Multilingual Polarization Detection Using Transformer-Based Models with Class Weighting and Threshold Tuning
Pith reviewed 2026-07-01 02:03 UTC · model grok-4.3
The pith
Transformer models with class-weighted loss and per-label threshold tuning reach competitive F1 scores on multilingual polarization detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
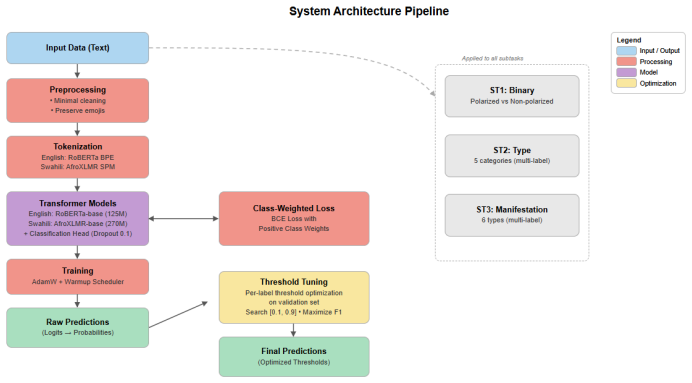
Our approach leverages transformer-based models (RoBERTa-base for English, AfroXLMR-base for Swahili) with class-weighted loss functions to address severe label imbalance and per-label threshold tuning to optimize multi-label classification, achieving the reported F1 macro scores on the test set and competitive leaderboard placement.
What carries the argument
RoBERTa-base and AfroXLMR-base transformers combined with class-weighted loss functions and per-label threshold tuning for multi-label output.
If this is right
- Class-weighted loss counters the effects of severe label imbalance in the polarization datasets.
- Per-label threshold tuning improves multi-label classification performance on the type and manifestation subtasks.
- The same pipeline yields competitive results for both English and Swahili.
- Remaining errors concentrate on dehumanization detection and lack-of-empathy cases.
Where Pith is reading between the lines
- The same weighting and tuning steps could be tested on other imbalanced multi-label classification problems in computational linguistics.
- Targeted improvements on the hardest categories identified in the error analysis would raise overall scores further.
- A controlled comparison against untuned or unweighted versions of the same transformers would clarify how much each adjustment adds.
Load-bearing premise
The test-set F1 scores alone demonstrate that class weighting and threshold tuning are effective without ablation studies or baseline comparisons to isolate their contributions.
What would settle it
An ablation experiment that retrains the same models without class weighting or without per-label threshold tuning and reports the change in F1 macro on the identical test set.
Figures
read the original abstract
This paper describes our submission to SemEval-2026 Task 9 on detecting multilingual, multicultural, and multievent online polarization. We address all three subtasks: binary polarization detection, polarization type classification, and manifestation identification for English and Swahili. Our approach leverages transformer-based models (RoBERTa-base for English, AfroXLMR-base for Swahili) with class-weighted loss functions to address severe label imbalance and per-label threshold tuning to optimize multi-label classification. On the test set, we achieve F1 macro scores of 0.7901 (English) and 0.7910 (Swahili) for Subtask 1, 0.4615 (English) and 0.4808 (Swahili) for Subtask 2 and 0.4791 (English) and 0.5830 (Swahili) for Subtask 3, which give competitive performance on the leaderboard, demonstrating the effectiveness of our methods for handling imbalanced multi-label polarization detection. Our error analysis reveals that models struggle with dehumanization detection and lack of empathy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a SemEval-2026 Task 9 submission for multilingual polarization detection across three subtasks (binary detection, type classification, manifestation identification) in English and Swahili. It employs RoBERTa-base and AfroXLMR-base transformers with class-weighted loss functions to mitigate label imbalance and per-label threshold tuning for multi-label output. The abstract reports test-set F1 macro scores of 0.7901/0.7910 (Subtask 1), 0.4615/0.4808 (Subtask 2), and 0.4791/0.5830 (Subtask 3), asserting that these scores are competitive on the leaderboard and demonstrate the effectiveness of the proposed techniques; an error analysis notes difficulties with dehumanization and empathy detection.
Significance. If the contributions of class weighting and threshold tuning could be isolated, the work would supply practical guidance for severe imbalance in multilingual multi-label settings. The reported scores on a hidden test set and the error analysis on specific failure modes (dehumanization) are concrete, but the absence of any controlled comparison prevents attribution of gains to the highlighted methods and therefore limits methodological impact.
major comments (2)
- [Abstract] Abstract: the claim that the reported F1 scores demonstrate the effectiveness of class-weighted loss functions and per-label threshold tuning is unsupported, because the manuscript contains no ablation experiments (weighted vs. unweighted loss; tuned thresholds vs. default 0.5) and no direct comparison against the unmodified RoBERTa-base / AfroXLMR-base models.
