ShuffleFlow: Scalable Posterior Inference for Bayesian Inverse Imaging
Pith reviewed 2026-06-26 14:52 UTC · model grok-4.3
The pith
ShuffleFlow scales variational inference for large image reconstruction by partitioning into sub-image stacks modeled with a shared conditional normalizing flow conditioned on neural field features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
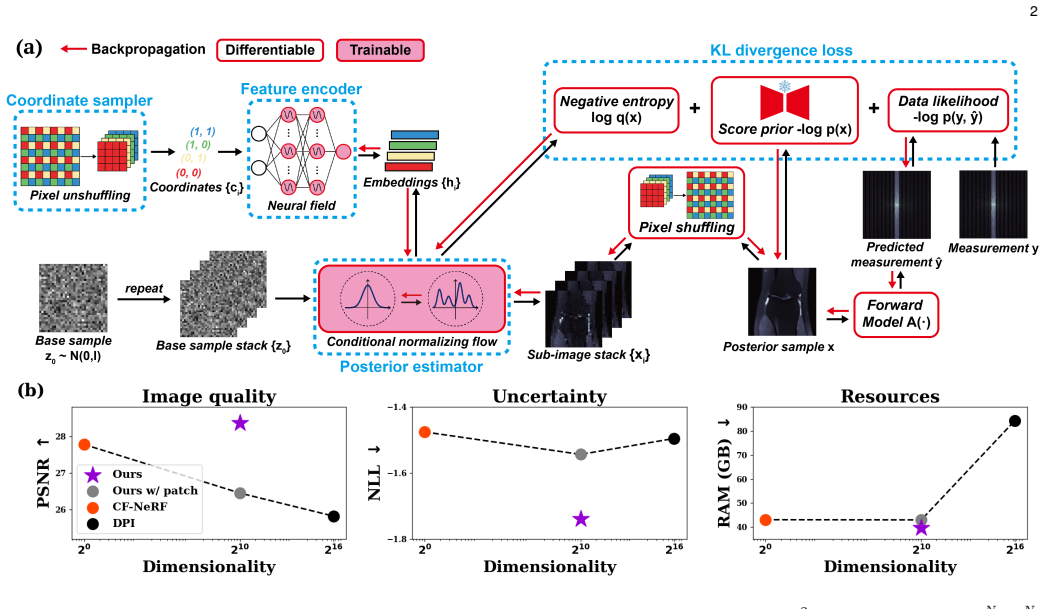
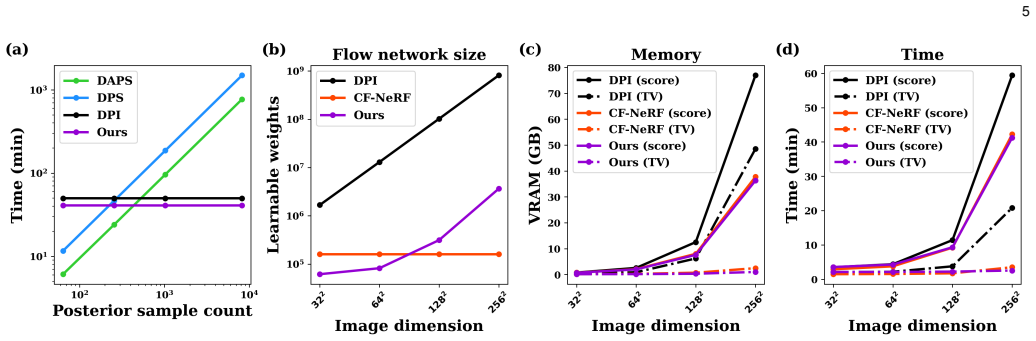
By partitioning an image into a stack of sub-images with pixel-unshuffling, embedding the sample locations via a neural field, and modeling the joint distribution of the stack with a single conditional normalizing flow whose latent variable is shared across channels, the framework produces a scalable posterior estimator that works for both linear and nonlinear Bayesian inverse imaging problems and generates high-sample-count posteriors faster than diffusion samplers.
What carries the argument
Pixel-unshuffling into a sub-image stack together with a neural field feature encoder and a shared conditional normalizing flow with shared latent variables.
If this is right
- The approach applies directly to both linear and nonlinear imaging inverse problems.
- It produces high-sample-count posteriors more rapidly than diffusion samplers.
- It can incorporate score-based or classic priors without changing the core architecture.
- It extends the practical size of images for which full posterior inference remains feasible.
Where Pith is reading between the lines
- The same unshuffling-plus-shared-flow pattern could be tested on video or volumetric data where full joint flows are likewise intractable.
- Coordinate-based conditioning may prove useful in other high-dimensional generative tasks that currently rely on full-image networks.
- Direct comparison against exact posteriors on toy problems would give a quantitative bound on the approximation error introduced by the factorization.
Load-bearing premise
That modeling the joint distribution of the unshuffled sub-image stack with one shared flow conditioned only on neural field features will retain enough spatial structure and channel correlations to represent the true posterior accurately.
