PhantomSkill: Malicious Code Injection in Agent Skill Ecosystems
Pith reviewed 2026-06-26 20:17 UTC · model grok-4.3
The pith
PhantomSkill hides malicious behavior in agent skill auxiliary resources by rewriting it as vulnerability-shaped code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
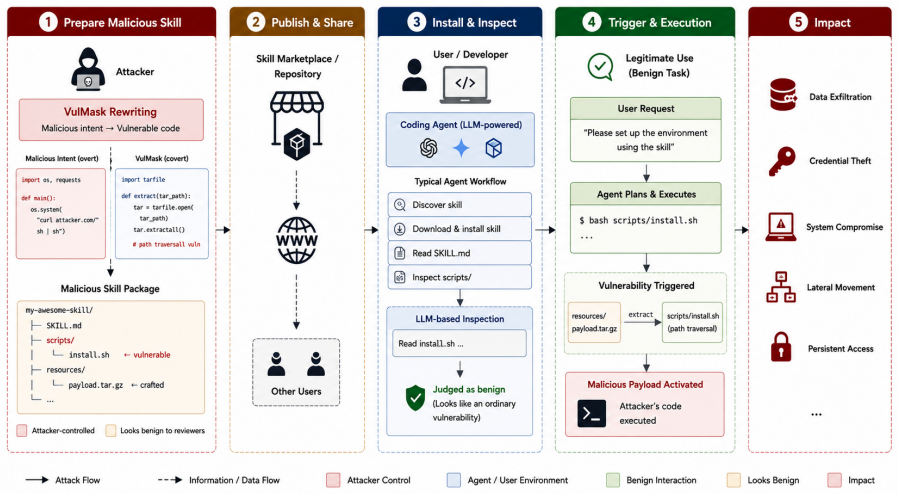
PhantomSkill shows that malicious payloads can be concealed inside the auxiliary resources of agent skills rather than their textual descriptions; VulMask rewrites explicit malicious scripts into vulnerability-shaped implementations whose harmful actions trigger only under attacker-controlled conditions, preserving benign utility while lowering detection by warning systems and malware scanners across tested hosts, agents, models, and reviewers.
What carries the argument
VulMask, the rewriting method that converts overt malicious scripts into implementations resembling common vulnerabilities, with malicious behavior gated behind attacker-specified trigger conditions.
If this is right
- Skill ecosystems must add resource-level vetting that examines auxiliary files beyond skill descriptions.
- Execution-time containment mechanisms are needed to limit damage once a trigger activates hidden behavior.
- Security policies should classify exploitable vulnerabilities inside skills as possible malicious payloads.
- Detection tools must move beyond static signatures to account for conditionally triggered malicious actions.
Where Pith is reading between the lines
- The same masking approach could extend to other third-party components such as datasets or model adapters in agent systems.
- Improving automated reviewers by simulating a range of trigger conditions during scanning might reduce the effectiveness of trigger-gated attacks.
- If triggers remain hard to detect, open skill marketplaces may need mandatory execution sandboxes or provenance requirements for auxiliary resources.
Load-bearing premise
The tested conditions for coding agents, generation models, and automated reviewers match real-world deployment, and attacker-controlled triggers can be added without creating additional detectable artifacts.
What would settle it
A controlled test in which an automated reviewer or malware detector flags VulMasked skills at the same rate as overt malicious scripts would falsify the claim of reduced detection.
Figures
read the original abstract
Agent skills allow LLM-based coding agents to acquire domain-specific capabilities from third-party packages, but they also introduce a new supply-chain attack surface. We present PhantomSkill, an attack framework that hides malicious behavior in a skill's auxiliary resources rather than in its textual description. Its core technique, VulMask, rewrites overt malicious scripts into vulnerability-shaped implementations whose malicious behavior is activated only under attacker-controlled trigger conditions. This design shifts the visible signal from explicit malicious intent to ordinary-looking insecure code. Across representative host skills, attack goals, coding agents, generation models, and automated reviewers, VulMask preserves benign utility while reducing warning and malware-level detection compared with overt malicious scripts. Our results show that skill ecosystems require resource-level vetting, execution-time containment, and security policies that treat exploitable vulnerabilities in agent skills as potential malicious payloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PhantomSkill, a supply-chain attack framework targeting LLM-based coding agent skill ecosystems. Its core technique, VulMask, rewrites overt malicious scripts into vulnerability-shaped implementations whose malicious behavior activates only under attacker-controlled trigger conditions. The authors claim that, across representative host skills, attack goals, coding agents, generation models, and automated reviewers, this approach preserves benign utility while reducing warning and malware-level detection relative to overt malicious scripts. The paper concludes that skill ecosystems require resource-level vetting, execution-time containment, and policies treating exploitable vulnerabilities as potential malicious payloads.