- [Results] Results section (implied by leaderboard claims): no baseline F1 scores, no statistical significance tests on differences, and no error bars or run-to-run variance are supplied, so the headline numbers cannot be used to validate the specific techniques emphasized in the abstract and methods.
minor comments (1)
- [Abstract] Abstract: F1 values are reported to four decimal places without any indication of whether multiple random seeds were used or whether variance was measured.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback on our SemEval-2026 Task 9 submission. We agree that stronger evidence is needed to attribute performance gains specifically to class weighting and threshold tuning, and we will revise the manuscript accordingly to avoid unsupported claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the reported F1 scores demonstrate the effectiveness of class-weighted loss functions and per-label threshold tuning is unsupported, because the manuscript contains no ablation experiments (weighted vs. unweighted loss; tuned thresholds vs. default 0.5) and no direct comparison against the unmodified RoBERTa-base / AfroXLMR-base models.
Authors: We acknowledge that the manuscript lacks ablation studies or direct comparisons to unmodified baselines, rendering the abstract's claim about demonstrating the effectiveness of the techniques unsupported. In the revised version, we will update the abstract to state only that the approach yields competitive leaderboard performance, removing any assertion that the scores validate the specific contributions of class weighting and threshold tuning. revision: yes
-
Referee: [Results] Results section (implied by leaderboard claims): no baseline F1 scores, no statistical significance tests on differences, and no error bars or run-to-run variance are supplied, so the headline numbers cannot be used to validate the specific techniques emphasized in the abstract and methods.
Authors: The current manuscript reports single-run test-set scores and references the shared-task leaderboard for context but provides no internal baselines, significance tests, or variance estimates. We agree this prevents direct validation of the methods. We will add a limitations paragraph in the results section clarifying that competitiveness is assessed via leaderboard position rather than controlled experiments, while noting that additional runs for statistical analysis exceed the scope of this submission. revision: partial
Circularity Check
No circularity: direct empirical test-set measurements.
full rationale
The paper reports F1 macro scores obtained by applying RoBERTa-base and AfroXLMR-base models (with class-weighted loss and per-label thresholds) to the held-out test set of SemEval-2026 Task 9. These scores are independent empirical observations, not quantities derived from or equivalent to the fitted parameters by construction. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The manuscript is self-contained against external benchmarks (the shared-task leaderboard) and contains no mathematical reduction that would trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- class weights
- per-label thresholds
axioms (1)
- domain assumption Pre-trained RoBERTa and AfroXLMR models already encode features relevant to polarization detection in English and Swahili.
Reference graph
Works this paper leans on
-
[1]
David Ifeoluwa Adelani, Graham Neubig, Sebastian Ruder, Shruti Rijhwani, Michael Beukman, Chester Palen-Michel, Constantine Lignos, Jesujoba Alabi, Shamsuddeen H Muhammad, Peter Nabende, and 1 others. 2022. Masakhaner 2.0: Africa-centric transfer learning for named entity recognition. In Proceedings of the 2022 Conference on Empirical Methods in Natural L...
2022
-
[2]
Jesujoba Alabi, David Ifeoluwa Adelani, Marius Mosbach, and Dietrich Klakow. 2022. Adapting pre-trained language models to african languages via multilingual adaptive fine-tuning. In Proceedings of the 29th international conference on computational linguistics, pages 4336--4349
2022
-
[3]
Pinkesh Badjatiya, Shashank Gupta, Manish Gupta, and Vasudeva Varma. 2017. Deep learning for hate speech detection in tweets. In Proceedings of the 26th international conference on World Wide Web companion, pages 759--760
2017
-
[4]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 8440--8451
2020
-
[5]
Michael Conover, Jacob Ratkiewicz, Matthew Francisco, Bruno Gon c alves, Filippo Menczer, and Alessandro Flammini. 2011. Political polarization on twitter. In Proceedings of the international aaai conference on web and social media, volume 5, pages 89--96
2011
-
[6]
Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. 2017. Automated hate speech detection and the problem of offensive language. In Proceedings of the international AAAI conference on web and social media, volume 11, pages 512--515
2017
-
[7]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171--4186
2019
-
[8]
Paula Fortuna and S \'e rgio Nunes. 2018. A survey on automatic detection of hate speech in text. Acm Computing Surveys (Csur), 51(4):1--30
2018
-
[9]
Purva Grover, Arpan Kumar Kar, Yogesh K Dwivedi, and Marijn Janssen. 2019. Polarization and acculturation in us election 2016 outcomes--can twitter analytics predict changes in voting preferences. Technological Forecasting and Social Change, 145:438--460
2019
-
[10]
Justin M Johnson and Taghi M Khoshgoftaar. 2019. Survey on deep learning with class imbalance. Journal of big data, 6(1):1--54
2019
-
[12]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations (ICLR)
2019
-
[13]
O zge Alacam, Cengiz Acar
Usman Naseem, Robert Geislinger, Juan Ren, Sarah Kohail, Rudy Garrido Veliz, P Sam Sahil, Yiran Zhang, Marco Antonio Stranisci, Idris Abdulmumin, "O zge Alacam, Cengiz Acar "u rk, Aisha Jabr, Saba Anwar, Abinew Ali Ayele, Elena Tutubalina, Aung Kyaw Htet, Xintong Wang, Surendrabikram Thapa, Tanmoy Chakraborty, and 15 others. 2026 a . S em E val-2026 task ...