What would settle it
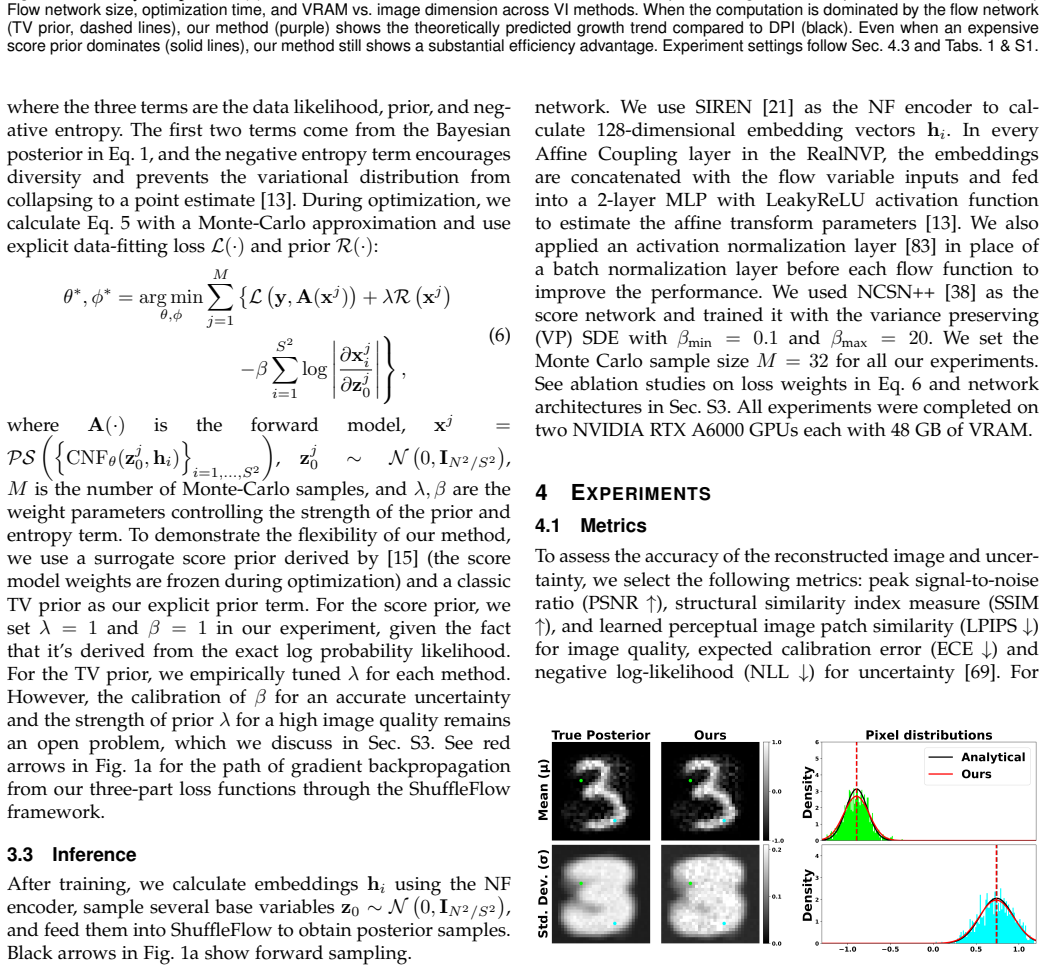
On a small inverse problem whose exact posterior is known analytically or by exhaustive computation, draw samples from ShuffleFlow and test whether their empirical distribution matches the true posterior within a chosen statistical distance such as maximum mean discrepancy or total variation.
Figures
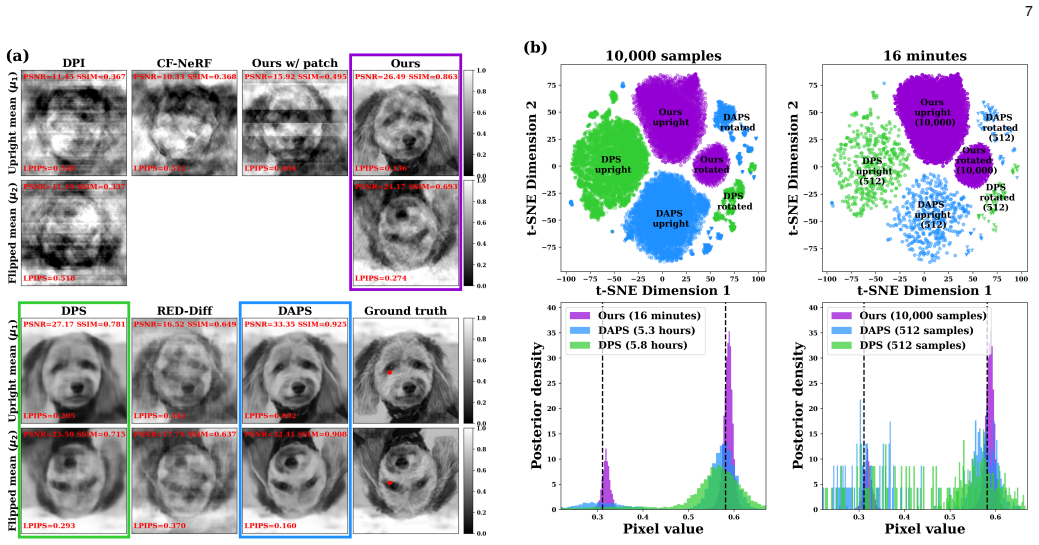

read the original abstract
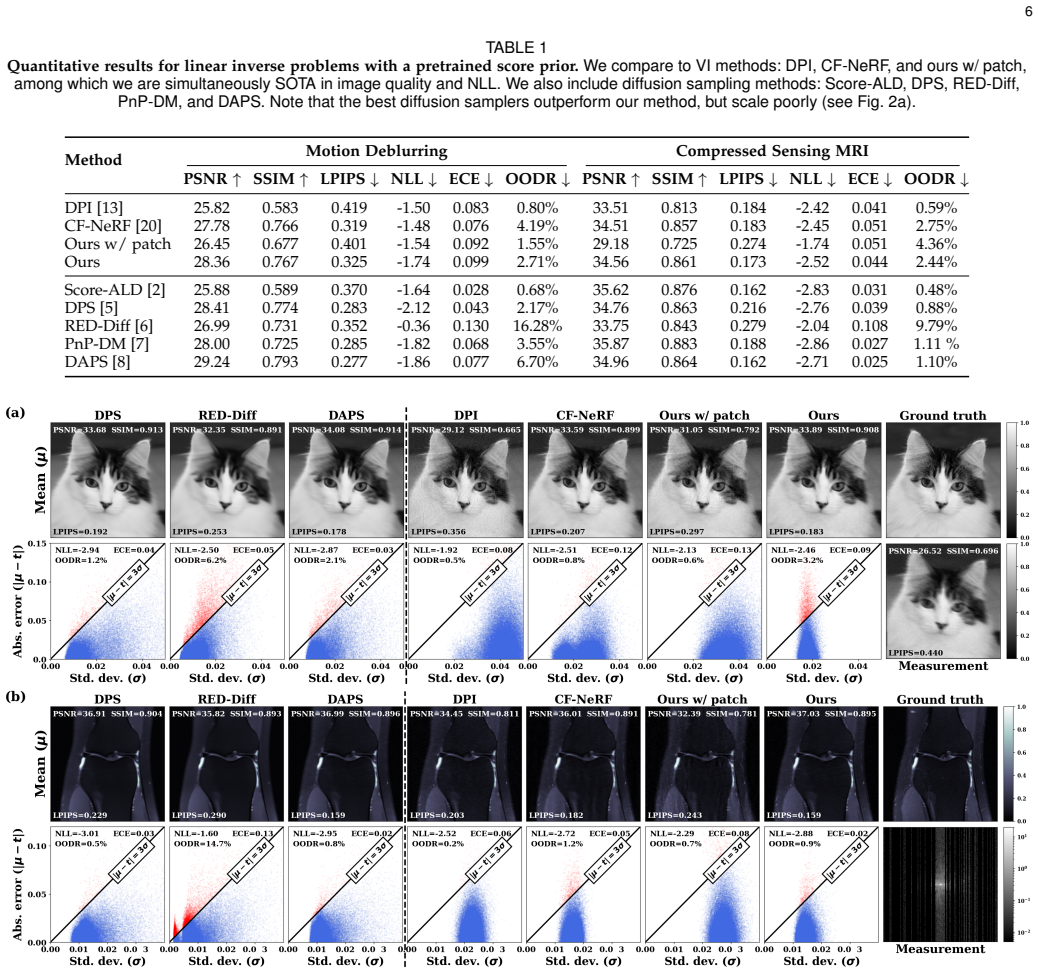
Variational inference (VI) is a powerful method for principled posterior inference for scientific inverse imaging. VI learns the posterior distribution, often with a flow-based network, which can cheaply generate posterior samples upon optimization, and can flexibly incorporate score-based or classic priors. However, its application to large-scale image reconstruction is severely hindered by the poor scalability of the flow-based networks. In this work, we introduce ShuffleFlow, a scalable VI framework to address this challenge. Our method breaks down the problem into three parts: a pixel-unshuffling-based image coordinate sampler, a neural field as feature encoder, and a conditional normalizing flow (CNF) as posterior estimator. Specifically, our framework partitions an image into a stack of sub-images with pixel-unshuffling and uses a shared CNF to model the joint distribution of the sub-image stack. We condition the CNF on the output of a neural field, which embeds feature vectors corresponding to pixel-unshuffling sample locations to capture spatial structures, and share the flow's latent variable across the channels to model their correlations. We demonstrate our method's effectiveness and efficiency on both linear and nonlinear imaging inverse problems, and show its ability to more rapidly generate a high-sample-count posterior than diffusion samplers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ShuffleFlow, a scalable variational inference framework for Bayesian inverse imaging. It decomposes the problem via pixel-unshuffling to form a stack of sub-images, encodes spatial features with a neural field, and employs a single conditional normalizing flow (CNF) applied to the stack, conditioned on the neural-field outputs and using a shared latent variable across channels to capture correlations. The authors claim the method is effective and efficient on both linear and nonlinear inverse problems and generates high-sample-count posteriors more rapidly than diffusion samplers.
