TrafficRAG: A Multimodal RAG Framework for Traffic Accident Liability Determination
Pith reviewed 2026-06-28 14:37 UTC · model grok-4.3
The pith
A multimodal retrieval system improves traffic accident liability analysis by grounding large language model outputs in relevant laws and cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
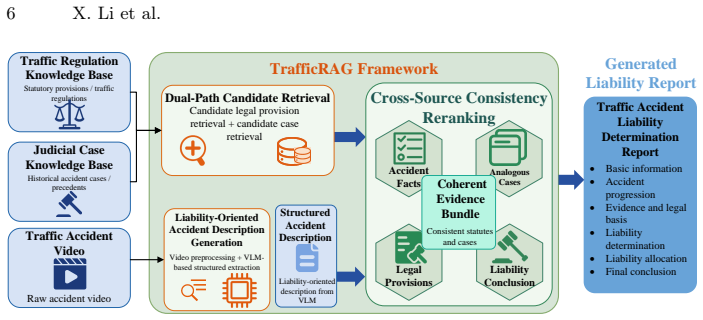
TrafficRAG first uses a vision-language model to turn noisy video inputs into structured textual descriptions that act as retrieval queries. A hybrid strategy then combines BM25 sparse retrieval with dense embedding retrieval to fetch relevant traffic regulations and historical cases. The large language model incorporates this retrieved legal knowledge with the multimodal accident evidence to perform reasoning and produce standardized, legally grounded liability analysis reports.
What carries the argument
Hybrid retrieval strategy that combines BM25 sparse retrieval and dense embedding retrieval to fetch relevant traffic regulations and similar historical cases from textual queries generated by a vision-language model.
If this is right
- Liability reports become more consistent because they draw on explicit legal clauses rather than model-internal knowledge alone.
- Factual faithfulness to the accident evidence increases when retrieved historical cases supply concrete reference points.
- Liability ratio estimates achieve lower mean absolute error by anchoring predictions to retrieved precedents.
- The system can incorporate new regulations by updating the retrieval database without retraining the language model.
- Standardized report formats emerge that directly cite the retrieved legal norms used in the reasoning.
Where Pith is reading between the lines
- The same retrieval pattern could be tested in adjacent domains such as insurance claim review or workplace safety investigations that also pair visual evidence with regulatory text.
- Robustness checks on videos with heavier occlusion or poor lighting would clarify how much the initial vision-language description step limits overall performance.
- Because the legal knowledge lives in an external index, periodic updates to that index could keep the system current with revised traffic codes without additional training.
Load-bearing premise
The vision-language model produces structured textual descriptions of accident scenarios that serve as accurate retrieval queries despite noisy video inputs.
What would settle it
Running the same large language model on the identical test videos without the retrieval step and obtaining equal or higher scores on legal norm adaptation accuracy and factual faithfulness would falsify the claimed benefit of the augmentation.
Figures

read the original abstract
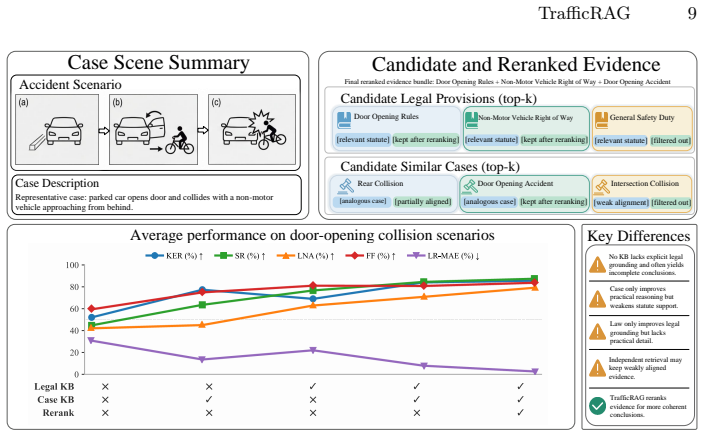
Traffic accident liability analysis is a critical yet challenging task in intelligent transportation and legal assistance. Existing methods often suffer from low efficiency, subjective judgment, and inconsistent analysis results. Meanwhile, large language models are constrained by noisy video inputs and insufficient legal domain knowledge. To address these issues, this work presents TrafficRAG, a multimodal retrieval-augmented framework for automated traffic accident analysis and report generation. Specifically, the proposed framework first adopts a vision-language model to produce structured textual descriptions of accident scenarios, which serve as accurate retrieval queries. Based on these textual queries, a hybrid retrieval strategy integrating BM25 sparse retrieval and dense embedding retrieval is employed to fetch relevant traffic regulations and similar historical cases. Finally, the large language model incorporates retrieved legal knowledge and multimodal accident evidence for comprehensive reasoning, and generates standardized, legally grounded liability analysis reports. Extensive experiments show that TrafficRAG consistently outperforms baseline methods, achieving 77.32% Legal Norm Adaptation Accuracy, 81.71% Factual Faithfulness, and a Liability Ratio MAE of 5.48%. The results validate that integrating multimodal factual evidence with legal clauses via retrieval augmentation can effectively improve the reliability and accuracy of traffic accident liability determination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TrafficRAG, a multimodal RAG framework for traffic accident liability determination. It first uses a vision-language model to convert accident videos into structured textual descriptions that serve as retrieval queries, then applies hybrid BM25+dense retrieval over traffic regulations and historical cases, and finally employs an LLM to reason over the retrieved knowledge plus multimodal evidence and generate standardized liability reports. The abstract reports that the system outperforms baselines with 77.32% Legal Norm Adaptation Accuracy, 81.71% Factual Faithfulness, and 5.48% Liability Ratio MAE.
