SiDiaC: Sinhala Diachronic Corpus
Pith reviewed 2026-05-21 21:22 UTC · model grok-4.3
The pith
SiDiaC supplies the first sizable collection of dated Sinhala texts from the 5th to the 20th century for tracking language change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
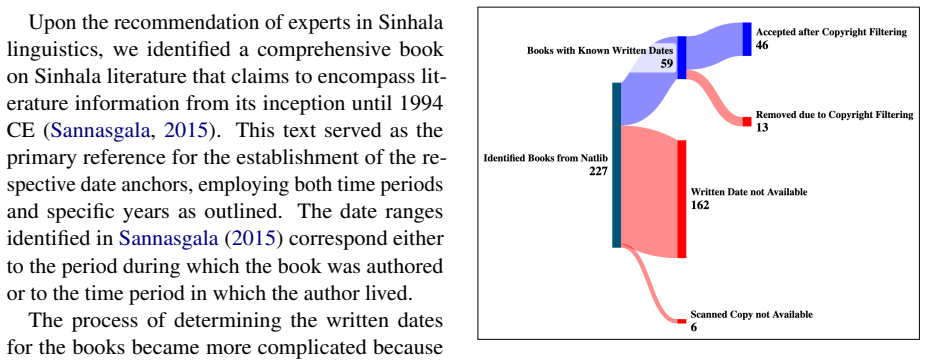
SiDiaC comprises 58k words across 46 literary works from the 5th to the 20th century CE. Texts were selected after filtering on availability, authorship, copyright, and attribution, then digitised with Google Document AI OCR followed by formatting correction and orthography modernisation. Primary genre labels divide each book into Fiction or Non-Fiction; secondary labels place them under Religious, History, Poetry, Language, or Medical. The resulting resource is presented as foundational for Sinhala NLP and directly enables diachronic studies of lexical change, neologism tracking, historical syntax, and corpus-based lexicography.
What carries the argument
The SiDiaC corpus itself: a date-annotated, genre-categorised collection of historical Sinhala texts that serves as the dataset for all proposed diachronic analyses.
If this is right
- Lexical change in Sinhala can be measured directly across fifteen centuries using the dated texts.
- Neologisms can be tracked by comparing vocabulary in earlier versus later works.
- Historical syntax patterns become accessible through the genre-stratified collection.
- Lexicographers gain a new historical layer for Sinhala dictionaries.
Where Pith is reading between the lines
- Similar date-stratified corpora could be built for other languages that have sparse historical records but some preserved literary works.
- Combining the corpus with modern embedding models might surface syntactic shifts that manual inspection misses.
- Periodic updates that add newly digitised texts would strengthen the reliability of any long-term trend measurements.
Load-bearing premise
The dates taken from secondary sources are accurate and the OCR plus orthography changes preserve the original linguistic features without systematic distortion.
What would settle it
A side-by-side check of corpus dates against primary historical records that finds repeated misattributions, or a linguistic comparison showing that the modernised spellings hide or alter period-specific forms.
Figures





read the original abstract
SiDiaC, the first comprehensive Sinhala Diachronic Corpus, covers a historical span from the 5th to the 20th century CE. SiDiaC comprises 58k words across 46 literary works, annotated carefully based on the written date, after filtering based on availability, authorship, copyright compliance, and data attribution. Texts from the National Library of Sri Lanka were digitised using Google Document AI OCR, followed by post-processing to correct formatting and modernise the orthography. The construction of SiDiaC was informed by practices from other corpora, such as FarPaHC, particularly in syntactic annotation and text normalisation strategies, due to the shared characteristics of low-resourced language status. This corpus is categorised based on genres into two layers: primary and secondary. Primary categorisation is binary, classifying each book into Non-Fiction or Fiction, while the secondary categorisation is more specific, grouping texts under Religious, History, Poetry, Language, and Medical genres. Despite challenges including limited access to rare texts and reliance on secondary date sources, SiDiaC serves as a foundational resource for Sinhala NLP, significantly extending the resources available for Sinhala, enabling diachronic studies in lexical change, neologism tracking, historical syntax, and corpus-based lexicography.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SiDiaC, the first comprehensive Sinhala diachronic corpus spanning the 5th to 20th centuries CE. It contains approximately 58,000 words from 46 literary works selected after filtering for availability, authorship, copyright, and attribution. The texts were digitized from the National Library of Sri Lanka using Google Document AI for OCR, followed by post-processing to correct formatting and modernize orthography. Dates are assigned based on secondary sources, and texts are annotated and categorized into primary (Fiction/Non-Fiction) and secondary genres (Religious, History, Poetry, Language, Medical). The work draws on practices from other low-resource language corpora like FarPaHC for syntactic annotation and normalization. The authors position SiDiaC as a foundational resource enabling diachronic NLP studies in lexical change, neologism tracking, historical syntax, and lexicography for Sinhala.