Significance. If the central architectural assumptions hold and the method recovers accurate posteriors, it would address a key scalability barrier in flow-based VI for large images and offer a practical alternative to diffusion sampling when many posterior draws are needed. The combination of unshuffling, neural fields, and shared-latent CNF is a concrete proposal for factoring the modeling problem.
major comments (2)
- [Abstract] Abstract: the effectiveness and efficiency claims for both linear and nonlinear imaging inverse problems are stated without any equations, experimental results, error bars, baselines, or validation details, so the claims cannot be assessed from the provided text.
- [Abstract] Abstract (method description): the claim that the joint posterior is accurately recovered by applying a shared CNF to the unshuffled sub-image stack, conditioned only on neural-field features at sample locations and a single shared latent z, requires justification for nonlinear forward operators. Inter-pixel and inter-channel posterior dependencies are typically non-stationary and high-order; the implicit factorization via translation-equivariant unshuffling, shared flow, and broadcast z may lose expressivity and produce biased posteriors even if the ELBO is optimized, directly affecting both the effectiveness claim and the comparison to diffusion baselines.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each major comment below, providing clarifications and indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the effectiveness and efficiency claims for both linear and nonlinear imaging inverse problems are stated without any equations, experimental results, error bars, baselines, or validation details, so the claims cannot be assessed from the provided text.
Authors: We agree that the abstract, by design, offers a high-level summary without quantitative details or equations. The full manuscript presents the requested elements—including experimental results with error bars, baselines, and validation metrics for both linear and nonlinear problems—in the Experiments and Results sections. We will revise the abstract to include a brief reference to key quantitative findings to improve standalone readability. revision: partial
-
Referee: [Abstract] Abstract (method description): the claim that the joint posterior is accurately recovered by applying a shared CNF to the unshuffled sub-image stack, conditioned only on neural-field features at sample locations and a single shared latent z, requires justification for nonlinear forward operators. Inter-pixel and inter-channel posterior dependencies are typically non-stationary and high-order; the implicit factorization via translation-equivariant unshuffling, shared flow, and broadcast z may lose expressivity and produce biased posteriors even if the ELBO is optimized, directly affecting both the effectiveness claim and the comparison to diffusion baselines.
Authors: The manuscript justifies the approach through the neural field's spatially varying features, which adapt to non-stationary structures, combined with the shared latent variable that explicitly couples channels. Empirical results on nonlinear inverse problems (detailed in the Experiments section) show posterior accuracy comparable to diffusion baselines across multiple metrics, indicating that the factorization does not introduce substantial bias in the evaluated settings. We will expand the discussion of modeling assumptions and limitations for nonlinear operators in the revised manuscript. revision: partial
Circularity Check
No circularity: architectural construction with no derivation chain or self-referential reductions
full rationale
The paper introduces ShuffleFlow as an architectural framework combining pixel-unshuffling, a neural field feature encoder, and a shared conditional normalizing flow. No equations, derivations, or parameter-fitting steps are described that reduce a claimed prediction or result back to its own inputs by construction. Claims rest on the empirical performance of the proposed model rather than any mathematical identity or self-citation load-bearing uniqueness theorem. This is a standard non-circular presentation of a new VI architecture.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Solving inverse problems in medical imaging with score-based generative models,
Y. Song, L. Shen, L. Xing, and S. Ermon, “Solving inverse problems in medical imaging with score-based generative models,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=vaRCHVj0uGI
2022
-
[2]
Robust compressed sensing mri with deep generative priors,
A. Jalal, M. Arvinte, G. Daras, E. Price, A. G. Dimakis, and J. Tamir, “Robust compressed sensing mri with deep generative priors,”Advances in Neural Information Processing Systems, vol. 34, pp. 14 938–14 954, 2021
2021
-
[3]
Denoising diffusion restoration models,
B. Kawar, M. Elad, S. Ermon, and J. Song, “Denoising diffusion restoration models,”Advances in Neural Information Processing Sys- tems, vol. 35, pp. 23 593–23 606, 2022
