Privacy Parameter Variation Using RAPPOR on a Malware Dataset
Pith reviewed 2026-05-24 16:54 UTC · model grok-4.3
The pith
RAPPOR with ε values of 10, 1.0 and 0.1 applied to Android app datasets of 10,000 to 1,200,000 samples maps privacy-utility tradeoffs for malware analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RAPPOR privacy parameter variations are applied against a public dataset containing a list of running Android applications data with sample sizes of 10,000; 100,000; and 1,200,000 while applying RAPPOR with ε = 10; 1.0; and 0.1 (respectively low; medium; high privacy guarantees). Also, in order to observe detailed variations within high to medium privacy guarantees (ε = 0.5 to 1.0), a second experiment is conducted by progressively varying the parameter.
What carries the argument
RAPPOR (Randomized Aggregatable Privacy-Preserving Ordinal Response) with tunable privacy parameter ε that controls the amount of noise added to each response before aggregation.
If this is right
- Stronger privacy (lower ε) reduces the visibility of malware indicators in the aggregated data.
- Larger sample sizes (1.2 million) preserve more analytical value than smaller ones when high privacy is required.
- Fine-grained tuning between ε = 0.5 and 1.0 allows selection of an operating point that meets specific regulatory needs.
- The same parameterized approach can be reused on other mobile application datasets to meet data protection requirements.
Where Pith is reading between the lines
- The results suggest that real-time malware monitoring systems could embed RAPPOR at the data collection stage rather than after the fact.
- Similar parameter sweeps could be run on proprietary enterprise device logs to check whether the public-dataset patterns generalize.
- Regulators might reference these ε ranges when setting minimum privacy thresholds for mobile threat intelligence sharing.
Load-bearing premise
The chosen public Android application dataset, after filtering and sampling, is representative enough to demonstrate meaningful privacy-utility tradeoffs for RAPPOR in malware analysis contexts.
What would settle it
If aggregate statistics or malware detection signals extracted from the dataset show no measurable change in accuracy or clarity as ε decreases from 10 to 0.1, the expected privacy-utility tradeoff would not hold.
Figures
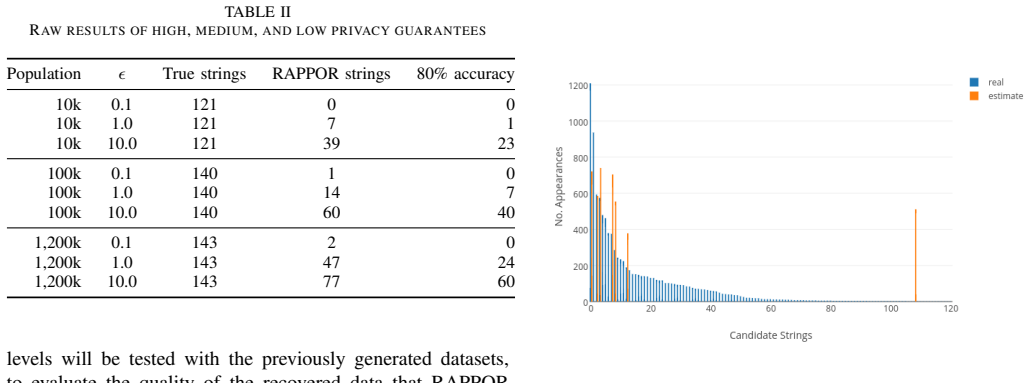



read the original abstract
Stricter data protection regulations and the poor application of privacy protection techniques have resulted in a requirement for data-driven companies to adopt new methods of analysing sensitive user data. The RAPPOR (Randomized Aggregatable Privacy-Preserving Ordinal Response) method adds parameterised noise, which must be carefully selected to maintain adequate privacy without losing analytical value. This paper applies RAPPOR privacy parameter variations against a public dataset containing a list of running Android applications data. The dataset is filtered and sampled into small (10,000); medium (100,000); and large (1,200,000) sample sizes while applying RAPPOR with ? = 10; 1.0; and 0.1 (respectively low; medium; high privacy guarantees). Also, in order to observe detailed variations within high to medium privacy guarantees (? = 0.5 to 1.0), a second experiment is conducted by progressively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that applying RAPPOR with privacy parameters ε = 10, 1.0, and 0.1 (low to high privacy) on filtered samples of sizes 10k, 100k, and 1.2M drawn from a public list of running Android applications demonstrates meaningful privacy-utility tradeoffs for RAPPOR in malware-analysis contexts; a second experiment varies ε progressively between 0.5 and 1.0.