Significance. If the corpus construction is rigorously validated, particularly regarding the accuracy of temporal metadata and the fidelity of linguistic features post-modernization, this resource could be significant for advancing Sinhala NLP. Sinhala is a low-resource language with limited historical corpora, so a diachronic collection, even of modest size, could support new research directions. The genre categorization and annotation approach add value for targeted studies. However, the small scale (58k words over 15 centuries) inherently limits the granularity of diachronic analyses, reducing the overall impact unless supplemented in future work.
major comments (3)
- In the corpus construction description (Abstract and corresponding methodology section), dates are taken from secondary sources after filtering, but no quantitative assessment of dating accuracy, cross-validation against primary sources, or error bounds is reported. This is load-bearing for the central claim that SiDiaC enables reliable diachronic studies in lexical change and historical syntax, as even moderate dating errors would undermine temporal resolution over a 15-century span with only 58k words total.
- In the post-processing description (Abstract and § on digitization and normalization), orthography is modernized after Google Document AI OCR, but no before/after comparisons of period-specific features (e.g., archaic spellings or case endings) or evidence that linguistic markers are preserved are provided. This directly affects the usability for tracking language change and constitutes a methodological gap for the headline applications.
- No OCR error rates, post-correction quality metrics, or inter-annotator agreement figures are supplied in the quality assurance or annotation sections. For a resource paper claiming to be a 'high-quality foundational' corpus, these details are necessary to substantiate the methodological rigor underlying all downstream claims.
minor comments (2)
- The abstract would benefit from a brief table or breakdown of word counts and text distribution across centuries and genres to better illustrate coverage and balance.
- Consider expanding the related work section to include more explicit comparisons with other diachronic corpora beyond FarPaHC, particularly those handling orthographic modernization in low-resource settings.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive feedback, which has helped us improve the manuscript. We address the major comments below, indicating where revisions have been made to enhance the description of the corpus construction process.
read point-by-point responses
-
Referee: In the corpus construction description (Abstract and corresponding methodology section), dates are taken from secondary sources after filtering, but no quantitative assessment of dating accuracy, cross-validation against primary sources, or error bounds is reported. This is load-bearing for the central claim that SiDiaC enables reliable diachronic studies in lexical change and historical syntax, as even moderate dating errors would undermine temporal resolution over a 15-century span with only 58k words total.
Authors: We appreciate the referee's emphasis on the need for transparency regarding dating accuracy. While a full quantitative assessment and cross-validation with primary sources would be ideal, the scarcity of digitized primary historical sources for Sinhala literature from this period makes such an analysis challenging at this stage. In the revised manuscript, we have added an appendix listing the specific secondary sources used for dating each of the 46 works, along with any noted uncertainties or alternative dates from the literature. We also include a discussion of how these potential dating inaccuracies might affect diachronic analyses and recommend caution in fine-grained temporal studies. This provides users with the necessary context without overstating the precision of the metadata. revision: partial
-
Referee: In the post-processing description (Abstract and § on digitization and normalization), orthography is modernized after Google Document AI OCR, but no before/after comparisons of period-specific features (e.g., archaic spellings or case endings) or evidence that linguistic markers are preserved are provided. This directly affects the usability for tracking language change and constitutes a methodological gap for the headline applications.
Authors: We agree that evidence of preserved linguistic features is important for the intended use cases. Accordingly, we have revised the normalization section to include concrete before-and-after examples from texts representing different centuries. These examples demonstrate that modernization was restricted to orthographic standardization (e.g., updating archaic letter forms to modern equivalents) while retaining period-specific morphological markers such as case endings and vocabulary. We believe this addition clarifies that the corpus remains suitable for tracking lexical and syntactic changes. revision: yes
-
Referee: No OCR error rates, post-correction quality metrics, or inter-annotator agreement figures are supplied in the quality assurance or annotation sections. For a resource paper claiming to be a 'high-quality foundational' corpus, these details are necessary to substantiate the methodological rigor underlying all downstream claims.
