a small fixed-state looped Transformer solves a P-complete problem under logspace reductions after polynomially many iterations, or a proof that no such counter-example exists.
Figures
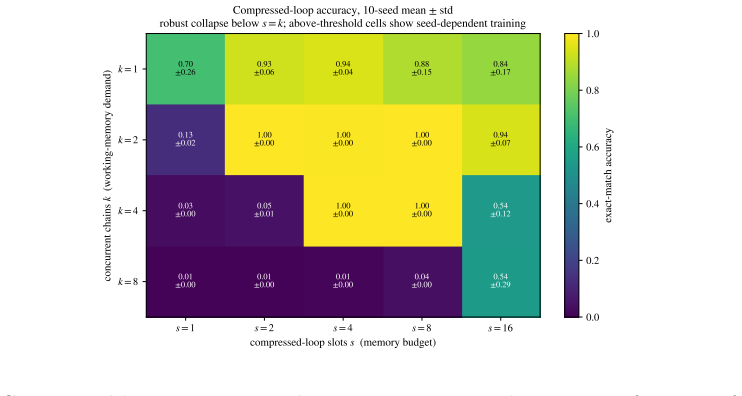
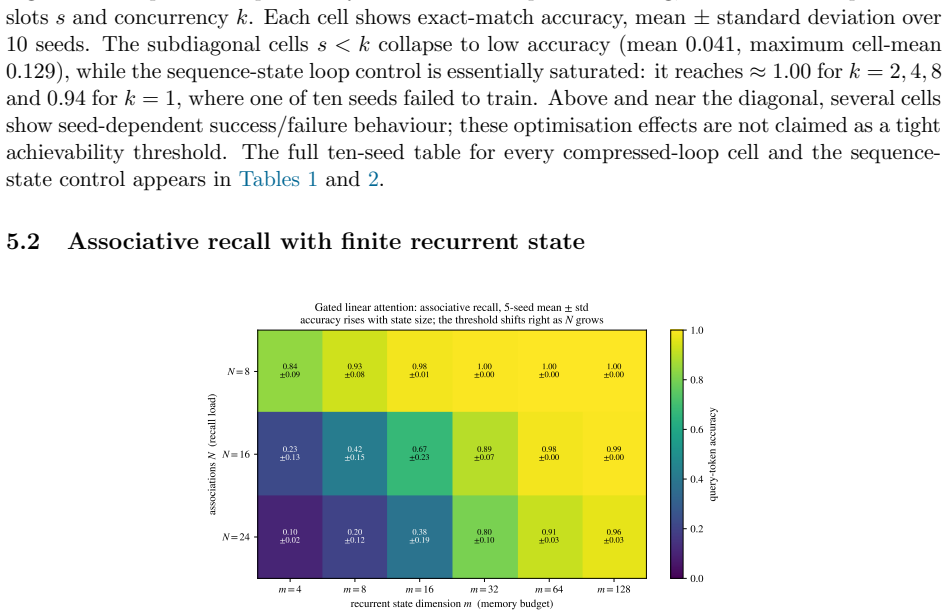
read the original abstract
Chain-of-thought prompting and looped Transformers both give a fixed model more test-time computation, but they differ in what they remember. Chain-of-thought stores intermediate state in generated tokens that remain in the context, whereas a looped Transformer carries state through recurrent hidden activations. We argue that this persistent mutable memory is a central resource for test-time reasoning. We compare three memory regimes, the compressed latent loop, the full sequence-state loop, and the chain-of-thought scratchpad. Our main result shows that a compressed loop is limited by the size of its recurrent state. Running the loop longer adds computation but does not by itself create a growing scratchpad, so a loop with a small recurrent state remains a small-space reasoner even when run for many steps. Under a standard complexity assumption, such loops cannot decide problems that are P-complete under logspace reductions, whereas polynomial-length chain-of-thought can. The separation is specific to compressed loops, as full sequence-state loops carry state at every input position and live in a memory-rich regime closer to explicit scratchpads. Controlled pointer-chasing and associative-recall sweeps illustrate this memory-budget view, with performance sensitive to whether the persistent-state budget matches the task's working-memory demand.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that compressed latent loops in Transformers are memory-limited by a fixed-size recurrent state that does not grow with iterations, placing them in a small-space regime unable to solve P-complete problems under logspace reductions (assuming L ≠ P), while polynomial-length chain-of-thought scratchpads can; full sequence-state loops occupy a memory-rich regime closer to explicit scratchpads. The separation is supported by an explicit modeling premise and illustrated via controlled pointer-chasing and associative-recall experiments.
Significance. If the modeling premise and complexity separation hold, the result offers a clear theoretical distinction among test-time compute regimes in Transformers, emphasizing persistent mutable memory as a key resource. The explicit contrast between the three regimes and the use of controlled task sweeps provide a useful framework for architecture design; the paper receives credit for grounding the argument in a standard complexity assumption rather than ad-hoc claims.
major comments (2)
- [Abstract] Abstract (main result paragraph): the separation is stated to rest on an external complexity assumption (L ≠ P) and an informal argument about state size without derivation steps, formal definitions of the loop regimes, or error analysis; this leaves the support for the central claim unclear and requires explicit formalization in the main text.