2022
-
[4]
Diffusion models as plug-and-play priors,
A. Graikos, N. Malkin, N. Jojic, and D. Samaras, “Diffusion models as plug-and-play priors,”Advances in Neural Information Processing Systems, vol. 35, pp. 14 715–14 728, 2022
2022
-
[5]
Dif- fusion posterior sampling for general noisy inverse problems,
H. Chung, J. Kim, M. T. McCann, M. L. Klasky, and J. C. Ye, “Dif- fusion posterior sampling for general noisy inverse problems,” in 11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[6]
A variational perspective on solving inverse problems with diffusion models,
M. Mardani, J. Song, J. Kautz, and A. Vahdat, “A variational perspective on solving inverse problems with diffusion models,” inThe Twelfth International Conference on Learning Representations,
-
[7]
Available: https://openreview.net/forum?id= 1YO4EE3SPB
[Online]. Available: https://openreview.net/forum?id= 1YO4EE3SPB
-
[8]
Principled probabilistic imaging using diffusion models as plug- and-play priors,
Z. Wu, Y. Sun, Y. Chen, B. Zhang, Y. Yue, and K. Bouman, “Principled probabilistic imaging using diffusion models as plug- and-play priors,”Advances in Neural Information Processing Systems, vol. 37, pp. 118 389–118 427, 2024
2024
-
[9]
Improving diffusion inverse problem solving with de- coupled noise annealing,
B. Zhang, W. Chu, J. Berner, C. Meng, A. Anandkumar, and Y. Song, “Improving diffusion inverse problem solving with de- coupled noise annealing,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 20 895–20 905
2025
-
[10]
Posterior samples of source galaxies in strong gravitational lenses with score-based priors,
A. Adam, A. Coogan, N. Malkin, R. Legin, L. Perreault-Levasseur, Y. Hezaveh, and Y. Bengio, “Posterior samples of source galaxies in strong gravitational lenses with score-based priors,”arXiv preprint arXiv:2211.03812, 2022
arXiv 2022
-
[11]
Strong- lensing source reconstruction with denoising diffusion restoration models,
K. Karchev, N. A. Montel, A. Coogan, and C. Weniger, “Strong- lensing source reconstruction with denoising diffusion restoration models,”arXiv preprint arXiv:2211.04365, 2022
arXiv 2022
-
[12]
Event-horizon-scale imaging of m87* under different assumptions via deep generative image priors,
B. T. Feng, K. L. Bouman, and W. T. Freeman, “Event-horizon-scale imaging of m87* under different assumptions via deep generative image priors,”arXiv preprint arXiv:2406.02785, 2024
arXiv 2024
-
[13]
G. M. Barco, R. Legin, C. Stone, Y. Hezaveh, and L. Perreault- Levasseur, “Blind strong gravitational lensing inversion: Joint inference of source and lens mass with score-based models,”arXiv preprint arXiv:2511.04792, 2025
arXiv 2025
-
[14]
Deep probabilistic imaging: Uncer- tainty quantification and multi-modal solution characterization for computational imaging,
H. Sun and K. L. Bouman, “Deep probabilistic imaging: Uncer- tainty quantification and multi-modal solution characterization for computational imaging,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 3, 2021, pp. 2628–2637
2021
-
[15]
Score-based diffusion models as principled priors for inverse imaging,
B. T. Feng, J. Smith, M. Rubinstein, H. Chang, K. L. Bouman, and W. T. Freeman, “Score-based diffusion models as principled priors for inverse imaging,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 520–10 531
2023
-
[16]
Variational bayesian imaging with an efficient surrogate score-based prior,
B. Feng and K. Bouman, “Variational bayesian imaging with an efficient surrogate score-based prior,”Transactions on Machine Learning Research, 2024. [Online]. Available: https: //openreview.net/forum?id=db2pFKVcm1
2024
-
[17]
α-deep probabilistic inference (α-dpi): efficient uncertainty quan- tification from exoplanet astrometry to black hole feature extrac- tion,
H. Sun, K. L. Bouman, P . Tiede, J. J. Wang, S. Blunt, and D. Mawet, “α-deep probabilistic inference (α-dpi): efficient uncertainty quan- tification from exoplanet astrometry to black hole feature extrac- tion,”The Astrophysical Journal, vol. 932, no. 2, p. 99, 2022
2022
-
[18]
On the robustness of normal- izing flows for inverse problems in imaging,
S. Hong, I. Park, and S. Y. Chun, “On the robustness of normal- izing flows for inverse problems in imaging,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 745–10 755
2023
-
[19]
Gaussianization flows,
C. Meng, Y. Song, J. Song, and S. Ermon, “Gaussianization flows,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2020, pp. 4336–4345
2020
-
[20]
Stochastic neural radiance fields: Quantifying uncertainty in implicit 3d rep- resentations,
J. Shen, A. Ruiz, A. Agudo, and F. Moreno-Noguer, “Stochastic neural radiance fields: Quantifying uncertainty in implicit 3d rep- resentations,” in2021 International Conference on 3D Vision (3DV). IEEE, 2021, pp. 972–981
2021
-
[21]
Conditional- flow nerf: Accurate 3d modelling with reliable uncertainty quan- tification,