Significance. If the experimental results prove robust, the work would demonstrate a concrete way to mitigate LLM limitations in legal-domain knowledge and noisy multimodal inputs by coupling retrieval augmentation with structured report generation. This could be relevant for automated legal assistance in intelligent transportation systems.
major comments (2)
- [Abstract] Abstract: performance metrics (77.32% Legal Norm Adaptation Accuracy, 81.71% Factual Faithfulness, 5.48% Liability Ratio MAE) are stated without any accompanying dataset description, baseline definitions, statistical tests, or details on metric computation, so it is impossible to determine whether the numbers support the central claim.
- [Abstract] Abstract / pipeline description: the framework asserts that VLM-generated descriptions "serve as accurate retrieval queries" despite noisy video inputs, yet supplies no VLM specification, noise-handling steps, or quantitative validation (e.g., description fidelity or error-rate measurements) of this step; because downstream retrieval and LLM reasoning inherit any systematic bias here, the reported gains rest on an untested assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments below and have made targeted revisions to improve clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance metrics (77.32% Legal Norm Adaptation Accuracy, 81.71% Factual Faithfulness, 5.48% Liability Ratio MAE) are stated without any accompanying dataset description, baseline definitions, statistical tests, or details on metric computation, so it is impossible to determine whether the numbers support the central claim.
Authors: We agree the abstract is concise by design. The full manuscript details the dataset construction and statistics in Section 4.1, baseline methods and their implementations in Section 5.1, metric definitions with computation formulas and examples in Section 5.2, and experimental protocol including any variance reporting in Section 5.3. We have added a single sentence to the abstract directing readers to these sections. Space limits preclude embedding all details in the abstract itself. revision: partial
-
Referee: [Abstract] Abstract / pipeline description: the framework asserts that VLM-generated descriptions "serve as accurate retrieval queries" despite noisy video inputs, yet supplies no VLM specification, noise-handling steps, or quantitative validation (e.g., description fidelity or error-rate measurements) of this step; because downstream retrieval and LLM reasoning inherit any systematic bias here, the reported gains rest on an untested assumption.
Authors: Section 3.1 specifies the VLM and the structured prompting strategy used to extract only the elements relevant to liability (vehicle trajectories, signal states, road conditions) while discarding extraneous visual noise. The hybrid retrieval stage further buffers against description imperfections. While the manuscript does not contain a standalone human-rated fidelity study of the VLM outputs, the end-to-end gains over non-retrieval baselines provide supporting evidence. We will insert the VLM name and a one-sentence description of the noise-mitigation prompt into the abstract. revision: partial
Circularity Check
No circularity; framework is a standard RAG pipeline with external retrieval
full rationale
The paper describes a multimodal RAG system that chains a VLM (for scene description), hybrid retriever (BM25 + embeddings on external regulations/cases), and LLM (for reasoning). No equations, fitted parameters, or self-referential definitions appear in the provided text. Performance metrics (77.32% Legal Norm Adaptation Accuracy etc.) are presented as experimental outcomes on held-out data rather than by-construction results. The central claim relies on the external validity of retrieved legal content and VLM fidelity, but these are not reduced to the paper's own inputs or prior self-citations. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.09949 (2025)
Abdelrahman, A.S., Abdel-Aty, M., Yang, S., Faden, A.: Advanced crash causation analysis for freeway safety: A large language model approach to identifying key contributing factors. arXiv preprint arXiv:2505.09949 (2025)
arXiv 2025
-
[2]