Authors: We acknowledge the value of reporting quantitative quality metrics. In the revised manuscript, we have expanded the quality assurance subsection to describe the manual post-correction process in greater detail, including that all texts underwent author review for formatting and obvious OCR errors. We have also added information on the genre annotation process. However, a comprehensive OCR error rate calculation was not part of the original project due to resource constraints, and we now explicitly discuss this as a limitation of the current release, with plans for future enhancements. revision: partial
Circularity Check
No circularity: direct corpus construction with no derivations or predictions
full rationale
The paper describes the assembly of SiDiaC from external historical texts via OCR digitization, orthography modernization, and genre annotation, drawing on standard practices cited from unrelated corpora such as FarPaHC. No equations, fitted parameters, predictions, or first-principles results appear anywhere in the manuscript. The central claim that the corpus enables diachronic studies rests on the described data collection process and external sources rather than any self-referential reduction or redefinition of inputs as outputs. Assumptions about date accuracy and normalization fidelity are empirical risks, not circular logic. The work is self-contained as a resource paper against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Practices from corpora such as FarPaHC for syntactic annotation and text normalisation are transferable to Sinhala due to shared low-resourced language characteristics.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SiDiaC comprises 58k words across 46 literary works, annotated carefully based on the written date, after filtering based on availability, authorship, copyright compliance, and data attribution. Texts from the National Library of Sri Lanka were digitised using Google Document AI OCR, followed by post-processing to correct formatting and modernise the orthography.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
David Bamman and Gregory Crane. 2006. The design and use of a latin dependency treebank. In Proceedings of the Fifth Workshop on Treebanks and Linguistic Theories (TLT2006), pages 67--78
work page 2006
-
[2]
Douglas Biber, Edward Finegan, and Dwight Atkinson. 1994. ARCHER and its challenges: Compiling and exploring a representative corpus of historical English registers . Creating and using English language corpora, pages 1--14
work page 1994
-
[3]
Cheng Chen and Renping Liu. 2025. How administrative powers have impacted land-use development in China during the last 30 years: A diachronic corpus-based news values analysis . Cities, 159:105786
work page 2025
-
[4]
Matthew Christy, Anshul Gupta, Elizabeth Grumbach, Laura Mandell, Richard Furuta, and Ricardo Gutierrez-Osuna. 2017. Mass digitization of early modern texts with optical character recognition. Journal on Computing and Cultural Heritage (JOCCH), 11(1):1--25
work page 2017
-
[5]
Michael C Corballis. 2017. The evolution of language
work page 2017
-
[6]
Mark Davies. 2012. Expanding horizons in historical linguistics with the 400-million word corpus of historical american english. Corpora, 7(2):121--157
work page 2012
-
[7]
Yomal De Mel, Kasun Wickramasinghe, Nisansa de Silva, and Surangika Ranathunga. 2025. https://aclanthology.org/2025.indonlp-1.19/ S inhala transliteration: A comparative analysis between rule-based and S eq2 S eq approaches . In Proceedings of the First Workshop on Natural Language Processing for Indo-Aryan and Dravidian Languages, pages 166--173, Abu Dha...
work page 2025
- [8]
-
[9]
Hanne Eckhoff, Kristin Bech, Gerlof Bouma, Kristine Eide, Dag Haug, Odd Einar Haugen, and Marius J hndal. 2018. The PROIEL treebank family: a standard for early attestations of Indo-European languages . Language Resources and Evaluation, 52(1):29--65
work page 2018
-
[10]
Stian R dven Eide, Nina Tahmasebi, and Lars Borin. 2016. The Swedish culturomics gigaword corpus: A one billion word Swedish reference dataset for NLP . In Proceedings of the From Digitization to Knowledge workshop at DH, pages 8--12
work page 2016
-
[11]
P E E Fernando. 1949. Palaeographical Development of the Brahmi Script in Ceylon from 3rd Century BC to 7th Century AD . University of Ceylon Review, 7(4):282--301
work page 1949
-
[12]
Hema Gaikwad and Jatinderkumar R. Saini. 2024. Identification of closed compound words in devanagari scripted and non-devanagari scripted corpora. In Proceedings of Fifth Doctoral Symposium on Computational Intelligence, pages 411--418, Singapore. Springer Nature Singapore
work page 2024
-