- [Modeling section (three memory regimes)] Modeling of compressed loops: the claim that a compressed loop 'remains a small-space reasoner even when run for many steps' depends on the premise that recurrent state dimension is fixed and independent of input length or iteration count; without equations defining the state update or a proof that this maps to o(log n) space under logspace reductions, the load-bearing step for the P-completeness separation is not fully elaborated.
minor comments (2)
- [Abstract] The abstract could more explicitly name the sections where the formal definitions and complexity reduction are provided.
- [Experiments] Figure captions for the pointer-chasing and associative-recall sweeps should state the exact state-dimension values used to match the theoretical regimes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater formality in presenting the modeling premises and complexity separation. We address each major comment below and will revise the manuscript accordingly to strengthen the formal foundations while preserving the core argument.
read point-by-point responses
-
Referee: [Abstract] Abstract (main result paragraph): the separation is stated to rest on an external complexity assumption (L ≠ P) and an informal argument about state size without derivation steps, formal definitions of the loop regimes, or error analysis; this leaves the support for the central claim unclear and requires explicit formalization in the main text.
Authors: We agree the abstract is concise and high-level. The main text already contains the regime definitions and the space argument, but we will add a short formal statement of the three memory regimes (including state-update equations) and a one-paragraph sketch of the o(log n) space bound under logspace reductions directly after the abstract or in the introduction. This will make the connection to the L ≠ P assumption explicit without altering the abstract length substantially. revision: yes
-
Referee: [Modeling section (three memory regimes)] Modeling of compressed loops: the claim that a compressed loop 'remains a small-space reasoner even when run for many steps' depends on the premise that recurrent state dimension is fixed and independent of input length or iteration count; without equations defining the state update or a proof that this maps to o(log n) space under logspace reductions, the load-bearing step for the P-completeness separation is not fully elaborated.
Authors: The modeling section states that the recurrent state dimension is fixed and independent of n and iteration count, which is the key premise. We will expand this subsection with explicit state-update equations (h_{t+1} = f_θ(h_t, x_t) where dim(h) = d is constant) and a short proof that, under standard logspace reductions, the overall computation remains in o(log n) space. This will directly support why such loops cannot decide P-complete problems unless L = P, while full-sequence loops and CoT do not face the same bound. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's separation between compressed latent loops and chain-of-thought rests on an explicit modeling premise (fixed-size recurrent state independent of loop iterations) plus an external complexity assumption (L ≠ P). No equations, fitted parameters, self-citations, or ansatzes appear in the provided text; the claim does not reduce any derived quantity to its own inputs by construction. The argument is self-contained against the stated external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard complexity assumption that P-complete problems under logspace reductions require more than logspace memory.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := ...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
, Huang, X
Amiri, A. , Huang, X. , Rofin, M. and Hahn, M. (2025). Lower bounds for chain-of-thought reasoning in hard-attention transformers. In Forty-second International Conference on Machine Learning. ://openreview.net/forum?id=Oh9sG5ae2b
2025
-
[4]
, Eyuboglu, S
Arora, S. , Eyuboglu, S. , Timalsina, A. , Johnson, I. , Poli, M. , Zou, J. , Rudra, A. and Re, C. (2024 a ). Zoology: Measuring and improving recall in efficient language models. In The Twelfth International Conference on Learning Representations (ICLR). ://openreview.net/forum?id=LY3ukUANko
2024
-
[5]
, Eyuboglu, S
Arora, S. , Eyuboglu, S. , Zhang, M. , Timalsina, A. , Alberti, S. , Zou, J. , Rudra, A. and Re, C. (2024 b ). Simple linear attention language models balance the recall-throughput tradeoff. In Forty-first International Conference on Machine Learning (ICML). ://openreview.net/forum?id=e93ffDcpH3
2024
-
[6]
and Fountoulakis, K
Back de Luca , A. and Fountoulakis, K. (2024). Simulation of graph algorithms with looped transformers. In Forty-first International Conference on Machine Learning (ICML). ://openreview.net/forum?id=aA2326y3hf
2024
-
[7]
A Mechanistic Analysis of Looped Reasoning Language Models