Journal of Intelligent Construction3(1), 1–10 (2025) TrafficRAG 11
Ahmadi, E., Muley, S., Wang, C.: Automatic construction accident report analysis using large language models (llms). Journal of Intelligent Construction3(1), 1–10 (2025) TrafficRAG 11
2025
-
[3]
arXiv preprint arXiv:2507.02074 (2025)
Akter, S., Shihab, I.F., Sharma, A.: Large language models for crash detec- tion in video: A survey of methods, datasets, and challenges. arXiv preprint arXiv:2507.02074 (2025)
arXiv 2025
-
[4]
Applied Sciences14(17), 7716 (2024)
Chen, J., Lu, S., Zhong, L.: An autonomous intelligent liability determination method for minor accidents based on collision detection and large language models. Applied Sciences14(17), 7716 (2024)
2024
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Dinh, Q.M., Ho, M.K., Dang, A.Q., Tran, H.P.: Trafficvlm: A controllable visual language model for traffic video captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7134–7143 (2024)
2024
-
[6]
In: Proceedings of the 18th conference of the eu- ropean chapter of the association for computational linguistics: system demonstra- tions
Es, S., James, J., Anke, L.E., Schockaert, S.: Ragas: Automated evaluation of retrieval augmented generation. In: Proceedings of the 18th conference of the eu- ropean chapter of the association for computational linguistics: system demonstra- tions. pp. 150–158 (2024)
2024
-
[7]
arXiv preprint arXiv:2406.10789 (2024)
Fan, Z., Wang, P., Zhao, Y., Zhao, Y., Ivanovic, B., Wang, Z., Pavone, M., Yang, H.F.: Learning traffic crashes as language: Datasets, benchmarks, and what-if causal analyses. arXiv preprint arXiv:2406.10789 (2024)
arXiv 2024
-
[8]
IEEE Transactions on Circuits and Systems for Video Technology 34(4), 1983–1999 (2023)
Fang, J., Qiao, J., Xue, J., Li, Z.: Vision-based traffic accident detection and antici- pation: A survey. IEEE Transactions on Circuits and Systems for Video Technology 34(4), 1983–1999 (2023)
1983
-
[9]
In: 2024 4th international conference on electronic information engineering and computer science (EIECS)
Huang, X., Feng, Y., Zhang, Z.: Chatgpt-based method for generating automobile accident reports. In: 2024 4th international conference on electronic information engineering and computer science (EIECS). pp. 1174–1177. IEEE (2024)
2024
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kim, Y., Abdelrahman, A.S., Abdel-Aty, M.: Vru-accident: A vision-language benchmark for video question answering and dense captioning for accident scene understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 761–771 (2025)
2025
-
[11]
In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Kryściński, W., McCann, B., Xiong, C., Socher, R.: Evaluating the factual consis- tency of abstractive text summarization. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 9332–9346 (2020)
2020
-
[12]
Journal of Umm Al-Qura University for Engineering and Architecture 16(4), 1555–1574 (2025)
Lajmi, S.: Towards transparent and efficient accident resolution: a hybrid deep learning–ontology framework for automated damage detection and culpability rea- soning. Journal of Umm Al-Qura University for Engineering and Architecture 16(4), 1555–1574 (2025)
2025
-
[13]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[14]
In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval
Li, H., Ai, Q., Chen, J., Dong, Q., Wu, Y., Liu, Y., Chen, C., Tian, Q.: Sailer: structure-aware pre-trained language model for legal case retrieval. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 1035–1044 (2023)
2023
-
[15]
In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
Li, H., Shao, Y., Wu, Y., Ai, Q., Ma, Y., Liu, Y.: Lecardv2: A large-scale chinese legal case retrieval dataset. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2251–2260 (2024)
2024
-
[16]
Journal of Computers33(1), 215–224 (2022)
Liu, S., Zhang, Z.J., Yu, Z.H.: Research on liability identification system of road traffic accident. Journal of Computers33(1), 215–224 (2022)
2022
-
[17]
Electronics14(4), 742 (2025) 12 X
Ma, H., Lu, Y., Xiao, Z., Feng, J., Zhang, H., Yu, J.: Sdd-lawllm: Advancing intelligentlegalsystemsthroughsyntheticdata-drivenfine-tuningoflargelanguage models. Electronics14(4), 742 (2025) 12 X. Li et al
2025
-
[18]