Significance. If the results hold and include explicit utility metrics on a malware-relevant task, the work would supply concrete empirical guidance on ε selection for large-scale app telemetry. The manuscript contains no machine-checked proofs, reproducible code release, or parameter-free derivations, so its value rests entirely on the quality of the experimental design and downstream-task evaluation.
major comments (2)
- [Abstract / Experiments] Abstract and experimental setup: the central claim requires the filtered Android-app dataset to exhibit distributional properties relevant to malware tasks (rare malicious package names, heavy-tailed frequencies). The manuscript provides no evidence that the chosen public list of running applications, after sampling, preserves these properties or that any downstream malware task (frequency estimation of known malicious apps, anomaly detection) was performed; without such a task and a concrete utility metric, variation in noisy reports does not establish usable tradeoffs for the stated use case.
- [Experiments] Experiments description: no error bars, confidence intervals, or comparison baselines (e.g., non-private frequency estimates or alternative mechanisms) are reported for the recovered statistics at each (ε, N) pair. This omission prevents assessment of whether analytical value is actually preserved at ε = 1.0 or 0.1, directly undermining the privacy-utility tradeoff narrative.
minor comments (2)
- [Abstract] Abstract: the symbol “?” is used in place of ε; the final sentence is truncated (“a second experiment is conducted by progressively.”).
- [Throughout] Notation: inconsistent use of ε versus numeric placeholders across the text; define ε once and use it uniformly.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond to each major comment below and note the revisions planned.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental setup: the central claim requires the filtered Android-app dataset to exhibit distributional properties relevant to malware tasks (rare malicious package names, heavy-tailed frequencies). The manuscript provides no evidence that the chosen public list of running applications, after sampling, preserves these properties or that any downstream malware task (frequency estimation of known malicious apps, anomaly detection) was performed; without such a task and a concrete utility metric, variation in noisy reports does not establish usable tradeoffs for the stated use case.
Authors: The manuscript applies RAPPOR to samples from a public list of running Android applications and reports the resulting frequency estimates under different ε values. We agree that no explicit verification of heavy-tailed properties or rare malicious package names is provided, and no downstream malware task (such as anomaly detection on known malicious apps) is evaluated. The experiments instead focus on the direct effect of ε on recovered package-name frequencies. In revision we will add a discussion section linking frequency estimation to potential malware-analysis use cases and include a concrete utility metric (top-k frequency preservation relative to the non-private baseline). revision: yes
-
Referee: [Experiments] Experiments description: no error bars, confidence intervals, or comparison baselines (e.g., non-private frequency estimates or alternative mechanisms) are reported for the recovered statistics at each (ε, N) pair. This omission prevents assessment of whether analytical value is actually preserved at ε = 1.0 or 0.1, directly undermining the privacy-utility tradeoff narrative.