Blayney, H. , Arroyo, \'A . , Obando-Ceron, J. , Castro, P. S. , Courville, A. , Bronstein, M. M. and Dong, X. (2026). A mechanistic analysis of looped reasoning language models. arXiv preprint arXiv:2604.11791
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Memory-Efficient Looped Transformer: Decoupling Compute from Memory in Looped Language Models
Conchello Vendrell , V. , Masdemont, A. P. , Grillo, N. , Ros-Giralt, J. , Behboodi, A. and Massoli, F. V. (2026). Memory-efficient looped transformer: Decoupling compute from memory in looped language models. arXiv preprint arXiv:2605.07721
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
, Shomali, B
Frey, M. , Shomali, B. , Bashir, A. H. , Berghaus, D. , Koehler, J. and Ali, M. (2026). Adaptive loops and memory in transformers: Think harder or know more? In Workshop on Latent & Implicit Thinking Going Beyond CoT Reasoning . ://openreview.net/forum?id=F87X9c107e
2026
-
[10]
, McLeish, S
Geiping, J. , McLeish, S. M. , Jain, N. , Kirchenbauer, J. , Singh, S. , Bartoldson, B. R. , Kailkhura, B. , Bhatele, A. and Goldstein, T. (2025). Scaling up test-time compute with latent reasoning: A recurrent depth approach. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. ://openreview.net/forum?id=S3GhJooWIC
2025
-
[11]
, Rajput, S
Giannou, A. , Rajput, S. , Sohn, J.-y. , Lee, K. , Lee, J. D. and Papailiopoulos, D. (2023). Looped transformers as programmable computers. In International Conference on Machine Learning (ICML). ://proceedings.mlr.press/v202/giannou23a.html
2023
-
[12]
, Sukhbaatar, S
Hao, S. , Sukhbaatar, S. , Su, D. , Li, X. , Hu, Z. , Weston, J. E. and Tian, Y. (2025). Training large language models to reason in a continuous latent space. In Second Conference on Language Modeling (COLM). ://openreview.net/forum?id=Itxz7S4Ip3
2025
-
[13]
, Ciccone, M
Jeddi, A. , Ciccone, M. and Taati, B. (2026). Loopformer: Elastic-depth looped transformers for latent reasoning via shortcut modulation. In The Fourteenth International Conference on Learning Representations (ICLR). ://openreview.net/forum?id=RzYXb5YWBs
2026
-
[14]
, Liu, H
Li, Z. , Liu, H. , Zhou, D. and Ma, T. (2024). Chain of thought empowers transformers to solve inherently serial problems. In The Twelfth International Conference on Learning Representations (ICLR). ://openreview.net/forum?id=3EWTEy9MTM
2024
- [15]
-
[16]
Merrill, W. and Sabharwal, A. (2023). The parallelism tradeoff: Limitations of log-precision transformers. Transactions of the Association for Computational Linguistics (TACL) 11 531--545. ArXiv:2207.00729
-
[17]
and Sabharwal, A
Merrill, W. and Sabharwal, A. (2024). The expressive power of transformers with chain of thought. In The Twelfth International Conference on Learning Representations (ICLR). ://openreview.net/forum?id=NjNGlPh8Wh
2024
-
[18]
and Sabharwal, A
Merrill, W. and Sabharwal, A. (2025 a ). Exact expressive power of transformers with padding. In The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS). ://openreview.net/forum?id=O1abxStFcy
2025
-
[19]
and Sabharwal, A
Merrill, W. and Sabharwal, A. (2025 b ). A little depth goes a long way: The expressive power of log-depth transformers. In The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS). ://openreview.net/forum?id=5pHfYe10iX
2025
-
[20]
Okpekpe, D. and Orvieto, A. (2025). Revisiting associative recall in modern recurrent models. arXiv preprint arXiv:2508.19029
-
[21]
Sapunov, G. (2026). Universal transformers need memory: Depth-state trade-offs in adaptive recursive reasoning. arXiv preprint arXiv:2604.21999
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
, Dikkala, N
Saunshi, N. , Dikkala, N. , Li, Z. , Kumar, S. and Reddi, S. J. (2025). Reasoning with latent thoughts: On the power of looped transformers. In The Thirteenth International Conference on Learning Representations (ICLR). ://openreview.net/forum?id=din0lGfZFd
2025
-
[23]
A Formal Comparison Between Chain of Thought and Latent Thought
Xu, K. and Sato, I. (2026). A formal comparison between chain of thought and latent thought. arXiv preprint arXiv:2509.25239 . ://arxiv.org/abs/2509.25239
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
, Srebro, N
Yang, C. , Srebro, N. , McAllester, D. and Li, Z. (2025). PENCIL : Long thoughts with short memory. In Forty-second International Conference on Machine Learning (ICML). ://openreview.net/forum?id=6wglsDXIei
2025
-
[25]
, Lee, K
Yang, L. , Lee, K. , Nowak, R. D. and Papailiopoulos, D. (2024). Looped transformers are better at learning learning algorithms. In The Twelfth International Conference on Learning Representations (ICLR). ://openreview.net/forum?id=HHbRxoDTxE
2024
-
[26]
Scaling Latent Reasoning via Looped Language Models
Zhu, R.-J. , Wang, Z. , Hua, K. , Zhang, T. , Li, Z. , Que, H. , Wei, B. , Wen, Z. , Yin, F. , Xing, H. , Li, L. , Shi, J. , Ma, K. , Li, S. , Kergan, T. , Smith, A. , Qu, X. , Hui, M. , Wu, B. , Min, Q. , Huang, H. , Zhou, X. , Ye, W. , Liu, J. , Yang, J. , Shi, Y. , Lin, C. , Zhao, E. , Cai, T. , Zhang, G. , Huang, W. , Bengio, Y. and Eshraghian, J. (20...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.