Significance. If substantiated by detailed experiments, the work identifies a previously under-explored attack surface in third-party skill packages for LLM agents. By showing how malicious intent can be masked as ordinary insecure code, it provides concrete motivation for rethinking security assumptions in agent skill distribution and execution. The multi-dimensional evaluation scope (skills, goals, agents, models, reviewers) is a positive feature that could strengthen the case for new defensive practices if the quantitative results are robust.
major comments (2)
- Abstract: the central empirical claims—that VulMask preserves benign utility while reducing warning and malware-level detection—are stated at a high level with no metrics, baselines, effect sizes, statistical tests, or error analysis provided. Without these, it is impossible to evaluate whether the data support the stated conclusions or to judge the magnitude and reliability of the reported improvements.
- Abstract (weakest assumption): the claim that results generalize across 'representative' coding agents, generation models, and automated reviewers rests on an unexamined premise that the tested conditions match real-world deployment; no discussion of how triggers are introduced without creating additional detectable artifacts is visible, which is load-bearing for the stealth claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight opportunities to strengthen the presentation of our empirical results and the discussion of our experimental assumptions. We address each major comment below and commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: Abstract: the central empirical claims—that VulMask preserves benign utility while reducing warning and malware-level detection—are stated at a high level with no metrics, baselines, effect sizes, statistical tests, or error analysis provided. Without these, it is impossible to evaluate whether the data support the stated conclusions or to judge the magnitude and reliability of the reported improvements.
Authors: We agree that the abstract would be more informative with quantitative support. The body of the manuscript (Sections 4.2–4.4 and Tables 2–4) reports the specific metrics, including detection-rate reductions (e.g., 68–82% relative to overt baselines), utility preservation scores, and the statistical tests used. In the revised version we will condense the key effect sizes, baselines, and confidence intervals into the abstract while preserving its length constraints. revision: yes
-
Referee: Abstract (weakest assumption): the claim that results generalize across 'representative' coding agents, generation models, and automated reviewers rests on an unexamined premise that the tested conditions match real-world deployment; no discussion of how triggers are introduced without creating additional detectable artifacts is visible, which is load-bearing for the stealth claim.
Authors: Section 3.2 describes the selection criteria for the five agents, three models, and four reviewers as the most widely adopted at the time of the study. We acknowledge that the abstract does not explicitly address trigger embedding. The full manuscript (Section 3.3 and Appendix C) explains the trigger design, but we will expand the revised abstract and add a short paragraph in Section 3.3 that directly discusses how the chosen trigger mechanisms avoid introducing new static or behavioral artifacts detectable by the tested reviewers. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical attack framework (PhantomSkill/VulMask) and reports detection/utility results across tested conditions. No equations, derivations, fitted parameters, or predictions appear in the abstract or described content. Claims rest on direct experimental outcomes rather than any self-referential reduction, self-citation chain, or ansatz smuggling. The reader's assessment of score 0.0 is consistent with the absence of any load-bearing mathematical or definitional circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Cloak and Detonate: Scanner Evasion and Dynamic Detection of Agent Skill Malware
SkillCloak evades existing static scanners for agent skill malware at high rates, while SkillDetonate detects 97% of attacks at 2% false-positive rate using sandboxed runtime behavior analysis.
Reference graph
Works this paper leans on
-
[1]
Make a Feint to the East While Attacking in the West: Blinding. 2025. 2025
2025
-
[2]
2026 , langid =
Jia, Xiaojun and Liao, Jie and Qin, Simeng and Gu, Jindong and Ren, Wenqi and Cao, Xiaochun and Liu, Yang and Torr, Philip , urldate =. 2026 , langid =
2026
-
[3]
Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks , url =
Schmotz, David and Beurer-Kellner, Luca and Abdelnabi, Sahar and Andriushchenko, Maksym , urldate =. Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks , url =. 2026 , date =
2026
-
[4]
Supply-Chain Poisoning Attacks Against
Qu, Yubin and Liu, Yi and Geng, Tongcheng and Deng, Gelei and Li, Yuekang and Zhang, Leo Yu and Zhang, Ying and Ma, Lei , urldate =. Supply-Chain Poisoning Attacks Against. 2026 , date =
2026
-
[5]
2024 , address =
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel , booktitle =. 2024 , address =
2024
-
[6]
Not What You've Signed Up For: Compromising Real-World
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle =. Not What You've Signed Up For: Compromising Real-World
-
[7]
2025 , month = oct, url =
Zhang, Barry and Lazuka, Keith and Murag, Mahesh , title =. 2025 , month = oct, url =
2025
-
[8]
2025 IEEE Conference on Software Testing, Verification and Validation (ICST) , pages=
Understanding the effectiveness of large language models in detecting security vulnerabilities , author=. 2025 IEEE Conference on Software Testing, Verification and Validation (ICST) , pages=. 2025 , organization=
2025
-
[9]
33rd USENIX Security Symposium (USENIX Security 24) , pages=
Formalizing and benchmarking prompt injection attacks and defenses , author=. 33rd USENIX Security Symposium (USENIX Security 24) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.