Authors: We acknowledge that the reported results lack error bars, confidence intervals, and explicit non-private baselines. This limits quantitative assessment of utility retention. In the revised version we will add confidence intervals for the frequency estimates at each (ε, N) combination and include side-by-side comparisons against the original non-private frequency counts to make the tradeoffs explicit. revision: yes
Circularity Check
Empirical parameter sweep with no derivation or self-referential predictions
full rationale
The paper conducts a straightforward empirical study: it filters and samples a public Android apps dataset into sizes 10k/100k/1.2M, then applies RAPPOR at fixed ε values (10, 1.0, 0.1 and a finer sweep 0.5–1.0). No equations, fitted parameters, or predictions are defined; the work reports observed noisy report statistics under these settings. No self-citations are used to justify uniqueness or load-bearing claims, and no step reduces by construction to its own inputs. This matches the default case of a self-contained empirical evaluation with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Facebook Is Now Selling Your Web-Browsing Data To Adverstisers,
C. Morran, “Facebook Is Now Selling Your Web-Browsing Data To Adverstisers,” 2016. [Online]. Available: https://consumerist.com/2014/ 06/12/facebook-is-now-selling-your-web-browsing-data-to-advertisers/
work page 2016
-
[2]
A Systematic Review of Re-Identification Attacks on Health Data,
K. El Emam, E. Jonker, L. Arbuckle, and B. Malin, “A Systematic Review of Re-Identification Attacks on Health Data,” PLoS ONE , vol. 6, no. 12, p. e28071, dec 2011. [Online]. Available: http: //dx.plos.org/10.1371/journal.pone.0028071
-
[3]
What are GDPR data controllers, processors, subjects and all the other actors?
D. Kelly, “What are GDPR data controllers, processors, subjects and all the other actors?” 2016. [Online]. Available: https://gdprchecklist.com/ what-are-gdpr-data-controllers-processors-subjects-and-all-the-other-actors/
work page 2016
-
[4]
Ú. Erlingsson, V . Pihur, and A. Korolova, “RAPPOR,” in Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security - CCS ’14 . New York, New York, USA: ACM Press, 2014, pp. 1054–1067. [Online]. Available: http://dl.acm.org/citation. cfm?doid=2660267.2660348
-
[5]
Anonymity, Unobservability, and Pseudonymity — A Proposal for Terminology,
A. Pfitzmann and M. Köhntopp, “Anonymity, Unobservability, and Pseudonymity — A Proposal for Terminology,” in Designing Privacy Enhancing Technologies: International Workshop on Design Issues in Anonymity and Unobservability Berkeley, CA, USA, July 25–26, 2000 Proceedings , H. Federrath, Ed. Berlin, Heidelberg: Springer Berlin Heidelberg, 2001, pp. 1–9. [O...
-
[6]
N. Harkiolakis, “Right to Privacy,” in Encyclopedia of Corporate Social Responsibility. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013, pp. 2082–2087. [Online]. Available: http://link.springer.com/10. 1007/978-3-642-28036-8{_}453
work page 2013
-
[7]
A Face Is Exposed for AOL Searcher No. 4417749,
M. Barbaro and T. Zeller, “A Face Is Exposed for AOL Searcher No. 4417749,” New York Times , no. 4417749, pp. 1–3, 2006. [Online]. Available: https://www.nytimes.com/2006/08/09/technology/09aol.html
work page 2006
-
[8]
Simple Demographics Often Identify People Uniquely,
L. Sweeney, “Simple Demographics Often Identify People Uniquely,” Data Privacy Working Paper , vol. 3, 2000. [Online]. Available: https://dataprivacylab.org/projects/identifiability/paper1.pdf
work page 2000
-
[9]
A. Narayanan and V . Shmatikov, “Myths and fallacies of "personally identifiable information",” Communications of the ACM , vol. 53, no. 6, p. 24, jun 2010. [Online]. Available: http://portal.acm.org/citation.cfm? doid=1743546.1743558
-
[10]
How To Break Anonymity of the Netflix Prize Dataset,
——, “How To Break Anonymity of the Netflix Prize Dataset,” oct
-
[11]
How To Break Anonymity of the Netflix Prize Dataset
[Online]. Available: http://arxiv.org/abs/cs/0610105
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
SherLock vs Moriarty: A Smartphone Dataset for Cybersecurity Research,
Y . Mirsky, A. Shabtai, L. Rokach, B. Shapira, and Y . Elovici, “SherLock vs Moriarty: A Smartphone Dataset for Cybersecurity Research,” in Proceedings of the 2016 ACM Workshop on Artificial Intelligence and Security - ALSec ’16 . New York, New York, USA: ACM Press, 2016, pp. 1–12. [Online]. Available: http: //dl.acm.org/citation.cfm?doid=2996758.2996764
-
[13]
C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating Noise to Sensitivity in Private Data Analysis,” in Proceedings of the 3rd Theory of Cryptography Conference (TCC) , 2006, pp. 265–284. [Online]. Available: https://link.springer.com/chapter/10.1007/ 11681878{_}14http://link.springer.com/10.1007/11681878{_}14
-
[14]
Will differential privacy take favour in the enterprise?