2026
-
[14]
Usman Naseem, Robert Geislinger, Juan Ren, Sarah Kohail, Rudy Garrido Veliz, P Sam Sahil, Yiran Zhang, Marco Antonio Stranisci, Idris Abdulmumin, Özge Alacam, Cengiz Acartürk, Aisha Jabr, Saba Anwar, Abinew Ali Ayele, Simona Frenda, Alessandra Teresa Cignarella, Elena Tutubalina, Oleg Rogov, Aung Kyaw Htet, and 24 others. 2026 b . https://arxiv.org/abs/25...
-
[15]
Kelechi Ogueji, Yuxin Zhu, and Jimmy Lin. 2021. Small data? no problem! exploring the viability of pretrained multilingual language models for low-resourced languages. In Proceedings of the 1st workshop on multilingual representation learning, pages 116--126
2021
-
[16]
Ellery Wulczyn, Nithum Thain, and Lucas Dixon. 2017. Ex machina: Personal attacks seen at scale. In Proceedings of the 26th international conference on world wide web, pages 1391--1399
2017
-
[18]
Technological Forecasting and Social Change , volume=
Polarization and acculturation in US Election 2016 outcomes--Can twitter analytics predict changes in voting preferences , author=. Technological Forecasting and Social Change , volume=. 2019 , publisher=
2016
-
[19]
Proceedings of the international AAAI conference on web and social media , volume=
Automated hate speech detection and the problem of offensive language , author=. Proceedings of the international AAAI conference on web and social media , volume=
-
[20]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[21]
Available at SSRN 4934897 , year=
Automated Risk Assessment in SAP Financial Modules through Machine Learning , author=. Available at SSRN 4934897 , year=
-
[22]
Proceedings of the National Academy of Sciences , volume=
Cognitive impairment after focal brain lesions is better predicted by damage to structural than functional network hubs , author=. Proceedings of the National Academy of Sciences , volume=. 2021 , publisher=
2021
-
[23]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Optimal thresholding of classifiers to maximize F1 measure , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2014 , organization=
2014
-
[24]
ACM computing surveys (CSUR) , volume=
A survey of predictive modeling on imbalanced domains , author=. ACM computing surveys (CSUR) , volume=. 2016 , publisher=
2016
-
[25]
Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Improving neural machine translation models with monolingual data , author=. Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[26]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Loshchilov, Ilya and Hutter, Frank , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[27]
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[28]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Masakhaner 2.0: Africa-centric transfer learning for named entity recognition , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[29]
Learning from the worst: Dynamically generated datasets to improve online hate detection , author=. Proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[30]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Unsupervised cross-lingual representation learning at scale , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[31]
EDA: Easy data augmentation techniques for boosting performance on text classification tasks , author=. arXiv preprint arXiv:1901.11196 , year=
-
[32]
Computers & Security , volume=
Synthetic attack data generation model applying generative adversarial network for intrusion detection , author=. Computers & Security , volume=. 2023 , publisher=
2023
-
[33]
Journal of big data , volume=
Survey on deep learning with class imbalance , author=. Journal of big data , volume=. 2019 , publisher=
2019
-
[34]
Proceedings of the IEEE international conference on computer vision , pages=
Focal loss for dense object detection , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[35]
Proceedings of the 1st workshop on multilingual representation learning , pages=
Small data? no problem! exploring the viability of pretrained multilingual language models for low-resourced languages , author=. Proceedings of the 1st workshop on multilingual representation learning , pages=
-
[36]
Proceedings of the 26th international conference on World Wide Web companion , pages=
Deep learning for hate speech detection in tweets , author=. Proceedings of the 26th international conference on World Wide Web companion , pages=
-
[37]
Proceedings of the international aaai conference on web and social media , volume=
Political polarization on twitter , author=. Proceedings of the international aaai conference on web and social media , volume=
-
[38]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[39]
Proceedings of the 29th international conference on computational linguistics , pages=
Adapting pre-trained language models to African languages via multilingual adaptive fine-tuning , author=. Proceedings of the 29th international conference on computational linguistics , pages=
-
[40]
Acm Computing Surveys (Csur) , volume=
A survey on automatic detection of hate speech in text , author=. Acm Computing Surveys (Csur) , volume=. 2018 , publisher=
2018
-
[41]
Predicting the Type and Target of Offensive Posts in Social Media
Predicting the type and target of offensive posts in social media , author=. arXiv preprint arXiv:1902.09666 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[42]
Proceedings of the 26th international conference on world wide web , pages=
Ex machina: Personal attacks seen at scale , author=. Proceedings of the 26th international conference on world wide web , pages=
-
[43]
Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , year =
Naseem, Usman and Geislinger, Robert and Ren, Juan and Kohail, Sarah and Garrido Veliz, Rudy and Sam Sahil, P and Zhang, Yiran and Stranisci, Marco Antonio and Abdulmumin, Idris and Alacam,. Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , year =
2026
-
[44]
2026 , eprint=
POLAR: A Benchmark for Multilingual, Multicultural, and Multi-Event Online Polarization , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.