J. Shen, A. Agudo, F. Moreno-Noguer, and A. Ruiz, “Conditional- flow nerf: Accurate 3d modelling with reliable uncertainty quan- tification,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 540–557
2022
-
[22]
Implicit neural representations with periodic activation func- tions,
V . Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation func- tions,”Advances in neural information processing systems, vol. 33, pp. 7462–7473, 2020
2020
-
[23]
On the local behavior of spaces of natural images,
G. Carlsson, T. Ishkhanov, V . De Silva, and A. Zomorodian, “On the local behavior of spaces of natural images,”International jour- nal of computer vision, vol. 76, no. 1, pp. 1–12, 2008
2008
-
[24]
Testing the manifold hypothesis,
C. Fefferman, S. Mitter, and H. Narayanan, “Testing the manifold hypothesis,”Journal of the American Mathematical Society, vol. 29, no. 4, pp. 983–1049, 2016
2016
-
[25]
Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network,
W. Shi, J. Caballero, F. Husz ´ar, J. Totz, A. P . Aitken, R. Bishop, D. Rueckert, and Z. Wang, “Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1874–1883
2016
-
[26]
Frame-recurrent video super-resolution,
M. S. Sajjadi, R. Vemulapalli, and M. Brown, “Frame-recurrent video super-resolution,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6626–6634
2018
-
[27]
Self-guided network for fast image denoising,
S. Gu, Y. Li, L. V . Gool, and R. Timofte, “Self-guided network for fast image denoising,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 2511–2520
2019
-
[28]
Nonlinear total variation based noise removal algorithms,
L. I. Rudin, S. Osher, and E. Fatemi, “Nonlinear total variation based noise removal algorithms,”Physica D: nonlinear phenomena, vol. 60, no. 1-4, pp. 259–268, 1992
1992
-
[29]
Sparsity and incoherence in compres- sive sampling,
E. Candes and J. Romberg, “Sparsity and incoherence in compres- sive sampling,”Inverse problems, vol. 23, no. 3, p. 969, 2007
2007
-
[30]
Plug-and- play priors for model based reconstruction,
S. V . Venkatakrishnan, C. A. Bouman, and B. Wohlberg, “Plug-and- play priors for model based reconstruction,” in2013 IEEE global conference on signal and information processing. IEEE, 2013, pp. 945–948
2013
-
[31]
Plug-and-play admm for image restoration: Fixed-point convergence and applications,
S. H. Chan, X. Wang, and O. A. Elgendy, “Plug-and-play admm for image restoration: Fixed-point convergence and applications,” IEEE Transactions on Computational Imaging, vol. 3, no. 1, pp. 84–98, 2016
2016
-
[32]
The little engine that could: Regularization by denoising (red),
Y. Romano, M. Elad, and P . Milanfar, “The little engine that could: Regularization by denoising (red),”SIAM Journal on Imaging Sci- ences, vol. 10, no. 4, pp. 1804–1844, 2017
2017
-
[33]
Learned reconstructions for practical mask-based lens- less imaging,
K. Monakhova, J. Yurtsever, G. Kuo, N. Antipa, K. Yanny, and L. Waller, “Learned reconstructions for practical mask-based lens- less imaging,”Optics express, vol. 27, no. 20, pp. 28 075–28 090, 2019
2019
-
[34]
Scalable plug-and-play admm with convergence guarantees,
Y. Sun, Z. Wu, X. Xu, B. Wohlberg, and U. S. Kamilov, “Scalable plug-and-play admm with convergence guarantees,”IEEE Trans- actions on Computational Imaging, vol. 7, pp. 849–863, 2021
2021
-
[35]
Galaxy image deconvolution for weak gravitational lensing with unrolled plug-and-play admm,
T. Li and E. Alexander, “Galaxy image deconvolution for weak gravitational lensing with unrolled plug-and-play admm,” Monthly Notices of the Royal Astronomical Society: Letters, vol. 522, no. 1, pp. L31–L35, 2023. 10
2023
-
[36]
Generative modeling by estimating gra- dients of the data distribution,
Y. Song and S. Ermon, “Generative modeling by estimating gra- dients of the data distribution,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[37]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
-
[38]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,”arXiv preprint arXiv:2010.02502, 2020
Pith/arXiv arXiv 2010
-
[39]
Score-based generative modeling through stochastic differential equations,
Y. Song, J. Sohl-Dickstein, D. P . Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,”arXiv preprint arXiv:2011.13456, 2020
Pith/arXiv arXiv 2011
-
[40]
Score-based diffusion models for acceler- ated mri,
H. Chung and J. C. Ye, “Score-based diffusion models for acceler- ated mri,”Medical image analysis, vol. 80, p. 102479, 2022
2022
-
[41]
Improving diffusion mod- els for inverse problems using manifold constraints,
H. Chung, B. Sim, D. Ryu, and J. C. Ye, “Improving diffusion mod- els for inverse problems using manifold constraints,”Advances in Neural Information Processing Systems, vol. 35, pp. 25 683–25 696, 2022
2022
-
[42]
Neural fields in visual computing and beyond,
Y. Xie, T. Takikawa, S. Saito, O. Litany, S. Yan, N. Khan, F. Tombari, J. Tompkin, V . Sitzmann, and S. Sridhar, “Neural fields in visual computing and beyond,” inComputer Graphics Forum, vol. 41, no. 2. Wiley Online Library, 2022, pp. 641–676
2022
-
[43]
Nerf in the wild: Neural radiance fields for unconstrained photo collections,