B. Rossi, “Will differential privacy take favour in the enterprise?” 2016. [Online]. Available: http://www.information-age. com/will-differential-privacy-take-favour-enterprise-123461324/
work page 2016
-
[15]
Using Randomized Response for Differential Privacy Preserving Data Collection,
Y . Wang, X. Wu, and D. Hu, “Using Randomized Response for Differential Privacy Preserving Data Collection,” in 9th International Workshop on Privacy and Anonymity in the Information Society (PAIS) ,
-
[16]
Available: http://ceur-ws.org/V ol-1558/paper35.pdf
[Online]. Available: http://ceur-ws.org/V ol-1558/paper35.pdf
-
[17]
Privacy-Conscious Information Diffusion in Social Networks,
G. Giakkoupis, R. Guerraoui, A. Jégou, A.-M. Kermarrec, and N. Mittal, “Privacy-Conscious Information Diffusion in Social Networks,” in Proceedings of the 29th International Symposium on Distributed Computing (DISC)1 , ser. Lecture Notes in Computer Science, Y . Moses, Ed. Berlin, Heidelberg: Springer Berlin Heidelberg, 2015, vol. 9363, pp. 480–496. [Onli...
-
[18]
Differential privacy in telco big data platform,
X. Hu, M. Yuan, J. Yao, Y . Deng, L. Chen, Q. Yang, H. Guan, and J. Zeng, “Differential privacy in telco big data platform,” Proceedings of the VLDB Endowment , vol. 8, no. 12, pp. 1692–1703, aug
-
[19]
Available: http://dl.acm.org/citation.cfm?doid=2824032
[Online]. Available: http://dl.acm.org/citation.cfm?doid=2824032. 2824067
-
[20]
Apple’s ’Differential Privacy’ Is About Collecting Your Data-But Not Your Data,
A. Greenberg, “Apple’s ’Differential Privacy’ Is About Collecting Your Data-But Not Your Data,” 2016. [Online]. Available: https: //www.wired.com/2016/06/apples-differential-privacy-collecting-data/
work page 2016
-
[21]
F. D. McSherry, “Privacy integrated queries,” in Proceedings of the 35th SIGMOD international conference on Management of data - SIGMOD ’09 . New York, New York, USA: ACM Press, 2009, p. 19. [Online]. Available: https://www.microsoft. com/en-us/research/project/privacy-integrated-queries-pinq/http: //portal.acm.org/citation.cfm?doid=1559845.1559850
-
[22]
Research Blog: Learning Statistics with Privacy, aided by the Flip of a Coin,
Ú. Erlingsson, “Research Blog: Learning Statistics with Privacy, aided by the Flip of a Coin,” 2014. [Online]. Available: https://research. googleblog.com/2014/10/learning-statistics-with-privacy-aided.html
work page 2014
-
[23]
The Algorithmic Foundations of Differential Privacy,
C. Dwork and A. Roth, “The Algorithmic Foundations of Differential Privacy,” Foundations and Trends® in Theoretical Computer Science , vol. 9, no. 3-4, pp. 211–407,
-
[24]
[Online]. Available: https://www.cis.upenn.edu/{~}aaroth/ Papers/privacybook.pdfhttp://www.nowpublishers.com/articles/ foundations-and-trends-in-theoretical-computer-science/TCS-042
-
[25]
C. Dwork, “Differential Privacy,” in Automata, Languages and Programming, 2006, vol. 33, pp. 1–12. [Online]. Available: http: //link.springer.com/10.1007/11787006{_}1
-
[26]
Differential Privacy: An Economic Method for Choosing Epsilon