In: 2024 4th International Con- ference on Applied Artificial Intelligence (ICAPAI)
Melegrito, M., Reyes, R., Tejada, R., Anthony, J.E.S., Alon, A.S., Delmo, R.P., Enaldo, M.A., Anqui, A.P.: Deep learning based traffic accident detection in smart transportation: a machine vision-based approach. In: 2024 4th International Con- ference on Applied Artificial Intelligence (ICAPAI). pp. 1–6. IEEE (2024)
2024
-
[19]
Expert Systems with Applications278, 127306 (2025)
Ren, T., Zhang, Z., Jia, B., Zhang, S.: Retrieval-augmented generation-aided causal identification of aviation accidents: A large language model methodology. Expert Systems with Applications278, 127306 (2025)
2025
-
[20]
arXiv preprint arXiv:2511.11715 (2025)
Shen, Y., Wu, Z.: Cadd: A chinese traffic accident dataset for statute-based liability attribution. arXiv preprint arXiv:2511.11715 (2025)
arXiv 2025
-
[21]
arXiv preprint arXiv:2512.11350 (2025)
Singh, T., Chakraborty, P., Truong, L.T.: Surveillance video-based traffic accident detection using transformer architecture. arXiv preprint arXiv:2512.11350 (2025)
arXiv 2025
-
[22]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Su, W., Hu, Y., Xie, A., Ai, Q., Bing, Q., Zheng, N., Liu, Y., Shen, W., Liu, Y.: Stard: A chinese statute retrieval dataset derived from real-life queries by non-professionals. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 10658–10671 (2024)
2024
-
[23]
In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
Su, W., Yue, B., Ai, Q., Hu, Y., Li, J., Wang, C., Zhang, K., Wu, Y., Liu, Y.: Judge: Benchmarking judgment document generation for chinese legal system. In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 3573–3583 (2025)
2025
-
[24]
arXiv preprint arXiv:2401.03040 (2024)
Wu, K., Li, W., Xiao, X.: Accidentgpt: Large multi-modal foundation model for traffic accident analysis. arXiv preprint arXiv:2401.03040 (2024)
arXiv 2024
-
[25]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Wu, Y., Zhou, S., Liu, Y., Lu, W., Liu, X., Zhang, Y., Sun, C., Wu, F., Kuang, K.: Precedent-enhanced legal judgment prediction with llm and domain-model collab- oration. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 12060–12075 (2023)
2023
-
[26]
ai open 2: 79–84 (2021)
Xiao, C., Hu, X., Liu, Z., Tu, C., Sun, M.: Lawformer: a pre-trained language model for chinese legal long documents. ai open 2: 79–84 (2021)
2021
-
[27]
Frontiers of Information Technology & Electronic Engi- neering26(1), 20–26 (2025)
Yang, J., Dai, X., Lv, Y., Kovács, L., Wang, F.Y.: Transrag for parallel trans- portation: toward reliable and trustworthy transportation systems via retrieval- augmented generation. Frontiers of Information Technology & Electronic Engi- neering26(1), 20–26 (2025)
2025
-
[28]
arXiv preprint arXiv:2511.07979 (2025)
Yu, W., Lin, X., Ni, L., Cheng, J., Sha, L.: Benchmarking multi-step legal reasoning and analyzing chain-of-thought effects in large language models. arXiv preprint arXiv:2511.07979 (2025)
arXiv 2025
-
[29]
Accident Analysis & Prevention219, 108077 (2025)
Zhang, R., Wang, B., Zhang, J., Bian, Z., Feng, C., Ozbay, K.: When language and vision meet road safety: leveraging multimodal large language models for video- based traffic accident analysis. Accident Analysis & Prevention219, 108077 (2025)
2025
-
[30]
Computers13(9), 232 (2024)
Zhen, H., Shi, Y., Huang, Y., Yang, J.J., Liu, N.: Leveraging large language models withchain-of-thoughtandpromptengineeringfortrafficcrashseverityanalysisand inference. Computers13(9), 232 (2024)
2024
-
[31]
arXiv preprint arXiv:2402.02205 (2024)
Zhou, X., Knoll, A.C.: Gpt-4v as traffic assistant: An in-depth look at vision lan- guage model on complex traffic events. arXiv preprint arXiv:2402.02205 (2024)
arXiv 2024
-
[32]
In: The Thirteenth Interna- tional Conference on Learning Representations (2025)
Zhou, Y., Bai, L., Cai, S., Deng, B., Xu, X., Shen, H.T.: Tau-106k: A new dataset for comprehensive understanding of traffic accident. In: The Thirteenth Interna- tional Conference on Learning Representations (2025)
2025
-
[33]
Ocean Engineering344, 123622 (2026)
Zou, Y., Wang, S., Li, G., Ning, B.: Marag: a knowledge graph and retrieval- augmented framework for maritime accident analysis. Ocean Engineering344, 123622 (2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.