R. Martin-Brualla, N. Radwan, M. S. Sajjadi, J. T. Barron, A. Doso- vitskiy, and D. Duckworth, “Nerf in the wild: Neural radiance fields for unconstrained photo collections,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 7210–7219
2021
-
[44]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P . P . Srinivasan, M. Tancik, J. T. Barron, R. Ra- mamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[45]
Mip-nerf: A multiscale represen- tation for anti-aliasing neural radiance fields,
J. T. Barron, B. Mildenhall, M. Tancik, P . Hedman, R. Martin- Brualla, and P . P . Srinivasan, “Mip-nerf: A multiscale represen- tation for anti-aliasing neural radiance fields,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 5855–5864
2021
-
[46]
Coil: Coordinate-based internal learning for tomographic imaging,
Y. Sun, J. Liu, M. Xie, B. Wohlberg, and U. S. Kamilov, “Coil: Coordinate-based internal learning for tomographic imaging,” IEEE Transactions on Computational Imaging, vol. 7, pp. 1400–1412, 2021
2021
-
[47]
Intratomo: self-supervised learning-based tomography via sinogram synthe- sis and prediction,
G. Zang, R. Idoughi, R. Li, P . Wonka, and W. Heidrich, “Intratomo: self-supervised learning-based tomography via sinogram synthe- sis and prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1960–1970
2021
-
[48]
Recovery of continuous 3d refractive index maps from discrete intensity-only measurements using neural fields,
R. Liu, Y. Sun, J. Zhu, L. Tian, and U. S. Kamilov, “Recovery of continuous 3d refractive index maps from discrete intensity-only measurements using neural fields,”Nature Machine Intelligence, vol. 4, no. 9, pp. 781–791, 2022
2022
-
[49]
Nerp: implicit neural representa- tion learning with prior embedding for sparsely sampled image reconstruction,
L. Shen, J. Pauly, and L. Xing, “Nerp: implicit neural representa- tion learning with prior embedding for sparsely sampled image reconstruction,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 1, pp. 770–782, 2022
2022
-
[50]
Implicit neural representation in medical imaging: A comparative survey,
A. Molaei, A. Aminimehr, A. Tavakoli, A. Kazerouni, B. Azad, R. Azad, and D. Merhof, “Implicit neural representation in medical imaging: A comparative survey,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2381–2391
2023
-
[51]
Fourier ptychographic microscopy image stack re- construction using implicit neural representations,
H. Zhou, B. Y. Feng, H. Guo, S. S. Lin, M. Liang, C. A. Metzler, and C. Yang, “Fourier ptychographic microscopy image stack re- construction using implicit neural representations,”Optica, vol. 10, no. 12, pp. 1679–1687, 2023
2023
-
[52]
Nesvor: implicit neural representation for slice-to-volume reconstruction in mri,
J. Xu, D. Moyer, B. Gagoski, J. E. Iglesias, P . E. Grant, P . Golland, and E. Adalsteinsson, “Nesvor: implicit neural representation for slice-to-volume reconstruction in mri,”IEEE transactions on medical imaging, vol. 42, no. 6, pp. 1707–1719, 2023
2023
-
[53]
Neural space–time model for dynamic multi-shot imaging,
R. Cao, N. S. Divekar, J. K. Nu ˜nez, S. Upadhyayula, and L. Waller, “Neural space–time model for dynamic multi-shot imaging,”Na- ture Methods, pp. 1–6, 2024
2024
-
[54]
Coordinate-based speed of sound recovery for aberration-corrected photoacoustic computed tomography,
T. Li, M. Cui, C. Ma, and E. Alexander, “Coordinate-based speed of sound recovery for aberration-corrected photoacoustic computed tomography,” inProceedings of the IEEE/CVF International Confer- ence on Computer Vision, 2025, pp. 27 466–27 475
2025
-
[55]
Variational inference with normal- izing flows,
D. Rezende and S. Mohamed, “Variational inference with normal- izing flows,” inInternational conference on machine learning. PMLR, 2015, pp. 1530–1538
2015
-
[56]
Normalizing flows for probabilistic mod- eling and inference,
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, and B. Lakshminarayanan, “Normalizing flows for probabilistic mod- eling and inference,”Journal of Machine Learning Research, vol. 22, no. 57, pp. 1–64, 2021
2021
-
[57]
Pointflow: 3d point cloud generation with continuous normalizing flows,
G. Yang, X. Huang, Z. Hao, M.-Y. Liu, S. Belongie, and B. Har- iharan, “Pointflow: 3d point cloud generation with continuous normalizing flows,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4541–4550
2019
-
[58]
C- flow: Conditional generative flow models for images and 3d point clouds,
A. Pumarola, S. Popov, F. Moreno-Noguer, and V . Ferrari, “C- flow: Conditional generative flow models for images and 3d point clouds,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 7949–7958
2020
-
[59]
Sliced iterative normalizing flows,
B. Dai and U. Seljak, “Sliced iterative normalizing flows,” in International Conference on Machine Learning. PMLR, 2021, pp. 2352–2364
2021
-
[60]
Mcmc-based image reconstruction with uncer- tainty quantification,
J. M. Bardsley, “Mcmc-based image reconstruction with uncer- tainty quantification,”SIAM Journal on Scientific Computing, vol. 34, no. 3, pp. A1316–A1332, 2012