J. Hsu, M. Gaboardi, A. Haeberlen, S. Khanna, A. Narayan, B. C. Pierce, and A. Roth, “Differential Privacy: An Economic Method for Choosing Epsilon,” 2014 IEEE 27th Computer Security Foundations Symposium , vol. 2014-Janua, pp. 398–410, feb 2014. [Online]. Available: http://arxiv.org/abs/1402.3329http://dx.doi.org/10.1109/CSF.2014.35
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/csf.2014.35 2014
-
[27]
Defining privacy based on distributions of privacy breaches,
M. Huber, J. Müller-Quade, and T. Nilges, “Defining privacy based on distributions of privacy breaches,” Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 8260 LNCS, pp. 211–225, 2013. [Online]. Available: http://link.springer.com/10.1007/978-3-642-42001-6{_}15
-
[28]
A firm foundation for private data analysis,
C. Dwork, “A firm foundation for private data analysis,” Communications of the ACM , vol. 54, no. 1, p. 86, jan 2011. [Online]. Available: http://portal.acm.org/citation.cfm?doid=1866739.1866758
-
[29]
S. Goldwasser, Y . Ishai, and J. B. Nielsen, “Test-of-Time Award,” 2016. [Online]. Available: https://www.iacr.org/workshops/tcc/awards.html
work page 2016
-
[30]
G. Fanti, V . Pihur, and Ú. Erlingsson, “Building a RAPPOR with the Unknown: Privacy-Preserving Learning of Associations and Data Dictionaries,” Proceedings on Privacy Enhancing Technologies, vol. 2016, no. 3, pp. 1–21, jan 2016. [Online]. Available: http://www.degruyter.com/view/j/popets. 2016.2016.issue-3/popets-2016-0015/popets-2016-0015.xmlhttp: //con...
-
[31]
Space/time trade-offs in hash coding with allowable errors,
B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,” Communications of the ACM , vol. 13, no. 7, pp. 422–426, jul 1970. [Online]. Available: http://portal.acm.org/citation.cfm?doid= 362686.362692
-
[32]
Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias,
S. L. Warner, “Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias,” Journal of the American Statistical Association, vol. 60, no. 309, pp. 63–69, mar 1965. [Online]. Available: http://www.tandfonline.com/doi/abs/10.1080/01621459.1965.10480775
-
[33]
How Mobile Apps are Invading Your Privacy Infographic,
N. Lord, “How Mobile Apps are Invading Your Privacy Infographic,” 2012. [Online]. Available: www.veracode.com/blog/ 2012/05/how-mobile-apps-are-invading-your-privacy-infographic
work page 2012
-
[34]
Scripts to automate testing of RAPPOR,
J. J. M. de Acuña, “Scripts to automate testing of RAPPOR,” 2018. [Online]. Available: https://github.com/ricemiller/rappor-scripts
work page 2018
-
[35]
Differentially-private network trace analysis,
F. McSherry and R. Mahajan, “Differentially-private network trace analysis,” ACM SIGCOMM Computer Communication Review , vol. 40, no. 4, p. 123, aug 2010. [Online]. Available: http://dl.acm.org/citation. cfm?doid=1851275.1851199
-
[36]
Differentially Private Empirical Risk Minimization
A. D. Sarwate and C. Monteleoni, “Differentially Private Support Vector Machines,” Communication, pp. 1–23, nov 2010. [Online]. Available: https://arxiv.org/abs/0912.0071v1
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.