[13]
Alexander Geyken, Susanne Haaf, Bryan Jurish, Matthias Schulz, Jakob Steinmann, Christian Thomas, and Frank Wiegand. 2011. Das Deutsche Textarchiv: Vom historischen Korpus zum aktiven Archiv . Digitale Wissenschaft, 157
work page 2011
-
[14]
Charles Hallisey. 2003. Works and persons in sinhala literary culture. Literary cultures in history: Reconstructions from South Asia, pages 689--746
work page 2003
-
[15]
William L Hamilton, Jure Leskovec, and Dan Jurafsky. 2016. Cultural shift or linguistic drift? comparing two computational measures of semantic change. In Proceedings of the conference on empirical methods in natural language processing. Conference on empirical methods in natural language processing, volume 2016, page 2116
work page 2016
-
[16]
Dag TT Haug and Marius J hndal. 2008. Creating a parallel treebank of the old indo-european bible translations. In Proceedings of the second workshop on language technology for cultural heritage data (LaTeCH 2008), pages 27--34. Prague
work page 2008
- [17]
-
[18]
Alek Keersmaekers and Toon Van Hal. 2024. Creating a large-scale diachronic corpus resource: Automated parsing in the Greek papyri (and beyond) . Natural Language Engineering, 30(5):1035--1064
work page 2024
-
[19]
Thomas Klein and Stefanie Dipper. 2016. Handbuch zum Referenzkorpus Mittelhochdeutsch . Technical report, Ruhr-Universit \"a t Bochum, Sprachwissenschaftliches Institut
work page 2016
-
[20]
Karel Ku c era, Anna R eho r kov \'a , and Martin Stluka. 2015. http://www.korpus.cz/ DIAKORP: diachronic corpus of Czech, version 6 . Institute of the Czech National Corpus, Faculty of Arts, Charles University, Prague
work page 2015
-
[21]
Manika Lamba and Margam Madhusudhan. 2023. Exploring ocr errors in full-text large documents: a study of lis theses and dissertations. Library Philosophy and Practice (e-journal), 7824
work page 2023
-
[22]
Barbara McGillivray and Adam Kilgarriff. 2013. Tools for historical corpus research, and a corpus of latin. New methods in historical corpus linguistics, 1(3):247--257
work page 2013
-
[23]
S T Nandasara and Yoshiki Mikami. 2016. Bridging the digital divide in Sri Lanka: some challenges and opportunities in using Sinhala in ICT . International Journal on Advances in ICT for Emerging Regions (ICTer), 8(1)
work page 2016
-
[24]
Carolin Odebrecht, Malte Belz, Amir Zeldes, Anke L \"u deling, and Thomas Krause. 2017. RIDGES Herbology: designing a diachronic multi-layer corpus . Language Resources and Evaluation, 51(3):695--725
work page 2017
-
[25]
Eva Pettersson and Lars Borin. 2019. Characteristics of diachronic and historical corpora. Features to consider in a Swedish diachronic corpus.[online].[cit. 29. 1. 2022]. Dostupn \'e z
work page 2019
-
[26]
Surangika Ranathunga and Nisansa de Silva. 2022. https://doi.org/10.18653/v1/2022.aacl-main.62 Some languages are more equal than others: Probing deeper into the linguistic disparity in the NLP world . In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conferen...
-
[27]
Eir \'i kur R \"o gnvaldsson, Anton Karl Ingason, Einar Freyr Sigur sson, and Joel Wallenberg. 2012. https://aclanthology.org/L12-1228/ The I celandic parsed historical corpus ( I ce P a HC ) . In Proceedings of the Eighth International Conference on Language Resources and Evaluation ( LREC `12) , pages 1977--1984, Istanbul, Turkey. European Language Reso...
work page 2012
-
[28]
Punchibandara Sannasgala. 2015. Sinhala Sahithya Wanshaya. S. Godage saha Sahodarayo
work page 2015
-
[29]
Whitt, Martin Durrell, and Paul Bennett
Silke Scheible, Richard J. Whitt, Martin Durrell, and Paul Bennett. 2011. https://aclanthology.org/W11-0415/ A gold standard corpus of early M odern G erman . In Proceedings of the 5th Linguistic Annotation Workshop, pages 124--128, Portland, Oregon, USA. Association for Computational Linguistics
work page 2011
-
[30]
Helmut Schmid. 1999. Improvements in part-of-speech tagging with an application to german. In Natural language processing using very large corpora, pages 13--25. Springer
work page 1999
-
[31]
Achim Stein and Sophie Pr \'e vost. 2013. Syntactic annotation of medieval texts: the syntactic reference corpus of medieval french (srcmf). New methods in historical corpora, 3:275
work page 2013
-
[32]
Ann Taylor and Anthony S Kroch. 1994. The penn-helsinki parsed corpus of middle english. MS. University of Pennsylvania, page 30
work page 1994
-
[33]
Sarathchandra Wickremasuriya. 1978. The beginnings of the sinhalese printing press. In Senarat Paranavitana commemoration volume, pages 283--300. Brill
work page 1978
- [34]
-
[35]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[36]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.