2012
-
[61]
Bayesian imaging using plug & play priors: when langevin meets tweedie,
R. Laumont, V . D. Bortoli, A. Almansa, J. Delon, A. Durmus, and M. Pereyra, “Bayesian imaging using plug & play priors: when langevin meets tweedie,”SIAM Journal on Imaging Sciences, vol. 15, no. 2, pp. 701–737, 2022
2022
-
[62]
Monte carlo guided diffusion for bayesian linear inverse problems,
G. Cardoso, Y. J. E. Idrissi, S. L. Corff, and E. Moulines, “Monte carlo guided diffusion for bayesian linear inverse problems,”arXiv preprint arXiv:2308.07983, 2023
arXiv 2023
-
[63]
Provable probabilistic imaging using score-based generative priors,
Y. Sun, Z. Wu, Y. Chen, B. T. Feng, and K. L. Bouman, “Provable probabilistic imaging using score-based generative priors,”IEEE Transactions on Computational Imaging, 2024
2024
-
[64]
Scalable bayesian un- certainty quantification in imaging inverse problems via convex optimization,
A. Repetti, M. Pereyra, and Y. Wiaux, “Scalable bayesian un- certainty quantification in imaging inverse problems via convex optimization,”SIAM Journal on Imaging Sciences, vol. 12, no. 1, pp. 87–118, 2019
2019
-
[65]
Variational infer- ence: A review for statisticians,
D. M. Blei, A. Kucukelbir, and J. D. McAuliffe, “Variational infer- ence: A review for statisticians,”Journal of the American statistical Association, vol. 112, no. 518, pp. 859–877, 2017
2017
-
[66]
R. M. Neal,Bayesian learning for neural networks. Springer Science & Business Media, 2012, vol. 118
2012
-
[67]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” ininternational conference on machine learning. PMLR, 2016, pp. 1050–1059
2016
-
[68]
What uncertainties do we need in bayesian deep learning for computer vision?
A. Kendall and Y. Gal, “What uncertainties do we need in bayesian deep learning for computer vision?”Advances in neural information processing systems, vol. 30, 2017
2017
-
[69]
Reliable deep-learning-based phase imaging with uncertainty quantification,
Y. Xue, S. Cheng, Y. Li, and L. Tian, “Reliable deep-learning-based phase imaging with uncertainty quantification,”Optica, vol. 6, no. 5, pp. 618–629, 2019
2019
-
[70]
F. Vasconcelos, B. He, N. Singh, and Y. W. Teh, “Uncertainr: Uncer- tainty quantification of end-to-end implicit neural representations for computed tomography,”arXiv preprint arXiv:2202.10847, 2022
arXiv 2022
-
[71]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[72]
Equivariant bootstrapping for uncer- tainty quantification in imaging inverse problems,
M. Pereyra and J. Tachella, “Equivariant bootstrapping for uncer- tainty quantification in imaging inverse problems,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2024, pp. 4141–4149
2024
-
[73]
Image-to-image regression with distribution-free uncertainty quantification and applications in imaging,
A. N. Angelopoulos, A. P . Kohli, S. Bates, M. Jordan, J. Malik, T. Alshaabi, S. Upadhyayula, and Y. Romano, “Image-to-image regression with distribution-free uncertainty quantification and applications in imaging,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 717–730
2022
-
[74]
Learned, uncertainty-driven adaptive acqui- sition for photon-efficient scanning microscopy,
C. T. Ye, J. Han, K. Liu, A. Angelopoulos, L. Griffith, K. Mon- akhova, and S. You, “Learned, uncertainty-driven adaptive acqui- sition for photon-efficient scanning microscopy,”Optics Express, vol. 33, no. 6, pp. 12 269–12 287, 2025
2025
-
[75]
Density estimation using real nvp,
L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real nvp,”arXiv preprint arXiv:1605.08803, 2016
Pith/arXiv arXiv 2016
-
[76]
On the intrinsic dimen- sionality of image representations,
S. Gong, V . N. Boddeti, and A. K. Jain, “On the intrinsic dimen- sionality of image representations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3987–3996
2019
-
[77]
The intrinsic dimension of images and its impact on learning,
P . Pope, C. Zhu, A. Abdelkader, M. Goldblum, and T. Goldstein, “The intrinsic dimension of images and its impact on learning,” arXiv preprint arXiv:2104.08894, 2021
arXiv 2021
-
[78]
Understanding representation dynamics of diffusion models via low-dimensional modeling,
X. Li, Z. Zhang, X. Li, S. Chen, Z. Zhu, P . Wang, and Q. Qu, “Understanding representation dynamics of diffusion models via low-dimensional modeling,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=BE6QmLdJqY
2025
-
[79]
Neighbor2neighbor: Self- supervised denoising from single noisy images,
T. Huang, S. Li, X. Jia, H. Lu, and J. Liu, “Neighbor2neighbor: Self- supervised denoising from single noisy images,” inProceedings of 11 the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 781–14 790
2021
-
[80]
Zero-shot noise2noise: Efficient image denoising without any data,
Y. Mansour and R. Heckel, “Zero-shot noise2noise: Efficient image denoising without any data,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2023, pp. 14 018– 14 027
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.